레이어가 깊어짐에 따라 생기는 문제
AlexNet -> VGGNet 을 통해 더 깊은 레이어를 가진 모델일수록 성능이 좋아진다는 것을 확인하였다.
그러나 레이어가 어느 정도 이상 깊어지면 Gradient Vanishing / Exploding 문제가 생기고, 또한 많은 컴퓨팅 자원 필요하며, 모델이 충분한 학습을 못 하는 등의 문제가 생겨 성능이 더 낮아진다.
GoogLeNet

GoogLeNet 은 위 문제를 해결하기 위해 레이어를 깊게가 아닌 옆으로 쌓고 concat 하였다.
추가적으로 레이어 자체의 크기 (파라미터 개수) 를 줄이기 위해 1x1 Conv 를 적용하였다.
1x1 Convolution
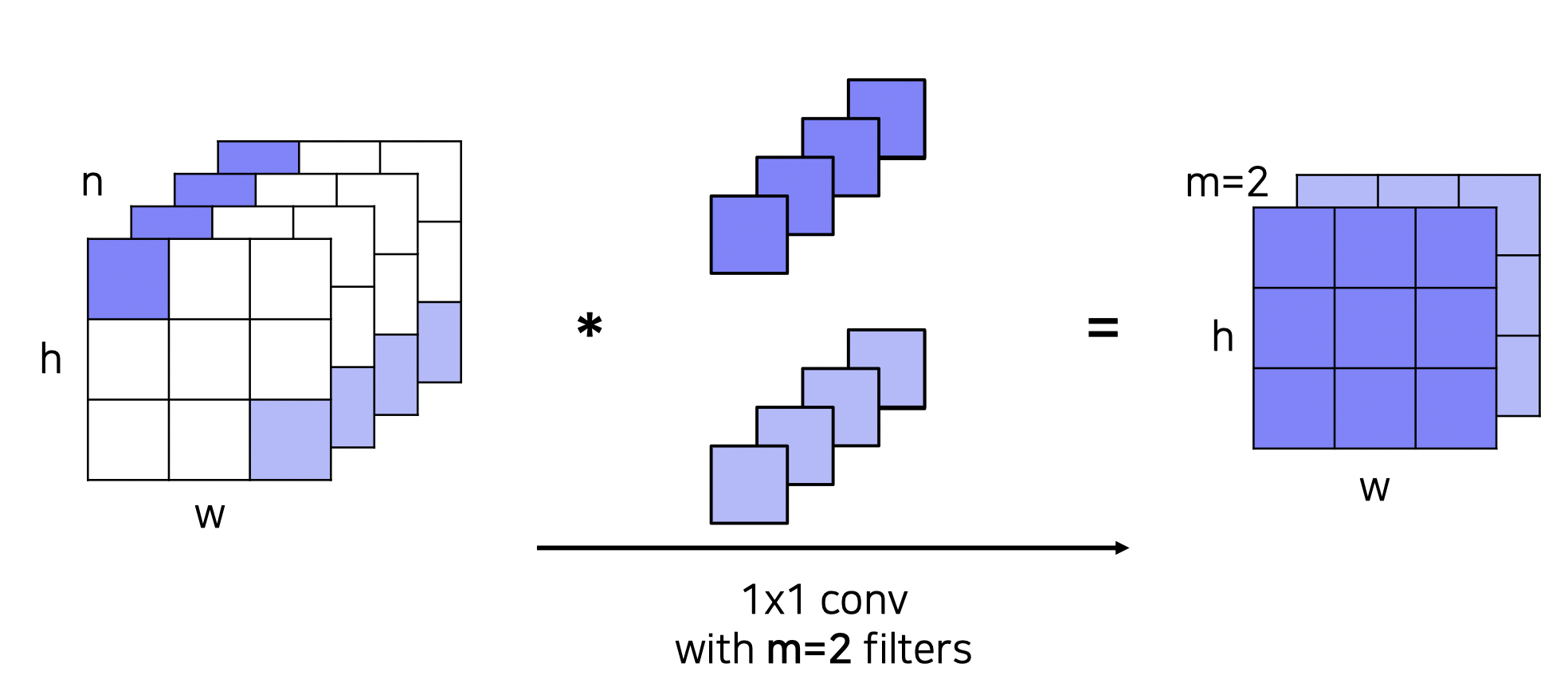
3x3x4 크기가 1x1 Conv 2개에 의해 3x3x2 가 되었다.
모델 특징

- Stem network : vanilla convolution networks
- Stacked inception modules : 가로로 쌓고 concat 하는 모델 (inception module) 을 중첩함
- Auxiliary classifiers
- 중간 중간 최종 태스크를 수행하여 로스를 측정하고 역전파되도록 설계한 구조를 말한다.
- 기울기 소실 문제 해결 위해 사용되었으며 테스트할 때는 사용하지 않는다.

ResNet
위에서 말했듯 레이어가 깊어지면 역전파 과정에서 Gradient 가 소실되는 문제가 있다. 이를 Residual connection 을 통해 어느정도 해결한 모델이 ResNet 이다.
이 모델의 function 웨이트는 자기 자신을 뺀 값으로 학습을 하기 때문에 기울기 소실이 덜 된다.
Target function : H(x) = F(x) + x
Residual function : F(x) = H(x) - x
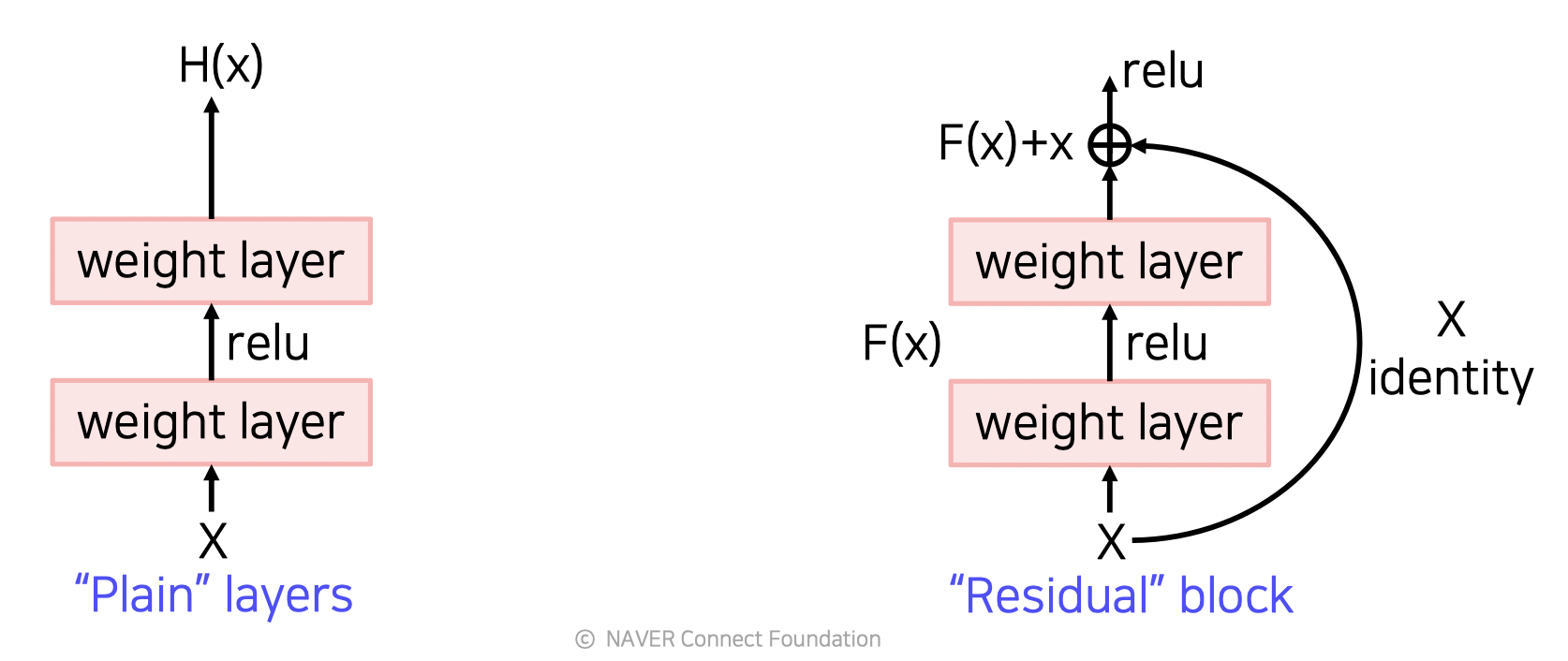
Shortcut connection (skip connection)
위의 H(x) 식에서 보듯 F(x) 에 자기 자신 x 를 더하는 방법을 말한다.
이를 통해 역전파 과정에서 직접 전단계로 영향을 줄 수 있다.
ResNet 전체 구조
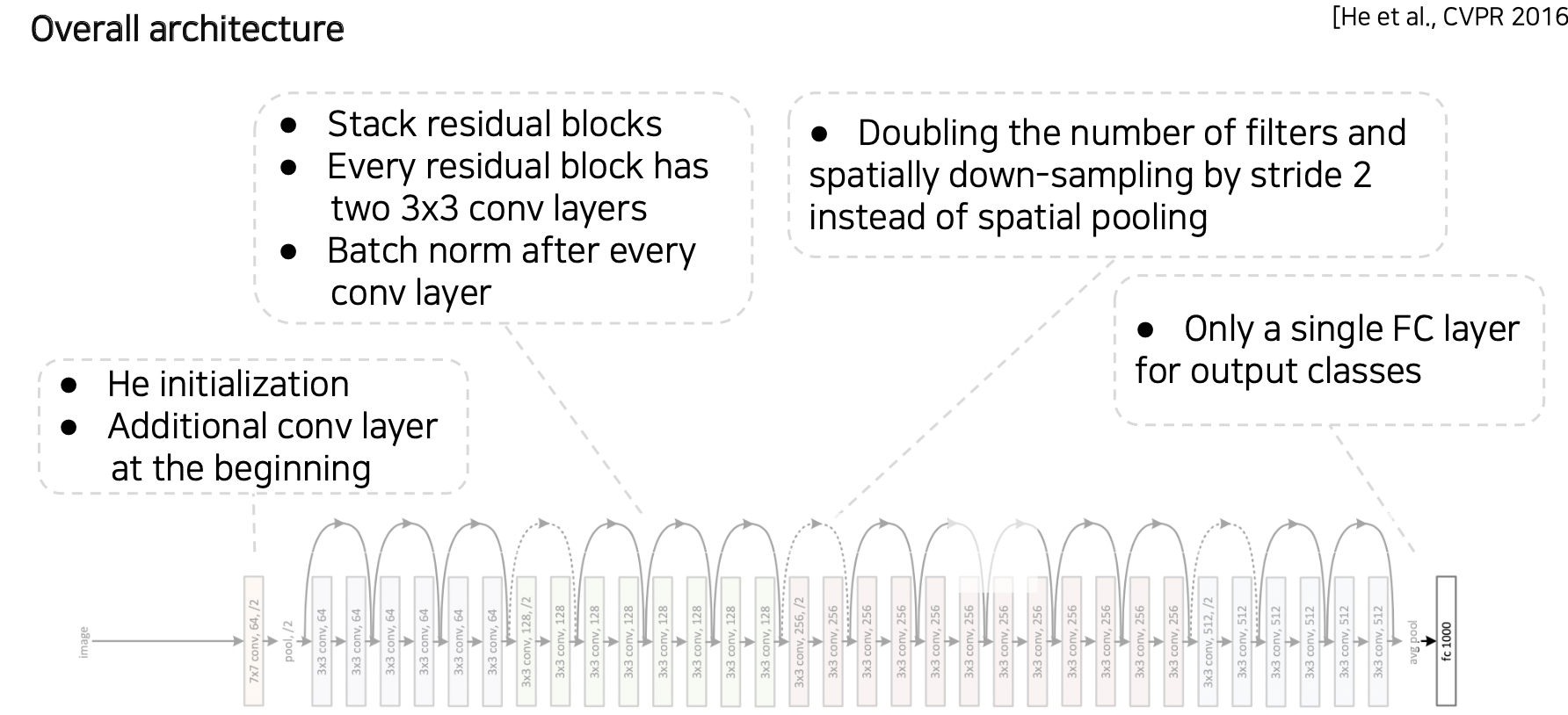
ResNet 이후 모델들
DenseNet
ResNet 과 다르게 채널 단위로 각 레이어들의 결과를 concat하고
앞 채널이 뒷 채널에까지 영향을 줘서 뒤에서는 앞의 내용을 다 참고할 수 있게 되었다. (발전된 ResNet 이라 보면 된다.)

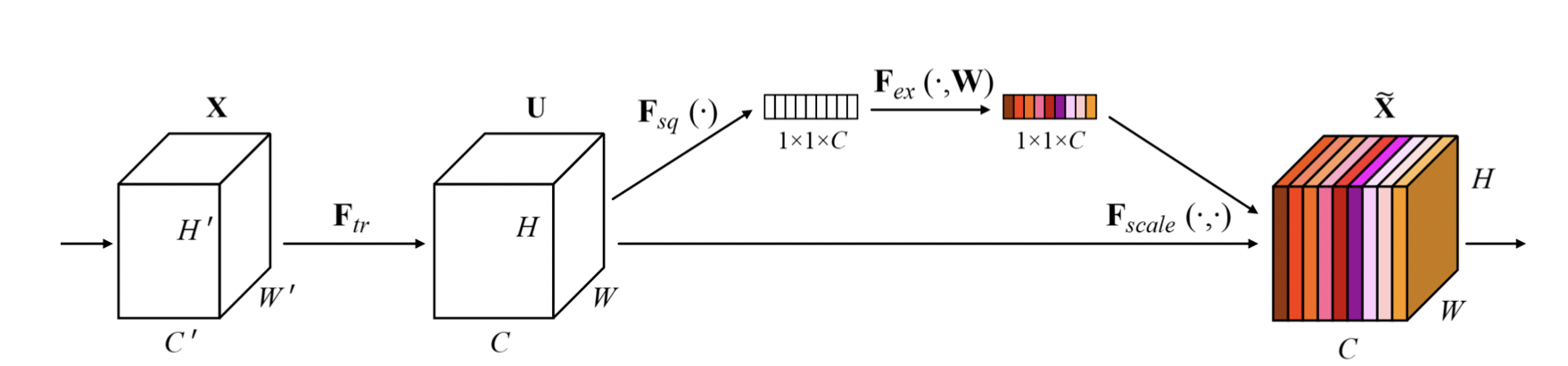
SENet
채널끼리 attention 을 수행한다.
attention 은 Squeeze (채널의 분포 파악) 와 Excitation (채널간 연관성 파악) 으로 수행된다.
EfficientNet
Component scaling (가로로 크게, 세로로 크게, 인풋 이미지 크기를 크게) 을 적용하여 성능을 높였다.
Deformable Convolution
기존 방법과 다르게 사람이나 동물처럼 움직이는 등 분포가 다른 물체를 탐지하기 위해 사용하는 방법이다.
물체에 고정되지 않은 grid 를 적용한다.
일반적으로 많이 사용하는 모델
일반적으로 GoogLeNet 계열 모델은 사용하기 복잡하기 때문에 VGGNet 이나 ResNet 계열 모델을 많이 사용한다.
참조
BoostCamp AI Tech
