시퀀스 데이터
시퀀스 데이터 이해하기
- 순차적으로 들어오는 데이터, 소리, 문자열, 주가 등
- 시계열 (time-series) 데이터는 시간 순서에 따라 나열된 데이터로 시퀀스 데이터에 속함
- 시퀀스 데이터는 독립동등분포 (i.i.d.) 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀜
- 개가 사람을 물었다 → 사람이 개를 물었다 : 순서가 바뀌면 데이터의 확률분포가 바뀜, 의미가 바뀜, 과거의 정보와 앞뒤 맥락으로 의미를 유추하기 때문
시퀀스 데이터 다루기
- 이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부확률을 이용할 수 있음

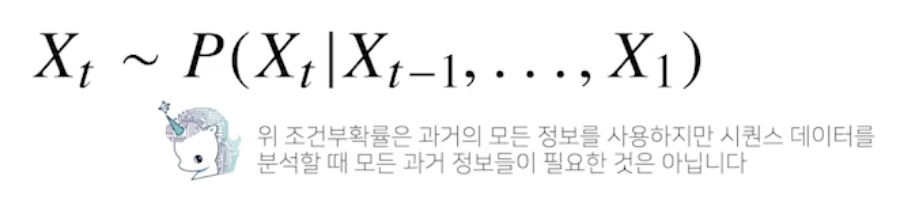
-
베이즈 정리 사용
-
시퀀스 데이터를 분석할 때 모든 과거 정보들이 필요한 것은 아님
- 삼성 주가를 예측하는데 설립 당시 정보는 필요 없기 때문
- 문장도 마찬가지로 문장 예측을 하는데 책의 처음부터 알 필요는 없음
-
방법 1
- 시퀀스 데이터를 다루기 위해서는 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요함
-
방법 2
- 하지만, 위에서 말한 것 처럼 모든 앞선 내용을 알 필요가 없기 때문에 고정된 길이 만큼의 시퀀스만 사용하고, 이 경우 AR() (Autoregressive Model) 자기회귀모델이라고 부름
- 예시
- 10 번째 단어를 예측할 때, 타우가 3 이라면 9, 8, 7 단어를 이용해 예측
- 11 번째면 10, 9, 8 단어로 예측
-
방법 3
-
바로 이전 정보를 제외한 나머지 정보들을 라는 잠재변수로 인코딩해서 활용하는 잠재 AR 모델 사용
-
예시
-
10 번째 단어를 예측할 때, 는 8~1 단어가 되고 이를 이용해 예측
-
11 번째 단어는 는 9~1 단어가 되고 이를 이용해 예측
Q. 바로 하나 전 정보 빼는거랑 안빼는거랑, 방법 1 이랑 방법 3이랑 무슨 차이?
⇒ 그게 아니라 t-1 번째 단어와, 잠재변수 두 개를 이용해서 t 번째 단어를 예측하는 것!
⇒ RNN
-
-
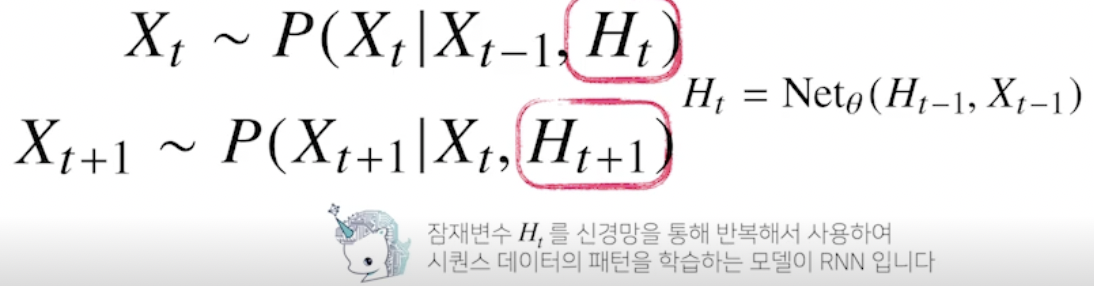
Recurrent Neural Network
RNN 이해하기
- 가장 기본적인 RNN 모형은 MLP 와 유사함

- 이 모델은 t 번째 입력이 들어오기 때문에 과거의 정보를 다룰 수 없음
- 어떻게 과거의 정보를 H 에 담을까?
- RNN 은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링
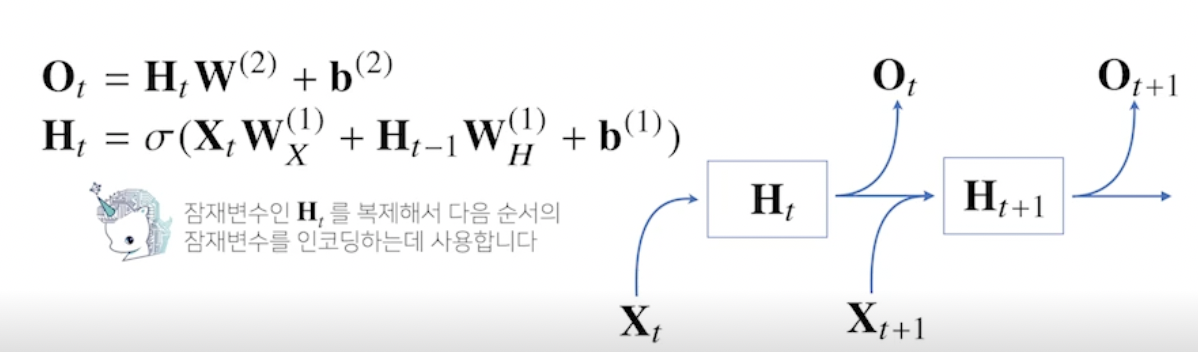
- 가중치 행렬
- 입력 데이터를 선형모델을 통해 잠재변수로 인코딩해주는 과 이전 시점의 잠재변수로부터 정보를 받아 현재 시점의 잠재변수로 인코딩해주는 가 있음
- 이렇게 만들어진 잠재변수를 통해 출력으로 만들어주는 가 있음
- 이 가중치 행렬들은 t 에 따라 변하지 않음! (중요)
- t 에 따라 변하는 것들은 잠재변수와 입력 데이터!
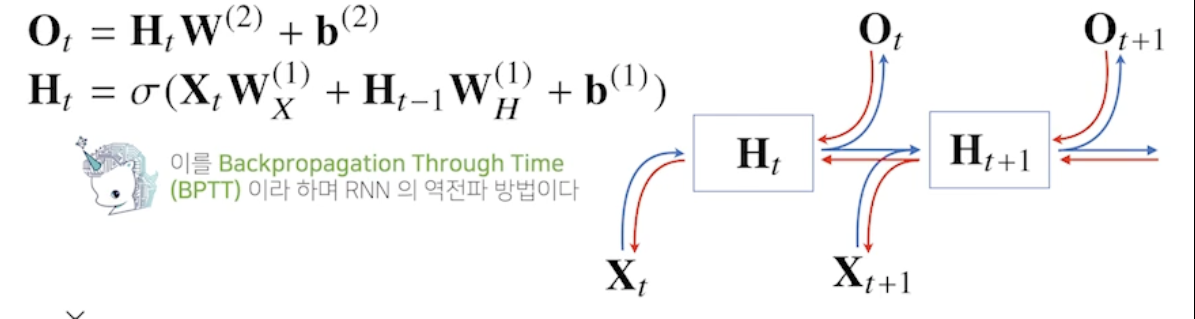
- RNN 의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산
- 즉 계산 그래프의 거꾸로 흐름, 잠재 변수들의 연결 그래프에 따라 순차적으로 진행됨, 맨 마지막 시점의 그래디언트가 타고 타고 올라와서 과거 그래디언트까지 흐름 (BPTT)
BPTT, Backpropagation Through Time
- BPTT 를 통해 RNN 의 가중치행렬의 미분을 계산해보면 아래와 같이 미분의 곱으로 이루어진 항이 계산됨

- 최종적으로 나오는 프로덕트텀 (i+1 부터 t 까지 잠재변수 곱) 을 보면 시퀀스 길이가 길어질수록 곱해지는 텀들이 불안정해짐, 이 값이 1 보다 크면 미분값이 매우 커지고 1보다 작으면 미분값이 매우 작아지기 때문 (기울기 소실)
- 일반적인 BPTT 를 모든 시점에 적용하면 학습이 어려움
기울기 소실의 해결책?
- 시퀀스 길이가 길어지는 경우 BPTT 를 통한 역전파 알고리즘의 계산이 불안정해지므로 길이를 끊어줘야 함
⇒ truncated BPTT
- BPTT 를 모든 시점에 적용하지 않고 블록으로 끊어서 수행
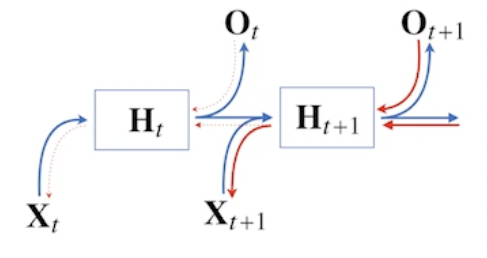
- 잠재변수들에 들어오는 그래디언트를 보면 미래에서 까지 들어오는 그래디언트는 받지만, 에는 전달하지 않음, 는 에서 들어오는 그래디언트르 받음
- 하지만 완전한 해결책이 되지 않음, 따라서 길이가 긴 시퀀스를 처리하기 힘든 Vanilla RNN 대신 LSTM 이나 GRU 등장
Sequential Model
- 비디오, 오디오, 말 등은 모두 시퀀셜 데이터
- 시퀀셜 데이터를 처리하는데 가장 큰 어려움
- 얻고 싶은 것은 하나의 라벨임, 내가 하는 말이 무엇인지
- 그런데 말이 몇 단어가 될지 알 수가 없음, 따라서 CNN 을 사용할 수가 없음
- 몇 개의 입력이 들어오든 상관없이 모델이 동작해야함
Naive sequence model
- 이전 데이터로 다음 단어를 예측해보자
- 고려해야하는 정보량이 늘어남

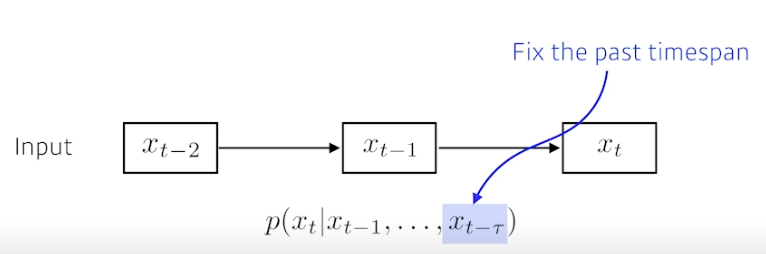
Autoregressive model
- Fix the past timespan, 과거 내용 중 볼 내용 크기를 고정
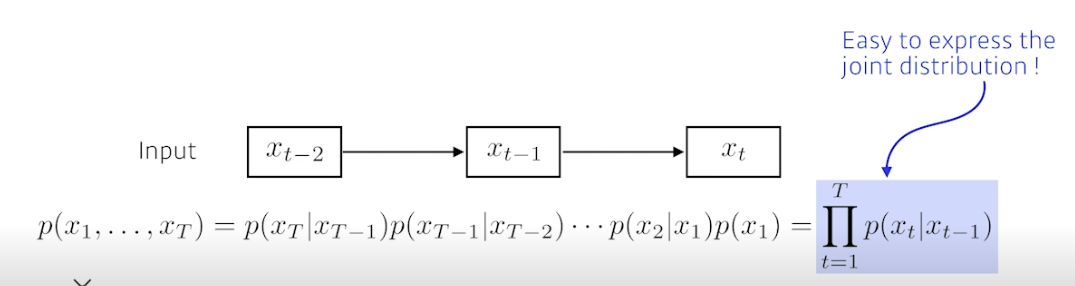
Markov model (first-order autoregressive model)
- Markovian assumption, property 을 가짐
- 내가 가정하기에 현재는 과거 (바로 전 과거) 에만 의존됨
- 내일이 수능이면 오늘 공부만 영향주는가? X → 과거 공부한게 다 누적됨
- 장점 : joint distribution 을 표현하기 쉬움
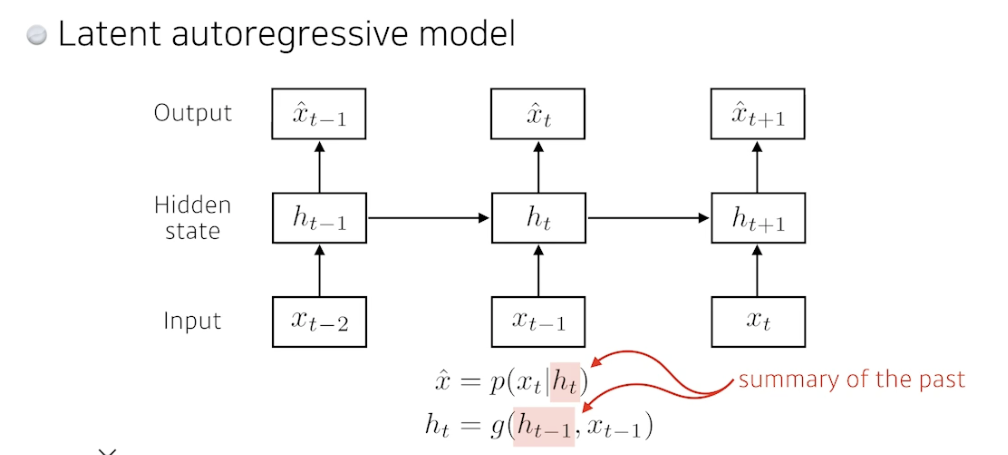
Latent autoregressive model
- 과거에 많은 정보를 고려해야하는데 할 수가 없음
- 중간에 히든 스테이트 (잠재변수, 과거를 요약) 가 들어감
- 아웃풋은 하나의 과거 정보만 의존하지만 그 이전 잠재변수 (Latent state) 에도 영향받음
Recurrent Nueral Network
- 앞서 말한 구조들을 가장 잘 표현
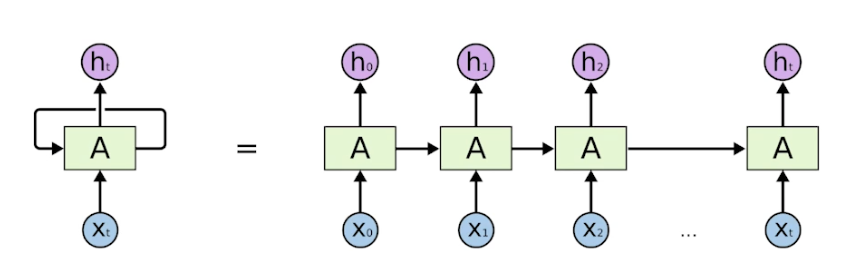
- RNN 은 시간순으로 푼다고 표현, t 에서 t-1 의 정보들도 봄
- 사실 RNN 을 시간순으로 풀면 입력이 굉장히 많은 Fullly-connected layer 와 동일해짐
- 단점, short-term dependencies
- 과거에 얻어진 어떤 정보들이 요약돼서 미래에서 고려해야 하는데, RNN 은 이 정보들을 같은 방식으로 계속 취합하기 때문에 먼 과거의 정보가 미래에 반영되기 힘듦
- 메멘토처럼 기억력이 일정 시간이라고 생각하면 됨 → 제한된 사고력
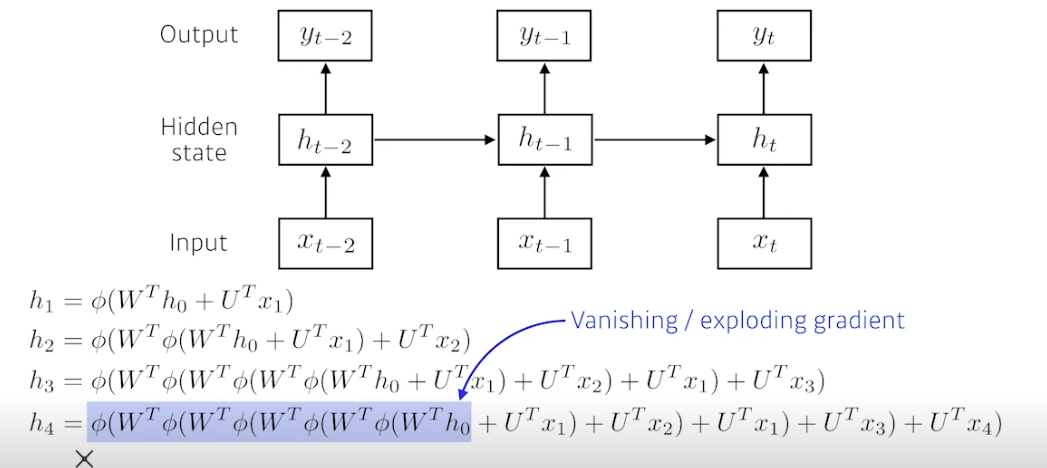
-
더불어 활성함수까지 합쳐지면 더 예전 정보는 영향력이 없어짐, 시그모이드면 Vanishing Gradient, 렐루면 너무 커져서 exponential (폭발적이게) 됨
⇒ Long short-term dependencies (LSTM) 로 단점을 극복
-
지금까지 말한 기본 RNN = Vanilla RNN
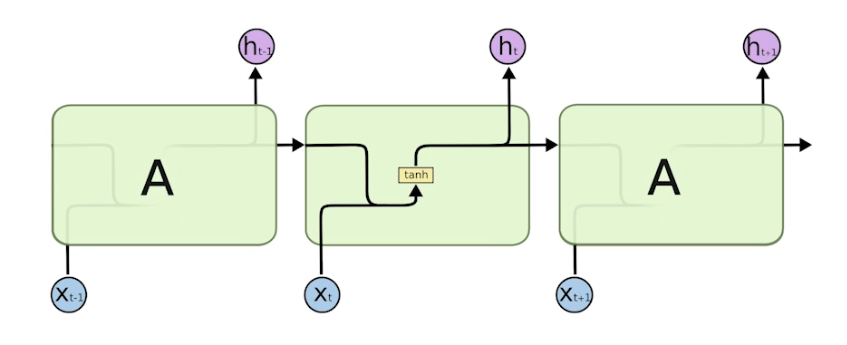
LSTM
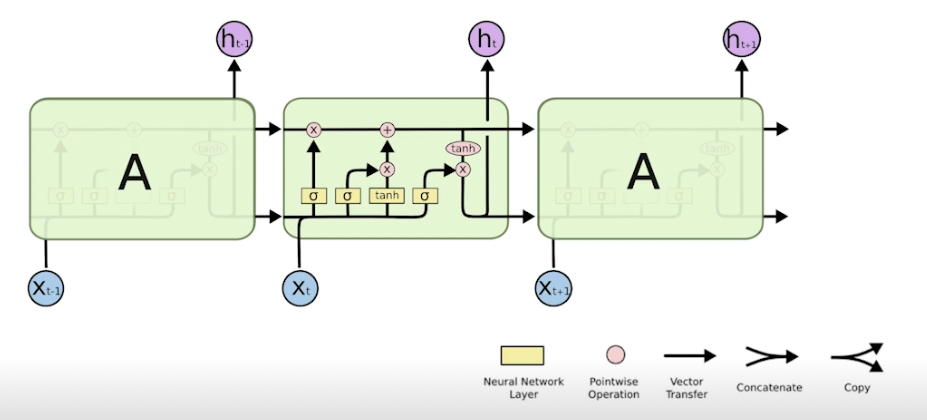
- 어떻게 LSTM 이 롱텀 디펜던시를 해결하는지 볼 것
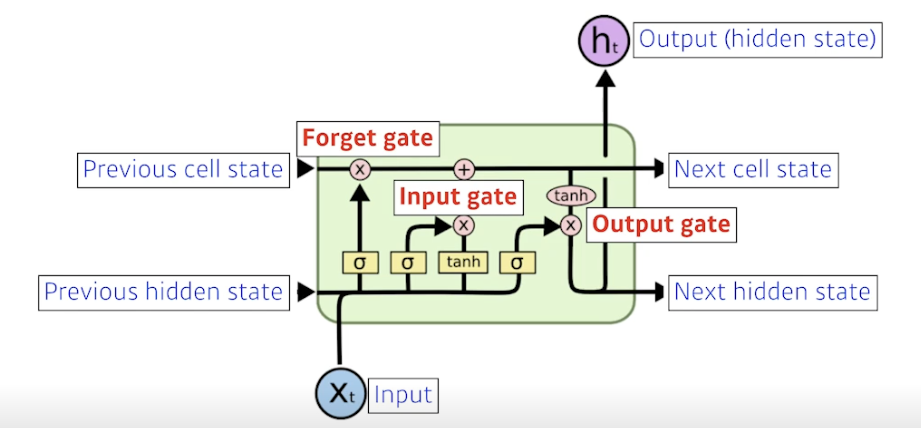
- input : 단어에 대한 벡터 (총 단어 5 만개면 5 만짜리 one-hot vector)
- output (hidden state) : 다음번 분포, 단어의 확률을 찾게 해줌 (유일하게 밖으로 나감)
- previous cell state : 지금까지 들어왔던 t-1 개의 정보를 요약한 정보 (밖으로 나가지 않음)
- previous hidden state : 전 단계의 아웃풋
- LSTM 의 가장 큰 아이디어는 중간을 흘러가는 cell state! 컨베이너 벨트와 같음. 이 정보를 잘 조작해서 어떤 정보가 유용하고 유용하지 않은지를 다음에 알려줌 ⇒ 게이트 사용
- LSTM 은 게이트로 이해하는게 좋음. 총 3개의 게이트 존재
- 히든으로부터 받은 정보를 조작해서 cell state 에 영향을 줌
-
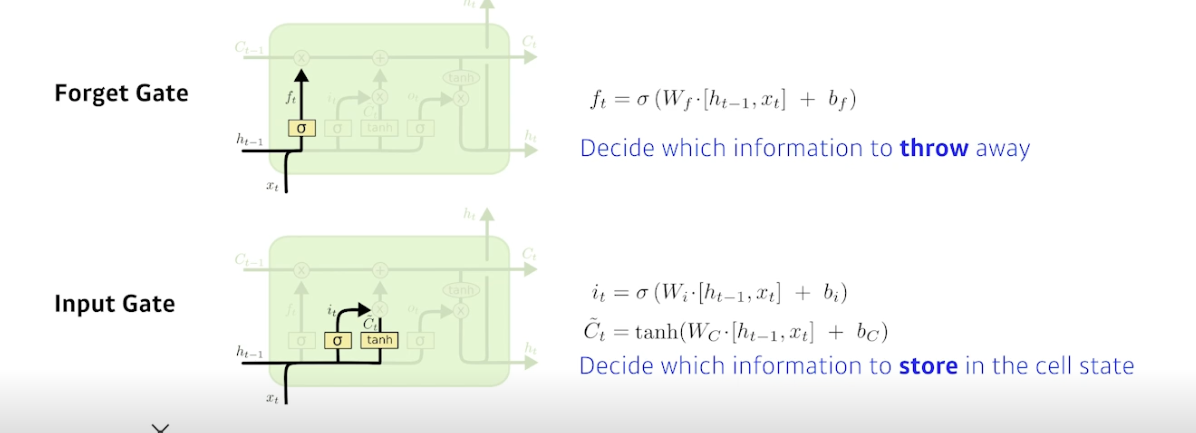
Forget gate (버릴거 정하기)
-
Decide which information to throw away
-
: 이전 셀스테이트에서 넘어온 정보 중 버릴 것을 정함
→ 이전 히든 정보와 현재 입력을 통해 지울거 정함
-
-
Input gate (남길거 정하기)
-
Decide which information to store in the cell state
-
: 이전 히든과 현재 정보를 통해 어떤 정보를 올릴지에 대한 정보
-
(cell state candidate) : 이전 히든과 현재 정보로 tanh 통과해서 모든 값이 정규화된 C 틸다, 셀 스테이트의 예비군
-
이 두개를 잘 섞으면 새로운 셀 스테이트로 업데이트됨
→ 이전 요약 정보와 현재 입력을 통해 남길거 정함
-
-
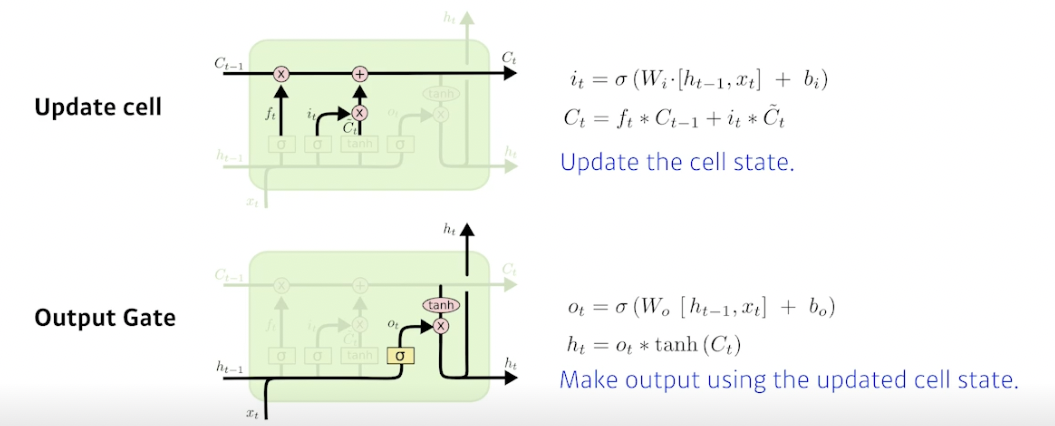
Update cell (작업 실시)
-
Update the cell state
-
f 를 통해 버릴거 버리고, C틸다를 통해 어느 값을 올릴지 정함
→ 버릴 것과 남길 것을 토대로 셀 스테이트를 업데이트
-
-
Output gate
-
Make output using the updated cell state
-
업데이트된 값을 얼만큼 밖으로 내보낼지 정함
→ 업데이트 된 값을 한 번 더 조작해서 밖으로 빼냄
-
GRU, Gated Recurrent Unit
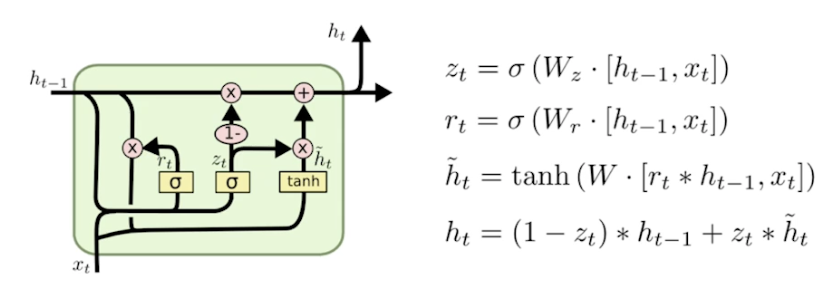
- LSTM 과 다르게 Gate 2 개 (reset gate (폴겟 게이트와 비슷), update gate)
- cell state 없음, hidden state 만 존재
- 똑같은 랭귀지 모델에 대해서 LSTM 보다 GRU 썼을 때 더 성능 좋은 경우가 꽤 있음
- 파라미터가 적어지기 때문에 퍼포먼스 증가
- 그러나 요즘엔 트랜스포머 때문에 LSTM, GRU 둘 다 대치되버림
참조
BoostCamp AI Tech
