개요
딥러닝 모델의 많은 레이어 중 중요하지 않은 파라미터를 지워 (가지치기) 가볍게 만들자.
Weighted Sum for Pruning
한 레이어에 존재하는 여러 파라미터의 중요도에 따라 다른 가중치를 적용하여 중요한 부분과 안 중요한 부분의 크기를 다르게 만든다.
Pruning 이란
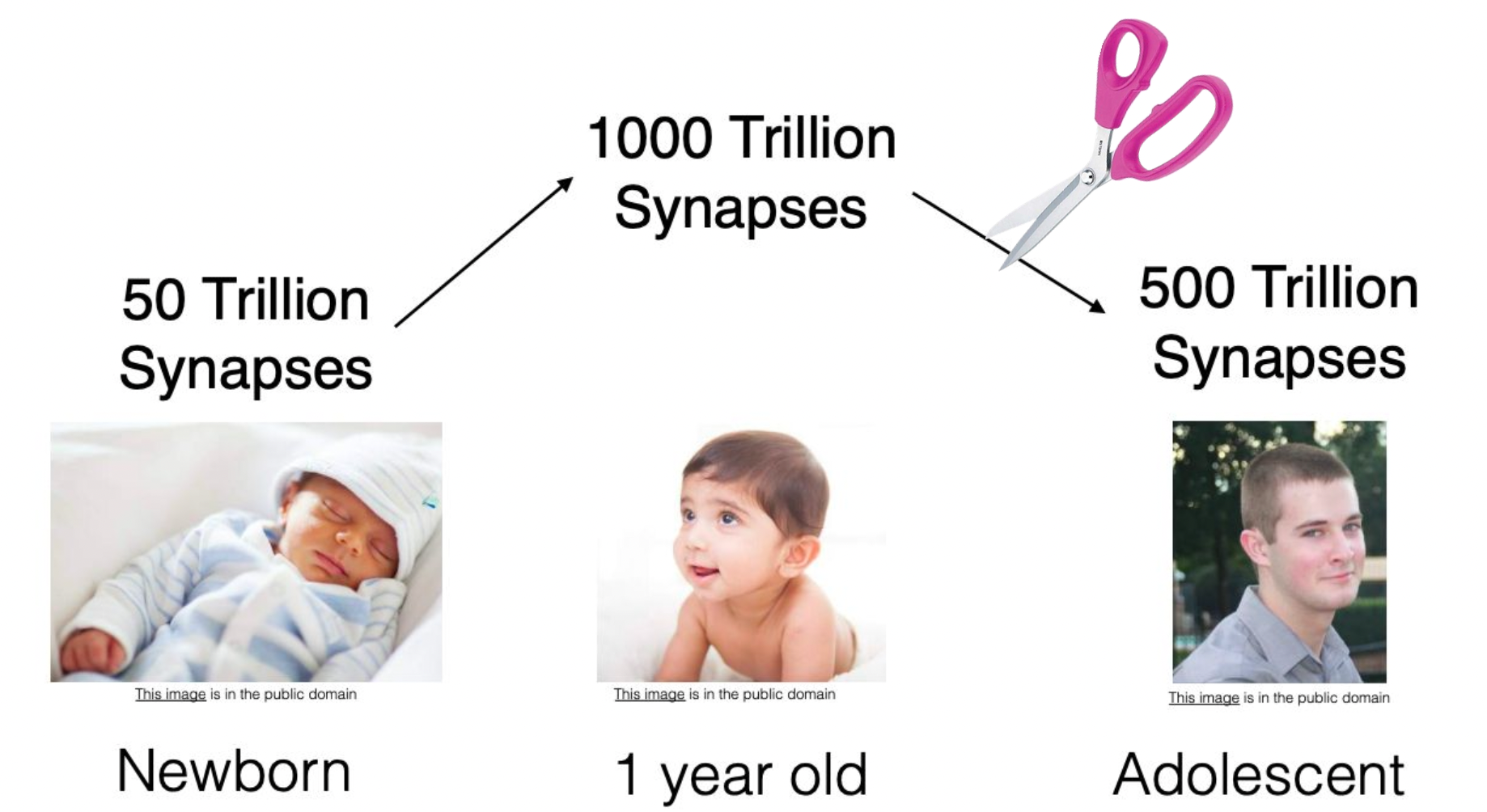
성장과정에서 뉴런 수의 변화
사람
사람은 성장하면서 뉴런의 수가 줄어든다.
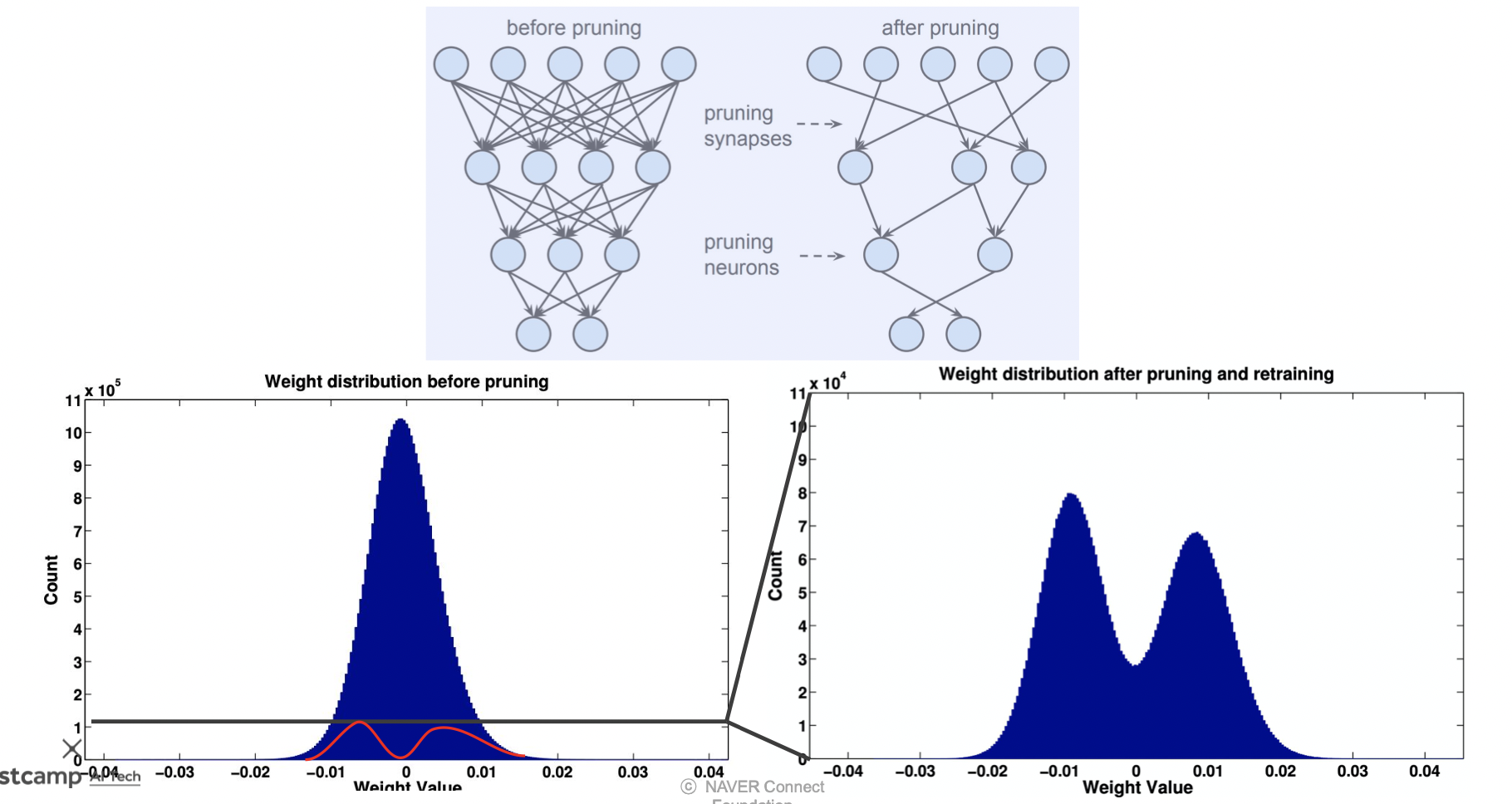
뉴럴 네트워크 모델
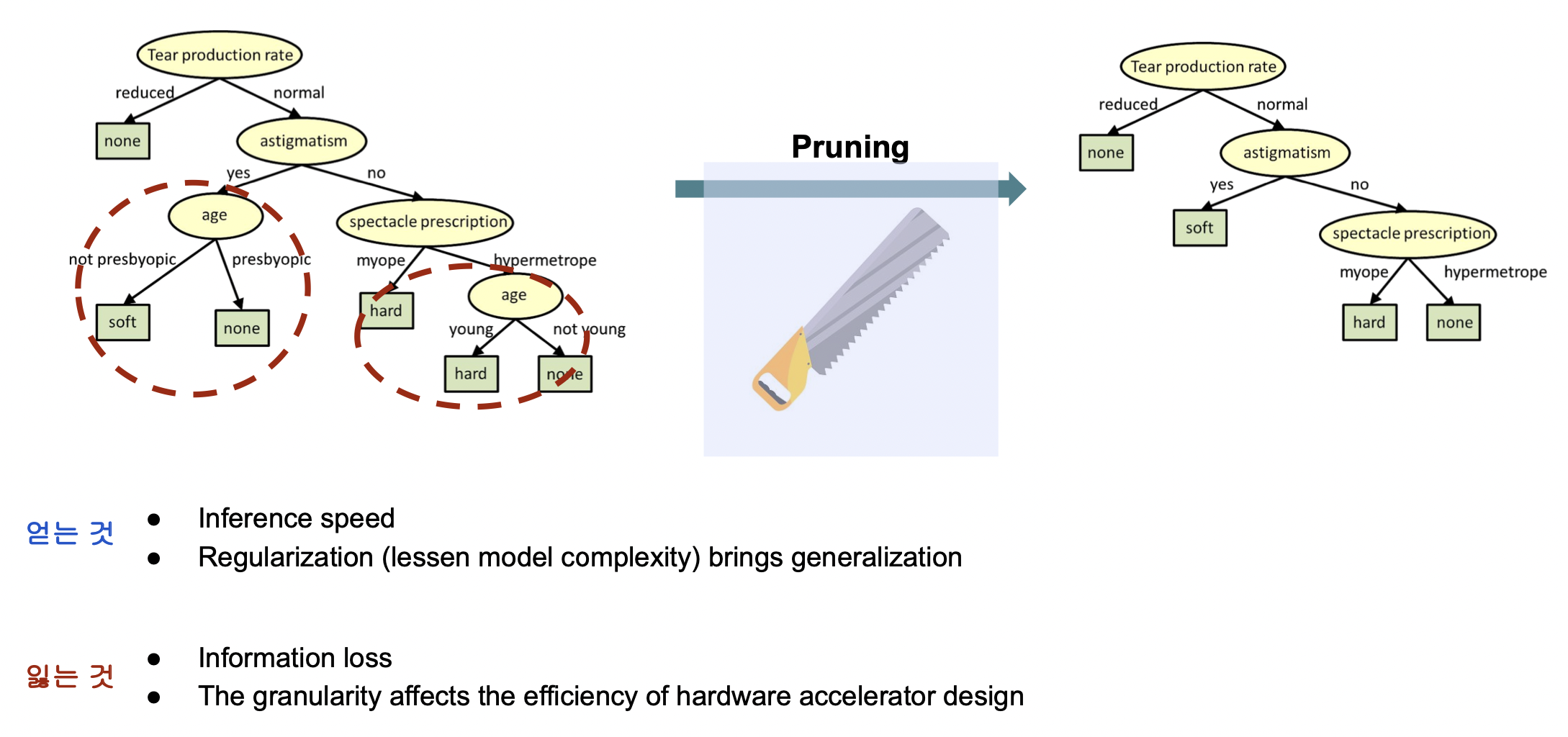
사람과 마찬가지로 많은 뉴런 중 중요한 부분만 선별하여 크기를 줄인다.
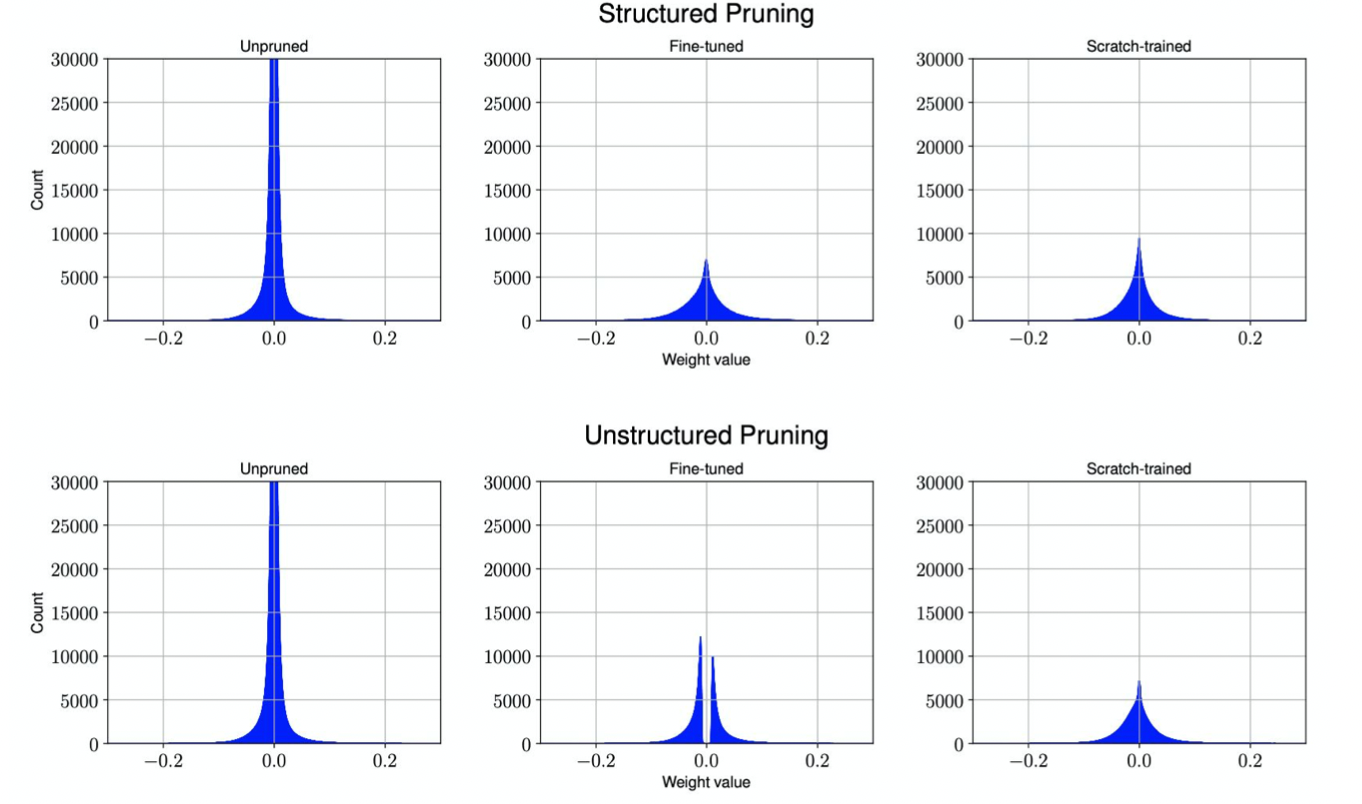
파라미터의 값에 따라 가중치가 적용되기 때문에 아래 pruning 결과 분포와 같이 0 주변의 웨이트들이 많이 사라진 것을 볼 수 있다.
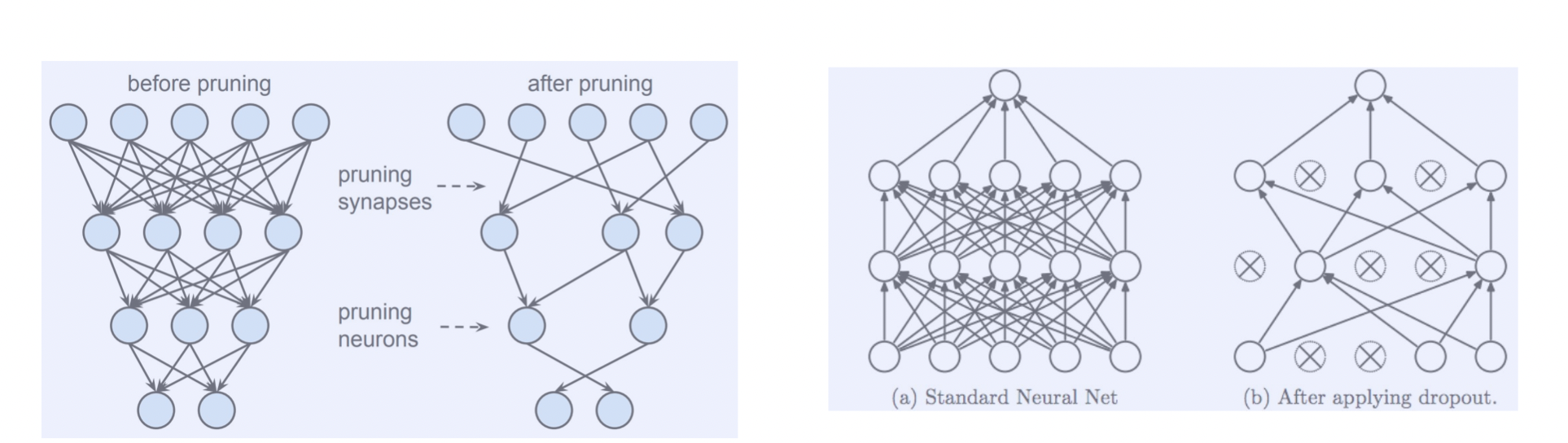
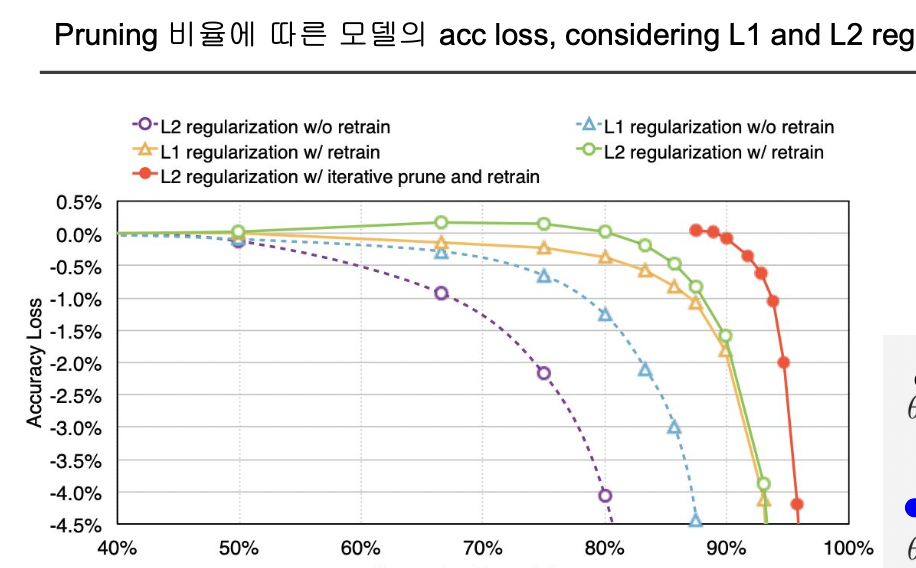
Pruning vs Dropout
pruning 은 잘라낸 웨이트를 다시 사용하지 않지만, dropout 은 이번 에포크에서 사용하지 않은 웨이트라도 다음 텀에서는 사용될 수 있다.
또한 dropout 은 inference 과정에서는 모든 웨이트를 사용한다.
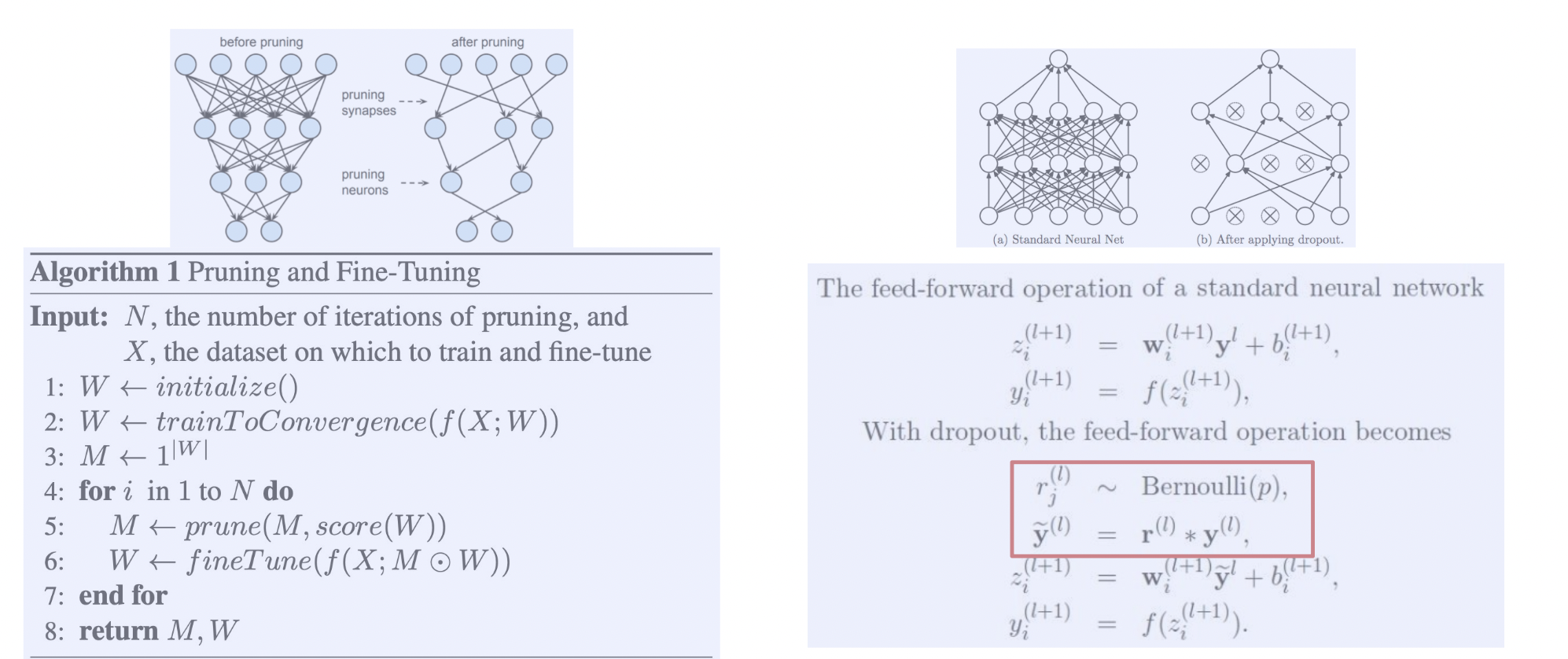
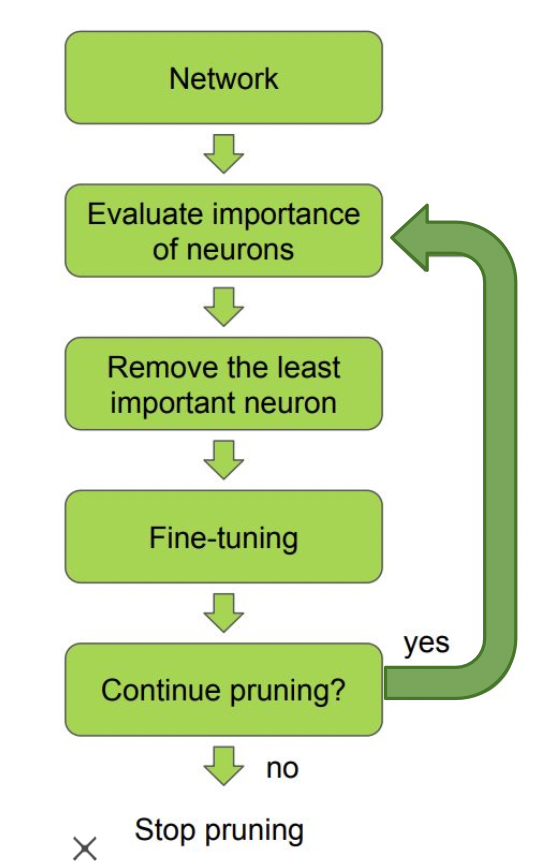
Pruning 학습
pruning 이 적용된 파라미터들로 다시 학습하는 과정을 반복한다. 설정해둔 N 번 만큼 purning & finetune 을 수행한다.
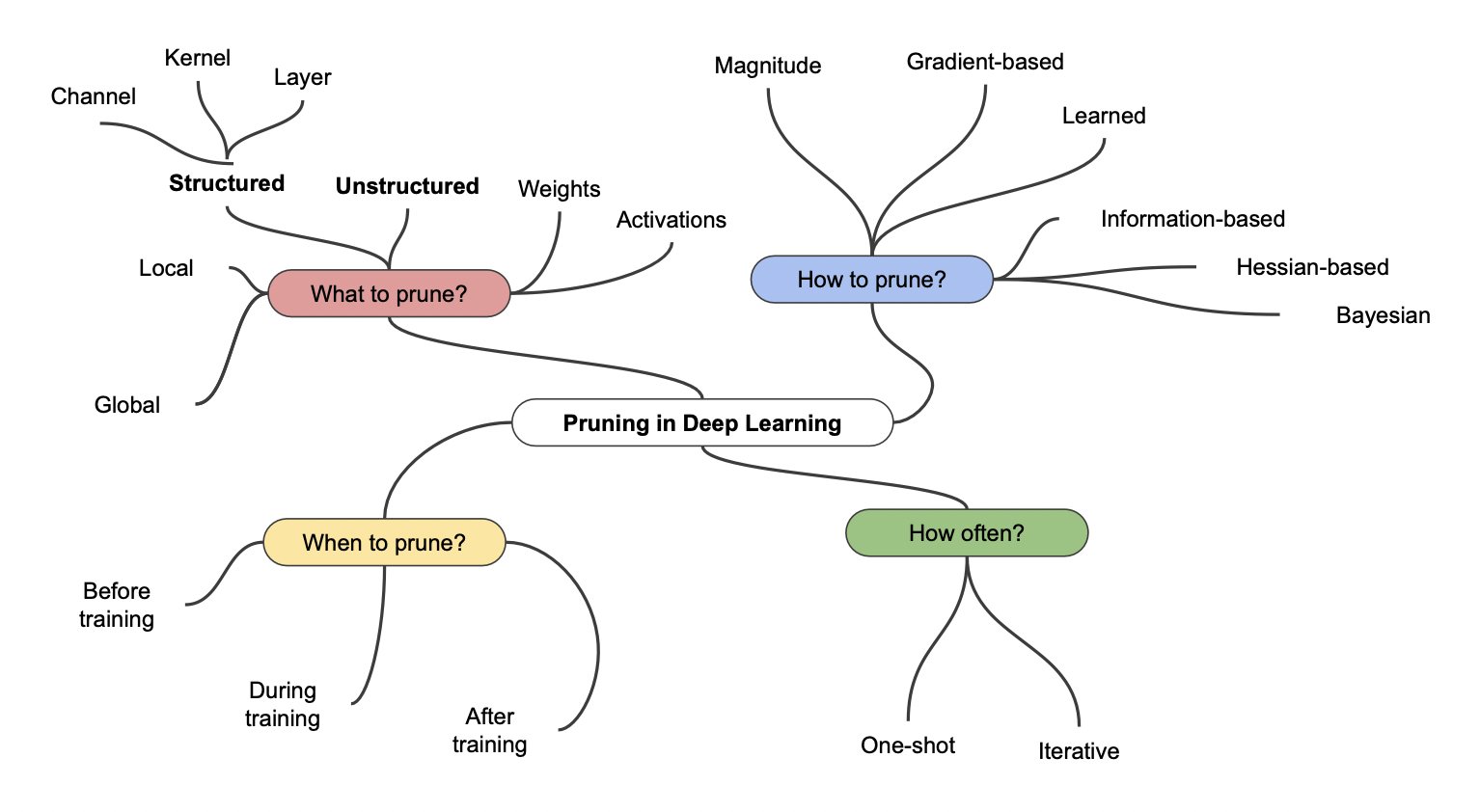
Pruning 결과
iterative pruning 을 적용한 모델은 거의 90% 의 웨이트를 날려버렸음에도 성능차이가 거의 나지 않음을 알 수 있다.
pruning 이 적용된 적은 수의 파라미터로 L1 이나 L2 norm 을 이용한 regularization (파라미터값 낮추기) 을 수행하기 때문에 좋은 성능을 유지할 수 있다.
여러 Pruning 들
Pruning 을 위한 여러 방법들이 있다.
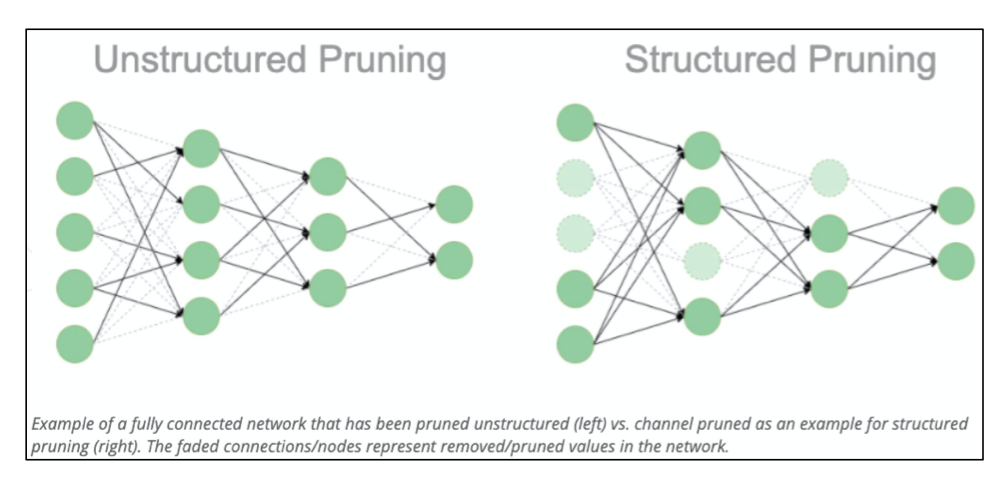
Unstructured Pruning 과 Structured Pruning
Unstructured Pruning 과 Structured Pruning 은 규격 (Filter, Channel, Filter Shape 등) 이 있는 상태로 잘라내냐 아니냐의 차이가 있다.
VGGNet16 에 적용한 결과
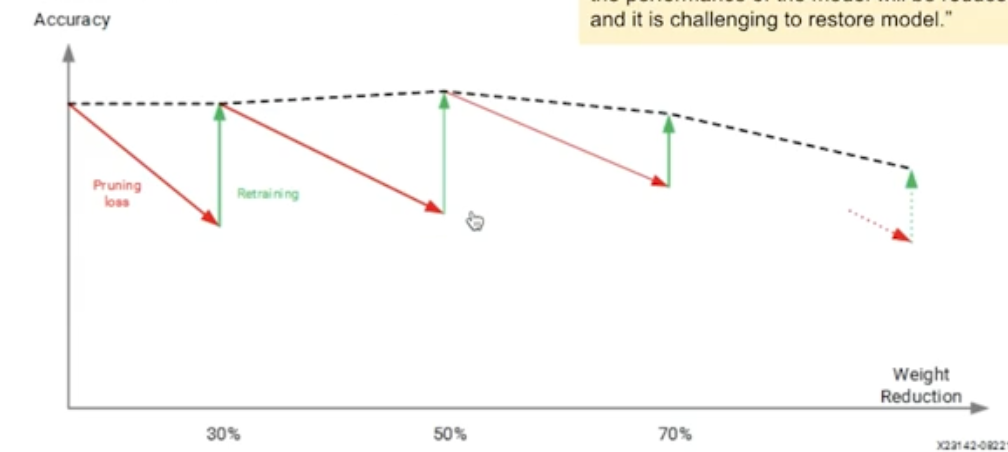
Iterative Pruning 을 하는 이유
한 번에 많은 웨이트를 잘라내면 성능 저하가 생기기 때문에 조금씩 반복적으로 (iterative) 잘라나가야 한다.
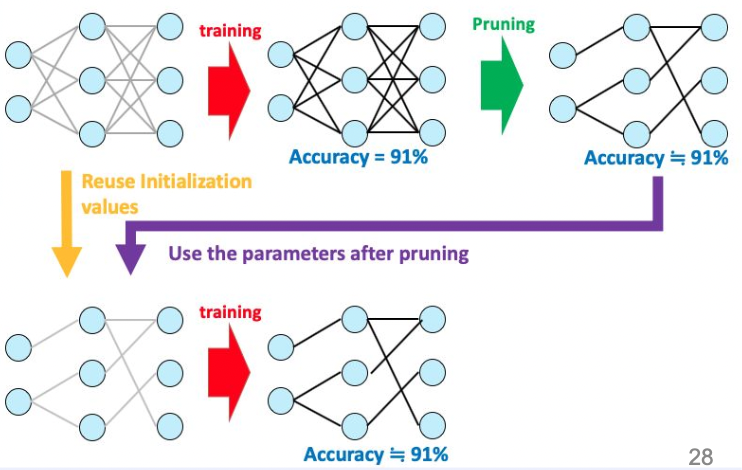
Lottery Ticket Hypothesis
가설이지만 사실이라면 pruning 에서 엄청난 성과를 가져올 가설을 소개한다.
개념
1) 학습된 전체 네트워크를 pruning 하여 원래 정확도와 비슷한 파라미터들을 찾는다.
2) 다시 원래 모델의 초기 상태에, 1) 에서 얻은 파라미터들만 적용시키면 가볍고 좋은 성능을 낼 수 있을 것이다.
즉, 오리지널 네트워크 안에 원래 성능을 유지시키며 epoch 을 덜 도는 서브 네트워크가 존재할 것이라는 가설이다.
문제점
항상 존재하는지는 알 수 없다.
또한 lottery ticket 을 알아내기 위해 너무 큰 비용을 소요해야 한다.
다만, 증명이 된다면 더 쉽게 lottery ticket 를 찾기 위한 노력을 해볼 수 있을 것이다.
lottery ticket 를 찾기 위한 방법
Iterative Magnitude Pruning
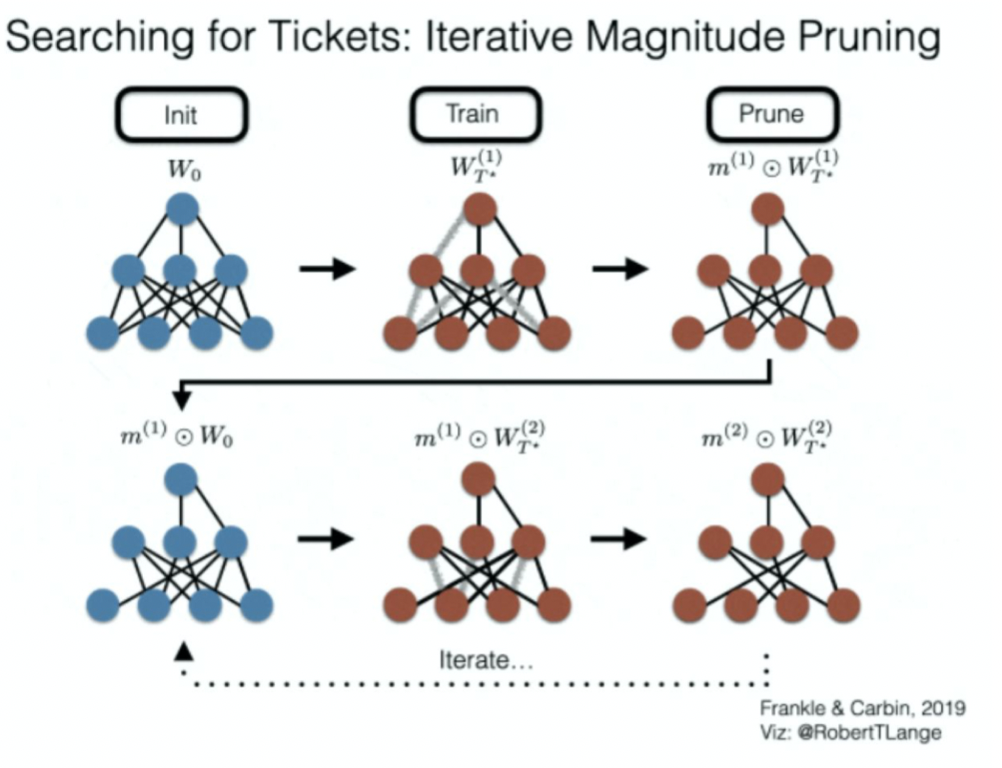
Iterative Magnitude Pruning with Rewinding
조금 배운 상태의 weight 를 가져옴으로써 비용을 절감한다.
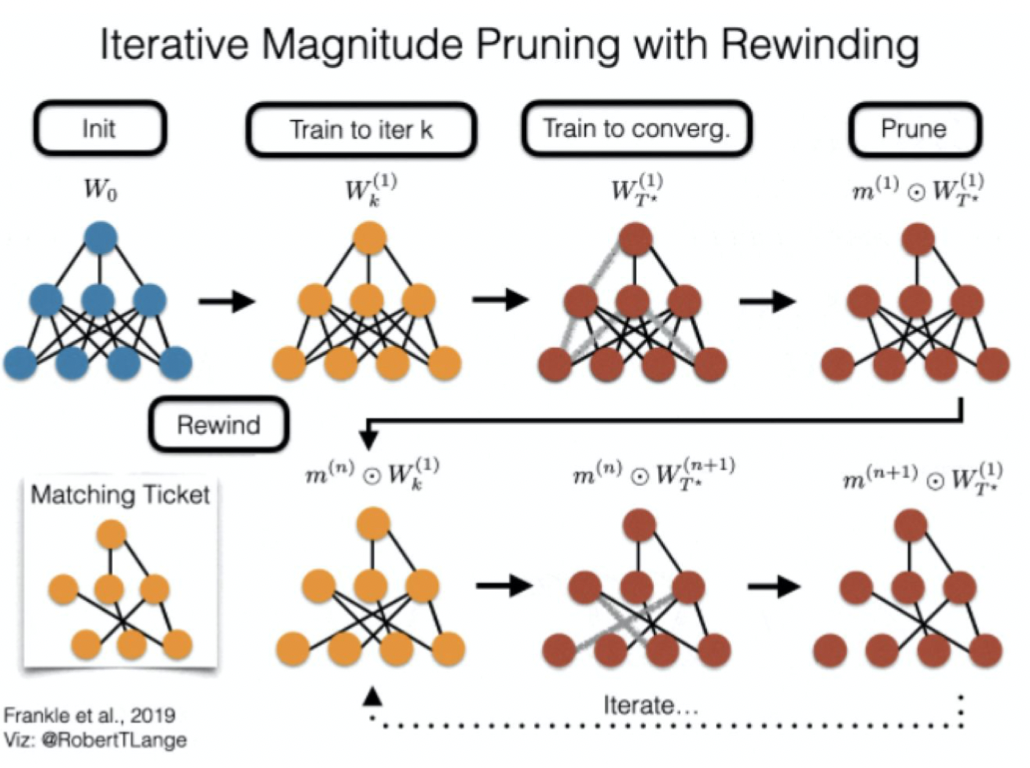
참조
BoostCamp AI Tech
