Acceleration
원래 속도보다 더 빠르게 만들어주는 작업을 가속화라고 한다.
Python list vs Numpy array
파이썬의 리스트는 모든 공간이 다른 공간을 가리킬 수 있는 구조로 되어 있어 여러 데이터 타입을 가질 수 있다는 장점이 있지만 느리고 메모리 소요가 크다.
반면, 넘파이의 어레이는 C 로 구현되어 있어 모든 공간을 하나의 데이터 타입의 크기로 세팅하여 속도가 빠르고 메모리 소요가 작다.
Python vs C
파이썬은 인터프리터 언어로 라인마다 해석을 하는데 비해 C 는 한 번만 컴파일 하기 때문에 더 속도가 빠르다.
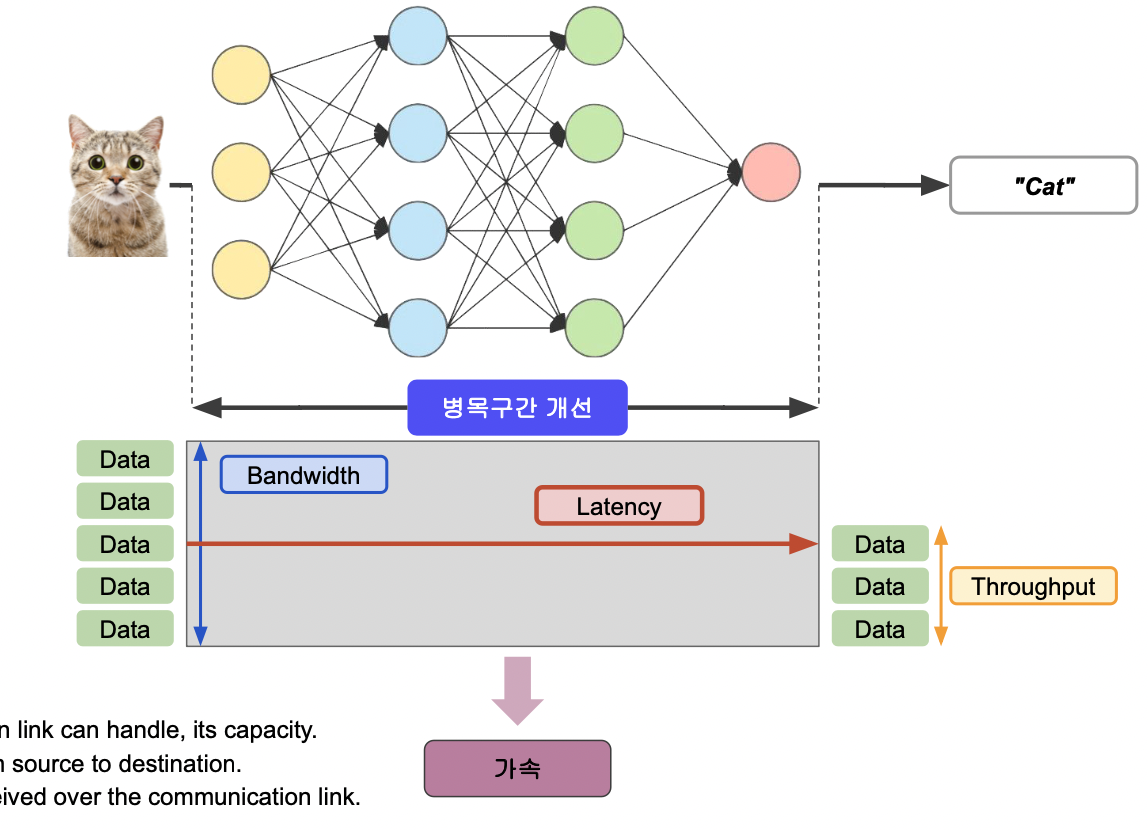
병목 현상
CPU 가 일처리를 할 때 효율적으로 하기 위해서는 막히는 구간, 병목 현상이 없어야 한다.
딥러닝에서도 마찬가지이다.
어느 특정 레이어에 파라미터가 많아서 처리하는데 시간이 오래 걸린다면 이 부분을 손봐서 속도를 높여야 한다.
모델의 가속화는 병목 현상 개선을 통해 이루어진다.
모델에서 병목 현상이 있는 부분은 가장 파라미터가 많은 레이어를 생각해볼 수 있다.
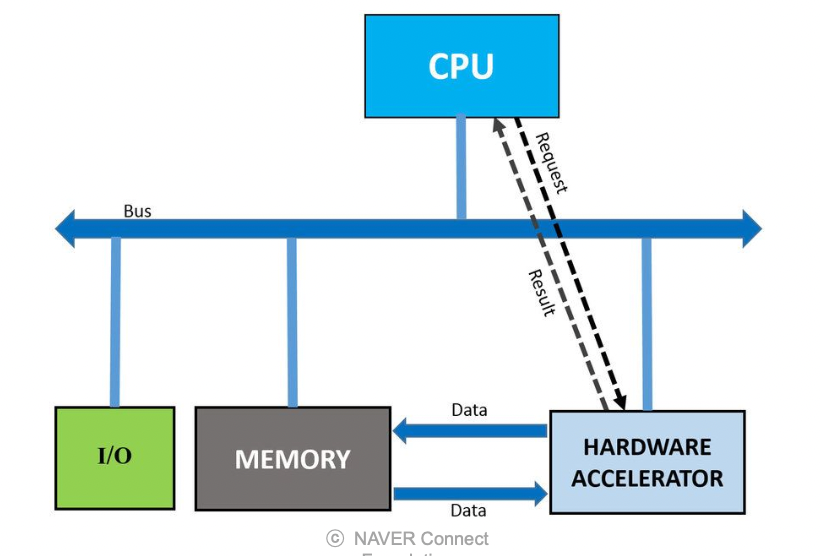
Hardwares (chip) 에서 가속화
가속화는 소프트웨어에서가 아닌 하드웨어에서 latency 를 줄이고 throughput 을 늘리는 작업을 통해 수행된다.
소프트웨어에서 수행되는 작업은 압축 (compress) 이다.
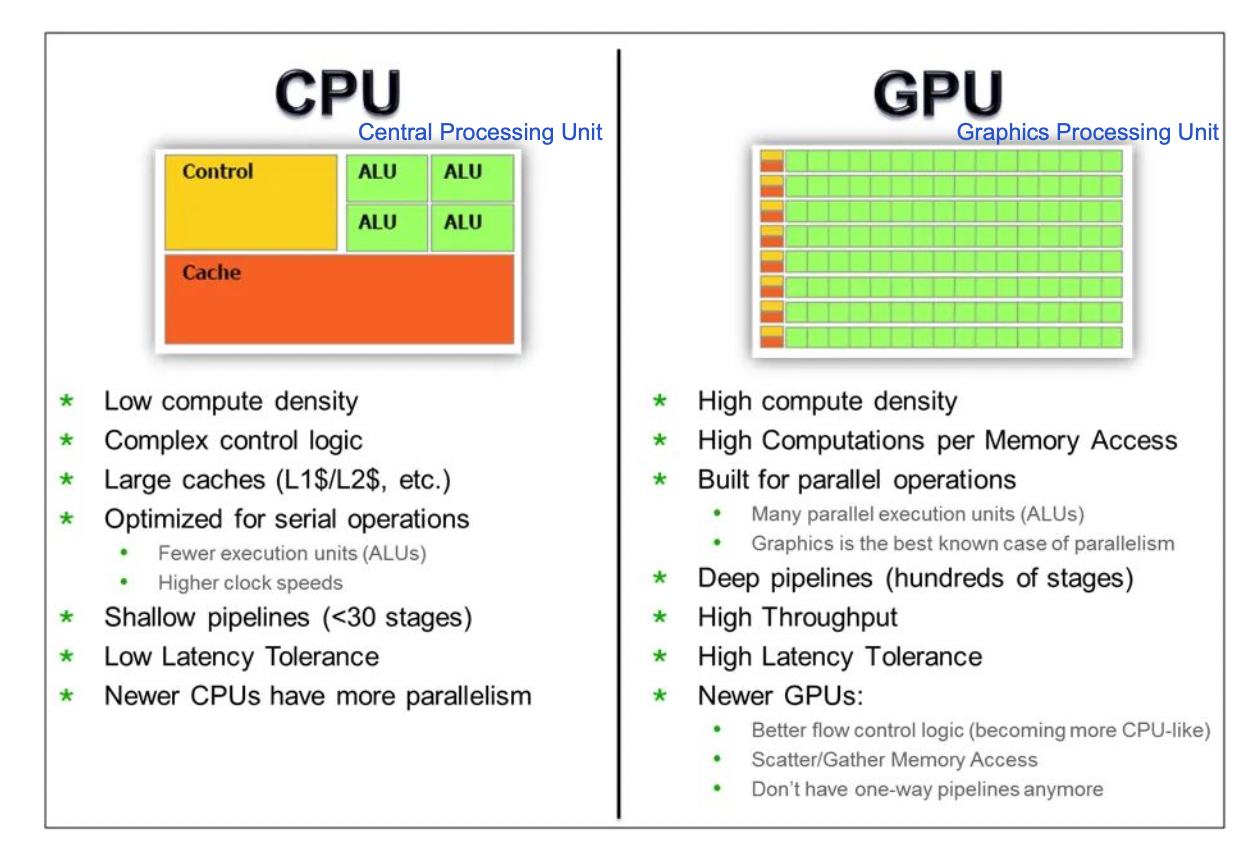
CPU 와 GPU 비교
Compression & Acceleration
비교
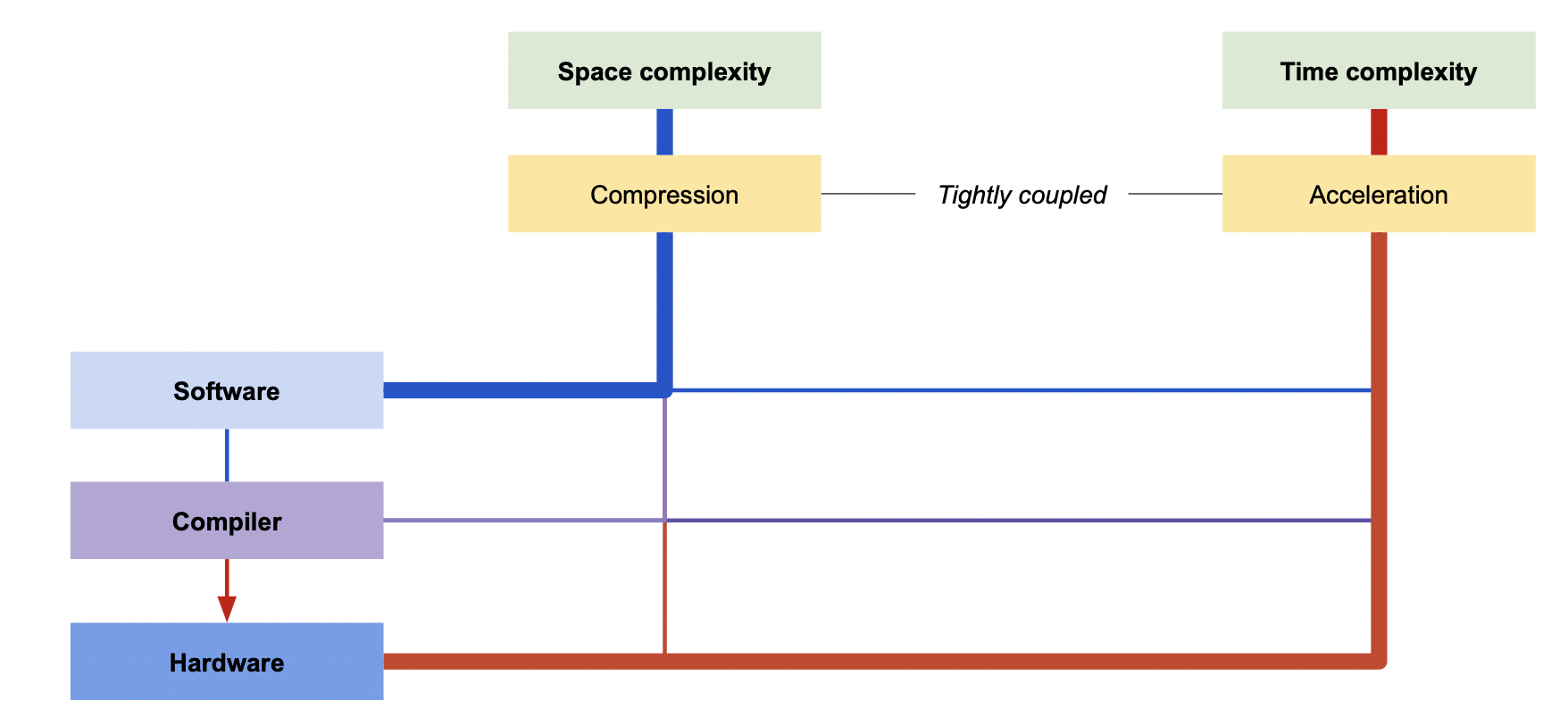
High-level (소프트웨어적으로) 성능 개선을 얘기를 할 때 Compression 을 수행하고,
Low-level (하드웨어적으로) 성능 개선을 얘기를 할 때 Acceleration 을 수행한다.
Hardware 성능과 Acceleration
Hardware 의 성능은 많은 경우 Acceleration 에 초점을 두고 있다.
왜냐하면 컴파일된 어셈블리어가 하드웨어의 processing unit 으로 왔을 때 Acceleration 을 통해 병목 현상 등을 줄이는 것이 곧 하드웨어의 성능이 되기 때문이다.
성능 개선을 위해 tflite 등을 이용하는 소프트웨어적으로만 해결 (Compression) 하기 보다 하드웨어에서도 함께 해결 (Compression + Acceleration) 해야 한다.
https://arxiv.org/pdf/2007.00864.pdf
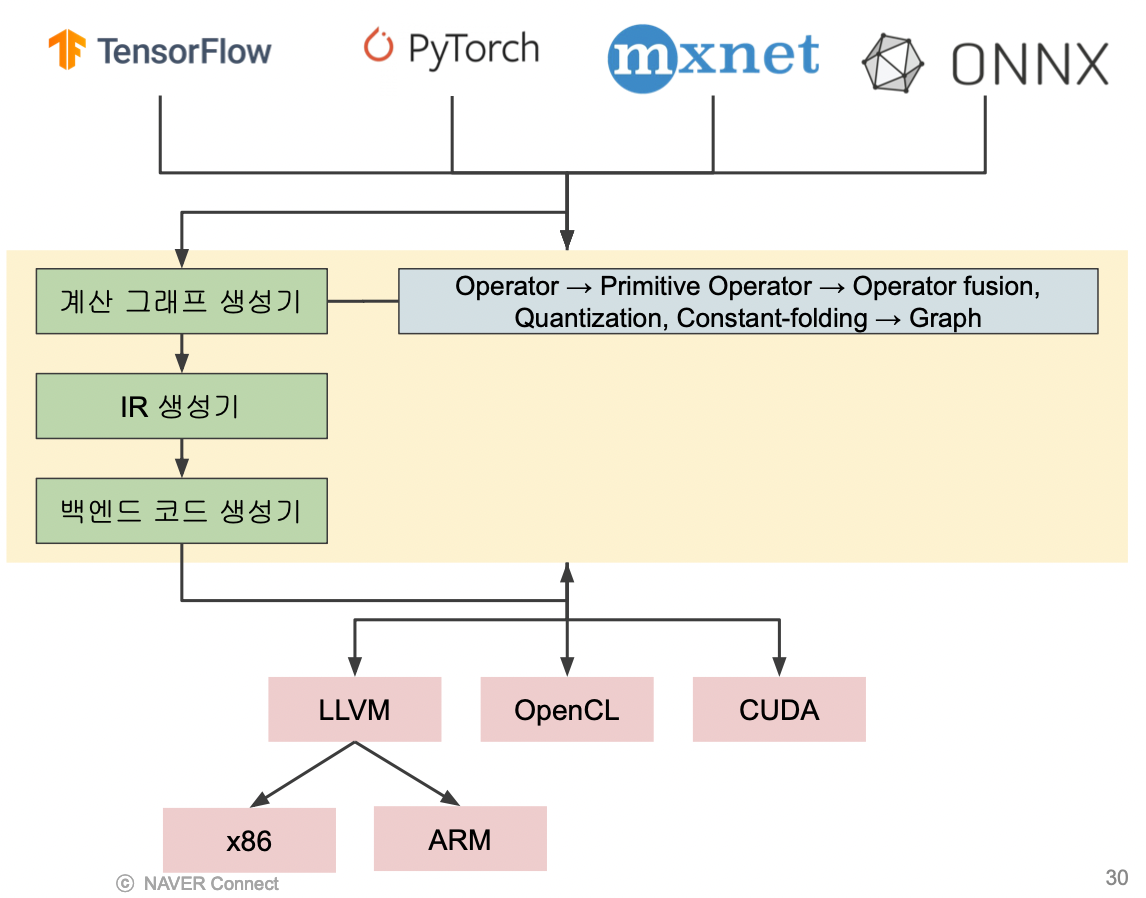
Deep Learning Compiler
개념
DL 컴파일러는 DL 모델 (파이토치, 텐서플로우 등 다양한 프레임워크로 구현된) 을 입력으로 받아서 DL 하드웨어에 최적화된 코드를 생성해준다.
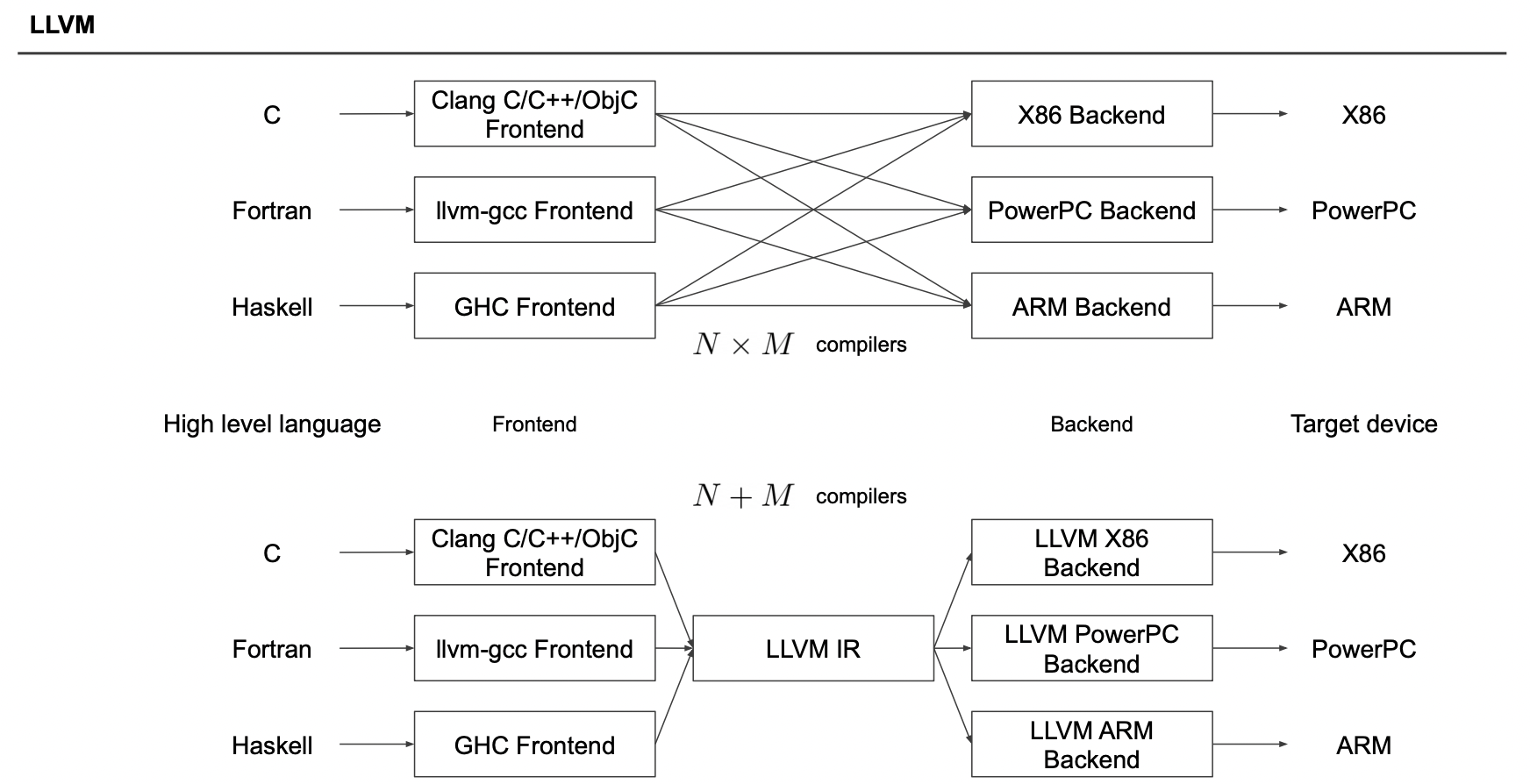
LLVM IR
여러 언어로 쓰인 코드를 여러 CPU 아키텍쳐에 대해 통합적으로 변환해준다.
메모리 효율성을 위한 방법들
Locality of reference
10% 의 코드가 전체 시간 중 90% 를 사용한다.
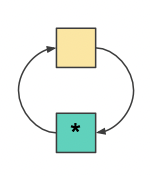
Temporal locality
한 번 참고한 메모리는 다시 참조할 가능성이 높다.
Spatial locality
어떤 지역을 참조하면 이후 그 근처 지역을 참조할 가능성이 높다.
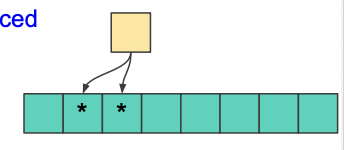
Branch locality
조건문 결과물의 위치는 한 지역으로 제한될 가능성이 높다.
Equidistant locality
반복문을 돌 때는 Spatial + Branch locality 의 성향이 동시에 나타날 가능성이 높다.
Hardware-aware compression
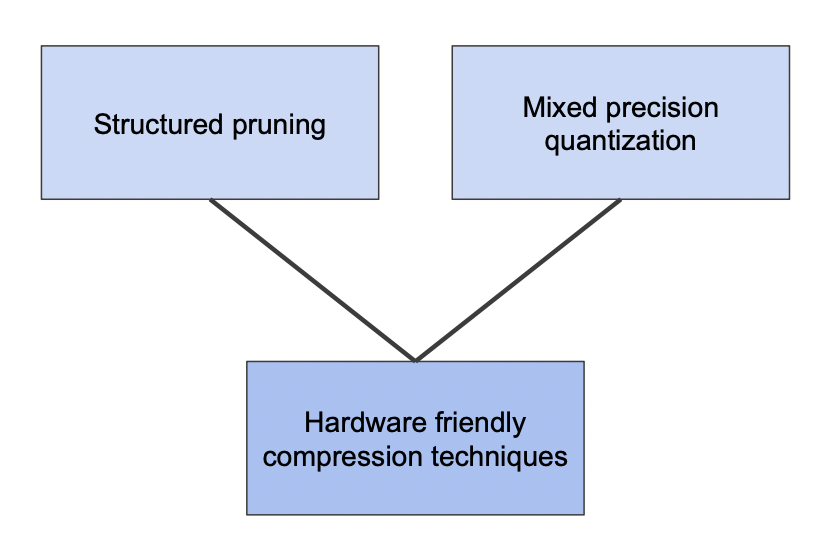
하드웨어친화적인 소프트웨어 압축을 하려면 어떤 레이어는 더 높은 precision, 어떤 레이어는 낮은 precision 를 적용하면 된다.
참조
BoostCamp AI Tech
