Bag-of-Words
- 1 단계 : 문장에서 유니크한 단어들만 vocabulary 에 모음
- 문장 : "John really really loves this movie", "Jane really likes this song"
- Voca : {"John", "really", "loves", "this", "movie", "Jane", "likes", "song"}
- 2 단계 : 사전의 단어들을 one-hot vector 로 인코딩
- 예시
- John : [1 0 0 0 0 0 0 0]
- ...
- song: [0 0 0 0 0 0 0 1]
- 두 단어 사이의 거리는
- 두 단어 사이의 cosine similarity (유사도) 는 0 (두 단어 관계 없음)
- 예시
- 3 단계 : 단어의 one-hot vectors 를 더하여 bag-of-words 생성
- "John really really loves this movie" → [1, 2, 1, 1, 1, 0, 0, 0]
NaiveBayes Classifier 를 활용한 문서 분류



-
한계 : 어떤 단어가 아무리 다른 단어들과 관계가 많더라도 학습 데이터에 없는 단어면 이 단어가 나올 확률은 0 이 되어 분류 성능이 저하된다.
→ 스무딩 사용
Word Embedding 이란?
- 단어를 벡터 (점) 로 표현
- 'cat' 과 'kitty' 는 유사하기 때문에 벡터가 비슷해야 함 → 거리가 가까워야 함
- 'hamburger' 는 위 단어들과 유사하지 않으므로 벡터가 달라야 함 → 거리가 멀어져야 함
Word2Vec
- 가까운 단어들과 관계가 높다고 가정
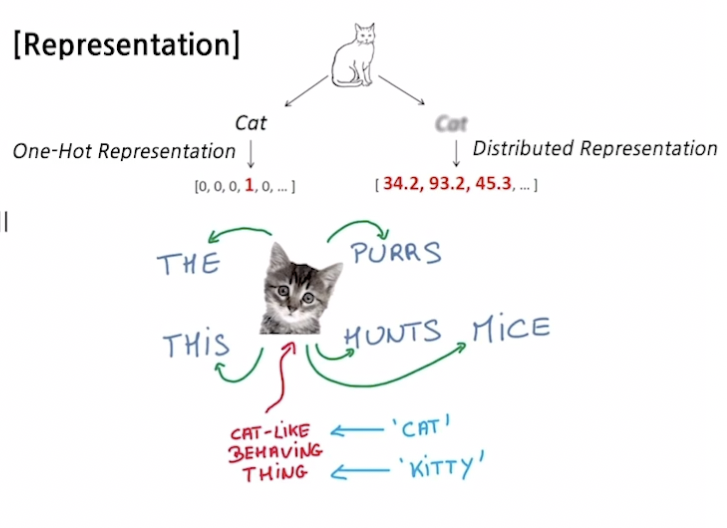
- 1) 문장 내 단어 tokenization
- 2) 유니크한 단어로 사전 구축, 한 단어는 사전 사이즈만큼 크기를 가진 원 핫 벡터가 됨
- 3) sliding window 를 적용하여 한 단어를 중심으로 앞 뒤 단어들과 쌍을 구성함
- I study math → (I, study), (study, I), (study, math), (math, study)
- 입력 레이어의 차원과 출력 레이어의 차원은 같아야 함, 히든 레이어의 차원은 임의 설정 가능
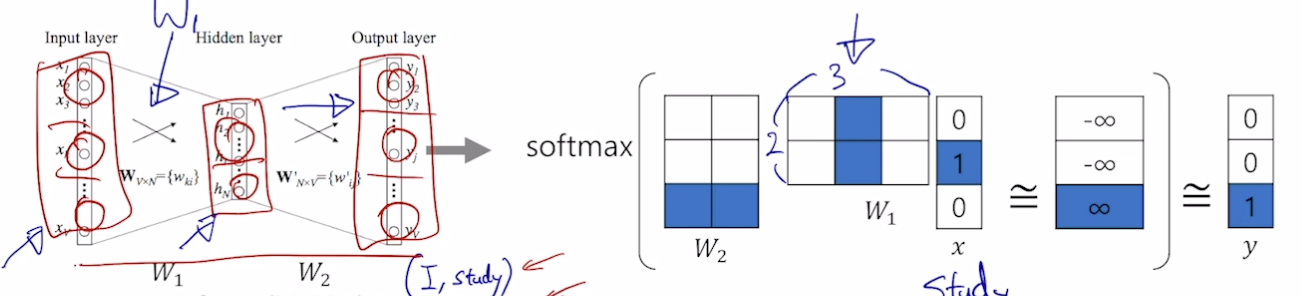

- (study, math) 예시
- 원 핫 벡터이기 때문에 W1 과 W2 의 해당 부분만 활성화됨
- 입력 [0, 1, 0] → [0, 0, 1] 이 됨
- 입력 단어와 출력 단어에 대해 W 가 최대가 되도록 함
- Gradient Descent 를 통해 웨이트 학습

- 수렴된 모습
- 왼쪽의 W 매트릭스를 보면, 입력값 juice 에 대해 drink 가 유사함을 알 수 있음 (내적시 가장 값이 큼)- 일반적으로 W1 (입력 임베딩 웨이트) 를 사용함
- 즉, 학습을 진행할 수록 입력, 출력 웨이트 매트릭스는 두 단어 사이의 관계 (유사도) 를 나타내줌
Property of Word2Vec
- Analogy Reasoning
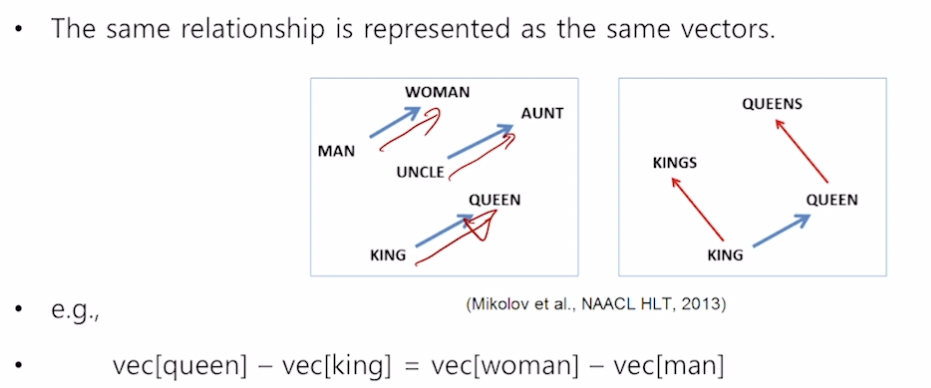
- 한국 - 서울 + 도쿄 = 일본
- Intrusion Detection
- 여러 단어가 주어졌을 때 나머지 단어와 가장 다른 단어 찾기
- 각 단어별로 word 벡터간의 유클리드 거리를 구해서 가장 먼 단어 찾으면 됨
- math, shopping, reading, science → shopping
- Word2Vec 은 NLP 문제들의 성능을 향상시킴
GloVe

- GloVe : Global Vectors for Word Representation
- Word2Vec 과 차이는 두 단어가 얼마나 등장했는지를 사전에 미리 계산하고, 두 단어의 내적 값이 두 단어 등장 횟수에 유사해지게 만들어 줌, 두 알고리즘 적용했을 때 성능 비슷
- 중복이 줄어들어 빠름
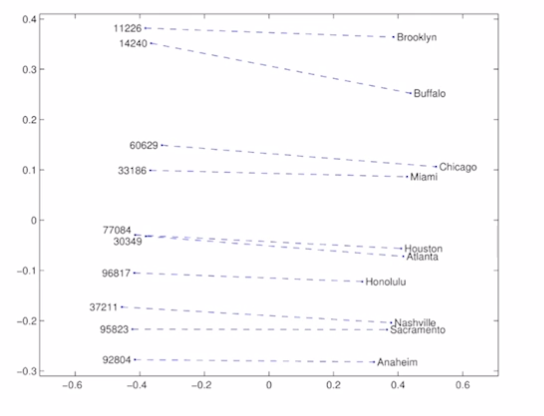
- 두 부류 간의 관계가 일정한 벡터로 나타남
*Word2Vec 과 GloVe 사이트 들어가면 이미 학습된 거 쓸 수 있음
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.