참고
들어가기 앞서 지난 번에 배운 RNN 첫걸음 내용도 참고하자.
Basic of RNNs
- 시퀀스 입력 데이터에 대해 현재 입력 는 이전 입력값들의 계산 결과 와 함께 계산되어 를 뽑아낸다.
- 출력값 y 를 만들기 위해서는 h 에 대해 선형 변환 () 수행, 매 스텝마다 뽑아내야할 수도 있고 아닐 수도 있음 (번역 or 요약 등)
- y 는 스칼라 값을 지닌 벡터이므로 softmax 를 통해 분류 등 수행
- RNN 함수 과 는 모든 스텝에서 동일
- h 의 차원 수는 사전에 정의해야 하는 하이퍼파라미터
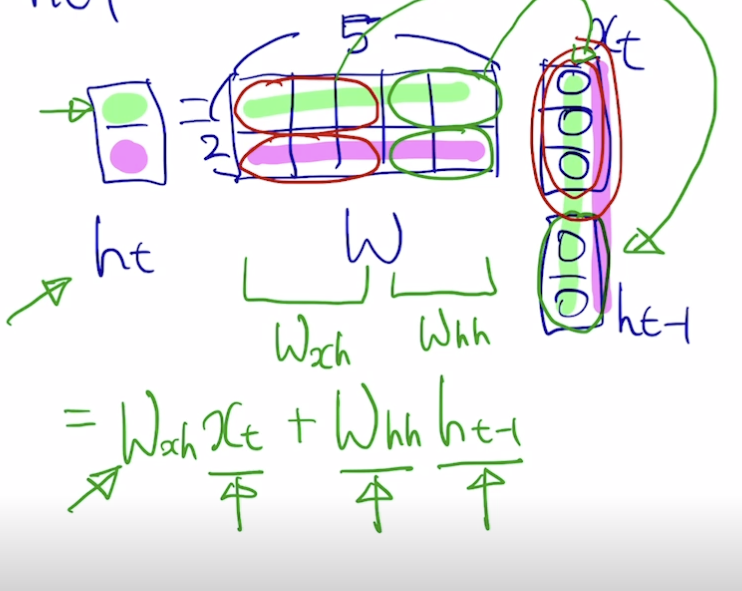
- 는 를 concat 하여 계산한다는 뜻
RNN 종류
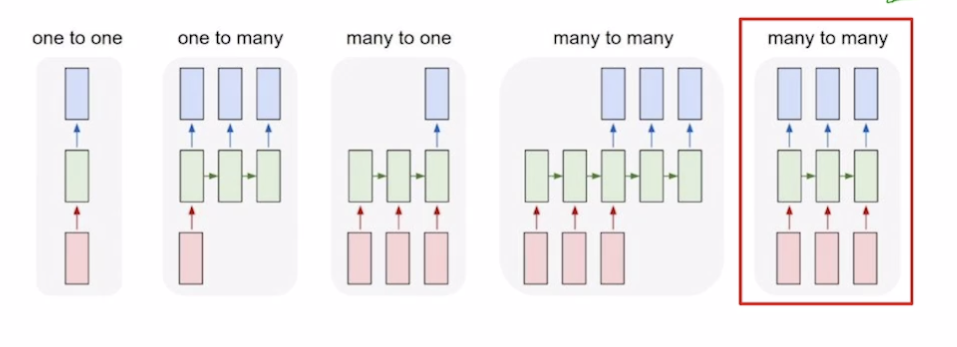
- one to one(RNN x) : 입력 1개, 출력 1개 (시퀀스 x) (점수 예측)
- one to many : 하나의 입력 (첫 스텝 제외, 나머지 스텝에서는 비어있는 입력 넣음) 으로 여러 스텝을 하며 항상 출력
- many to one : 시퀀스 입력을 스텝마다 처리하여 마지막에 결과 출력 (문장 감정 분석)
- many to many
- 시퀀스 입력과 여러 출력 (문장 번역)
- 입력, 출력 1대1 대응 (단어 품사 분석, 영상 프레임마다 어떤 장면인지 분석 등)
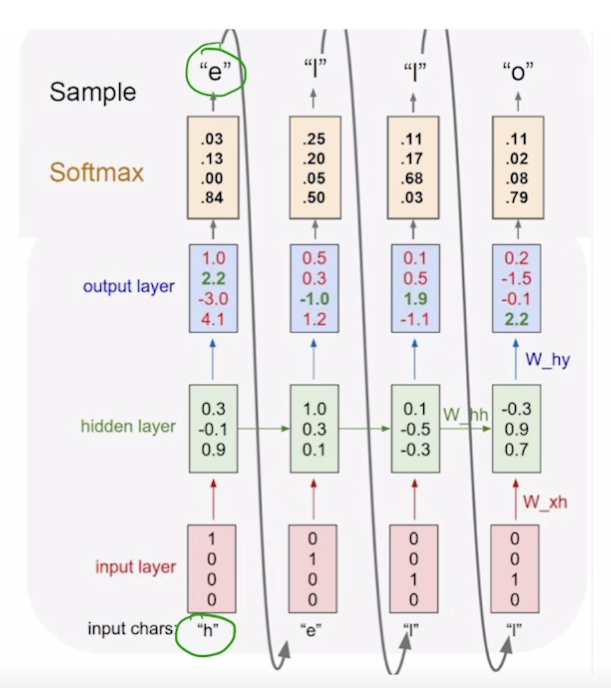
Character-level Language Model
- "hello" 단어에서 각 문자에 대해 다음 문자 예측 수행
- vocab : [h, e, l, o]
- [1, 0, 0, 0], ..., [0, 0, 0, 1]
- h→e, ... l→o
- many to many
- softmax(y_hat) 와 y 의 차를 loss 로 두어 backpropagation 수행
- inference
BPTT
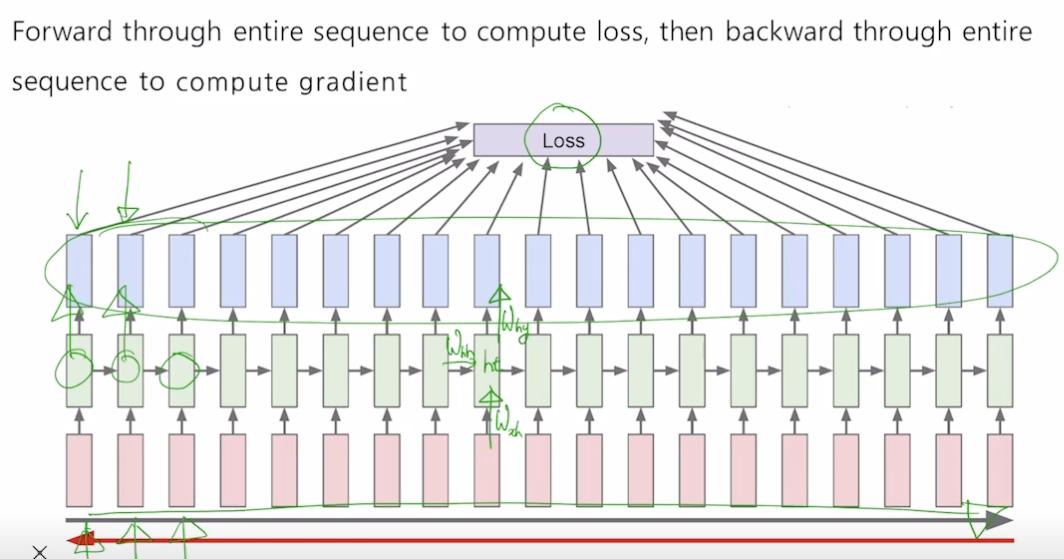
- RNN 과정이 많이 반복될 수록 backpropagation 수행 시간 많이 소요
- truncated, 특정 크기만큼만 backpropagetion 수행
How RNN Works
- If statement cell

- if 뒤에는 빨간색이 됨, 저 부분을 담당하는 특정 dim 이 학습되었음
Vanishing/Exploding Gradient Problem in RNN
- 백프로파게이션할 때 같은 매트릭스를 매 스텝마다 곱하면 grad 가 사라지거나 넘침

- h3 을 h1 에 대해 편미분해서 내려가다 보면, 3 이 계속 곱해짐. 를 계속 곱하게 됨.
- 학습이 잘 안 됨
Further Reading
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.