딥러닝 학습방법 이해하기
신경망은 기본적으로 비선형 모델.
이를 자세히 살펴보면 선형모델과 비선형 함수들의 결합으로 이루어짐.
비선형 모델을 어떻게 선형 모델로 만들어내는지 알 것!
선형 모델
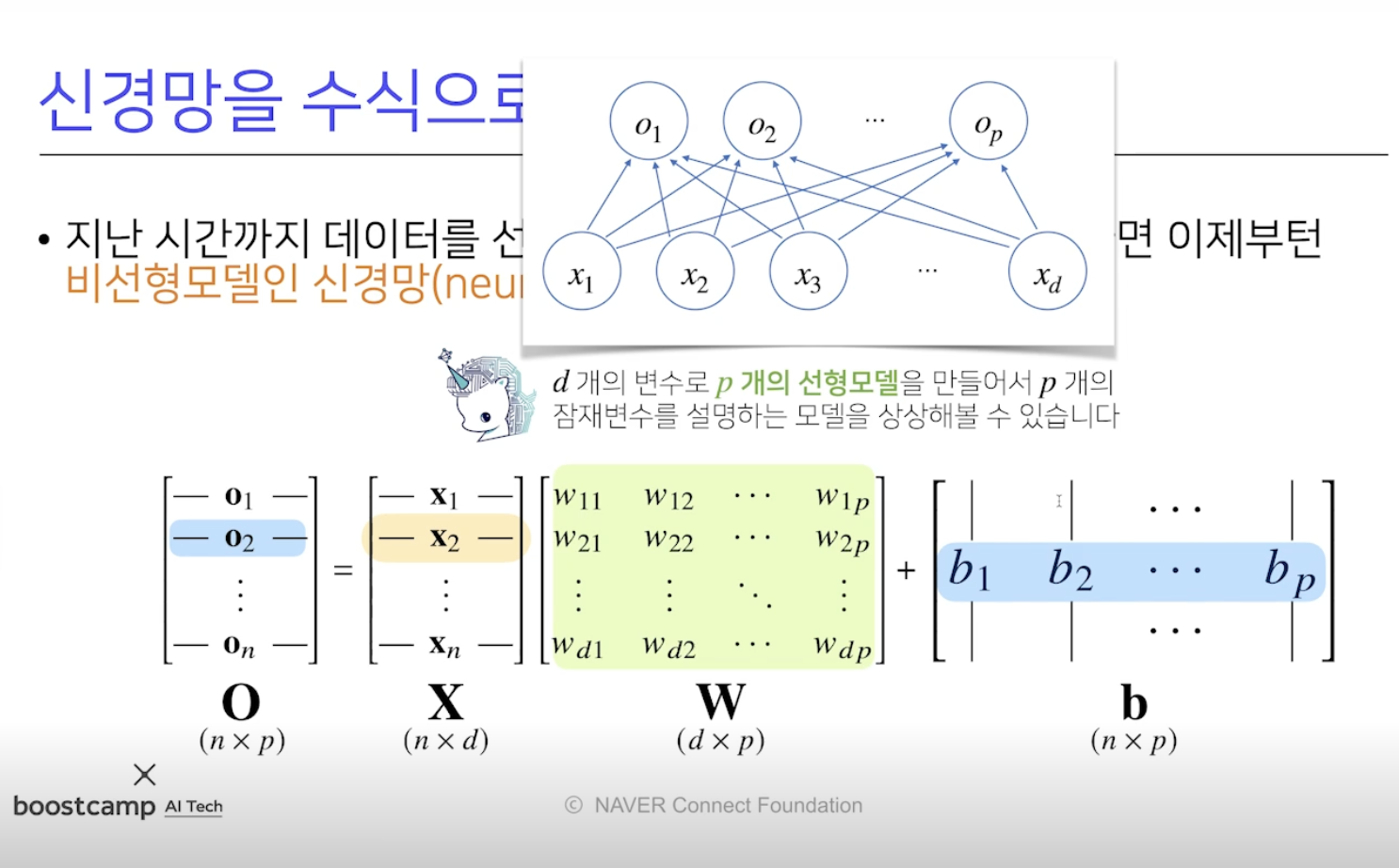
- O(n x p) = X(n x d)W(d x p) + b(n x p)
- X : 데이터 행렬, W : X 의 각 데이터를 다른 공간으로 보내주는 가중치 행렬
- b 는 각 행들이 같은 값을 지님 (y 절편 벡터)
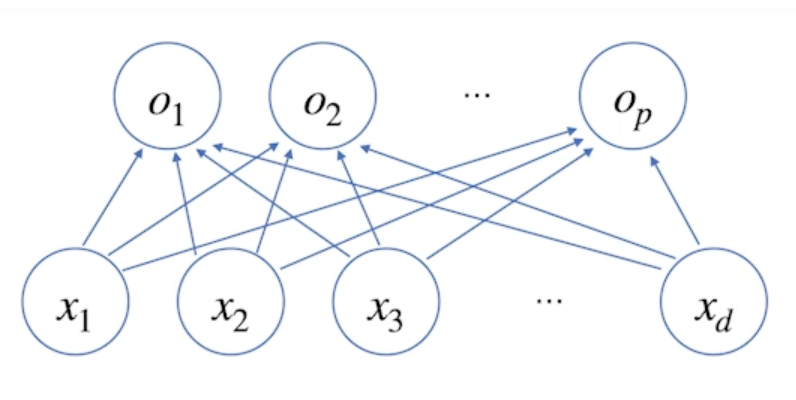
- 아래 그림과 같이 각 데이터 x 는 각 결과 o 에 대해 화살표로 연결됨
→ 화살표는 x 를 o 로 연결하는 W (웨이트) 라고 생각하면 됨
→ d 개가 p 개로 가므로 W 는 d x p 개가 있음
- W 는 d 개의 변수로 p 개의 선형모델을 만들어서 p 개의 잠재변수를 설명하는 모델
Softmax
- 분류 문제에서 모델 (비선형 모델) 의 출력을 확률로 해석할 수 있게 변환해주는 연산, 데이터가 어떤 클래스에 속하는지 분류
- 분류 문제에서 선형모델과 소프트맥스 함수 결합하여 예측
def softmax(vec):
denumerator = np.exp(vec = np.max(vec, axis=-1, keepdims=True)
numerator = np.sum(denumerator, axis=-1, keepdims=True)
val = denumerator / numerator
return val- 학습에는 소프트맥스가 필요하지만, 추론(실전) 할 때는 소프트맥스 말고 one_hot 벡터로 (최대값을 가진 주소만 1 로 출력하는 연산) 사용
신경망
- 선형모델과 활성함수를 합성한 함수 = 히든벡터
- 활성함수와 소프트맥스 차이 : 소프트맥스는 출력물 모든 값 고려해서 출력 - 벡터를 받음, 활성함수는 하나의 주소만 고려해서 출력 - 실수값 1 개만 받음
활성함수
- 실수를 받아서 실수를 반환
- 활성함수를 쓰지 않으면 선형모델임, 활성함수 써야 비선형으로 바뀜
- 시그모이드나 tanh 를 예전에 썼지만, 이제는 ReLU 함수 사용
- z 행렬의 모든 원소에 활성함수 씌움 (실수를 받기 때문에)
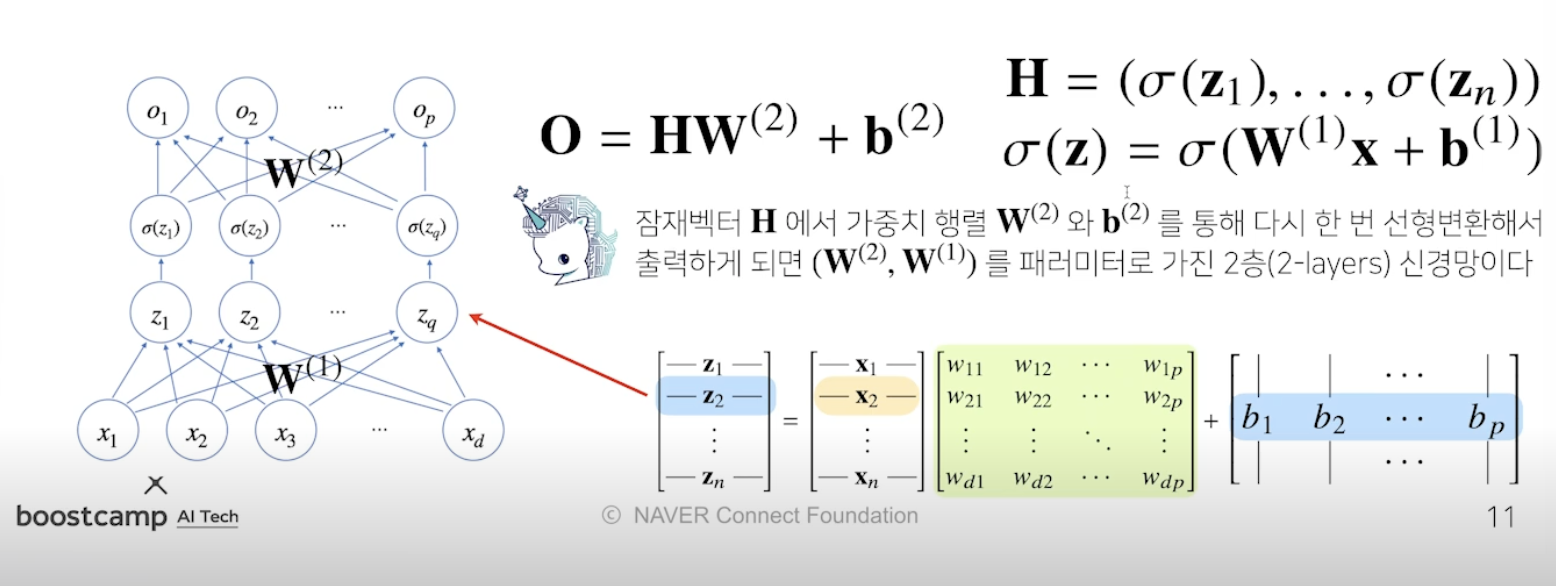
신경망 수식
-
2-layer 신경망 : x → z 에서 W1, 활성함수(시그마)(z) → o 에서 W2 사용
-
위 구조를 반복적으로 사용하면 multi-layer perceptron, MLP 신경망이 됨
-
위 작업은 Forward propagation!
-
왜 층을 여러개 쌓나요?
- 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드) 의 숫자가 훨씬 빨리 줄어들어 더 효율적인 학습 가능 → 층이 얇으면 넓은 신경망이 돼야함
- 층이 깊으면 복잡한 함수 표현은 가능하지만, 최적화는 더 어려워짐 (나중에 convolution 에서 residual 배울 것)
딥러닝 학습원리: 역전파 알고리즘
- 순전파는 선형모델에 활성함수 썼었음
- 역전파는 학습에서 경사하강법을 써야하는데 이 때 가중치를 업데이트함에 있어 합성함수를 다뤄서 최초의 가중치를 구할 수 있게 해줌
- 윗 층의 그레디언트를 구하여 다음층, 다음층 역순으로 전달함

역전파 원리 이해하기
- 합성함수 미분법인 연쇄법칙(체인룰) 기반 자동미분 사용

→ 모든 변수에 대해 편미분을 저장해야함 → 순전파보다 메모리 많이 사용
- 예제

- 파란색 : 순전파, 빨간색 : 역전파
- 역전파 결과값부터해서 W1까지 연쇄법칙 사용
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.