압축 (Compression)
자료를 압축하면 가벼워진다.
압축에는 손실 압축 (.jpg, .gif, mp4 등) 과 비손실 압축 (.zip, .png, .wav 등) 이 있다.
손실 압축은 압축된 자료에서 다시 원래 자료로 돌아갈 수 없는 대신 크기가 더 작고, 비손실 압축은 반대이다.
압축률
압축 전의 크기 / 압축 후의 크기
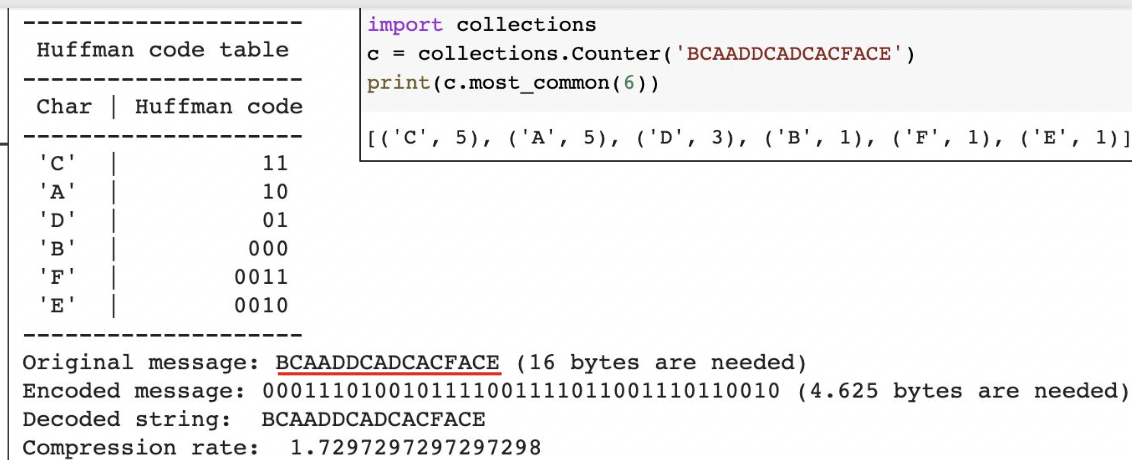
Huffman coding
유명한 압축 방법 중 하나이다.
문자열에서 많이 나온 단어를 적은 비트 수로 저장하고, 적게 나온 단어는 긴 비트로 저장하여 압축한다.
부호 (Coding)
코딩 (부호화) 은 어떤 규칙을 통해 사람의 언어를 컴퓨터가 이해할 수 있게 변환하는 과정을 말한다.
이 때, 변환 후 메세지의 크기가 변환 전 메세지의 크기보다 작다면 압축했다고 볼 수 있다.
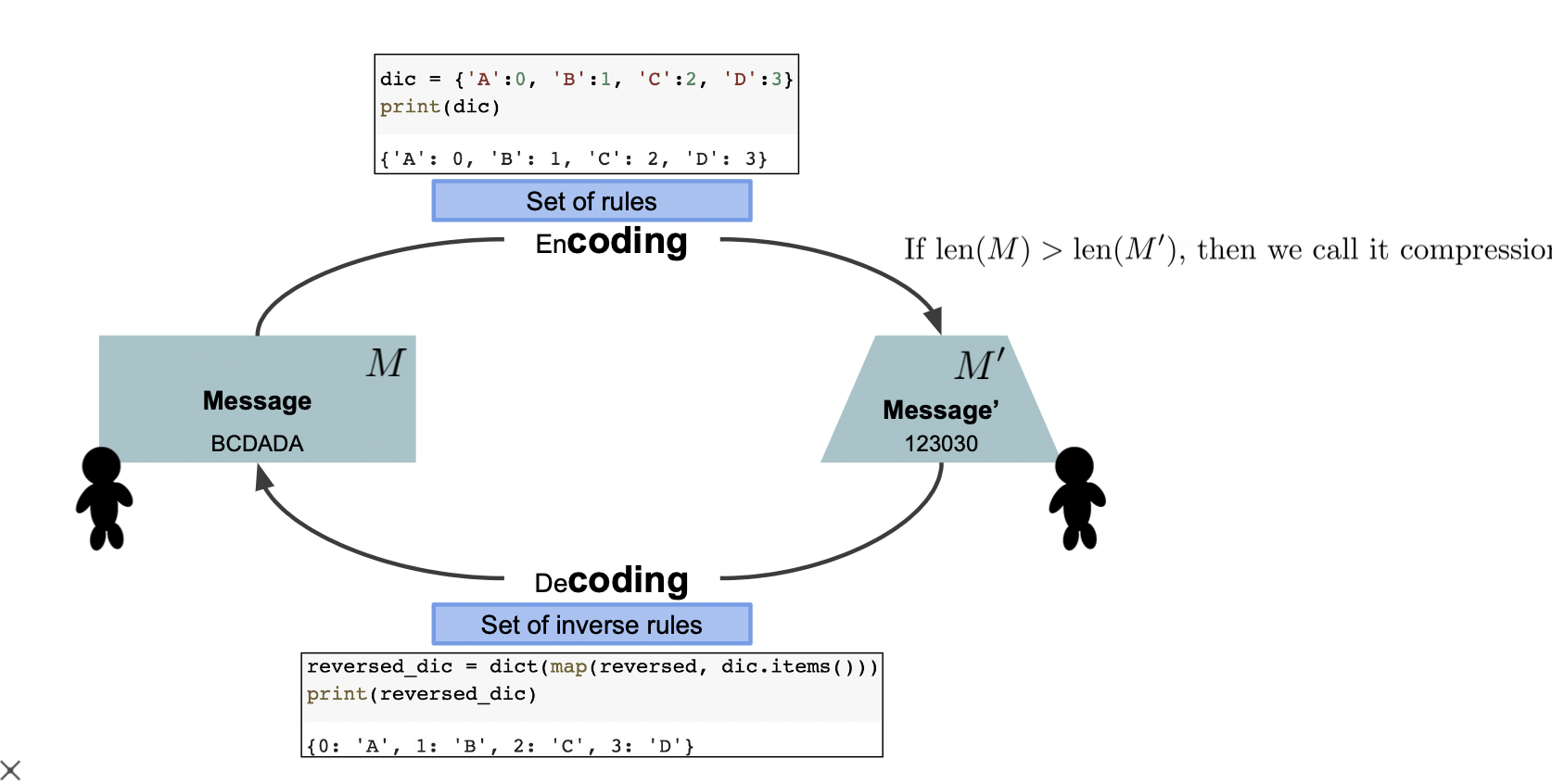
다시 말해, 코딩이라는 것은 공통된 언어 (컴파일을 거치면 컴퓨터와 사람이 모두 알아들을 수 있다는 뜻) 로 사람의 메세지를 컴퓨터가 이해하여 결과를 가져오는 것 (결정) 을 의미한다.
사람이 돼지를 먹고 소화하는 것 (이들은 모두 단백질로 이루어짐) 과 비슷하다고 볼 수 있다.
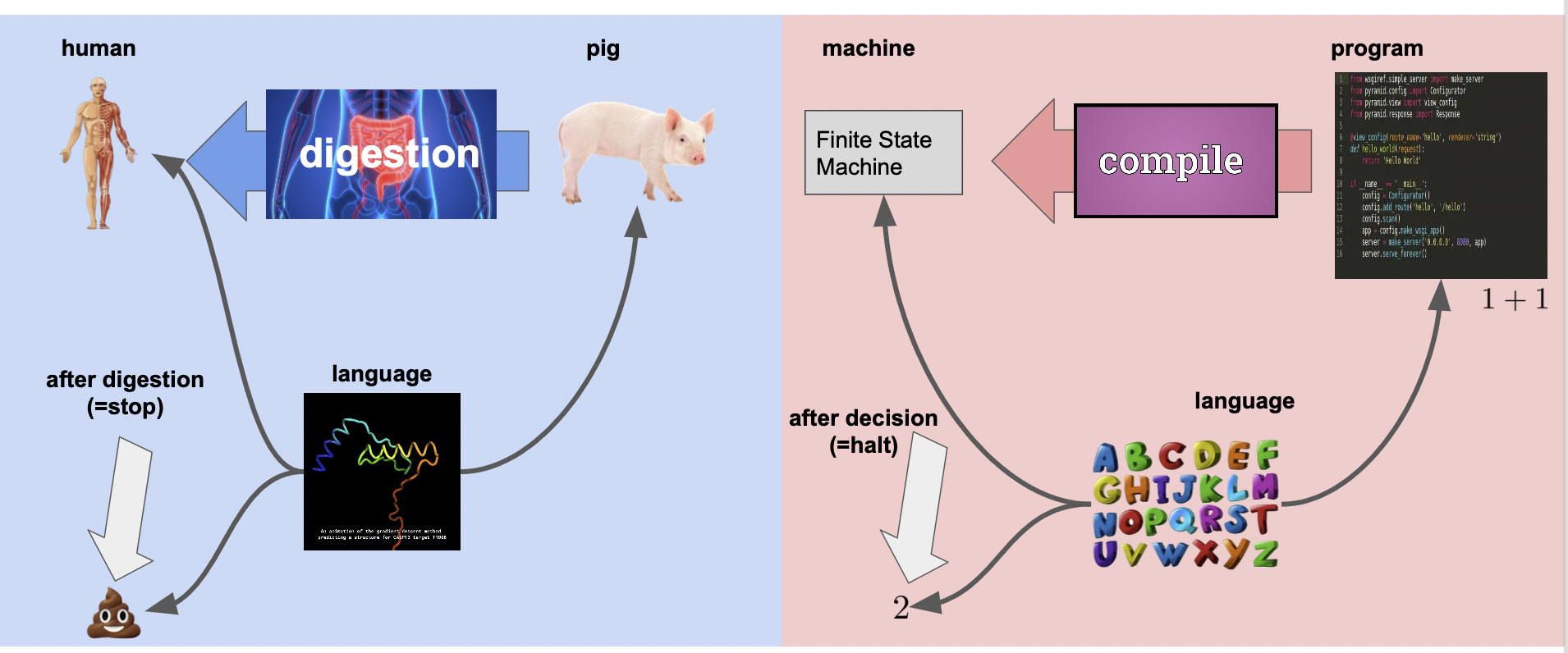
부호화 (Encoding)
Cross-entropy
Cross-entropy 는 두 확률 분포 P (정답), Q (예측) 가 얼만큼 다른지 알 수 있는 지표로 사용될 수 있다.
entropy 는 P 의 코드북으로 P 메세지를 인코딩한 것을 말한다.
머신러닝 적용
머신러닝에서 우리는 Q (예측) 를 최대한 P (정답) 에 근사하려는 목적이 있기 때문에
Q 의 코드북 (인코딩을 위한 일종의 dict, "a" -> 00, "b" -> 01) 으로 P 라는 메세지를 인코딩해야한다.
이 때 사용되는 것이 Cross-entropy 이다.
P 에 대한 Q 분포를 최대한 근사시키기 위해 사용한다.
더 구체적으로는 KL-divergence (Cross-entropy - entropy) 를 사용한다.
KL-divergence = Q 라는 코드북으로 P 를 인코딩했을 때의 무질서도 - P 라는 코드북으로 P 를 인코딩했을 때의 무질서도
-> 이를 loss 로 두고 최소화시키는 과정에서 Q 가 P 에 근사된다.
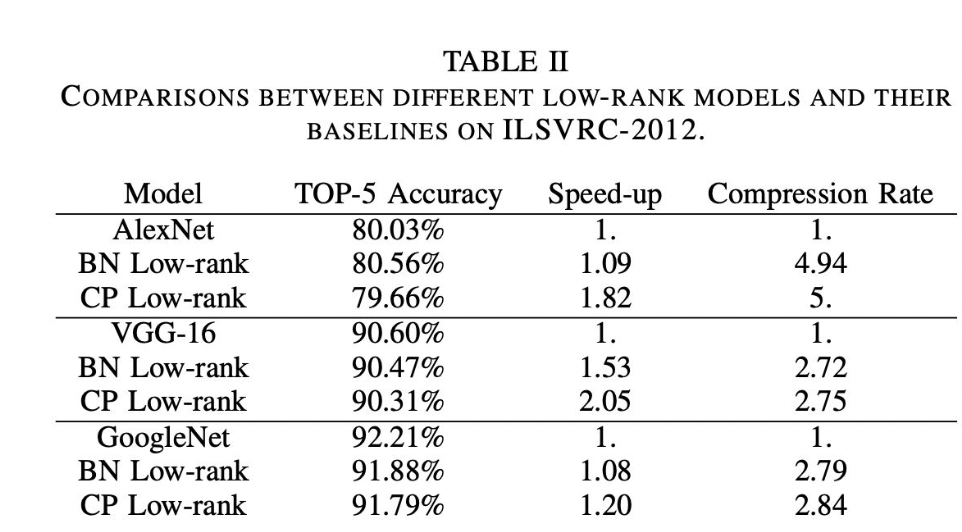
압축률 (Compression rate)
압축률은 압축 전의 크기 / 압축 후의 크기로 필요한 정보량 (파라미터) 이 얼만큼 줄었는지를 확인할 수 있다.
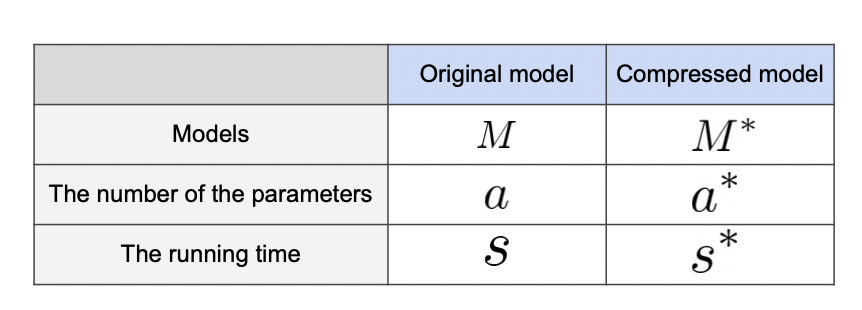

아래와 같은 표를 볼 때, 모델의 성능을 정확도 뿐만 아니라 속도와 압축률을 통해 비교할 수 있다.
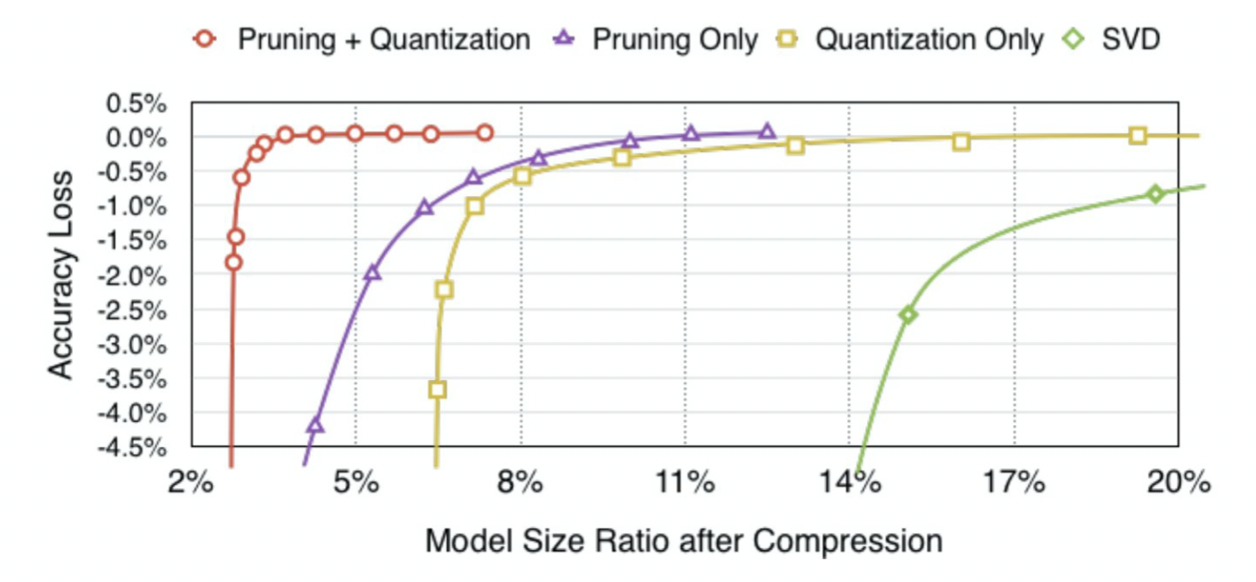
최적의 조합
Pruning + Quantization 을 했을 때 파라미터 수는 2% 로 매우 적어졌지만 정확도는 거의 유지되는 성능을 보여줬다.
참조
BoostCamp AI Tech
