개요
Factorization 를 통해 어떤 효과를 얻을 수 있을까?
행렬 (Matrix) 의 세가지 특성
Map1 : Matrix (Tensor) is a data modeling tool
2 차원 행렬 Matrix 와 3 차원 이상 행렬 Tensor 는 data 를 나타내고 처리할 수 있는 도구이다.
행렬과 텐서는 다양한 분해가 가능하다.
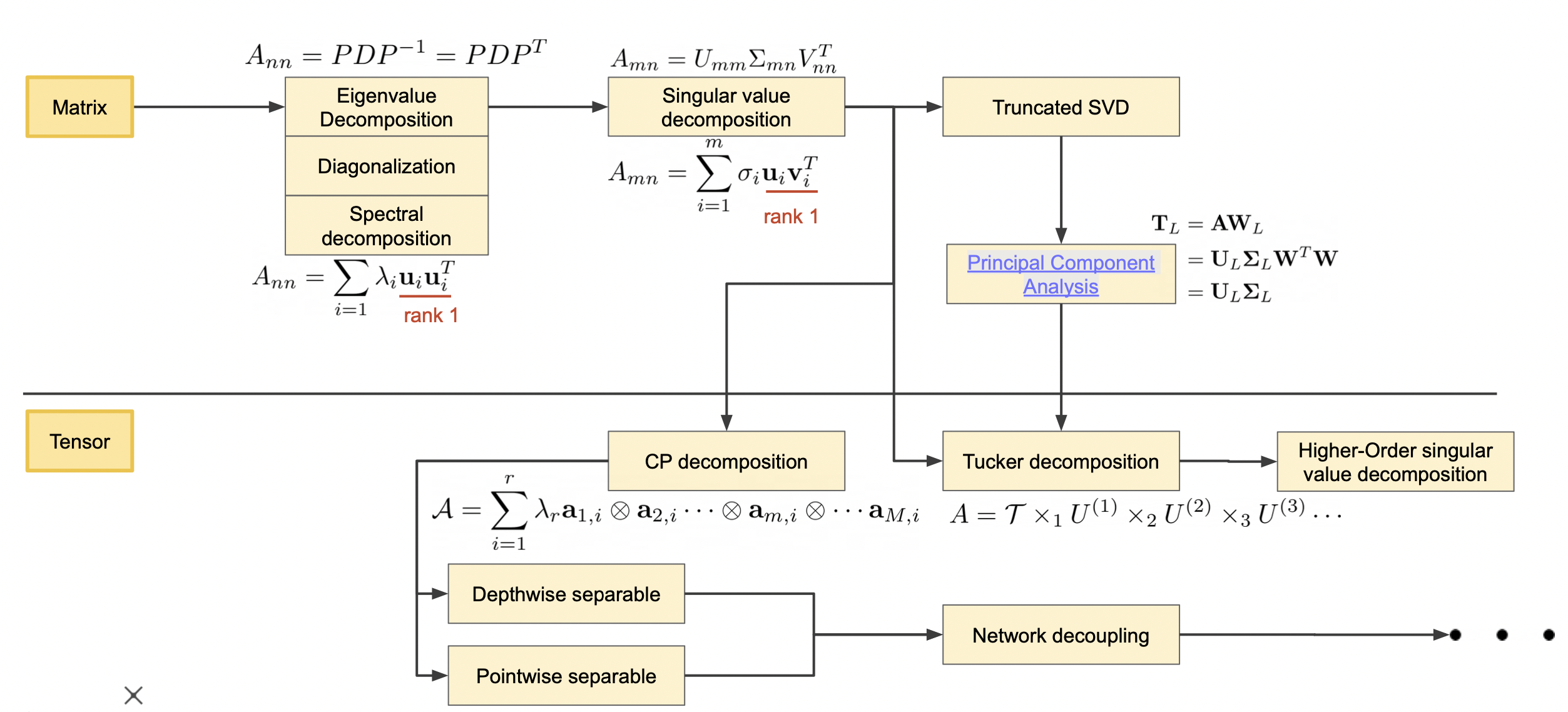
Map2 : Matrix (Tensor) is a linear transformation (map)
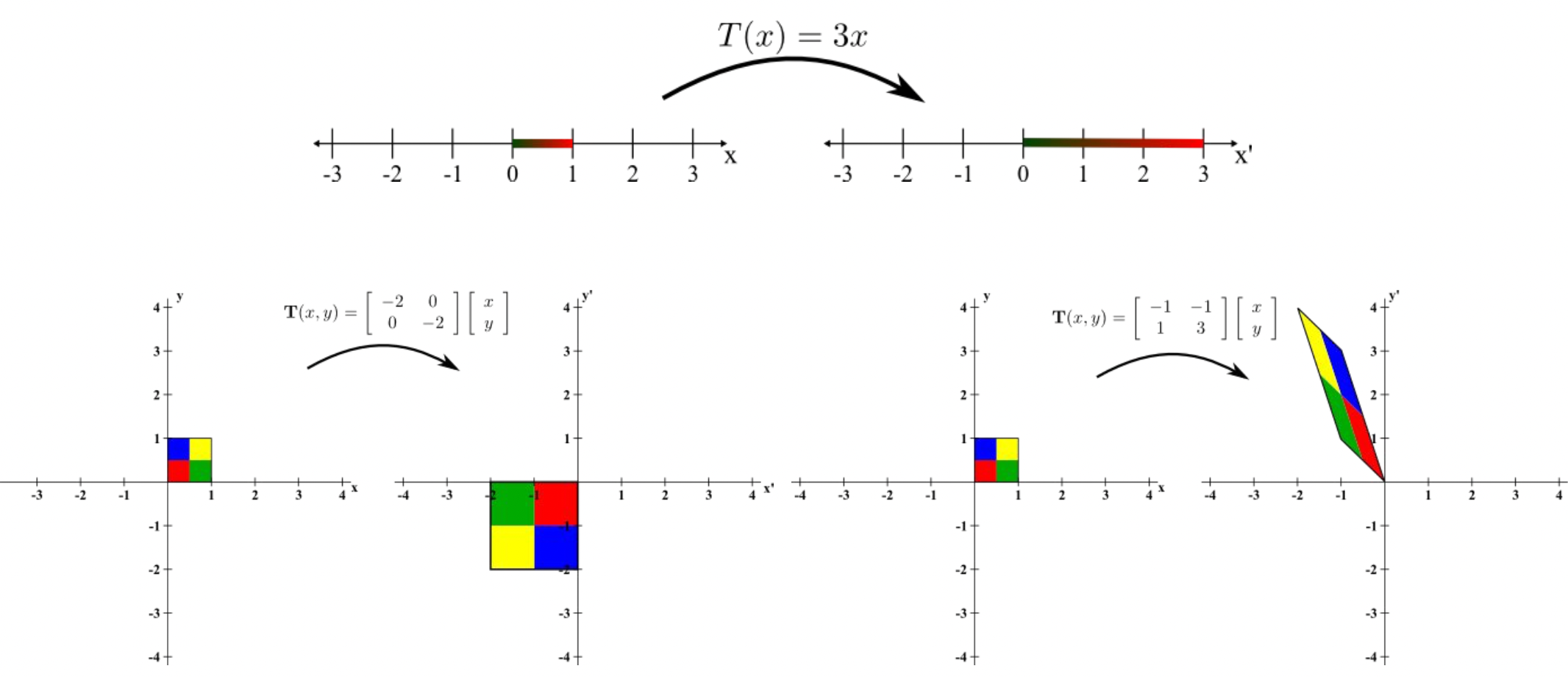
Matrix (Tensor) 는 선형 변환이다.
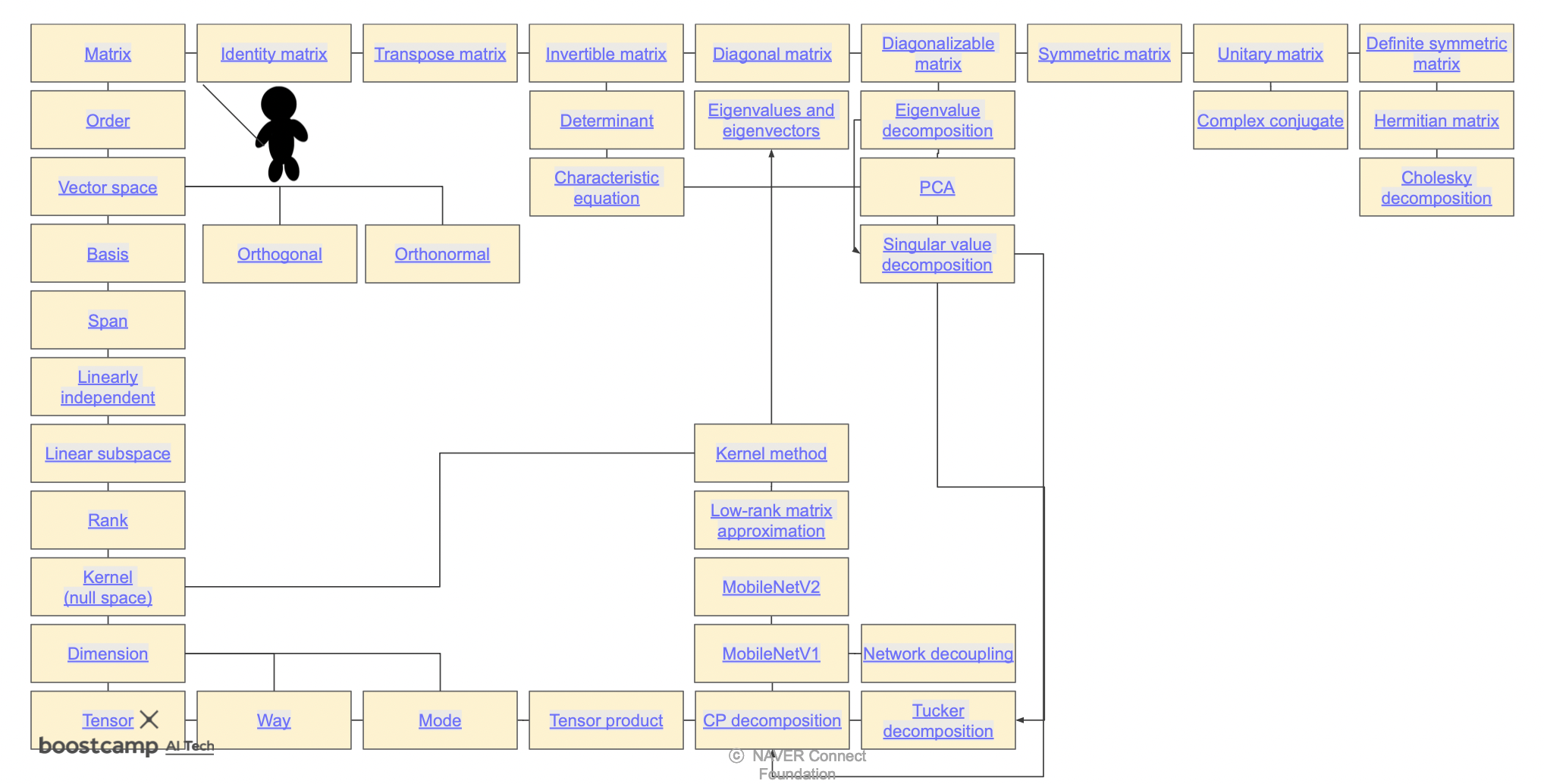
Map3 : Terminology
Matrix (Tensor) 에는 매우 많은 기법들을 적용할 수 있다.
분해의 종류
Filter decomposition
필터로 표현되는 데이터들의 분해 (e.g. 컨벌루션 레이어)
Matrix factorization
2 차원으로 표현되는 데이터들의 분해
Tensor factorization
고차원으로 표현되는 데이터들의 분해
Low-rank matrix approximation
large-scale 로 학습하는 문제에서 Low-rank matrix approximation 는 kernel method 의 필수적인 도구이다.
Kernel Method
Kernel is an umbrella term (포괄적 용어)
다양한 분야에서 커널이라는 말이 사용된다.
커널의 원의미는 중요한 부분을 의미한다.
딥러닝에서는 컨벌루션 레이어 같이 값을 얻기 위해 한 번에 살펴보는 어떤 영역을 말한다.
Kernel method (n=2, m=3)
아래는 굉장히 복잡해보이는 그림이지만 간단히 말하자면 원래는 m=3 이므로 3차원 식으로 표현을 해야하지만 n=2 이므로 2차원으로 (low-rank) 간단하게 표현하는 방법이 kernel method 이다.
Low-rank approximation in model compression
커널 메소드를 통해 원래 값을 근사하게 나타내면서 파라미터 수는 줄일 수 있다.
커널 메소드의 기준은 low-rank 가 된다.
Matrix Decomposition (행렬 분해)
딥러닝이 나오기 전, 추천 시스템의 Latent Factor Model 등에서 많이 사용되었다.

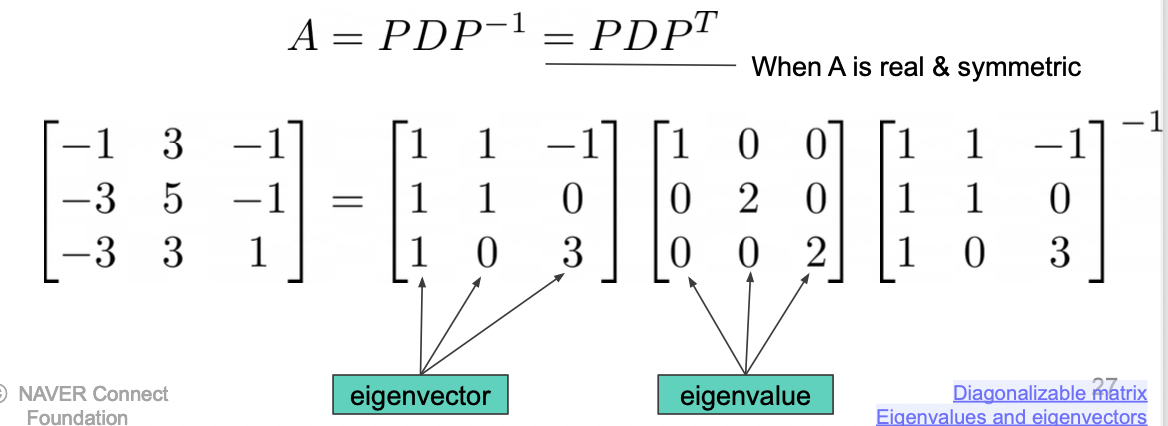
Eigenvalue Decomposition
Matrix 는 선형 변환이다.
어떤 점 (벡터) 을 변환시켰을 때 길이만 바뀌는 벡터를 아이겐 벡터라고 한다. 그리고 변하는 길이를 아이겐 밸류라고 한다.
Eigenvalue Decomposition 은 nxn 으로 이뤄진 행렬을 아이겐 벡터, 아이겐 밸류를 통해 분해하는 방법이다.
Singular Value Decomposition (SVD) : A Generalization (nm case) of EVD
SVD 는 mxn 행렬을 EVD 처럼 분해하는 방법이다.
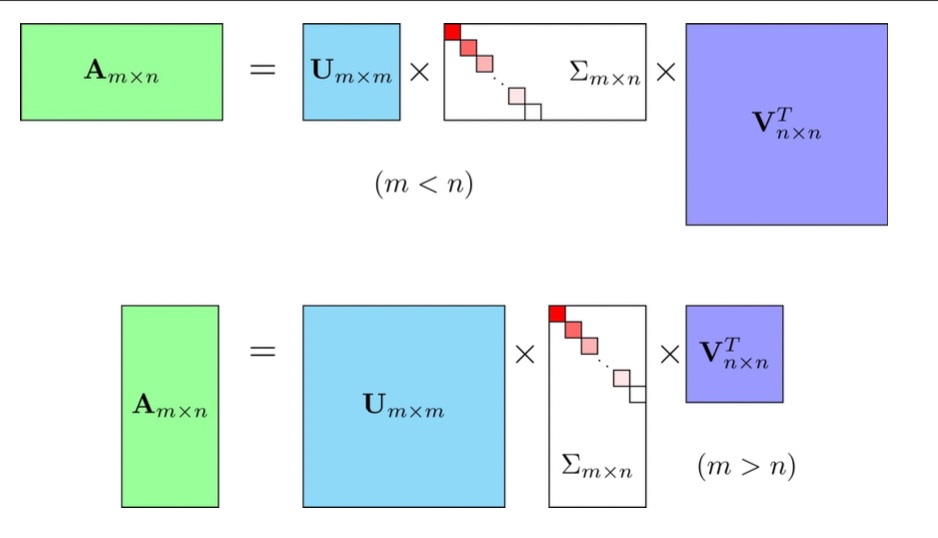
M 은 다음과 같이 분해될 수 있다.
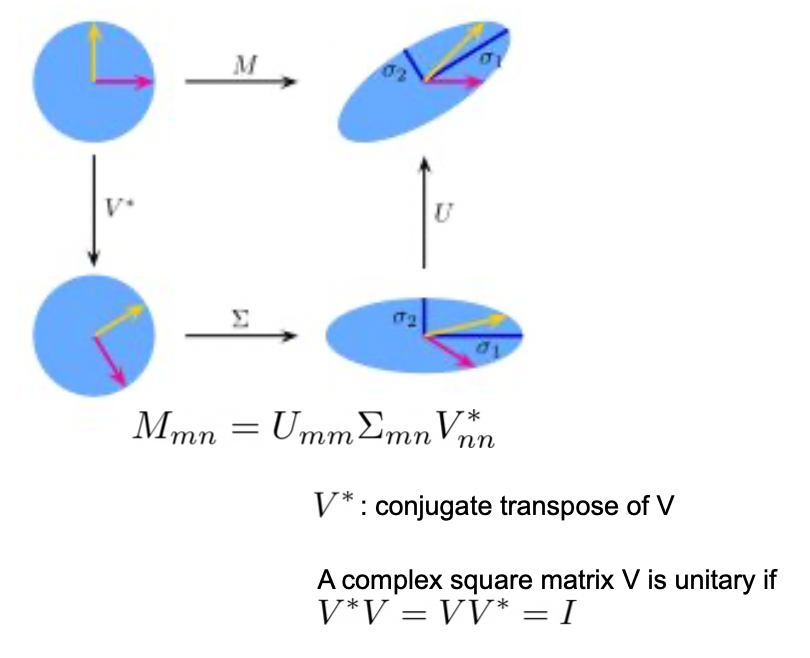
아래 식을 통해 SVD 는 EVD의 일반화된 방법임을 알 수 있다.
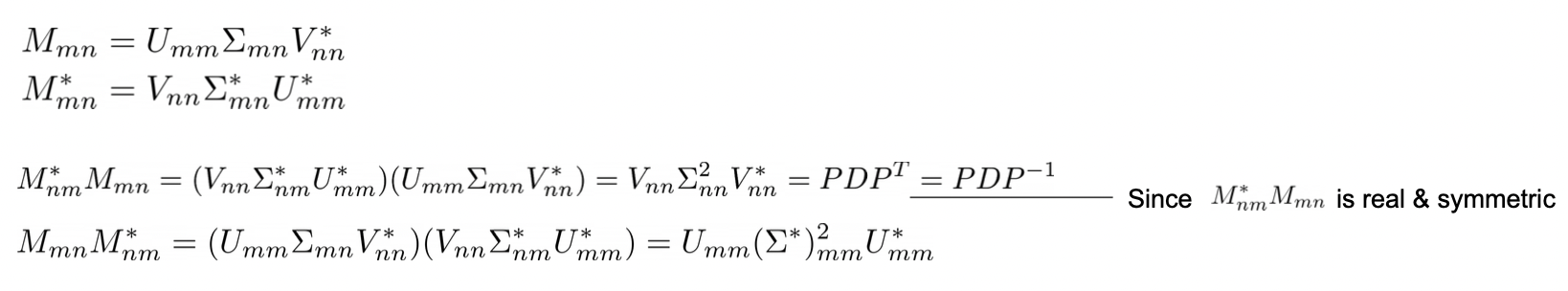
Tensor Decomposition
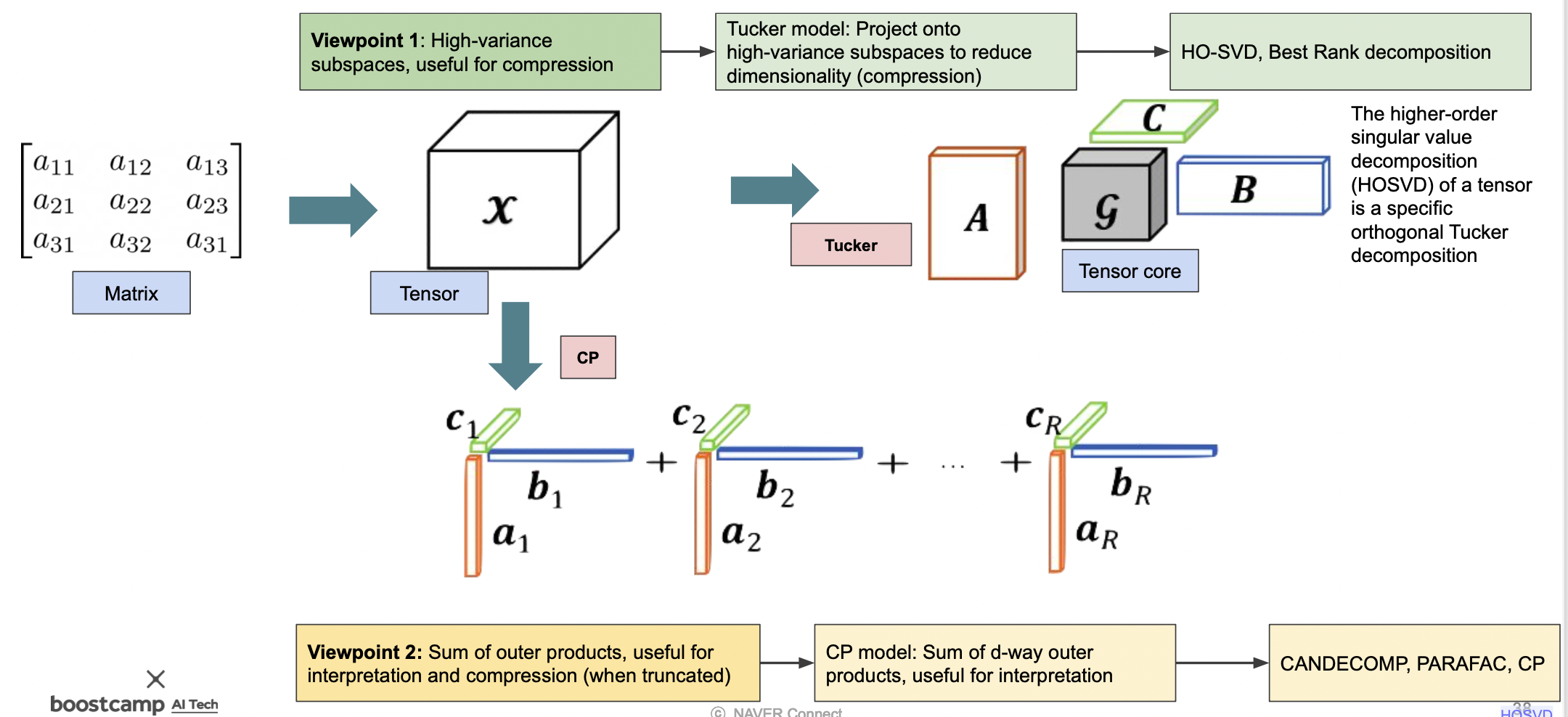
이제 다차원을 가진 텐서를 분해해보자.

CP (Canonical Polyadic) Decomposition
텐서에 SVD 를 적용하기 위해 한 레이어마다 SVD 를 작용하여 더한다.
Tucker Decomposition
Tucker Decomposition 은 한 번에 텐서를 분해하여 계산한다.
CPD 를 일반화한 것에 가깝다.
Tensor Decomposition on Network Compression
MobileNet 시리즈
MobileNet : Depthwise separable convolutions
MobileNetV2 : Inverted Residual Structure
MobileNetV3 : MobileNetV2 + Squeeze-and-Excite
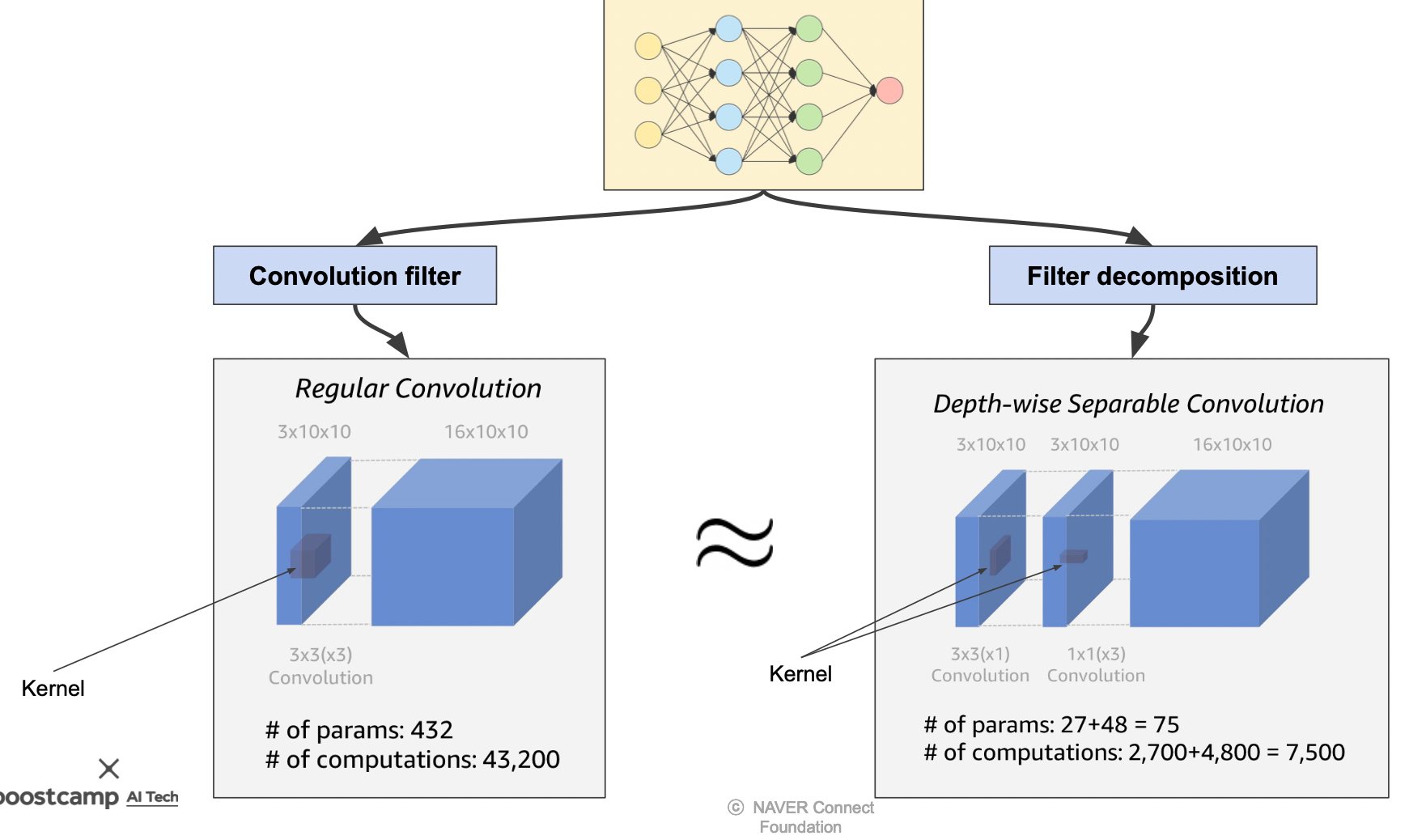
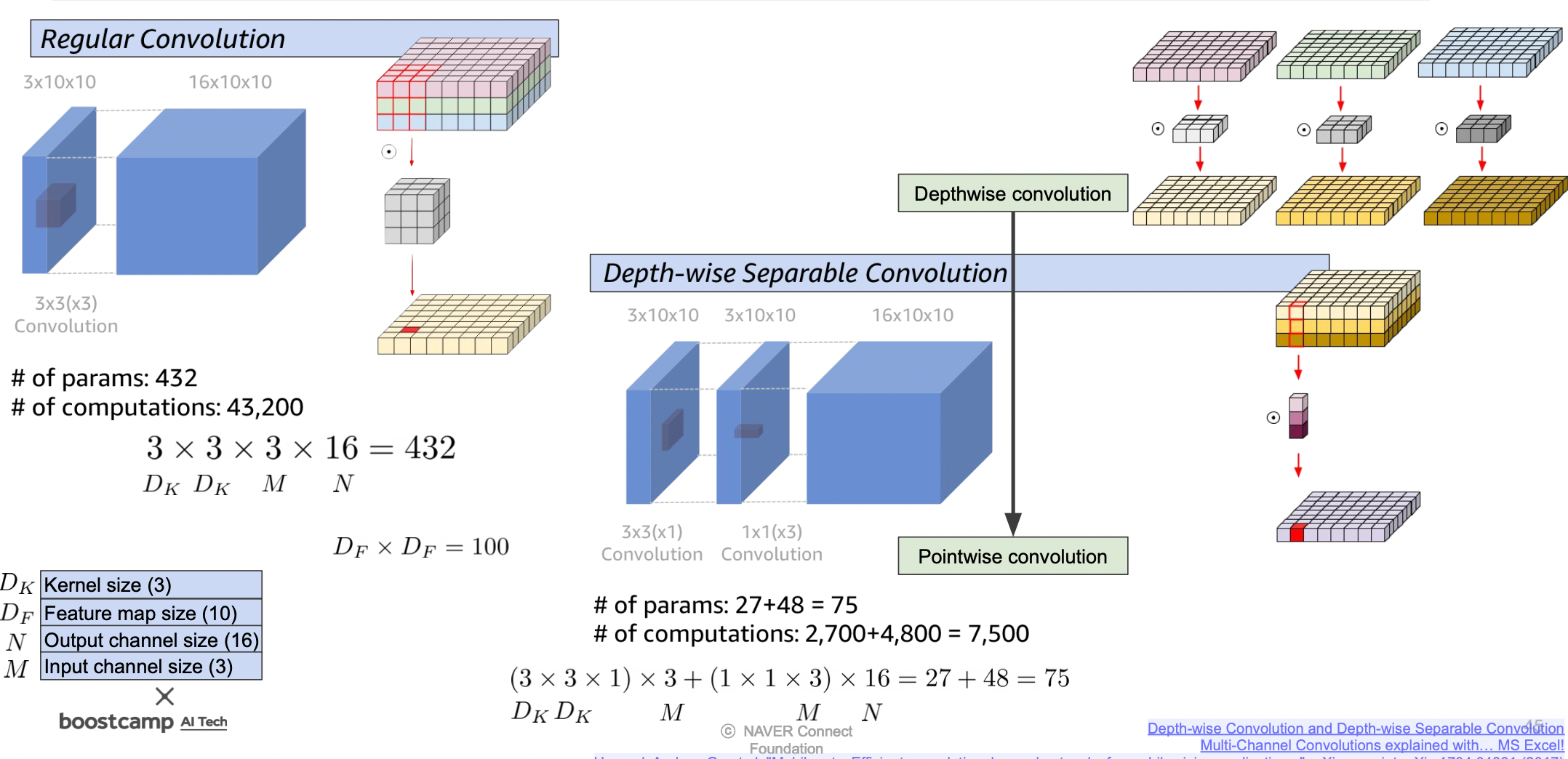
모바일넷의 대표적인 방법인 Depthwise separable convolutions 는 텐서 분해가 적용된 방법이다.
Depthwise separable convolutions
Regular convolution 대신 사용한 Depthwise separable convolution 은 Decomposition 을 적용하여 파라미터를 줄였다.
참조
BoostCamp AI Tech
