개요
애벌레와 나비가 필요로 하는 상태 (먹는 에너지의 양, 행동 양식) 가 다르듯 우리가 사용할 모델도 원하는 목적에 맞게 무게나 상태를 다르게 만들 필요가 있다.
Knowledge 이란
Data 에서 의미를 파악하면 Information 이 되고, Information 에서 문맥을 파악하면 Knowledge 이 되고, Knowledge 를 활용하면 Wisdom 이 된다.
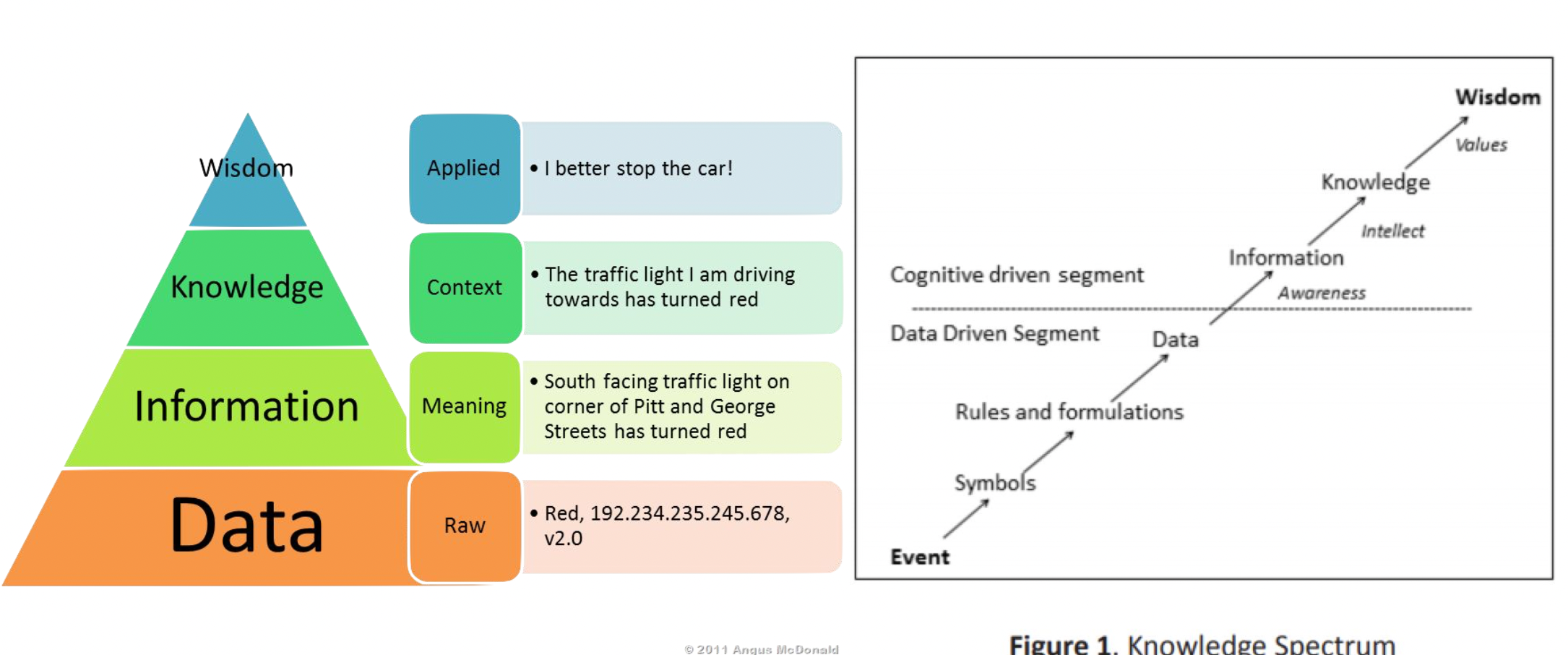
Knowledge & Decision
사람이 프로젝트를 수행한다고 가정해보자.
프로젝트를 하면서 지식은 쌓여갈 것이다.
그러나 중요한 결정은 지식이 없는 초반에 많이 필요로 한다.
즉, 역설적으로 지식이 없을 때 결정이 중요하므로 중요한 의사 결정을 빠르게 하고 개선해야 한다.
이를 해결하기 위해 지식 증류를 통해 초반에 좋은 지식을 얻고자 한다.
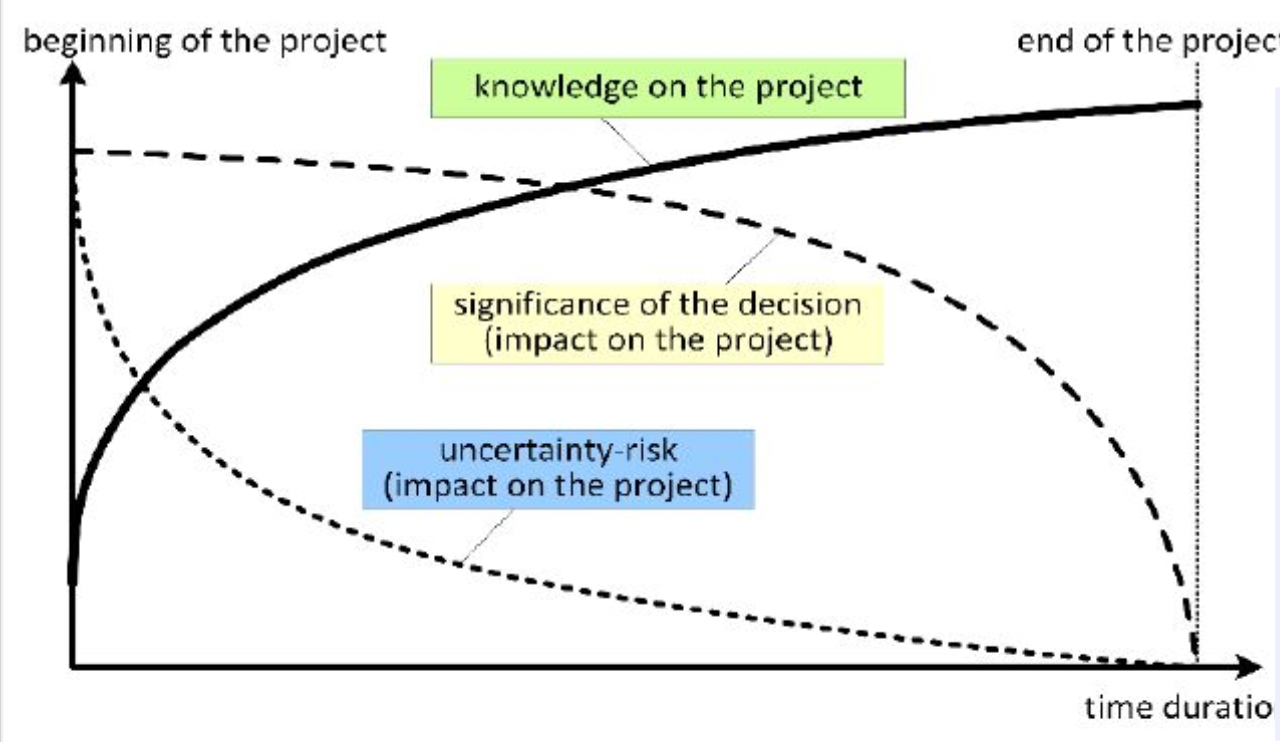
Knowledge Distillation
소금물을 증류하면 소금물의 농도가 진해지듯, 모델의 크기는 줄이되 중요한 부분을 남기는 방법을 말한다.
Knowledge Transfer
Teacher 가 아는 내용을 Student 에게 전달하자.
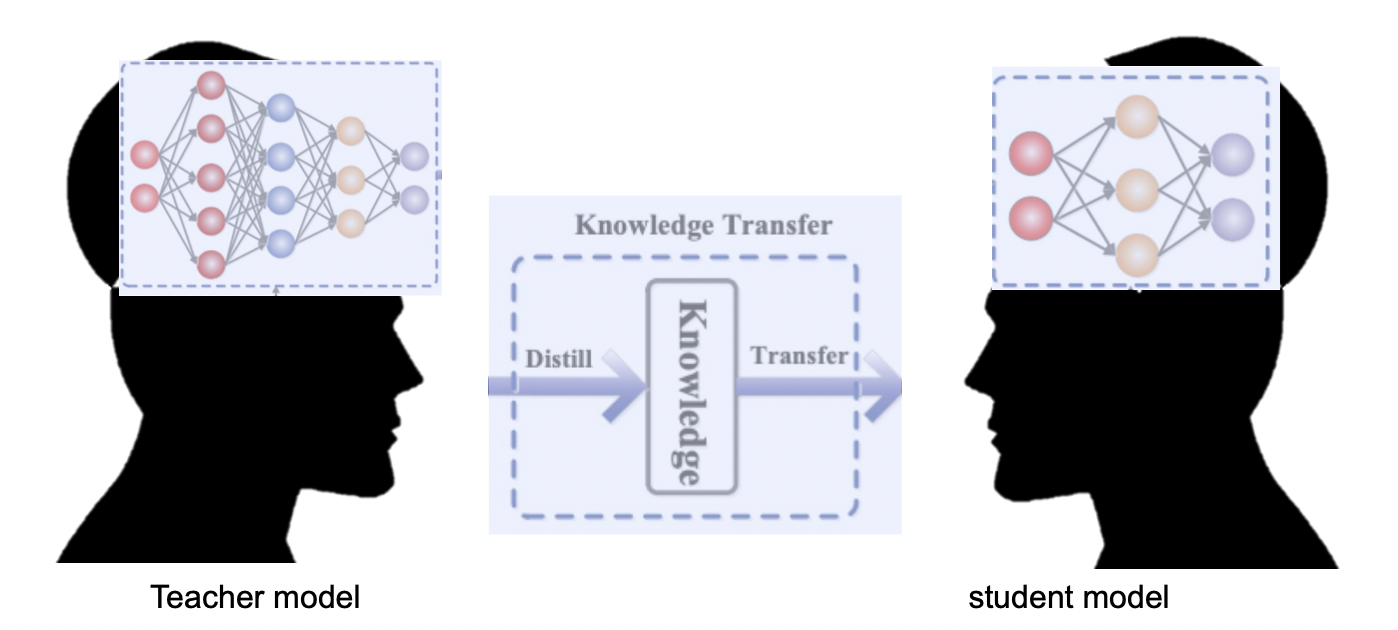
같은 문제를 해결할 때, 스튜던트가 혼자 학습하여 문제를 해결하는 성능보다 티쳐의 지식을 함께 이용할 때의 성능이 더 좋다.
Teacher-Student Network & Hinton Loss
Teacher-Student Network
이전에 작성한 포스트 참고
https://velog.io/@dldydldy75/Leveraging-Pre-trained-Information#knowledge-distillation
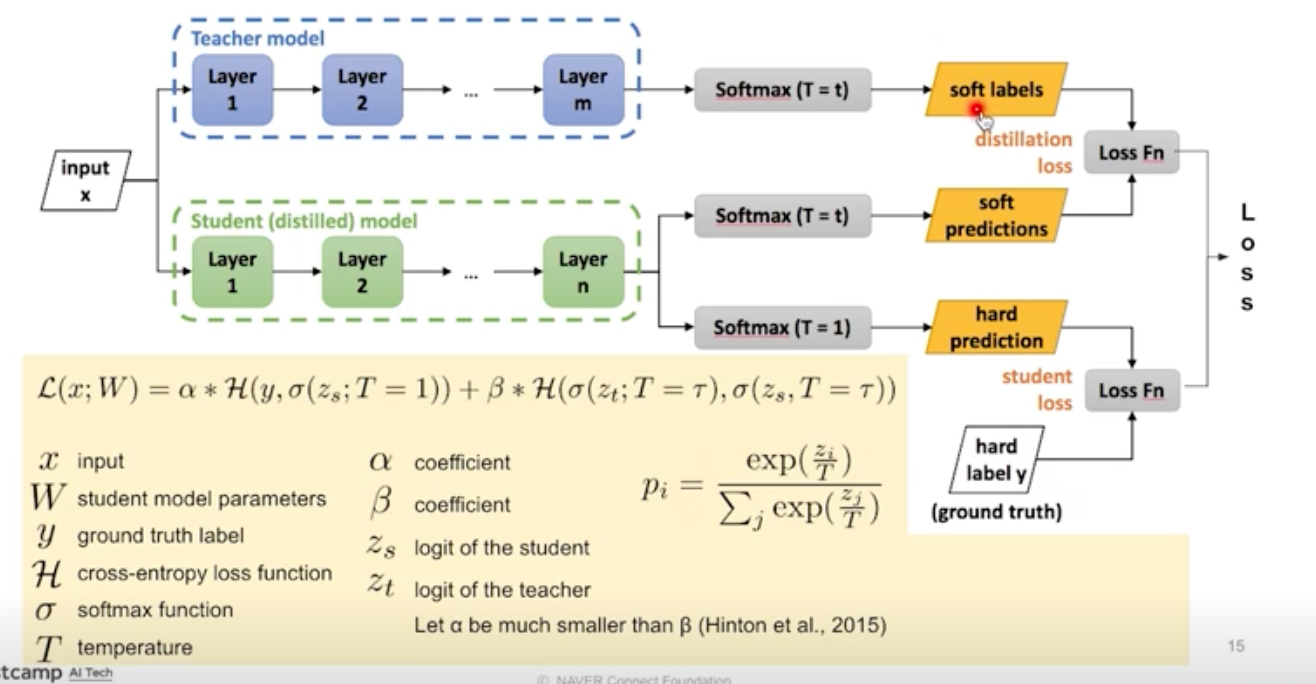
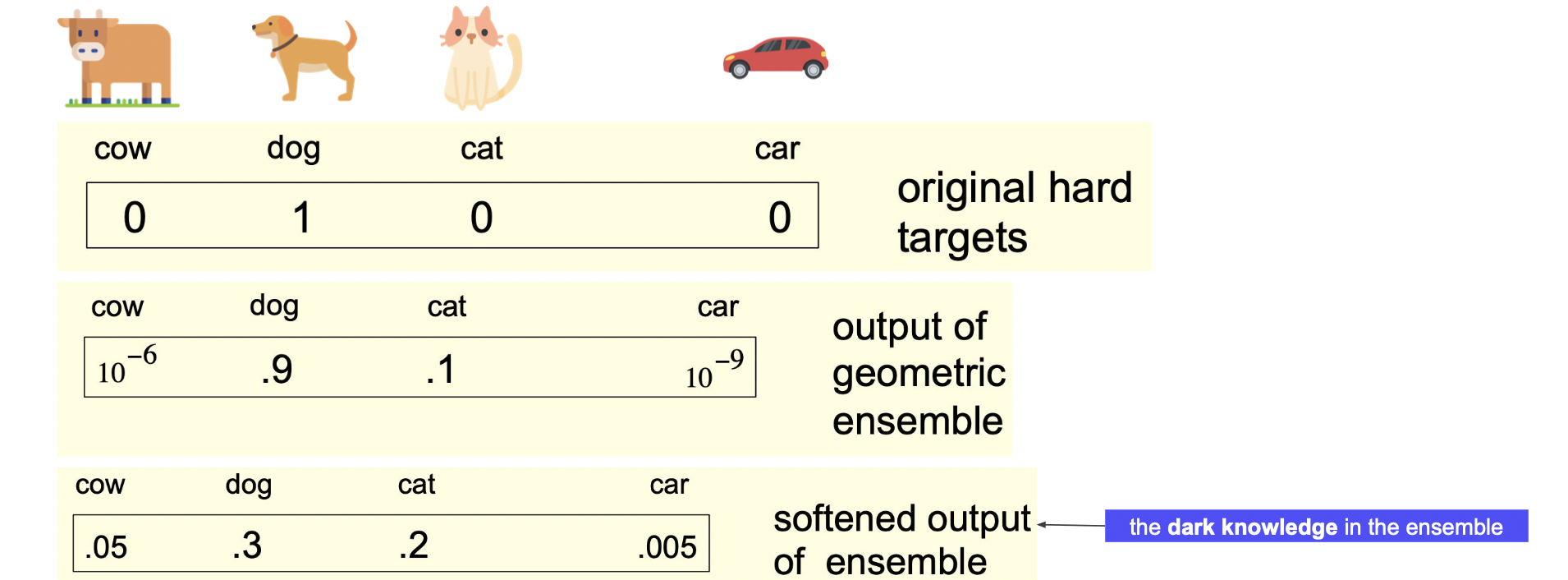
Hard & Soft label
개가 정답이라 하더라도 개만 아는게 지식이 아니다.
차와 개가 가까운 정도보다는 고양이와 개가 가까운 정도를 고려할 수 있어야 지식이다.
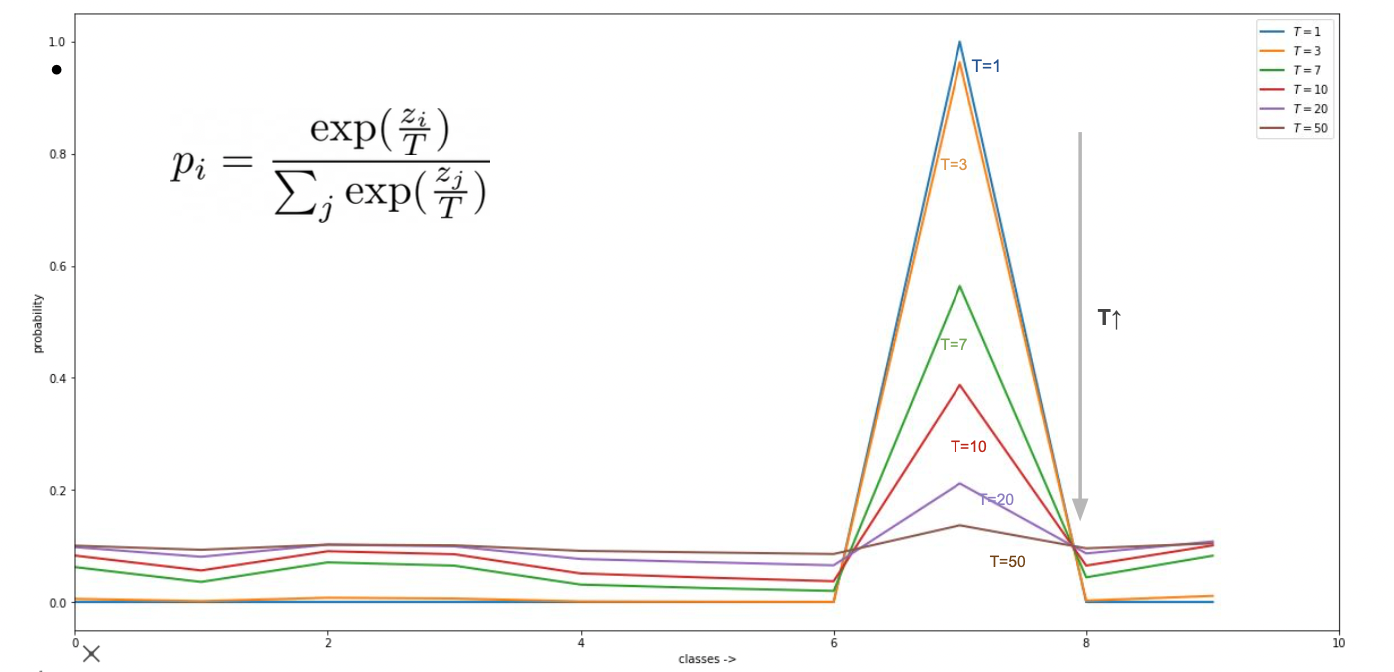
이러한 개념을 반영하는 것이 soft label (temperature 사용) 이다.
Temperature 에 따른 softmax 변화
Zero-mean Assumption
Distillation 이 Compression (Student 가 Teacher 의 성능을 가지면서 가벼워지는 상태) 이 되기 위해서는 distilled 된 logit z 와 combersome 된 logit v 의 평균이 0 이 되어야 한다.
그렇지 않다면 Student 는 Teacher 를 완전히 근사한 것이 아니게 된다.
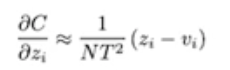
여러 Distillation 들
Feature Distillation
지식 증류 과정 중에 정말 잘하고 있는 것인지 확인하기 위해 착안된 방법이다.
구체적인 방법으로는 ReLU 전에 지식을 뽑아낸다.
다만 ReLU 가 적용되지 않았으므로 배우면 안되는 부분 (음수) 까지 학습이 되는 문제가 발생한다.
Batch Normalization 등으로 이 문제를 해결하려 하였다.
A Comprehensive Overhaul of Feature Distillation
Data-free Knowledge Distillation
스튜던트가 학습 하기 위해 티쳐의 학습 데이터를 필요로 하는 문제를 해결하기 위해 티쳐의 학습 데이터가 아니더라도 지식 증류를 가능하게 하는 방법이다.
Data-Free Knowledge Distillation for Deep Neural Networks
참조
BoostCamp AI Tech
