2021 부스트캠프 Day14
[Day 14] Recurrent Neural Networks
Mathematics for Artificial Intelligence : RNN
시계열 데이터, 시퀀스 데이터에서 이용되는 신경망 구조
시퀀스 데이터 이해하기
- 소리, 문자열, 주가 등의 데이터를 시퀀스(sequence)데이터로 분류
- 시계열(time-series) 데이터는 시간 순서에 따라 나열된 데이터로 시퀀스 데이터에 속한다.
- 시퀀스 데이터는 독립동등분포(i.i.d.) 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
- 과거 정보 또는 앞뒤 맥락 없이 미래를 예측하거나 문장을 완성하는 건 불가능하다.
시퀀스 데이터 다루기
- 이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부 확률을 이용할 수 있다.


- 시퀀스 데이터를 다루기 위해선 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요하다.
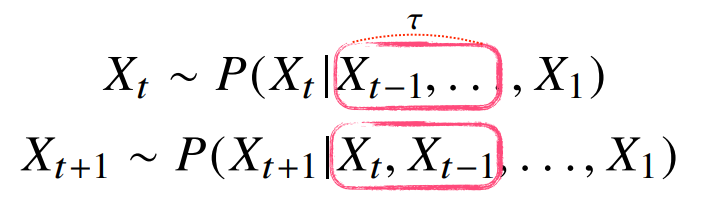
(고정된 길이 만큼의 시퀀스만 사용하는 경우 AR()(Autoregressive Model) 자기회위 모델 이라 부른다.)
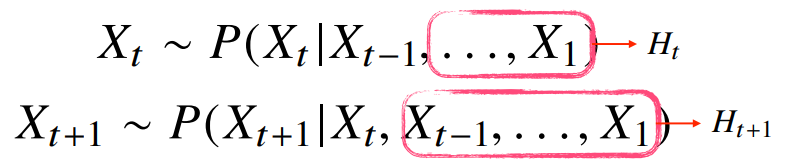
(또 다른 방법은 바로 이전 정보를 제외한 나머지 정보들을 Ht라는 잠재변수로 인코딩해서 활용하는 잠재 AR모델이다.)
(잠재변수 Ht를 신경망을 통해 반복해서 사용하여 시퀀스 데이터의 패턴을 학습하는 모델이 RNN이다.)
RNN(Recurrent Neural Network)
-
가장 기본적인 RNN 모형은 MLP와 유사한 모양이다.
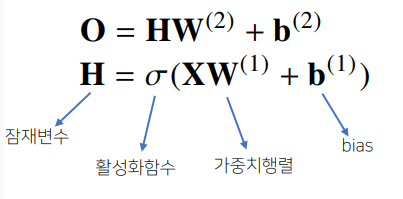
(이 모델은 과거의 정보를 다룰 수 없다.) -
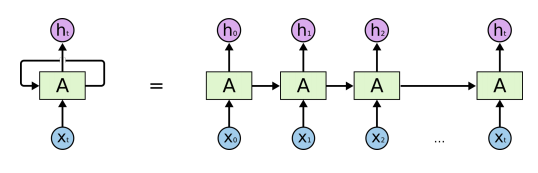
RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링한다.
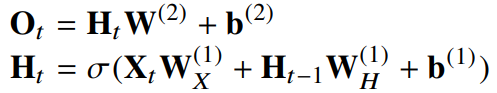
(잠재변수인 Ht를 복제해서 다음 순서의 잠재변수를 인코딩하는데 사용)
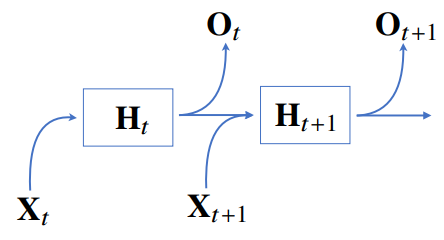
-
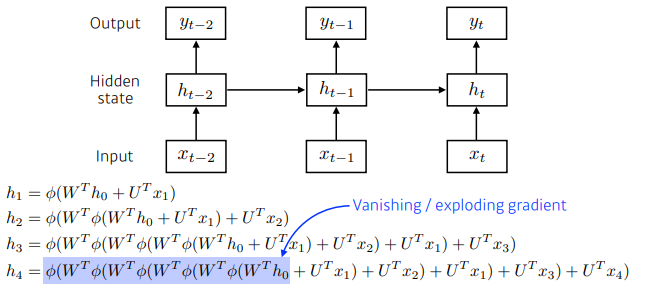
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산.
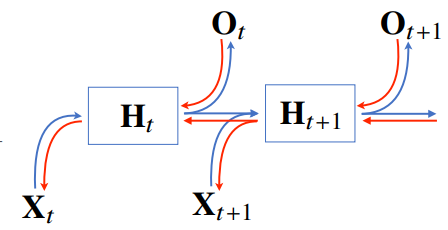
(이를 Backpropagation Through Time(BPTT)이라 하며 RNN의 역전파 방법이다.)
BPTT(Backpropagation Through Time)
- BPTT를 통해 RNN의 가중치 행렬의 미분을 계산해 보면 아래와 같이 미분의 곱으로 이루어진 항이 계산된다.
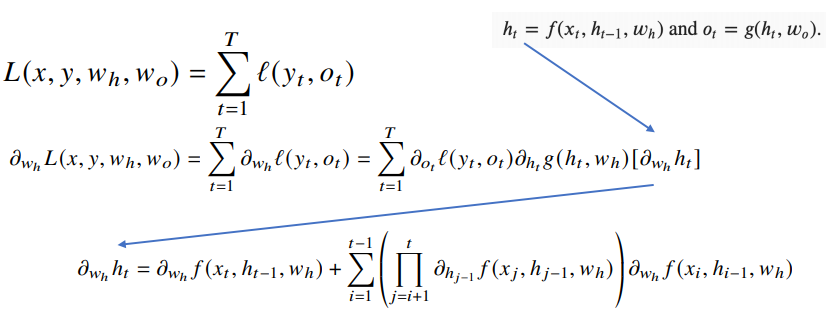
- 시퀀스 길이가 길어질수록 아래의 항이 불안정해지기 쉽다.

기울기 소실의 해결책
-
시퀀스 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정해지므로 길이를 끊는 것이 필요하다.
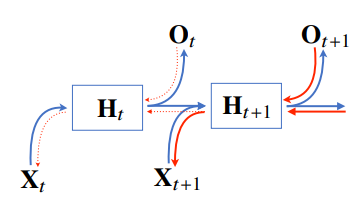
(이를 truncated BPTT라 부른다.) -
이런 문제들 때문에 Vanilla RNN은 길이가 긴 시퀀스를 처리하는데에 문제가 있다.
-
이를 해결하기 위해 등장한 RNN네트워크가 LSTM, GRU이다.
Deep Learning : RNN
Sequential Model
Naive sequence model
- 입력이 들어왔을 때 다음의 어떤 데이터를 예측 하는 것
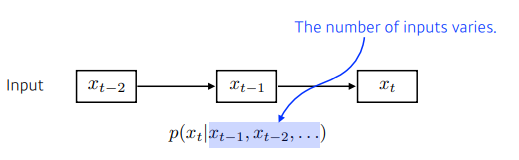
Autoregressive model
- 과거의 몇개만 보면서 모델을 구성(ex. 현재는 과거의 몇개만 참고해서 예측한다.)
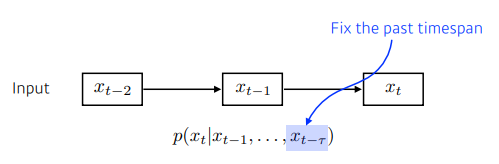
Markov model(first-order autoregressive model)
- 내가 가정을 하기에 나의 현재는 과거에만 dependent한다. 여기서 과거는 바로 이전을 말한다.(ex. 내가 내일 수능이라면 바로 전날의 공부에만 의존한다.)
- 이 모델은 많은 정보를 버리게되는 단점이 있다.
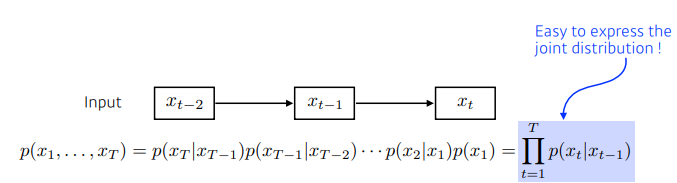
Latent autoregressive model
- 과거의 많은 정보를 고려해야하지만, 이전의 모델에서는 이를 고려할 수 없다.
- hidden state에서 이 과거의 정보들을 고려한다.
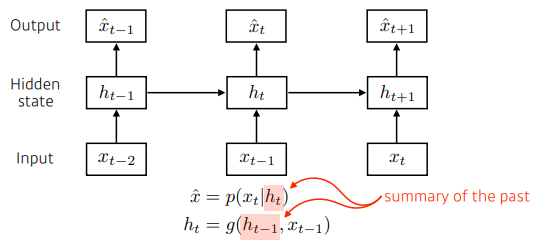
RNN
- 자기 자신으로 돌아오는 구조가 있다.
- sigmoid를 사용할경우 데이터의 vanishing, relu를 사용할경우 데이터의 값이 너무 커져 exploding현상이 발생한다.
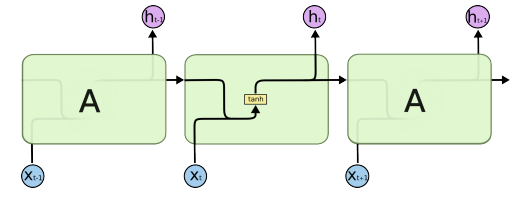
LSTM
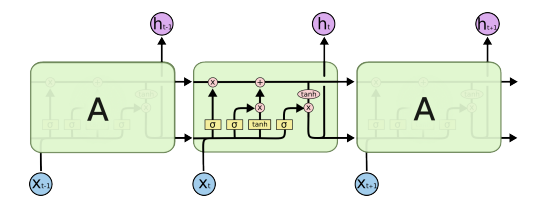
struct of LSTM
total structure
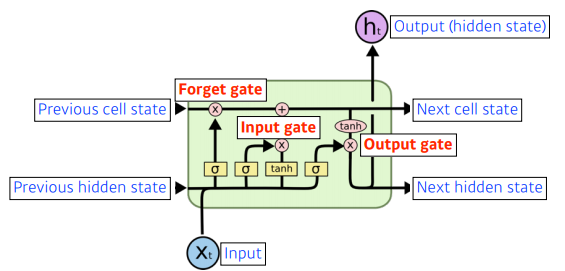
Forget Gate
- 이전의 데이터중 현재 cell state에서 버릴 것을 정해주는 gate

Input Gate
- it : 이전의 hidden state와 현재 입력정보를 가지고 추가하고 말지를 정한다.
- Ct : 현재 정보와 이전 출력정보를 가지고 만드는 cell state 예비군
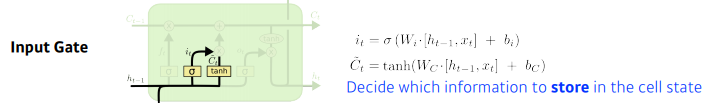
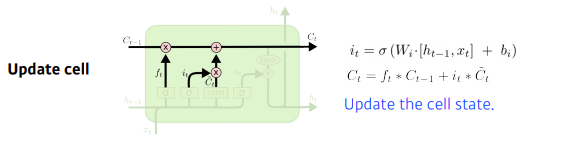
Update Cell
- Forget Gate와 Input Gate의 값들을 기준으로 새로운 cell state를 계산한다.
Ouput Gate
- 내가 어떤값을 밖으로 내보낼지에 해당하는 것에 tanh를 적용.
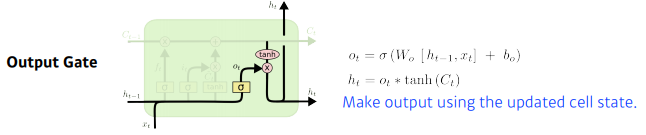
총 정리
- 결과적으로 보면, 현재 이전까지 들어왔던 정보를 현재의 입력을 바탕으로 지울지, 또 현재의 입력을 바탕으로 어떤 값을 새롭게 쓸지, 이 두정보를 취합하는 것이 Update cell이며, 취합된 Cell state를 한번 더 조작하여 어떤 값을 빼낼지를 Ouput Gate를 통해 진행된다.
GRU
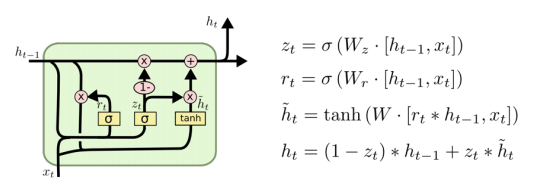
-
게이트가 2개.(vs LSTM은 3개) reset gate and update gate
-
앞에서 봤던 LSTM은 cell state가 하나 흘러가고 그 cell state를 한번더 manipulate해서 hidden state가 나왔지만, GRU는 hidden state가 곧 다음으로 이어지는 hiddn state가 된다.
-
reset gate에 해당하는 것이 LSTM의 forget gate와 비슷하다.
Transformer
Sequential Model
Transformer
Attentions is All You Need, NIPS, 2017
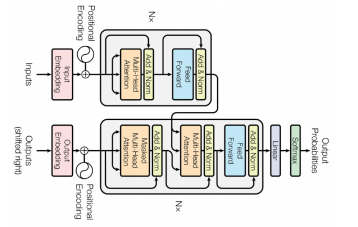
-
Transformer is the first sequence transduction model based entirely on attention.
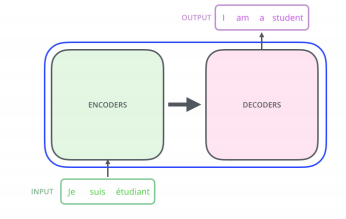
-
This is what the Transformer does.
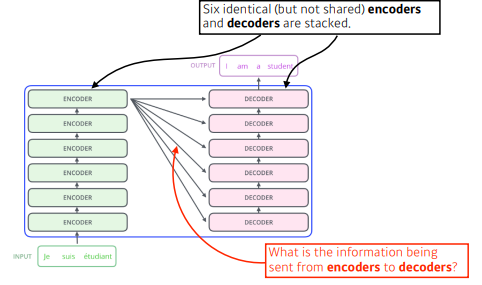
-
N개의 단어가 어떻게 인코더에서 한번에 처리가 되는지? 디코더와 인코더 혹은 인코더 디코더 사이의 어떤 정보가 주고 받는지? 디코더가 어떻게 generation을 할 수 있는지? 를 이해하는 것이 중요하다.
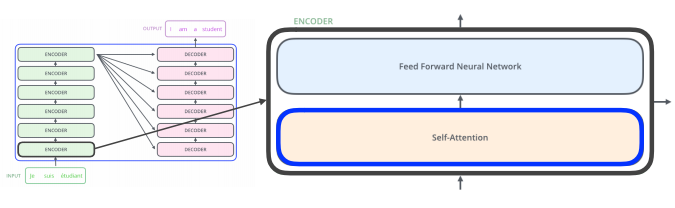
-
인코더를 보면 결국, N개의 단어가 들어간다. 즉 N개의 벡터가 들어가게된다.
하나의 인코더는 Feed Forward Neural Network + Self-Attention으로 구성되어있고, 이 인코더를 거친데이터가 다음 encoder로 전달되어지며, 이러한 encoder들이 stack되어 있다. -
Self-Attention 이 중요하다. Feed Forward Neural Network부분은 이전의 MLP구조와는 다를 것이 없다.

-
N개의 단어가 들어올 수 있지만, 현재는 3개의 단어만 들어온다고 가정을 한다.
-
각 단어마다 특정 숫자의 벡터를 표현하게 된다.
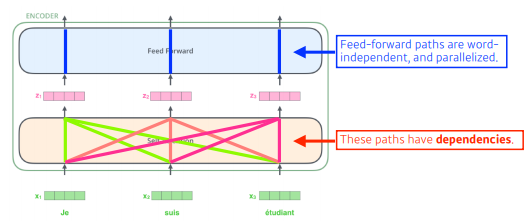
-
3개의 단어가 주어지면 각 벡터마다 3개의 처리를 진행해준다.
-
self-attention에서 하나의 벡터 x1이 z1으로 넘어 갈 때, 단순이 x1의 정보만을 활용하는 것이아니라 x2, x3정보를 같이 활용한다. 따라서 self-attention은 dependencies를 가진다.
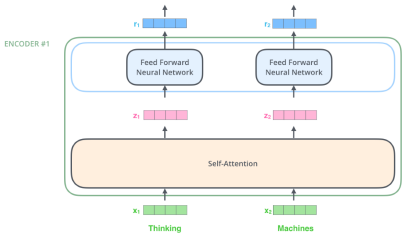
-
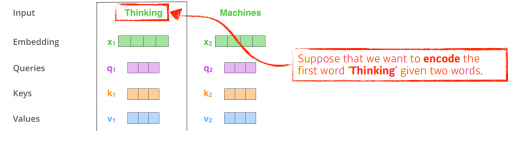
조금더 단순화하기 위해 2개의 단어만 주어졌다고 가정한다.
Thinking과 Maching을 각각 어떤 벡터로 표현했다고 가정.
-
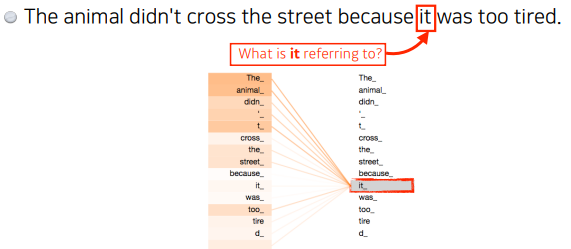
The animal didn't cross the street because it was too tired.이라는 문장이 주어졌다고 가정한다.
'it'이 어떤 단어에 dependent하는지가 중요하다.
하나의 문장에서 있는 단어를 설명할 때는 단어를 그 자체로만 이해하는 것이 아니라, 그 문장속에서 다른 단어들과 어떻게 interaction이 있는지가 중요하다.
실제로 학습결과를 보면 'it'이 'animal'과 크게 관련이 있다고 결과가 나온다.
-
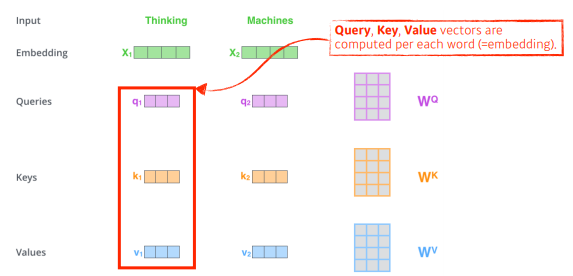
기본적으로 3가지의 vector를 만들어 내게 된다.
Key, Quries, Values vector.
하나의 입력(단어 벡터)가 주어졌을 때, 하나 마다 3개의 vector를 만들게 되고, 이 3개의 벡터를 통해서 우리가 x1이라고 불리우는 첫번째 단어에 대한 임베딩 벡터를 새로운 벡터로 바꾸어준다.
-
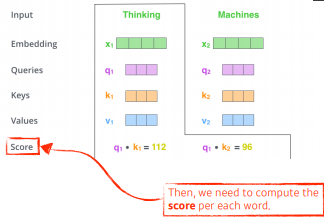
Score벡터라는 것은 첫번 째 단어 'thinking'에 대해 계산할 때 내가 벡터를 계산하고자 하는 query벡터와 나머지 모든 n개의 벡터에 대한 key벡터를 구하여 내적(inner product)를 한다.
바꾸어 말하면, i번째 단어가 나머지 n개의 단어들과 얼마나 관계가 있는지를 구하게 된다.
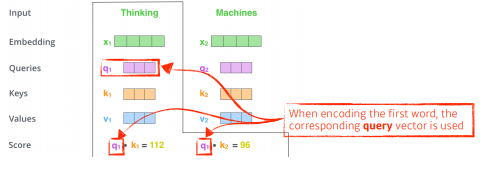
-
내적을 한 것이 결국은 R번째 단어와 나머지 단어들의 사이에 얼마나 interaction을 해야하는지를 알아서 학습하게 하는 것.
Attention이라는 것이 결국은 어떤 Task를 수행할때 특정 timestep에 어떤 입력들을 더 주의깊게 볼지를 계산하는 것.
즉, 한 단어를 볼때 어떤 단어들을 더 주의깊게 볼지를 query벡터와 나머지 벡터들의 key벡터들의 내적을 통해 본다.
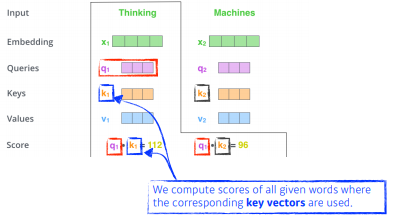
-
score벡터가 나오면 한번 normalize를 한다.
normalize : 8로 나누어준다. 8이라는 숫자는 (decay : key vector의 dimension에 dependent를 한다.)
정확히는 key vector가 몇 차원인지에 대한 hyperparameter. 여기서는 64vector의 제곱근을 통해 8이 나오게 된다.
값 자체가 너무 커지지 않게 만들어주는 과정.

-
nomalize score에 softmax를 취해준다.
thinking이라는 단어가 자기자신과의 관계값이 0.88이 되고, machines라는 단어와는 0.12의 값을 가진다.
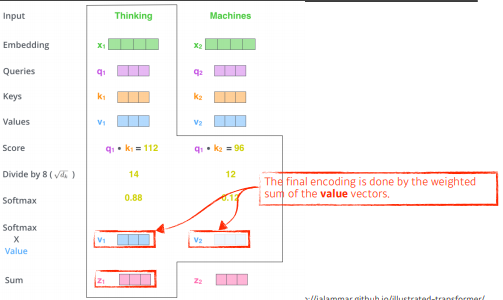
-
ateention rate는 각각의 단어가 자기 자신단어와 얼마나 interaction을 해야 하는 것이고, 중요한 것은 그 값이 어떤 값이 될지이다. 그래서 그 값은 value가 된다.
embedding벡터가 주어지면 각각의 query, key, value 벡터를 만들었고, key벡터와 value벡터의 내적으로 score 스칼라를 만들었고, 이것을 softmax를 하였다. 최종적으로 내가 사용할 값은 각각의 단어 임베딩에서 나오는 value vector들 weight에 sum을하는 것이다. -
qury벡터와 key벡터는 내적을 해야하므로 항상 차원이 같아야한다.
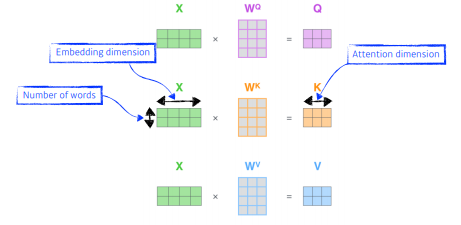
- Q : Query vector, K : key vector, v : value vector
2개의 단어가 주어졌다고 가정했으면 2개의 q,k,v vector가 나오게 된다.
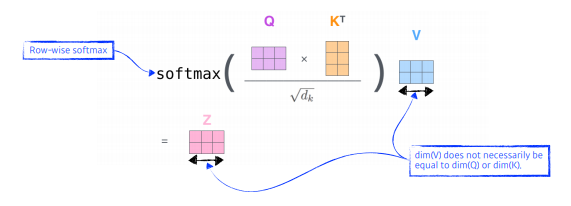
-
내적 후, 제곱근을 나누어주고, softmax를 취한 후, weight와 sum을 수행해주는 과정을 하나의 수식으로 표현한 것.
-
여기서 까지가 transformer의 single-headed attention 과정이다.
-
왜 이것이 잘될까?
이미지 하나를 CNN이나 MLP로 바꾸면 input이 fix되어있으면 출력이 fix된다.
weight가 고정이 되어있기 때문.
transformer는 하나의 input, network가 fix되어있더라도, 내가 이 encoding하려는 단어와 그 옆에 있는 단어들에 따라서 내가 인코딩된 값이 달라지게 된다.
바꾸어 말하면 MLP를 조금더 flexable하게 만든 것.
즉, 훨씬더 많은 것을 표현하는 것이 transformer 구조.
다른 입력들이 달라짐에 따라 출력이 달라질 수 있는 여지가 있다.
바꾸어 말하면 이렇게 더 많은 것을 표현하기 때문에 더 많은 computition이 발생.
여기서 볼수 있는 bottleneck은, 내가 한번을 처리하고자 하는 단어가 1000개면 1000x1000짜리 입력을 처리해야한다.
rnn은 1000개의 sequence가 주어지면 1000번 돌리면 된다.
하지만 transformer구조는 n개의 단어들을 한번에 처리하게 되고, 제곱근을 이용하기 때문에 이러한 부분에서 한계가 발생한다.
그렇지만, 훨씬더 flexable하고 훨씬 더 많은 것을 표현 할 수있는 nework를 만들게 된다.
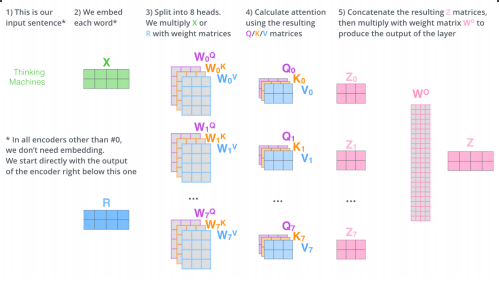
Multi-headed Attention(MHA)
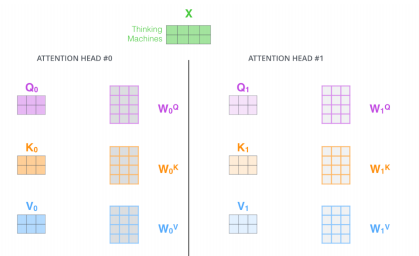
-
앞에서 얘기했던 attention을 여러번 하는 것.
-
하나의 encoding 벡터에 대해서 q,k,v를 하나만 만드는 것이아니라 n개 만드는 것.
-
이것을 함으로써 n개의 attention을 반복함으로써, n개의 인코딩된 벡터가 생성.
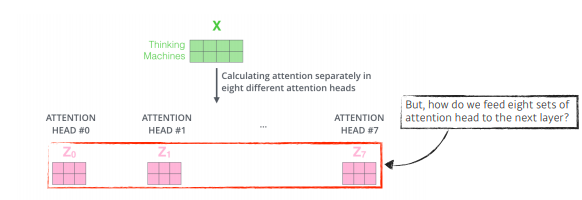
-
고려해야 될 부분 : 입력과 출력의 차원을 맞추어줘야됨. embedding 된 dimension과 encoding되어서 self-attention 된 데이터가 항상 같은 차원이되어야 한다.
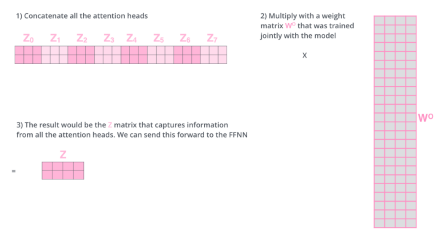
-
원래가 10dimension이였고, 8개가 나왔으면, 80 dimension짜리의 encoding된 데이터가 있다면, 80x10행렬을 곱하여 10차원으로 줄여버린다.
-
input이 들어오면, 각각의 단어를 임베딩하게 되고.
-
얘를 8개의 self-attention을 돌려서 8개의 encoding된 벡터를 만들고,
-
8개에서 다시 linearmap을 찾아서 맞춰주고 vector를 맞추어준다.
-
but, 실제 구현에서는 이렇게 구성되어지지 않는다.
-
원래 100dim의 데이터가 있고, 10개의 head를 사용한다고 하면, 100dim을 내가 10개의 head를 만드는 것이 아니라, 100dim을 10개로 나눈다.
즉, 10dim짜리만 가지고 1개의 head가 돌아가게된다.
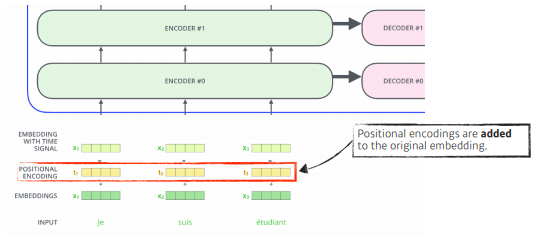
- position encoding이 필요하게 된다. bias가 된다.
- 왜 필요할까?
n개의 단어를 sequential하게 넣어줬지만, 이 sequential한 정보가 사실은 이 안에 포함되어있지 않다. a,b,c,d라는 단어를 내가 넣어주거나, b,c,d,a라는 단어를 넣거나, d,a,c,b를 넣는다면, 각각의 a,b,c,d에 대한 encoding된 값은 달라질 수 없다.
그렇기 때문에 우리가 문장을 만들때에는 어떤 단어가 어느 위치에 들어가는지가 중요하다.
그래서 position encoding이 필요하게 되고, 주어진 입력에 어떤 값을 더한다는 것이 된다.
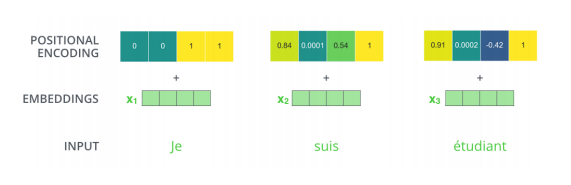
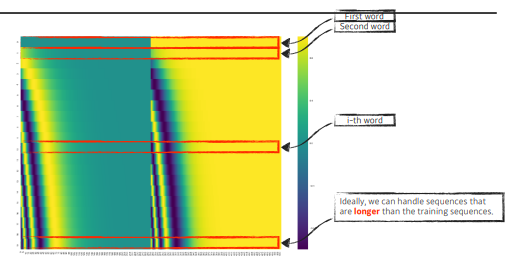
- 그 벡터에 해당하는 offset을 그대로 더해준다.
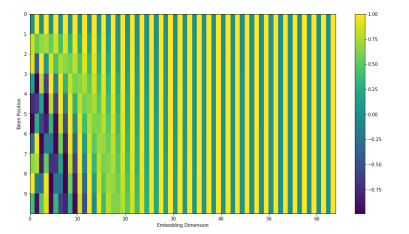
- recent (July, 2020) update on positional encoding.
- 최근에는 이 positional encoding이 바뀌게 된다. 이것은 pre-defined된 방법에 따라 바뀌게 된다.
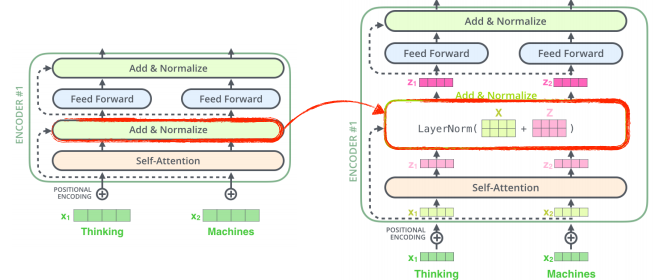
-
인코더 부분은 이와 같이 구성된다.
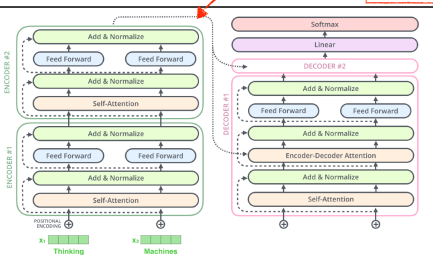
-
decoder쪽을 보게되면, 인코더는 주어진 단어를 표현하는 것이였고, decoder는 이것을 가지고 무언가를 생성하는 것이다.
중요한 점은, 인코더에서 디코더로 어떤정보가 전해지는지가 중요.
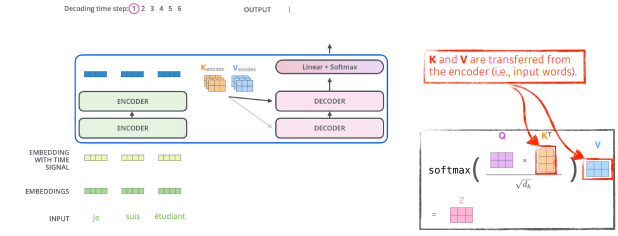
-
transformer는 결국 key와 value를 보내게 된다.
왜?
r번째 단어를 만들 때, r번쨰 벡터의 query벡터와 나머지 단어들의 key벡터를 통해 value를 만들고 이를 통해 attention을 만든다.
input에있는 단어들은 decoder에 대해 출력하고자 하는 맵을 만들려면, encoder에 있는 데이터들의 key, value가 필요하게 된다.
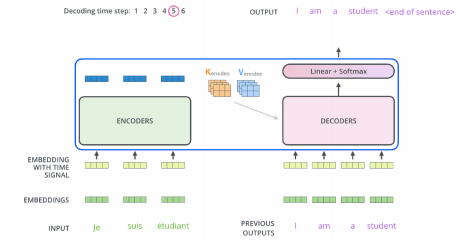
- 학습단계에서 masking을 하게 된다. 이전 단어들에 대해서만 dependent하고, 뒤에 있는 단어들에 대해서는 dependent하지않게 만드는 일종의 방법.
masking을 활용함으로써 미래에있는 단어를 활용하지 않겠다
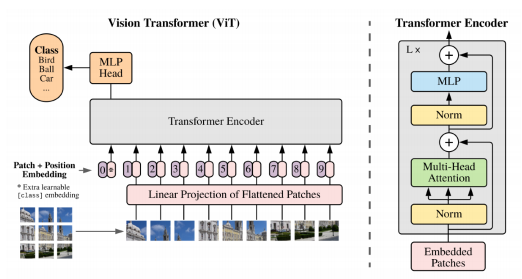
- 최근들어 attention 구조를 단순히 단어들의 sequence에 대해서 뿐만 아니라, image분야에서 활용하기 시작. 위 그림은 image분류에서 encoder만 활용하게 된다.
Further Question
LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
Modern CNN에서는 identitiy map의 구조에서 skip connection과정이 들어있다. 이 과정 또한 이전의 x에 대해 현재의 f(x)를 더하여 다음의 f(x)를 구성하는 것이다. 이러한 과정이 LSTM의 forget, input gate를 통해 이전의 x값들에 대한 정제를 거치고 현재의 f(x)를 통해 다음으로 전달되는 과정과 비슷한 개념이라고 생각이든다.
Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature), batch_first 관련 argument는 중요한 역할을 합니다. batch_first=True인 경우는 어떻게 작동이 하게되는걸까요?
https://discuss.pytorch.org/t/could-someone-explain-batch-first-true-in-lstm/15402/9
위 링크의 사이트에 이에 대한 설명이 잘 나와있었다.
Pytorch에서 Transformer와 관련된 Class는 어떤 것들이 있을까요?
https://pytorch.org/docs/master/nn.html#transformer-layers
pytorch 공식문서에서 이에 대한 답을 찾을 수 있었다.

transformer에 대해 잘 정리된 글을 찾았다.
