2021 부스트캠프 Day15
[Day 15] Generative Model
Generative Models Part I
Generative Model
-
We want to learn a probability distribution p(x) such that
- Generation : sampling
- Density estimation : 어떤 이미지가 들어갔을 때 확률값이 주어지면서 구분해 내는 것 like classification(anomaly detection)
Also known as, explicit models. - Unsupervised representation learning : feature learning. what these images have in common
-
p(x)를 어떻게 만드냐?
Basic Discrete Distributions
- Bernoulli distribution : (biased) coin flip
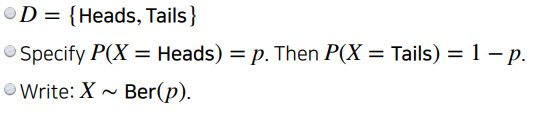
- Categorical distribution : (biased) m-sided dice
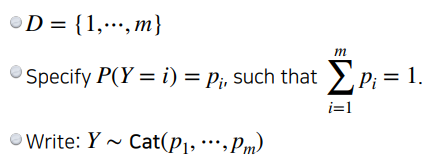
Structure Through Independence
- n개의 모든 pixel들이 independent 하다고 가정했을 때,
- 역시나 가능한 possible states는 2n
- 특정한 p(x1,...,xn)의 파라미터수는 n개이다.
- 이것에 대한 중간을 찾고싶은 것이 목표이다.
Conditional Independence
Chain rule
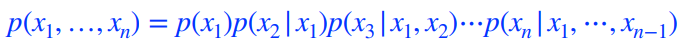
Bayes rule
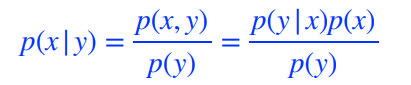
Conditional independence
- 가정의 방법, z가 주어 졌을 때 x, y가 independence가 하다. x라는 variable이 z가 주어 졌을 때 y는 상관이 없어진다.
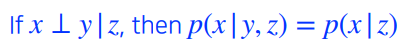
conditional independe와 chain rule을 적당히 섞어 fully dependent model과 fully independent model사이의 어떤 값을 만들 것이다.
Using the chain rule
- 어떠한 가정도 없을 경우 chain rule.
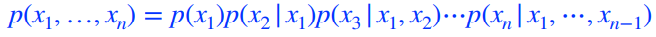
- 몇개의 파라미터가 필요할까?
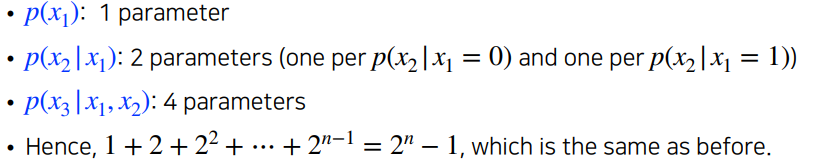
using the Markov assumption
-
i+1번째 pixel을 i번째 pixel에만 dependent한다고 가정.
-
chain rule로 얻어진 conditional distribution이 짤리게 된다.
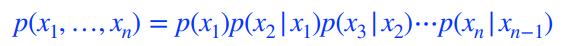
-
몇개의 파라미터가 필요할까?
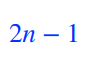
-
chain rule만 가지고 쪼개면, 파라미터의 숫자는 달라진게 없는데 쪼갠다음에 Markov assumption을 적용하면 conditional independence를 통해 parameter를 2n-1에서 2n-1로 줄일 수 있다.
-
we got exponential reduction
-
이러한 과정들을 Auto-regressive 모델이라 부른다.
Auto-regressive Model
We need an ordering of all random variables.
이전의 n개만 참고한다는 모델이 ar-n 모델이라고 부른다.
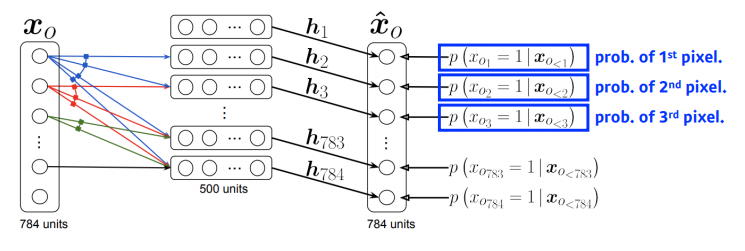
NADE : Neural Autoregressive Density Estimator
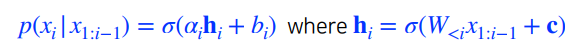
-
i번째 pixel을 첫반째 부터 i-1번째 pixel을 dependent하게 한다.
-
첫번째 pixel의 확률분포를 어느것에 dependent하지 않게 만들고,
두번째 pixel에 대한 확률을 첫번째 pixel에만 dependent하게 만든다.
이 의미는 첫번째 pixel값을 입력으로 받는 neural network를 만들어서,
single scalar가 나온다음에 sigmoid를 통과하여 수를 만들고
5번째 수를 만들때에는 1번째와 4번째 pixel에 대한 값을 받아서,
neural network를 통해 나온값을 sigmoid를 통과해서 나온 수로 만든다. -
i번째 pixel은 i-1개의 입력에 dependent하게 된다.
neural network입장에서는 입력차원이 계속 달라진다.
그래서 weight가 계속 커지게 된다.
첫번째 pixel을 만드는데에는 아무 것도 필요없고,
세번째 pixel에 대한 neural network를 만들때에는 2개의 입력을 받는 weight가 필요. -
NADE는 explicit model이다. 단순이 generation을 할 수 있는게 아니라, 어떤 입력에 대한 확률을 계산할수 있다.
-
어떻게?
- n개의 pixel이 주어지면, joint distibution을 chain rule을 통해 각 픽셀에 대한 확률분포를 알수 있다.
-
continuous ouput일 경우 mixture of Gaussian을 통해 사용될 수 있다.
Pixel RNN
-
결국은 어떤 이미지에 있는 pixel들을 만들어 내고 싶은 것.
-
RNN을 통해 Genetarion을 하겠다가 차이가 있다.
-
한가지 더 차이점이 있다면, ordering을 어떻게 하느냐에 따라서 두가지 알고리즘으로 된다.
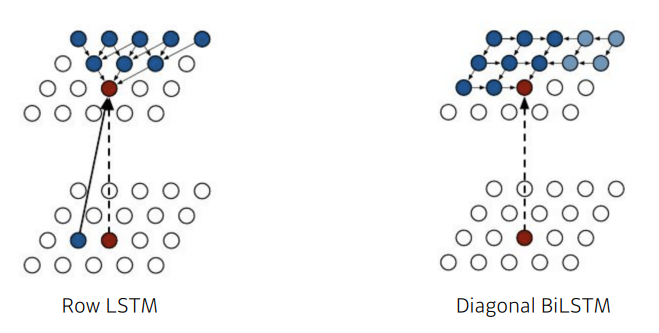
- Row LSTM : i번째 pixel을 만들 때, 위쪽에 있는 정보를 활용하는 것.
- Diagonal BiLSTM : pixel에 대한 자기 이전 정보들에 대해 다 활용하는 것.
Generative Models Part II
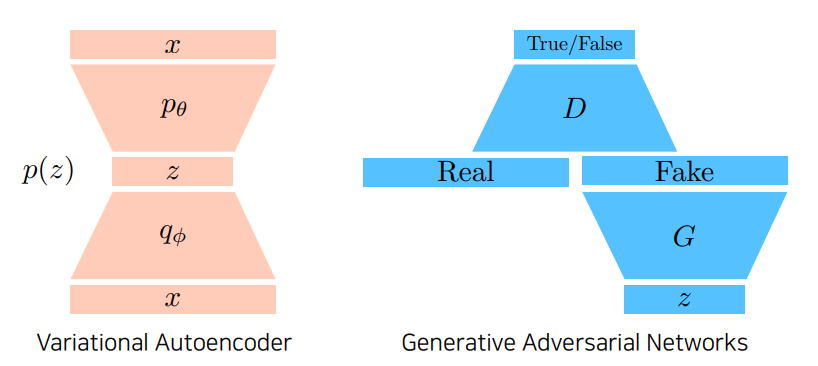
Variational Auto-encoder
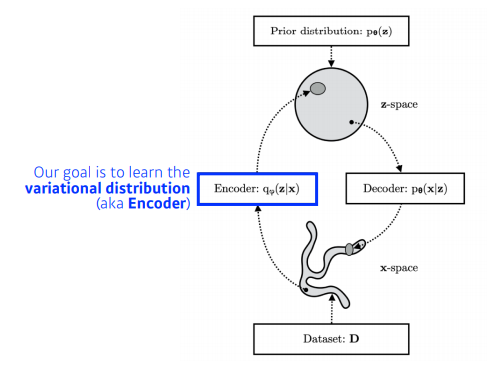
- Variational inference
- 목적은 posterior distribution을 찾는 것.
- Posterior distribution : 나의 attribution이 주어 졌을 때, 내가 관심있어하는 random variable에 대한 확률분포.
- Variational distribution : 일반적으로 posterior distribution을 계산하기가 너무 힘들다. 불가능 할때가 많다. 그래서 이것을 내가 학습할 수 있는, 최적화 시킬 수 있는 어떤 것으로 근사하겠다가 목적이고, 근사하는 분포가 variational distribution이다.

- 무언가를 잘 찾겠다. 무언가를 잘 최적화하겠다고 하면 우리에게 필요한 것은 objective(loss function)이다. KL divergence라는 matrix를 활용해서 posterior distribution과 variational distribution을 줄여보겠다.
-
문제는 뭐냐면, 내가 posterior가 뭔지도 모르는데, 뭔지도 모르는 posterior distribution을 근사할 수 있는 variational distribution을 찾는다는 것이 어불성설이다.
마치 loss function이있는데 target이 뭔지모른다. 근데 loss function을 줄이려는 것과 같다. -
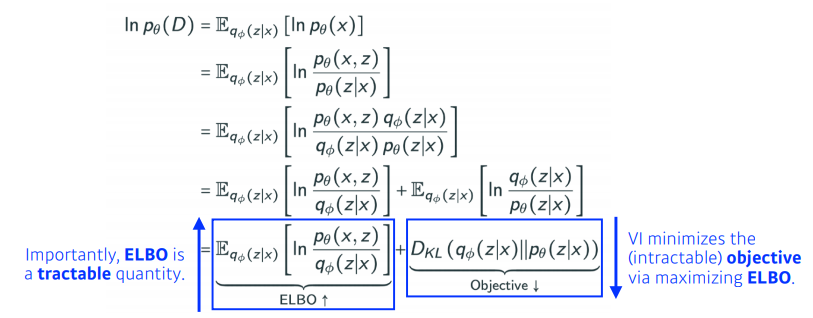
이를 가능하게하는 것이 ELBO이다.
-
궁극적으로 위 수식에서 얘기하고 싶은 것은, 우리가 VI에서 목적이었던, 두 distribution사이의 KL divergence를 줄이는 것이 목적인데 이것이 불가능하다. 그래서 우리는 ELBO라는 것을 계산함으로써 얘를 키움으로써 우리가 원하는 objective를 얻고자 하는 것.
-
결과적으로 내가 뭔지도 모르고, 계산할 수도 없는 것을 내가 어떤 임의의 Posterior distribution과 Variational distribution사이의 거리를 줄이는 어떤 목적을 ELBO를 maximize함으로써 얻어낼 수 있다.
-
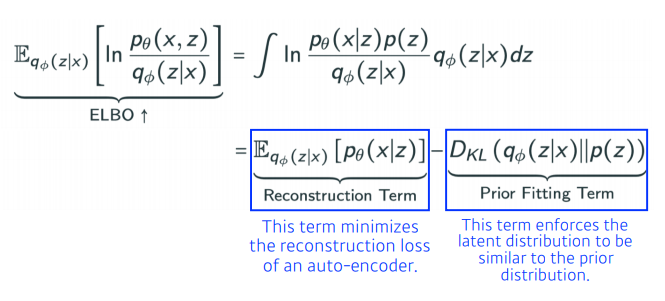
ELBO를 나누어 보면, deconstruction Term과 Prior Fitting Term으로 나뉜다.
-
이것이 encoder를 통해 x라는 입력을 latent space로 보냈다가 다시 encoder로 돌아오는 reconstruction loss를 줄이는 것이 deconstruction term이고, 이미지가 잔뜩 있는데 이 점들이 이루는 분포가 내가 가정하는 이 latent space에서의 prior distribution와 비슷하게 만들어주는 것을 동시에 만족하는 것과 같다는 것이 Variational Auto-encoder이다.
-
Key limitation:
- VA는 explicit한 model이 아니다. intractable model이다.
- prior fitting term이 diffeentiable하다. hence it is hard to use diverse latent prior distributions.
- In most cases, we use an isotropic Gaussian.
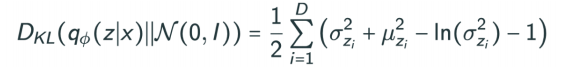
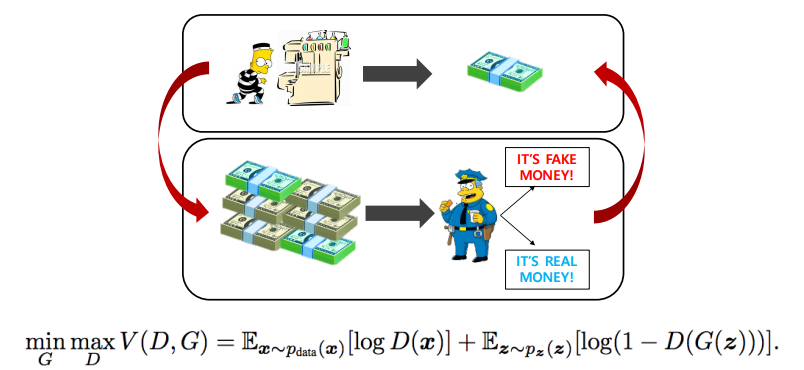
GAN : Generative Adversarial Network
I. Goodfellow et al., "Generative Adversarial Networks", NIPS, 2014
GAN vs VAE
GAN Objective
- two player minixam game between generator and discriminator
- discriminator :

- generator :
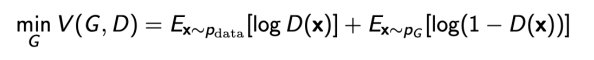
- Plugging in the optimal discriminator:
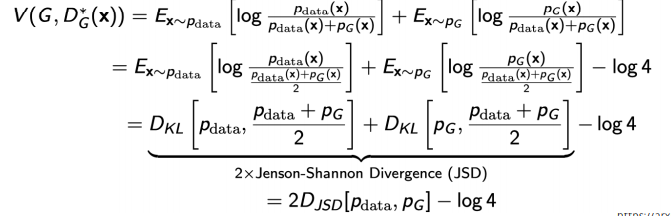
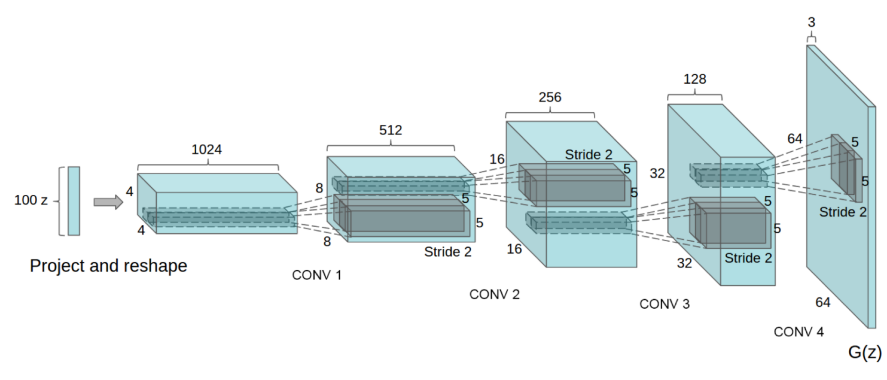
DCGAN
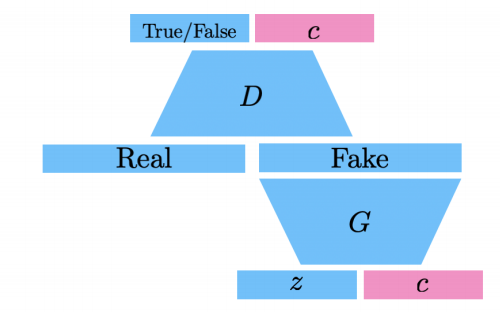
Info-GAN
- 학습을 할 때, 단순히 z라는 것과 진행하지 말고, c라는 class에 대한 값을 추가하여 진행한다.
Text2Image

Puzzle-GAN
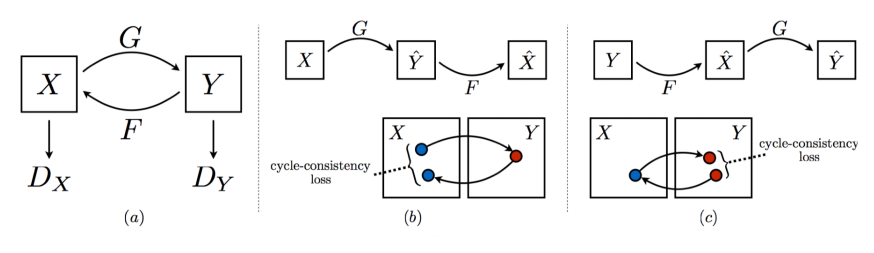
CycleGAN

Cycle-consistency loss
- 매우 중요하다.
Star-GAN

Progressive-GAN

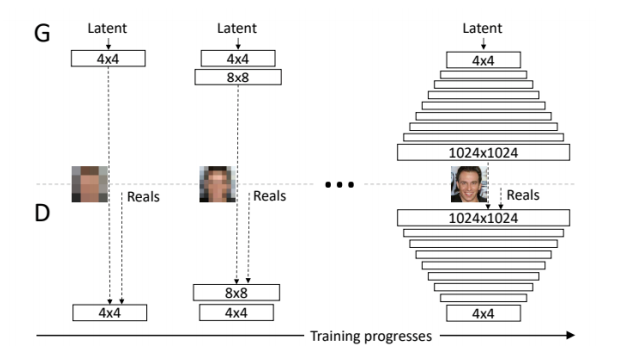
link : https://sensibilityit.tistory.com/508
youtube link: https://www.youtube.com/watch?v=odpjk7_tGY0&t=69s
