2021 부스트캠프 Day 16.
[Day 16] NLP
1. Intro to Natural Language Processing(NLP)
Natural language processing
-
Low-level parsing
- Tokenization
- stemming
-
Word and phrase level
- Named entity recognition(NER)
- part-of-speech(POS) tagging
- noun-phrase chunking
- dependency parsing
- coreference resolution
-
Sentence level
- Sentiment analysis
- machine traslation
-
Multi-sentence and paragraph level
- Entailment prediction (두 문장간의 논리적인 내포, 모순 관계를 예측)
- question answering
- dialog systems
- summarization
Text mining
- Extract useful information and insights from text and document data
- Document clustering (e.g., topic modeling)
- Highly related to computational social science
Information retrieval
- Hightly related to computational social science
Trends of NLP
-
each wod can be represented as a vector through a technique such as Word2Vec or Glove.
-
RNN-family models(LSTMs and GRUs)
-
attention modules and Transformer models.
-
As is the case for Transformer models, most of the advanced NLP models have been originally developed for improving machine translation tasks.
-
customized models for different NLP tasks
-
self-supervised training setting that does not require additional labels.
- e.g., BERT, GPT-3 ...
-
above models were applied to other tasks through transfer learning.
-
NLP research become difficult with limited GPU resourses, since they are too large to train.
2. Bag-of-Words
자연어 처리 및 앞서 말한 텍스트 마이닝 분야에서 딥러닝 기술이 적용되기 이전에 많이 활용되던, 단어를 문서에 대해 숫자로 나타낸 기법.
1. Constructing the vocabulary containing unique words
- sentence : “John really really loves this movie“, “Jane really likes this song”
- Vocabulary : : {“John“, “really“, “loves“, “this“, “movie“, “Jane“, “likes“, “song”}
- 중복이 없는 단어사전을 만든다.
2. Encoding unique words to one-hot vectors
- Vocabulary : : {“John“, “really“, “loves“, “this“, “movie“, “Jane“, “likes“, “song”}

- 단어 간의 거리는 , 유사도(cosine similarity)는 0
A sentence/document can be represented as the sum of one-hot vectors

- 위 벡터를 Bag-of-Words vector라고 부른다.
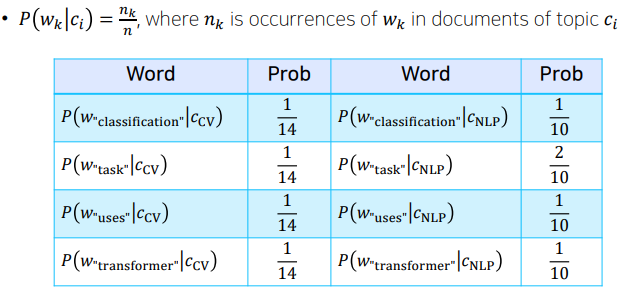
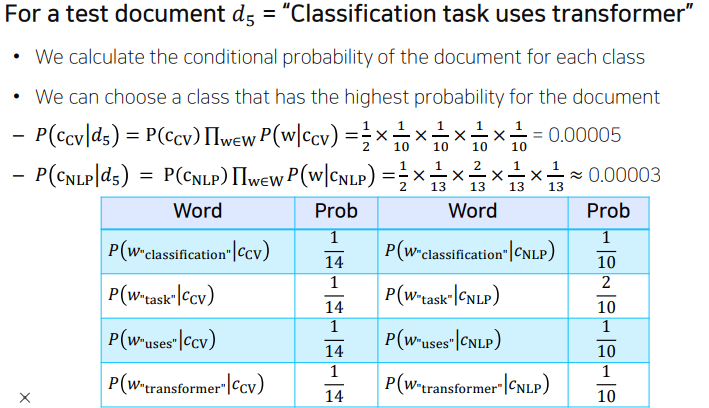
NaiveBayes Classifier for Document Classification
bag-of-words로 나눠진 벡터를 정해진 카테고리로 분류할 수 있는 대표적인 방법



3. Word Embedding : Word2Vec, GloVe
자연어가 단어들을 정보의 기본단위로 해서 이런 단어들의 sequence라고 볼 때, 각 단어들을 어떤 특정한 차원의 한점으로 변환해주는 기법
Word2Vec
-
An algorithm for training vector representation of word from context words(adjacent words)
-
Assumption : words in similar context will have similar meanings

-
Distributional Hypothesis : The meaning of "cat"is captured by the probability distribution
How Word2Vec Algorithm
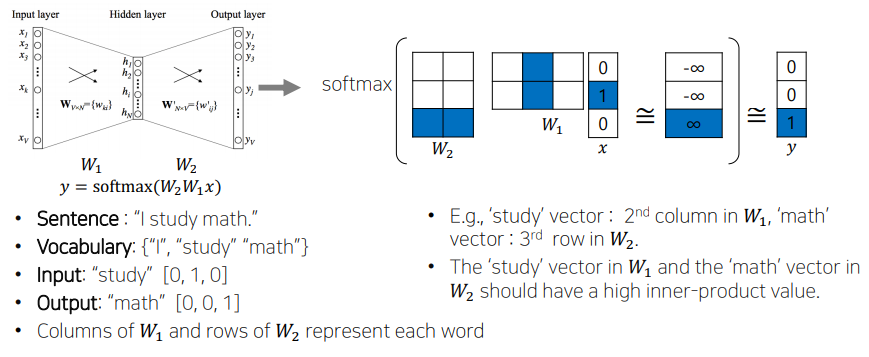
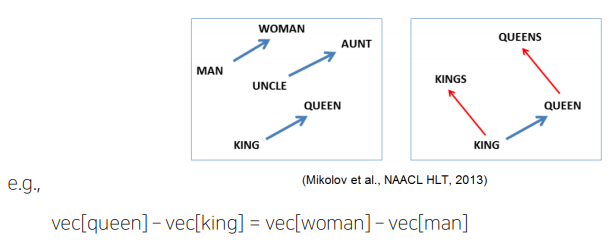
property of Word2Vec
- Intrusion Detection
- 여러 단어들이 주어져있을 때, 나머지 단어와 가상 상이한 단어를 찾아내는 것.
- 나머지 단어들과의 유클리드 거리를 구하고, 평균을 취하면 해당 단어와 나머지 단어들의 평균거리를 구할수있다.
- 평균거리가 가장 큰 단어를 고르게 되면 주어진 단어들 중 가장 의미가 상이한 단어가 된다.
CBOW(Continuous Bag-of-Words)
-
주변 단어들을 가지고 중심 단어를 예측하는 방식으로 학습합니다.
-
주변 단어들의 one-hot encoding 벡터를 각각 embedding layer에 projection하여 각각의 embedding 벡터를 얻고 이 embedding들을 element-wise한 덧셈으로 합친 뒤, 다시 linear transformation하여 예측하고자 하는 중심 단어의 one-hot encoding 벡터와 같은 사이즈의 벡터로 만든 뒤, 중심 단어의 one-hot encoding 벡터와의 loss를 계산합니다.
-
예) A cute puppy is walking in the park. & window size: 2
- Input(주변 단어): "A", "cute", "is", "walking"
- Output(중심 단어): "puppy"
Skip-gram
-
중심 단어를 가지고 주변 단어들을 예측하는 방식으로 학습합니다.
-
중심 단어의 one-hot encoding 벡터를 embedding layer에 projection하여 해당 단어의 embedding 벡터를 얻고 이 벡터를 다시 linear transformation하여 예측하고자 하는 각각의 주변 단어들과의 one-hot encoding 벡터와 같은 사이즈의 벡터로 만든 뒤, 그 주변 단어들의 one-hot encoding 벡터와의 loss를 각각 계산합니다.
-
예) A cute puppy is walking in the park. & window size: 2
- Input(중심 단어): "puppy"
- Output(주변 단어): "A", "cute", "is", "walking"
GloVe
W2V과의 가장 큰 차이점은,
각 입력 및 출력 단어 쌍들에 대해서 학습데이터 상에서 두 단어가 한 윈도우 내에서 총 몇 번 동시에 등장했는지를 사전에 미리 계산을 하고
아래의 수식에서 보이는 것처럼 입력word의 임베딩 벡터 i, 출력 임베딩 벡터i의 내적 값이
두 단어가 한 윈도우내에서 총 몇번 동시에 나타나는가.
그 어떤 값이 log값을 취해서 fitting될수 있도록 그 내적 값이 가까워 질수 있도록 새로운 형태의 loss funtion을 사용했다는 것이다.
이것이 GloVe모델의 W2V과는 다른 학습방법이자 objective function이 된다.
W2V의 경우는 특정한 단어 쌍이 자주 등장한 경우, 자연스럽게 여러번에 걸쳐 학습됨으로써 두 벡터간의 내적값이 더 커지도록 하는 학습 방법을 따랐다면,
GloVe에서는 어떤 단어 쌍이 등장할 확률을 미리 계산하고, 이에 대한 log값을 취한 값을 직접적인 두 단어간의 내적값과 통해 사용하여 학습을 진행했다는 점에서, 중복되는 계산을 줄여줄 수 있다는 장점이 존재할 수 있으며 상대적으로 W2V보다 빠르며 작은 데이터에서도 잘 동작하게 된다.
또한, GloVe모델은 선형대수 관점에서, 추천시스템 알고리즘에서 co-occurence matrix에서 Low-Rank Matrix Factorization의 task로도 이해할 수 있다.
이 외에도 Glove모델에는 세부적인 사항들이 추가적으로 많이 존재하며 큰 틀에서는 이정도의 차이점만 설명한다.
