
-
DB Join이 무엇인지 설명하고, 각각의 종류에 대해 설명해 주세요.
답
Join (조인)
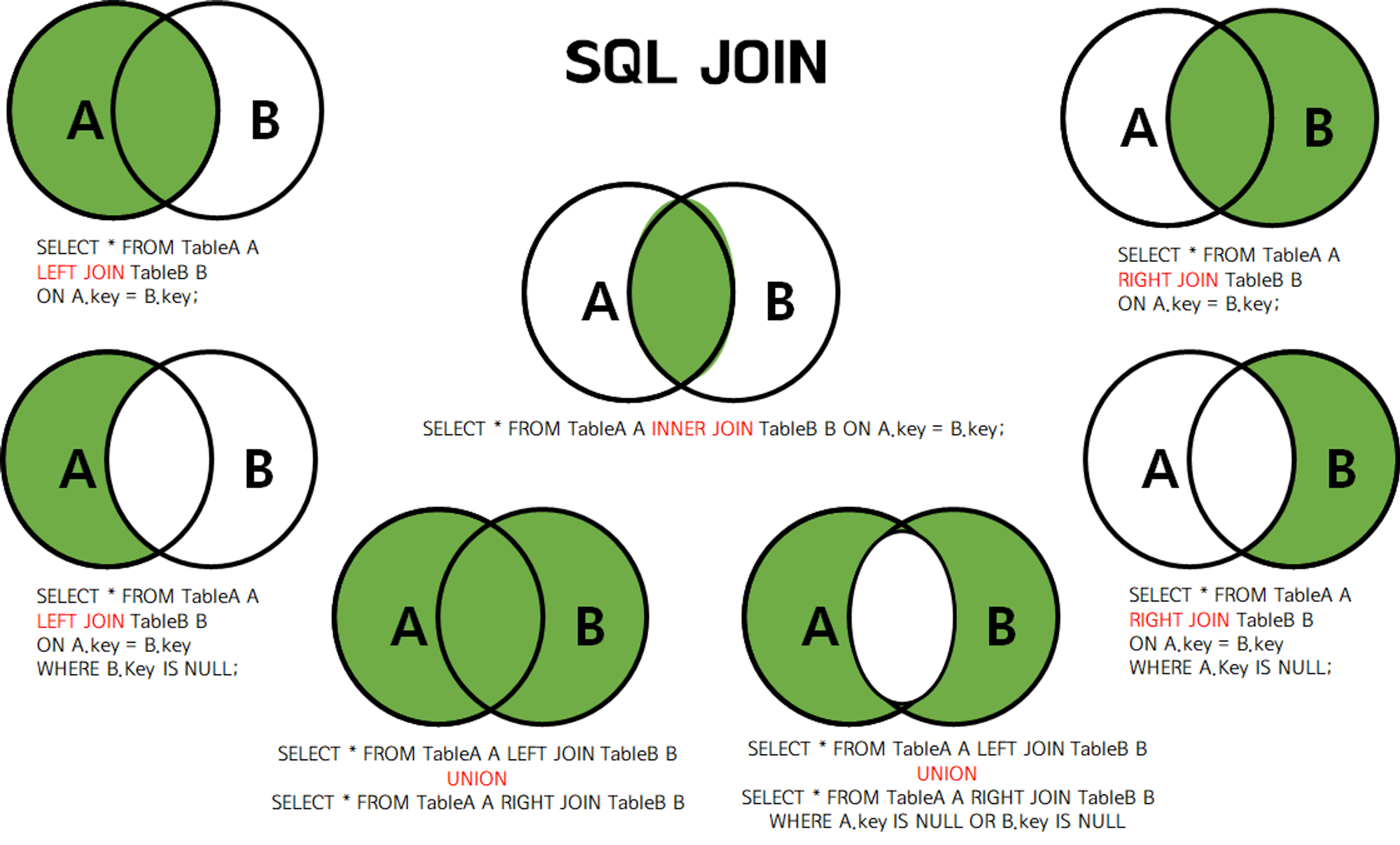
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
- 연결하려면 테이블들이 적어도 하나의 컬럼을 공유하고 있어야 함
- 이 공유하고 있는 컬럼을 PK 또는 FK값으로 사용
- 종류
- 내부 조인(INNER JOIN)
- 가장 많이 사용되는 조인 방식
- 두 테이블의 공통된 값을 가진 행만 출력
- 외부 조인 (OUTER JOIN)
- 일치 하지 않는 행도 결과에 포함시키는 조인 유형
- LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN …
- 셀프 조인(SELF JOIN)
- 하나의 테이블을 대상으로 자기 자신과 조인을 수행
- 교차 조인(CROSS JOIN)
- 두 테이블의 모든 행을 곱한 결과를 출력하는 조인
- 카티션 곱(Cartesian Product) 라고도 함
- 해시 조인 (HASH JOIN)
- 대용량 테이블 간의 조인에 효과적
- 외부조인과 내부 조인 모두에 사용 가능
- 내부 조인(INNER JOIN)
- 사실, JOIN은 상당한 시간이 걸릴 수 있기에 내부적으로 다양한 구현 방식을 사용하고 있습니다. 그 예시에 대해 설명해 주세요.
> 답 > > > ### 내부적으로 구현되는 알고리즘 > > - Nested Loops Join : 중첩 반복을 사용하는 알고리즘 → 가장 기본 > - Hash Join : 조인 컬럼을 기준으로 데이터를 정렬하여 조인 수행 > - Sort Merge Join : 해시 함수를 이용해 데이터 조인 > - 이 중 어느 알고리즘을 정할지는 데이터의 크기, 결합키, 인덱스에 따라 옵티마이저가 결정함 - 그렇다면 입력한 쿼리에서 어떤 구현 방식을 사용하는지는 어떻게 알 수 있나요?
답

- 앞 질문들을 통해 인덱스의 중요성을 알 수 있었는데, 그렇다면 JOIN의 성능도 인덱스의 유무의 영향을 받나요?
답
Join도 인덱스 유무에 영향을 받음
Join 연산에서 인덱스를 사용하면 데이터를 빠르게 검색할 수 있어 성능이 향상됨
- 3중 조인 부터는 동작 방식이 약간 바뀝니다. 어떻게 동작하는지, 그리고 그 방식이 성능에 어떠한 영향을 주는지 설명해 주세요.
답
3중 조인 동작 방식
- 첫 번째 테이블과 두 번째 테이블 조인
- 위의 조인 결과로 나온 테이블과 세 번째 테이블 조인
- 조인 결과 반환
⇒ 조인 연산이 두 번 수행되기 때문에, 조인 조건이 복잡하거나 테이블의 크기가 큰 경우 성능이 저하될 수 있음
-
B-Tree와 B+Tree에 대해 설명해 주세요.
답
B-Tree
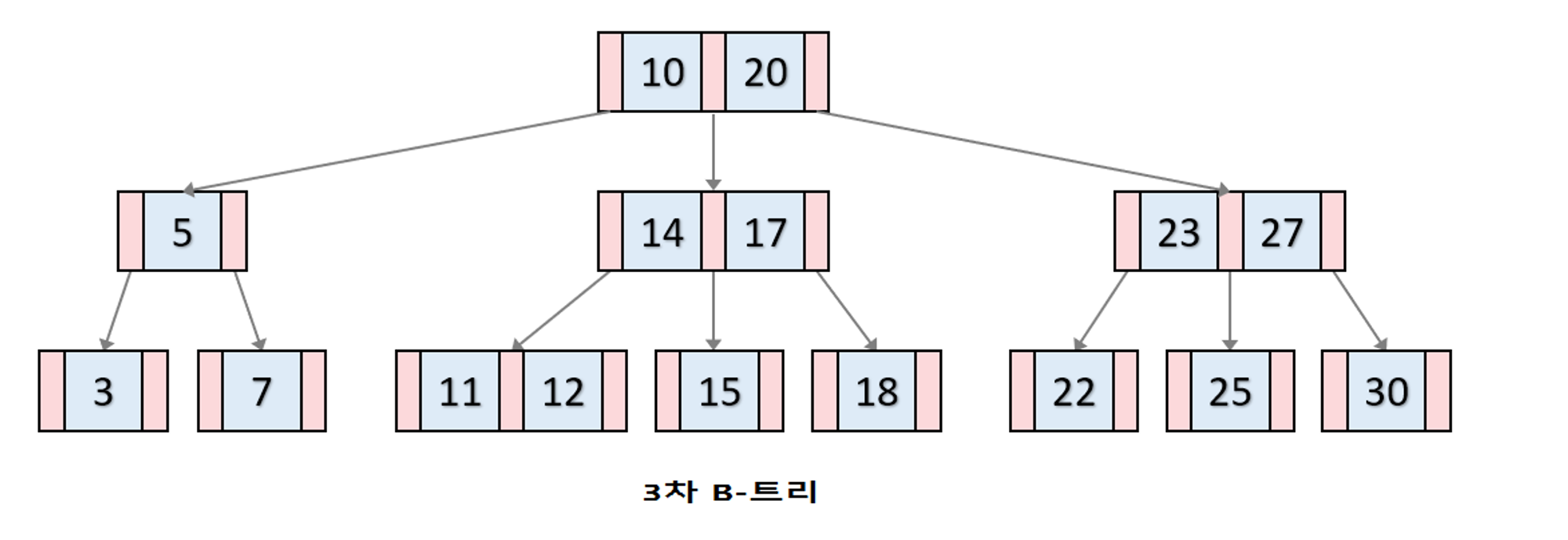
- 데이터베이스와 파일 시스템에서 널리 사용되는 트리 자료구조의 일종
- 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조
- 최대 M개의 자식을 가질 수 있는 B-트리를 M차 B-트리라고 함
B+Tree
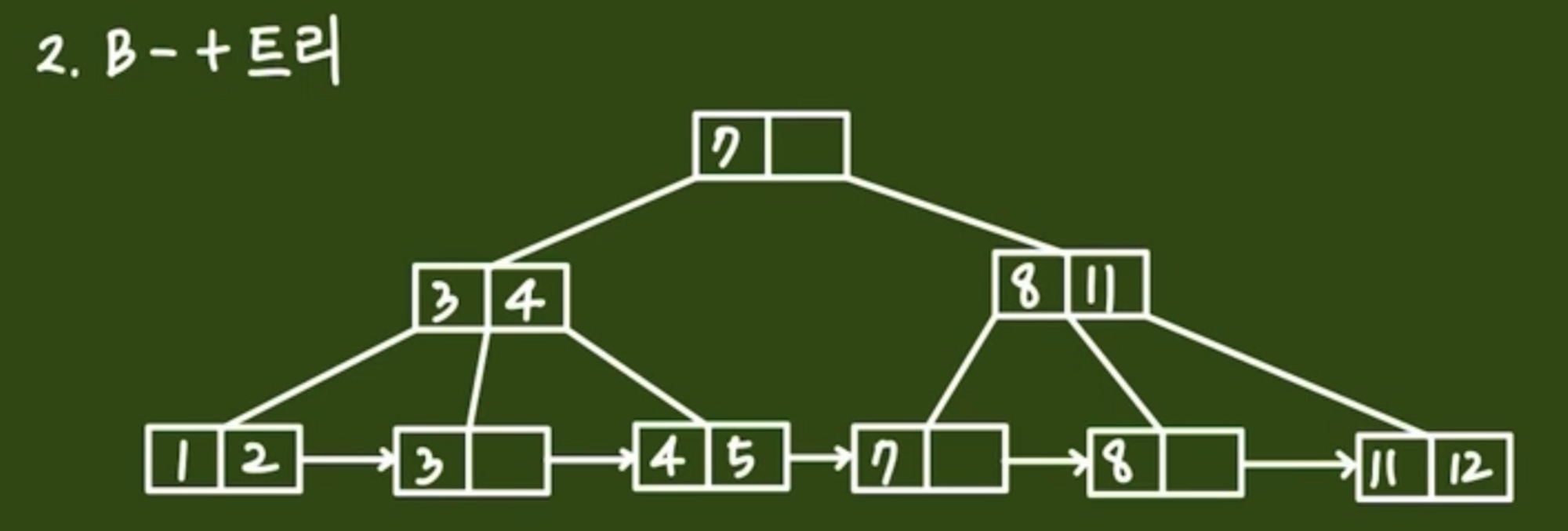
- 데이터베이스 index에 자주 사용되는 자료구조
- B-Tree 계열의 Balanced Tree 종류 중 하나
- 리프 노드가 서로 연결되어있어 형제 노드끼리도 옮겨가며 조회할 수 있음
- 연결된 리프 노드의 리스트를 따라가면서 범위 쿼리를 할 수 있어 범위 검색 성능이 좋음
- 각 노드는 루트 노드를 제외하고 오직 키만을 가지고 있음 → 인덱스를 검색하는 데 더 효율적임
- 그렇다면, B+Tree가 B-Tree에 비해 반드시 좋다고 할 수 있을까요? 그렇지 않다면 어떤 단점이 있을까요?
답
반드시 좋다고 할 수 없다
- B-Tree에서는 자주 access되는 노드를 루트 노드에 가까이 배치하여 루트 노드에서 가까울 경우 브랜치 노드에도 데이터가 존재하기 때문에 B+Tree보다 빠름 → B+Tree는 리프 노드에만 데이터가 존재하여 구현 불가능
- B-Tree에서는 자주 access되는 노드를 루트 노드에 가까이 배치하여 루트 노드에서 가까울 경우 브랜치 노드에도 데이터가 존재하기 때문에 B+Tree보다 빠름 → B+Tree는 리프 노드에만 데이터가 존재하여 구현 불가능
- DB에서 RBT를 사용하지 않고, B-Tree/B+Tree를 사용하는 이유가 있을까요?
답
RBT를 사용하지 않는 이유
- RBT가 이진 탐색 트리이기 때문 → 유연성이 적음
- Red-Black 특성으로 인한 조건이 세부적이라 restructuring이 자주 일어나는데 데이터베이스에서 이 구조를 사용하면 부하가 발생할 가능성이 큼
B-Tree/B+Tree를 사용하는 이유
- 항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없음
- 참조 포인트가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능함
- 데이터 탐색/저장/수정/삭제에도 항상 의 시간복잡도를 가짐
Red-Black Tree (RBT)
- 자가 균형 이진 탐색 트리
- 만족해야 할 조건
- 모든 노드는 빨간색 혹은 검은색
- 루트 노드는 검은색
- 모든 리프 노드는 검은색
- 빨간 노드의 자식은 검은색 (=빨간 노드가 연속적으로 발생할 수 없음)
- 모든 리프 노드에서 black depth는 같음 (리프 노드에서 루트 노드까지의 경로에서 만나는 검은 노드의 개수가 같음)
- 오름차순으로 정렬된 인덱스가 있다고 할 때, 내림차순 정렬을 시도할 경우 성능이 어떻게 될까요? B-Tree/B+Tree의 구조를 기반으로 설명해 주세요.
답
B-Tree의 경우
- B-Tree의 모든 노드를 순회하면서 키를 내림차순으로 재정렬
- 시간복잡도 (n : 인덱스 크기)
B+Tree의 경우
- B-Tree와 같이 모든 노드를 순회하면서 키를 내림차순으로 재정렬
- 시간복잡도 (n : 인덱스 크기)
-
DB Locking에 대해 설명해 주세요.
답
DB Locking
- 여러 세션이 같은 데이터에 동시 접근하였을 때, 한 세션이 트랜잭션을 시작하고 종료하기 전까지 다른 세션이 해당 데이터에 대해 수정할 수 없도록 막는 것
- 일관성 훼손 방지
- 종류
- 공유 락 : 읽기 명령에 주어지는 락
- 베타 락 : 데이터 변경 시 주어지는 락
- Optimistic Lock/Pessimistic Lock에 대해 설명해 주세요.
답
Optimistic Lock (낙관적 락)
- 특정 사용자가 먼저 이 값을 수정했다고 명시하여 다른 사람이 동일한 조건으로 값을 수정할 수 없게 하는 것
- DB에서 제공해주는 특징을 이용하는 것이 아닌 Application Level에서 잡아주는 Lock
- version 등의 구분 컬럼을 이용하여 충돌 예방
Pessimistic Lock (비관적 락)
- reatable 또는 serializable 정도의 격리성 수준 제공
- 트랜잭션이 시작될 때 Shared Lock 또는 Exclusive Lock을 걸고 시작하는 방법
- Transaction을 이용하여 충돌을 예방하는 것
- 물리적인 Lock을 건다면, 만약 이를 수행중인 요청에 문제가 생겨 비정상 종료되면 Lock이 절대 해제되지 않는 문제가 생길 수도 있을 것 같습니다. DB는 이를 위한 해결책이 있나요? 없다면, 우리가 이 문제를 해결할 수 없을까요?
답

-
트래픽이 높아질 때, DB는 어떻게 관리를 할 수 있을까요?
답
과부하가 발생하면 서비스의 속도가 저하되거나 접속이 불가능해지기 때문에 과부하가 발생하기 전 사전 모니터링을 통해 과부하를 줄여야 함
관리 방법
- DB 서버 분산
- 쿼리 최적화
- 캐시 새로고침 빈도 낮추기
- DB Sharding
- DB 서버를 분산하지 않고, 트래픽을 감당할 수 있는 방법은 없을까요?
답
분산하지 않고 감당하는 방법
- 데이터베이스 서버 스펙 향상
- 샤딩으로 데이터 분산 처리
- 서비스에 따라 데이터베이스 분리
해당 글은 보초님 깃허브의 질문을 가지고 작성한 글입니다.
출처
B-트리(B-Tree)란? B트리 탐색, 삽입, 삭제 과정
https://engineerinsight.tistory.com/336#💋 B%2BTree란%3F-1
DB 트래픽 분산시키기(feat. Routing Datasource) | Incheol's TECH BLOG

탐험하는 개발자