[AI : Data representation and problem solving] BERT, GPT
GPT(Generative Pre-trained Transformer)
GPT는 트랜스포머의 디코더 구조만을 활용한 텍스트 생성 모델이다.
GPT는 다양한 텍스트 데이터로 대규모 사전 학습된 트랜스포머를 생성한 후, 특정 생성 작업에 적합하도록 미세 조정을 거친 모델이다.
언어 학습 from Raw data
인터넷에는 이미 수많은 텍스트 데이터들이 존재하며, 이를 데이터셋으로 활용하여 기계가 '언어'를 배우도록 할 수 있다.
전통적인 확률 기반 언어 모델은 주어진 단어들의 시퀀스에 따라 나올법한 다음 단어의 확률을 계산하는 방식으로 표현된다.
P(next word | given words)
예를 들어, 문장 "공부 매우 하기" 다음에 오는 단어를 예측하기 위해, 모델은 "싫다"라는 단어가 올 확률을 계산한다.
P("싫다" | "공부 매우 하기")
이미 기록되어 있는 텍스트 데이터 자체가 일종의 지도 학습 데이터처럼 작동하기에, 위와 같은 확률 모델링은 구체적인 레이블이 필요없다.
GPT는 위와 같은 확률 모델링을 채택하여 인터넷에서 쉽게 접할 수 있는 방대한 양의 텍스트 데이터를 활용해 문맥에 따른 다음 단어의 적합성을 학습하였다.
결과적으로, 고도화된 GPT 모델은 첫 단어만 주어지더라도 그 후에 오게 될 그럴듯한(Likelihood) 시퀀스를 생성해내는 것을 학습하게 된다.
Autoregressive
Autoregressive 모델은 이전 정보를 바탕으로 다음 데이터 포인트를 예측한다.
위에서 설명한 언어 모델링 방식또한 앞의 단어를 기반으로 다음 단어를 예측하는 것을 반복하는 자동 회귀 모델링에 해당한다.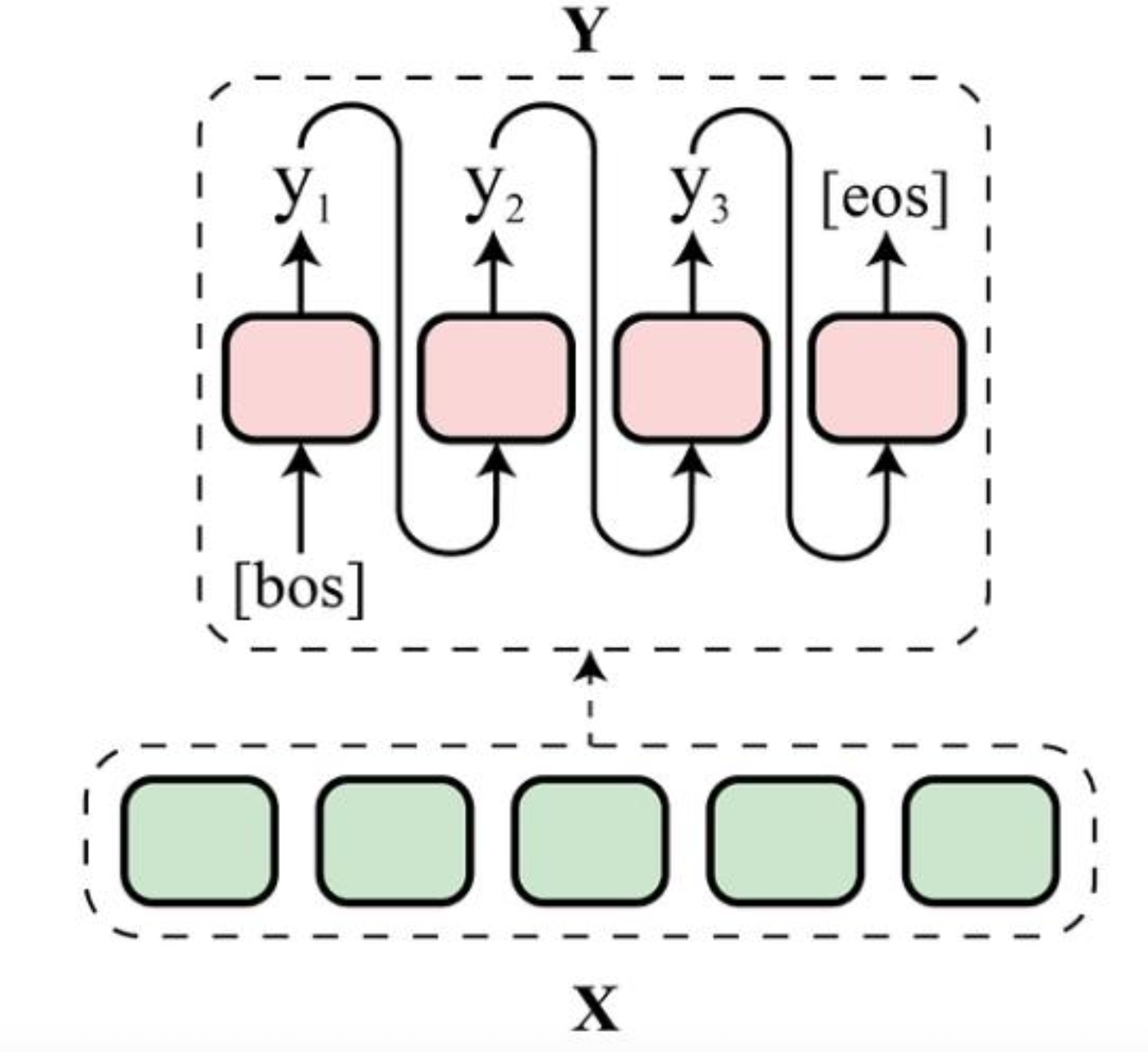
Autoregressive language model의 장단점은 다음과 같다.
장점
-
문맥에 따라 순차적으로 텍스트를 생성하므로 자연스러운 텍스트 생성
-
이전 모든 단어를 고려하여 다음 단어를 예측하므로 높은 문맥 이해 성능
-
여러가지 어법과 주제에 적응력이 뛰어나 유연한 언어 구사가 가능
-
데이터 효율성이 높음
단점
-
단어를 하나씩 생성하기 때문에 생성 속도 제한이 존재
-
초기 오류가 나머지 텍스트 생성에 영향을 미치는 오류 전파 문제
-
이전의 모든 단어 정보를 처리해야 하므로 학습 자원이 많이 필요
-
긴 문장에서 첫 부분의 정보가 끝 부분에 미치는 영향력이 줄어듦
Transformer decoder only
GPT는 위에서 언급한 특징들에 더해 트랜스포머의 디코더로만 구성된 모델이다.
GPT는 입력 시퀀스를 받아 각 시점에서 이전의 모든 출력을 참고하여 다음 출력을 생성하는 방식으로 작동한다.
단일 디코더 구조는 모델의 효율성을 높이고, 계산 자원을 더욱 집중적으로 사용할 수 있도록 한다.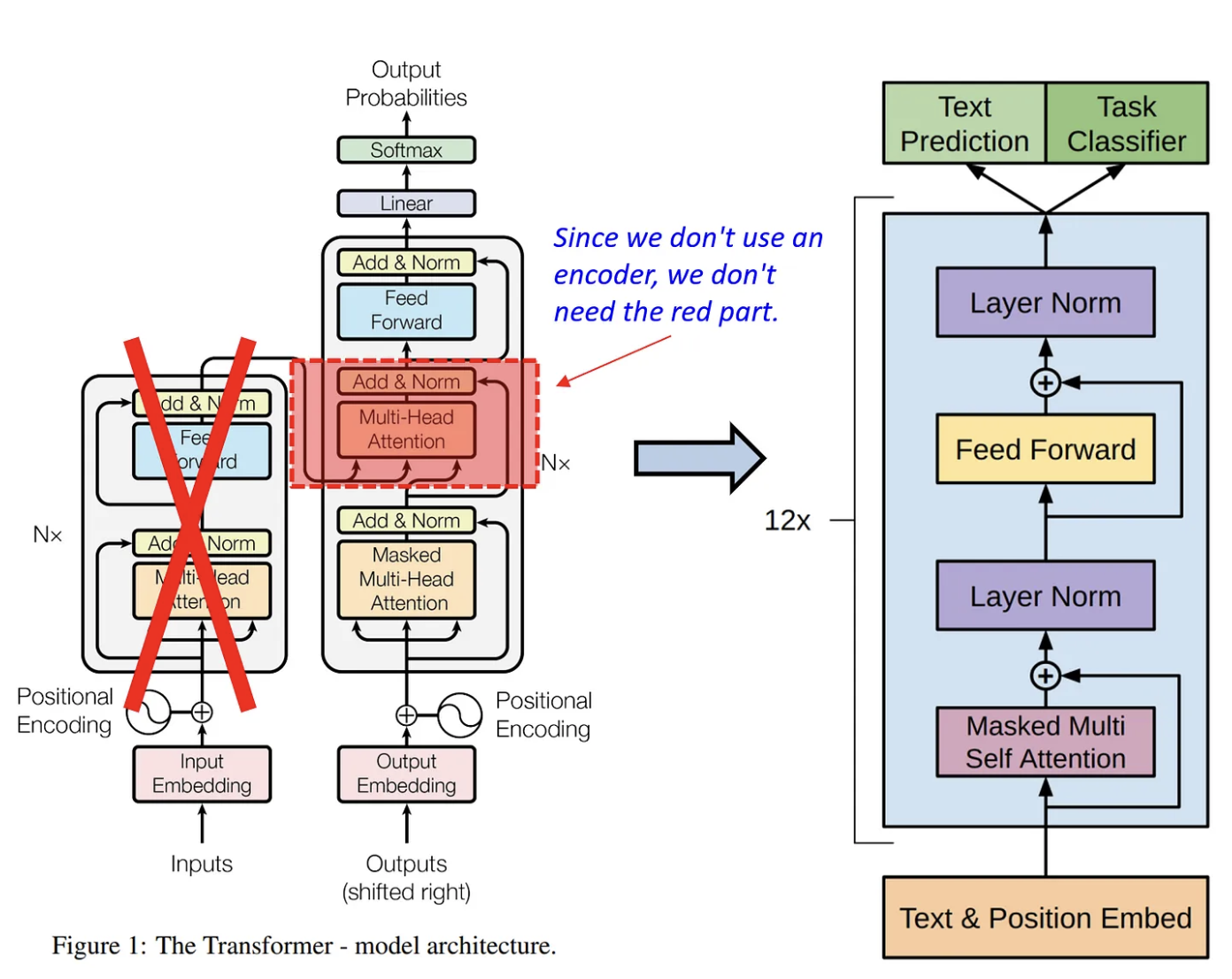
GPT의 진화
GPT 1부터 4까지 여러 버전으로 진화함에 따라 모델의 크기와 복잡성이 대폭 증가하였다.
각 버전은 더 많은 데이터, 더 큰 모델 크기, 더 복잡한 언어 이해 능력을 제공하며, 특히 GPT-3와 GPT-4는 수조 개의 매개변수(파라미터)를 통해 학습된다.
GPT-1
트랜스포머 아키텍처를 기반으로 한 첫 번째 대규모 언어 모델로, 전이 학습의 가능성을 보여줌.
Decoder-only 모델로도 효과적인 언어 학습 가능성, 다양한 NLP 작업 수행 가능성 시사
GPT-2
모델 확장과 데이터셋 증가로 향상된 텍스트 질과 다양성, Zero-shot 능력 강조.
다양한 Task를 하나의 모델로 다룰 수 있음(Multi-modal)을 보여줌.
GPT-3
거대한 모델 크기만으로도 추가 튜닝 없이도 큰 성능 개선이 가능함을 시사
1750억 개의 파라미터를 사용하여 복잡한 언어 이해 및 생성 능력 강화
Few-shot, Zero-shot 능력 크게 향상
거대한 모델은 그 자체로 Reasoning 능력을 가진다는 것을 밝혀냄
GPT 시리즈는 초거대 언어모델이라는 새로운 시대의 문을 열었으며, AI의 사용 가능성을 크게 확장시킨 모델들이다.
BERT(Bidirectional Encoder Representations from Transformers)
BERT는 Google AI에 의해 개발된 모델로, 트랜스포머의 인코더 구조만을 활용한 Encoder-Only 모델이다.
BERT는 특히 양방향 문맥 이해에 중점을 두어 사전 학습을 진행하였다.
새로운 언어 모델링 방식
BERT는 전통적인 언어 모델과는 다른 접근 방식을 채택하였다.
Masked language model, MLM
BERT는 일부 단어를 마스크로 처리하여 모델이 주어진 문맥 안에서 마스킹된 단어를 예측하도록 한다.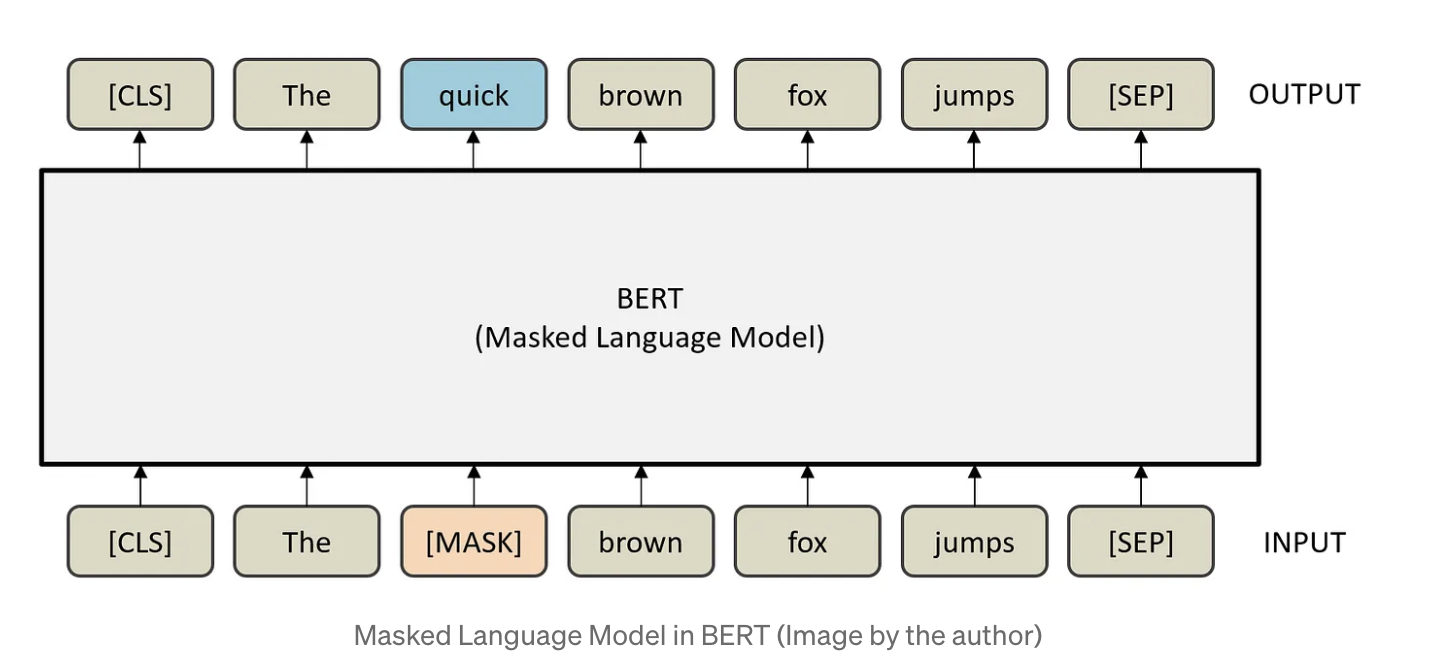
예를 들어, "공부 진짜 하기 [Mask]"라는 문장에서 BERT는 [MASK] 위치에 들어갈법한 단어를 예측한다.
즉, 원본 텍스트에 적절히 MASK를 씌우기만 해도 수많은 문제-답 쌍을 만들어낼 수 있다.
Next sentence prediction, NSP
NSP는 두 문장이 서로 이어질 문장인지 그렇지 않은 문장인지 언어 모델에게 물어보는 형태의 학습이다.
예를 들어,
"고양이가 매트 위에 앉아 있다."
"고양이가 주인을 쳐다보고 있다."
이 두 문장은 실제로 연결되어 있는 문장이며, BERT는 이어질 수 있는 문장이라고 예측해야 한다.
반면
"그는 수영복을 입었다."
"그 테이블은 둥글다."
이 두 문장에 대해 BERT는 이어질 수 없는 문장으로 예측하도록 학습된다.
만약 제대로 학습된 언어 모델이라면 언어의 맥락을 이해할 것이고, 이 맥락에 기반해 다음에 올 문장을 파악할 수 있을 것이다.
Transformer encoder only
BERT는 트랜스포머의 인코더만을 사용해 구성되었다. 다만 단순하게 인코더를 그대로 이어붙인 구조는 아니다.
BERT는 내부 트랜스포머 인코더 블록은 원형 그대로 유지하며, 입력되는 임베딩 레이어에 몇 가지 변화를 주었으며, 인코더 블록의 최상단에 예측 및 결과 출력을 위한 부분이 추가되었다.
즉, Input Layer와 Output Layer는 바뀌었고 그 이외 부분은 트랜스포머의 인코더 블록과 동일하다.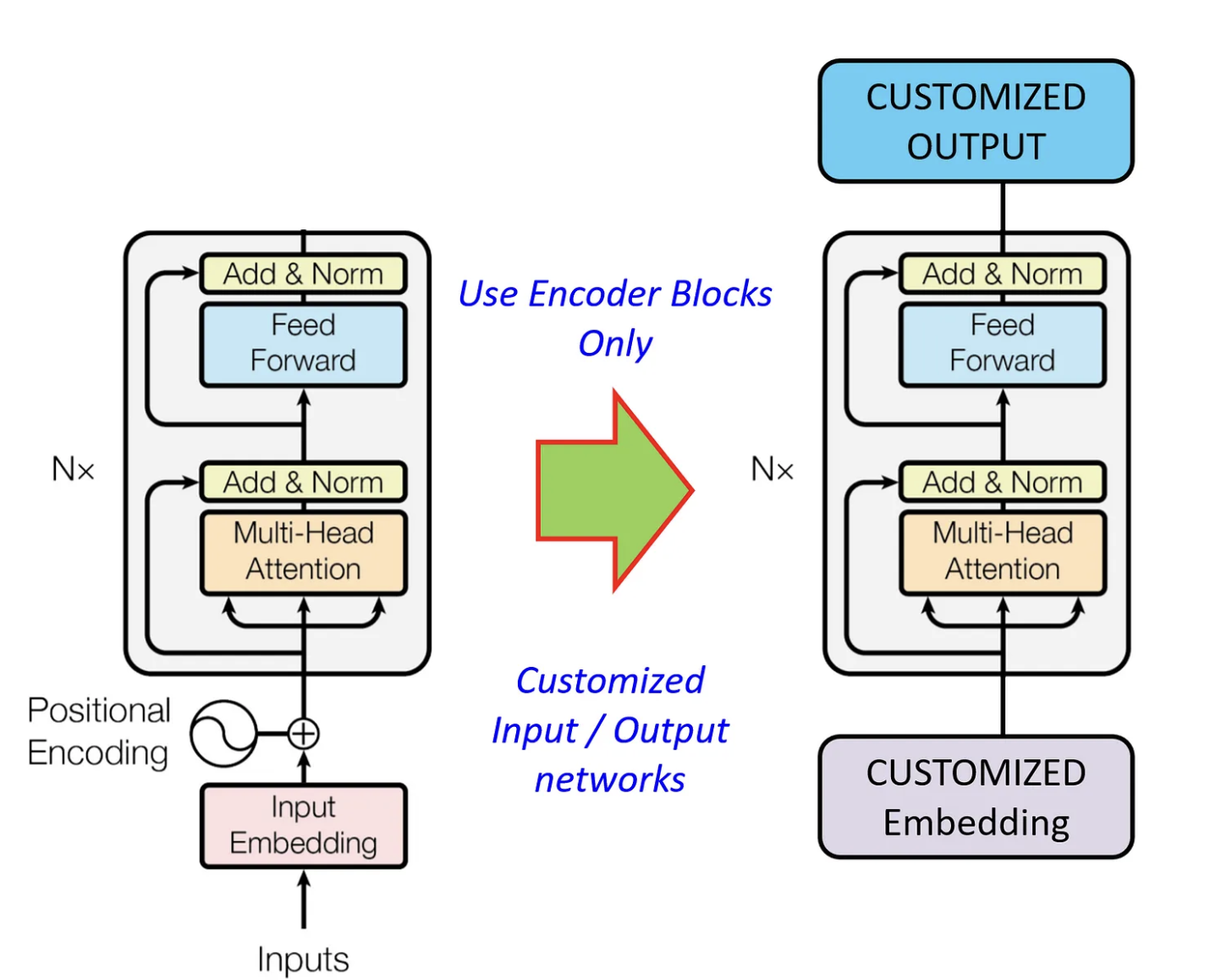
Segment Embedding
BERT가 두 문장을 하나의 입력으로 처리할 때 각 문장을 구분할 수 있도록 하는 정보를 제공하기 위해 Segment embedding을 도입하였다.
이는 특히 NSP 작업에 유용하며, [SEP] 토큰은 두 문장의 경계를 명확히한다.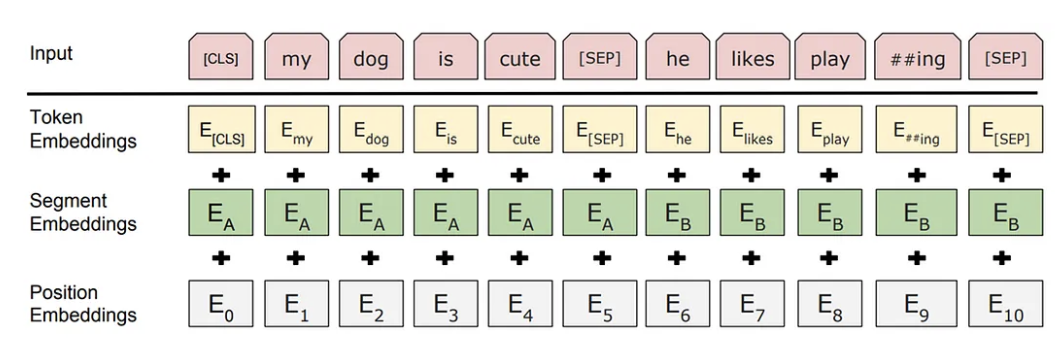
CLS Token
BERT는 Self-attention 메커니즘을 활용하여 CLS 토큰에 모든 단어들의 정보를 집약하여 문장 전체를 압축한 정보를 저장한다.
이후 단계에서 Pooler는 CLS 토큰에 몇 가지 추가적인 처리를 거친 뒤, Sequence Classification과 같은 다운스트림 작업에 사용한다.
학습형 포지셔널 임베딩
포지셔널 임베딩을 진행할 때 전통적인 사인 및 코사인 함수를 사용하지 않고 학습 가능한 파라미터를 도입하여 각 단어의 문장 내 위치에 따른 정보를 더욱 유연하게 적용할 수 있도록 하였다.
즉, BERT가 훈련되는 데이터의 종류에 맞춰 포지셔널 임베딩도 학습되기 때문에 데이터의 특성에 더 민감하게 작동하게 된다.
BERT Pooler
CLS 토큰은 전체 토큰의 정보를 하나로 추상화(요약)한다.
Pooler는 CLS 토큰의 출력에 추가적인 처리를 거쳐 벡터를 생성하는 모듈이다.
Pooler를 통해 생성된 벡터는 Classification과 같은 작업에 활용된다.
이는 다양한 다운스트림 작업에서 활용할 수 있다.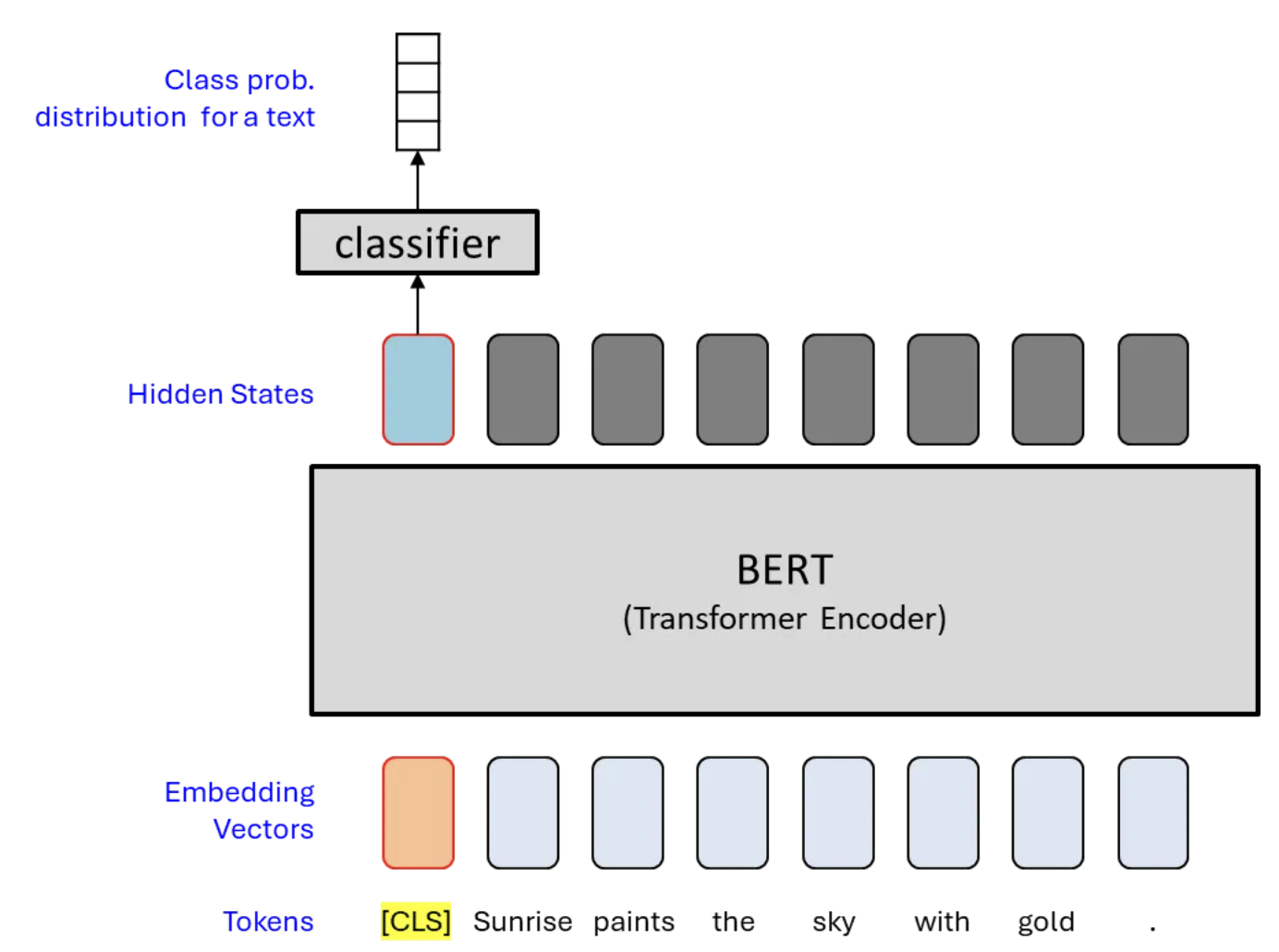
BERT(Encoder Only) vs GPT(Decoder Only)
기본적으로 두 모델 전부 트랜스포머의 아키텍처를 목적에 맞게 수정하여 매우 긍정적인 결과를 얻을 수 있음을 보여주었음.
또한 두 모델 모두 인터넷에 존재하는 방대한 양의 데이터를 Self-supervised learning을 통해 학습을 진행하였음.
BERT는 문맥을 전방향에서 파악하는 능력을 강화하여, 문장 간 관계를 파악하는 데 강점을 보임
GPT는 연속적인 텍스트 생성에 초점을 맞춰 주어진 텍스트에 이어질 내용을 자연스럽게 예측하는 데 강점을 보임
