AI data representation and problem solving
1.[AI : Data representation and problem solving] Representation learning
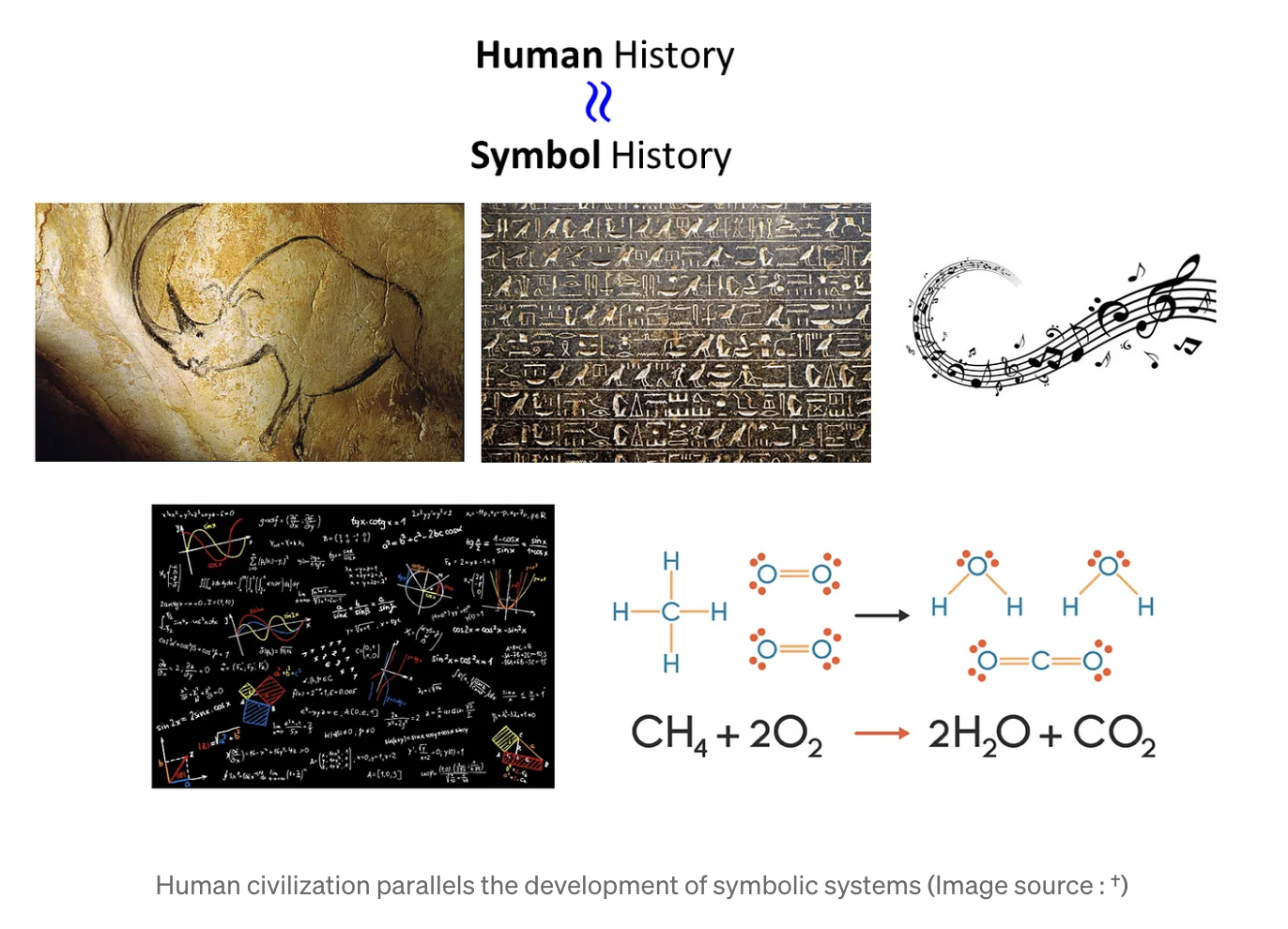
인류가 만들어낸 고도화된 결과물은 대부분 기호 체계를 포함하며, 인류의 역사와 기호의 발전은 밀접한 연관이 있다.즉, 인류는 현실 세계를 표현하는 방법으로 기호 체계를 선택하였다.하지만 컴퓨터(AI)는 인간이 현실 세계를 표현하는 방법을 온전히 이해할 수 없다. 따라서
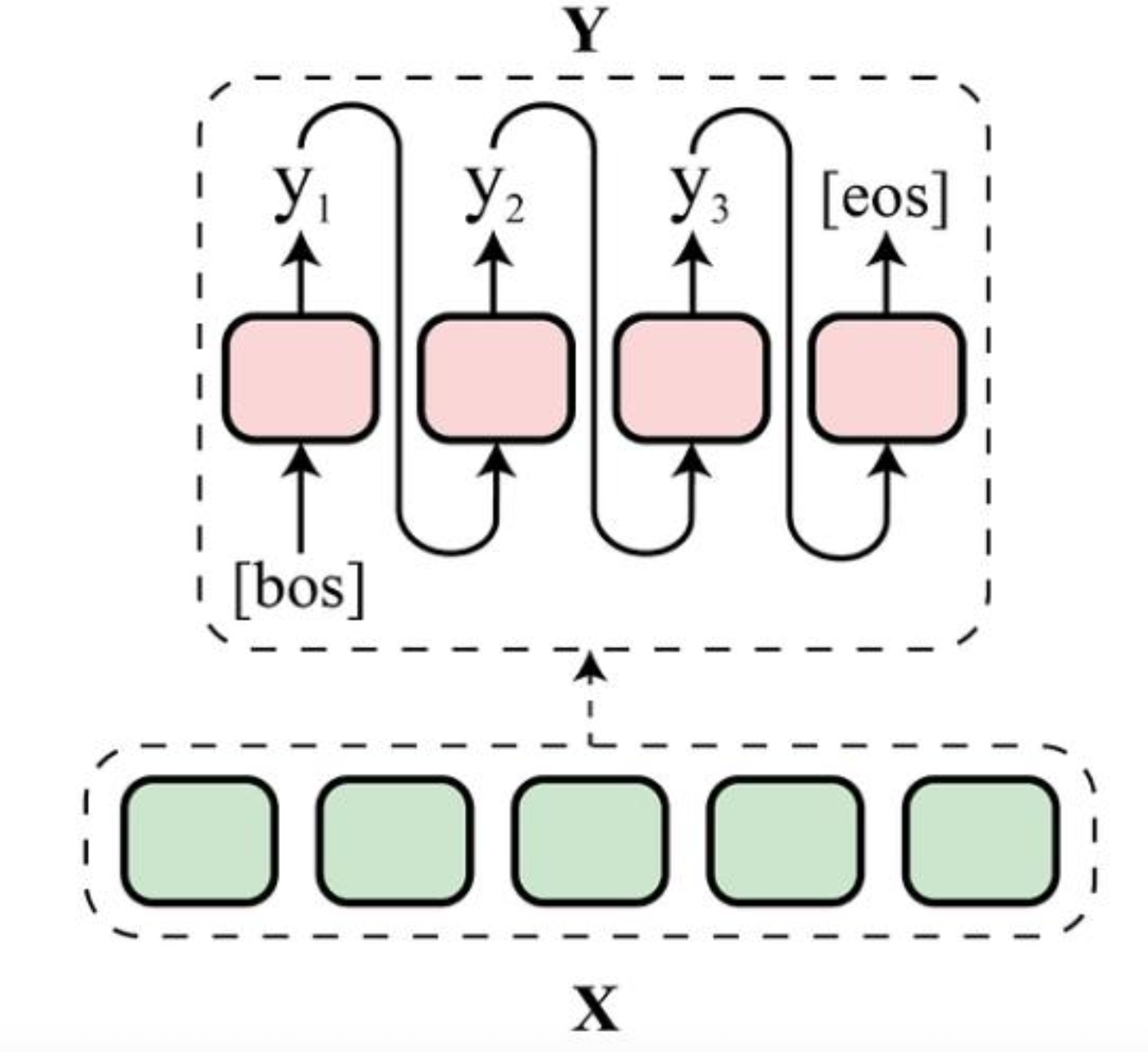
2.[AI : Data representation and problem solving] Sequence to Sequence learning
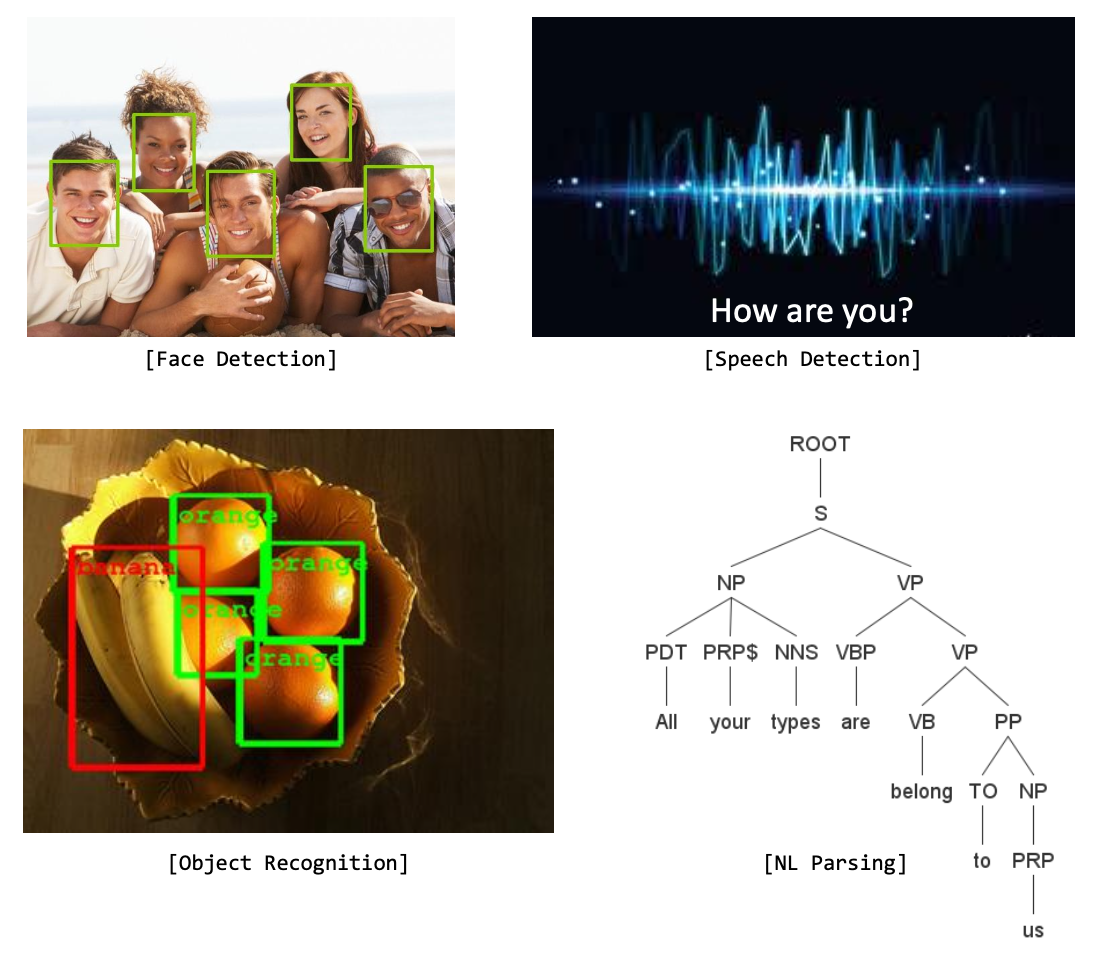
전통적인 머신러닝 문제들은 대부분 사람의 인지 기관을 모방하기 위한 기술이었다.예를 들면 얼굴 인식, 음성 인식, 홍채 인식, ... 등과 같은 문제들이다.반면 최근에는 Sequence-to-Sequence Learning이라는 새로운 프레임워크의 발전으로 해결 가능한
3.[AI : Data representation and problem solving] Embedding : Data to numbers
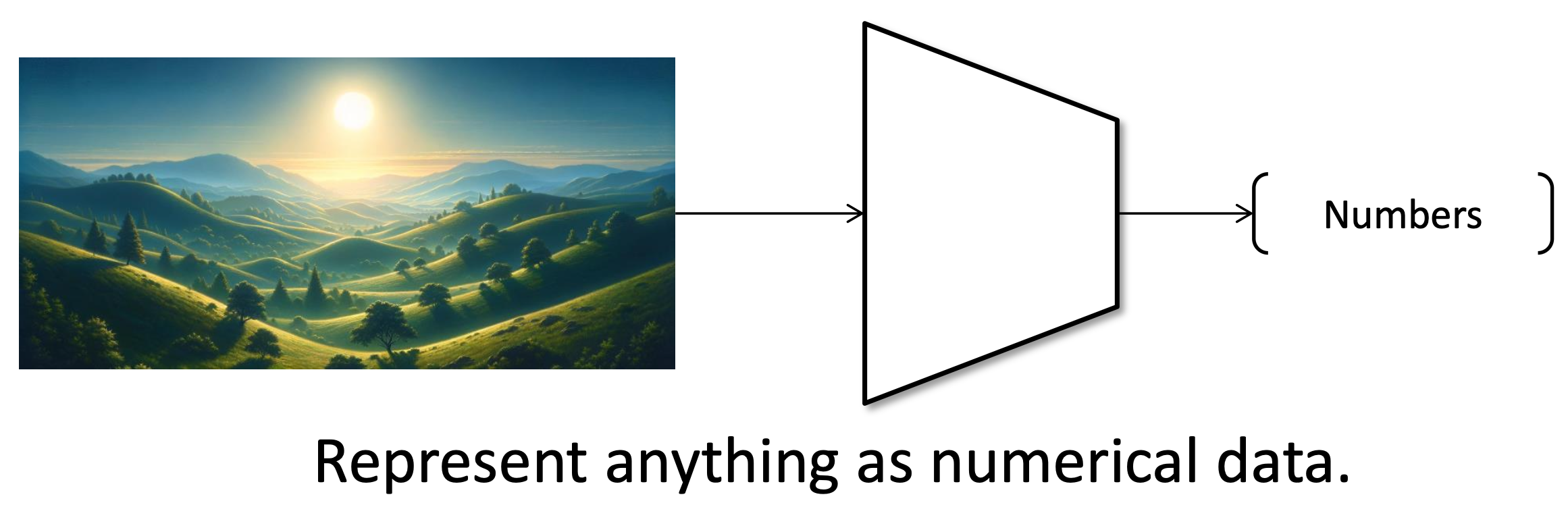
어떤 형태의 데이터든, 컴퓨터가 이해하기 위해선 숫자로 변환하는 과정이 반드시 필요하다.이는Encoding, Embedding, Feature extraction, Vectorization와 같이 다양하게 표현되며, 결론적으로 모두 Data to numbers의 의미를
4.[AI : Data representation and problem solving] Transformer
초기 Seq2Seq 모델은 주로 RNN(순환 신경망)을 활용하여 구현되었다.RNN은 시퀀스 데이터를 처리하는 데 뛰어난 성능을 보인 네트워크였지만, 기울기 소실(Vanishing Gradient), 기울기 폭발(Exploding Gradient), 장기 의존성(Long
5.[AI : Data representation and problem solving] BERT, GPT
트랜스포머의 변형의 대표적인 모델인 BERT, GPT에 대해 알아보자.
6.[AI : Data representation and problem solving] Classification
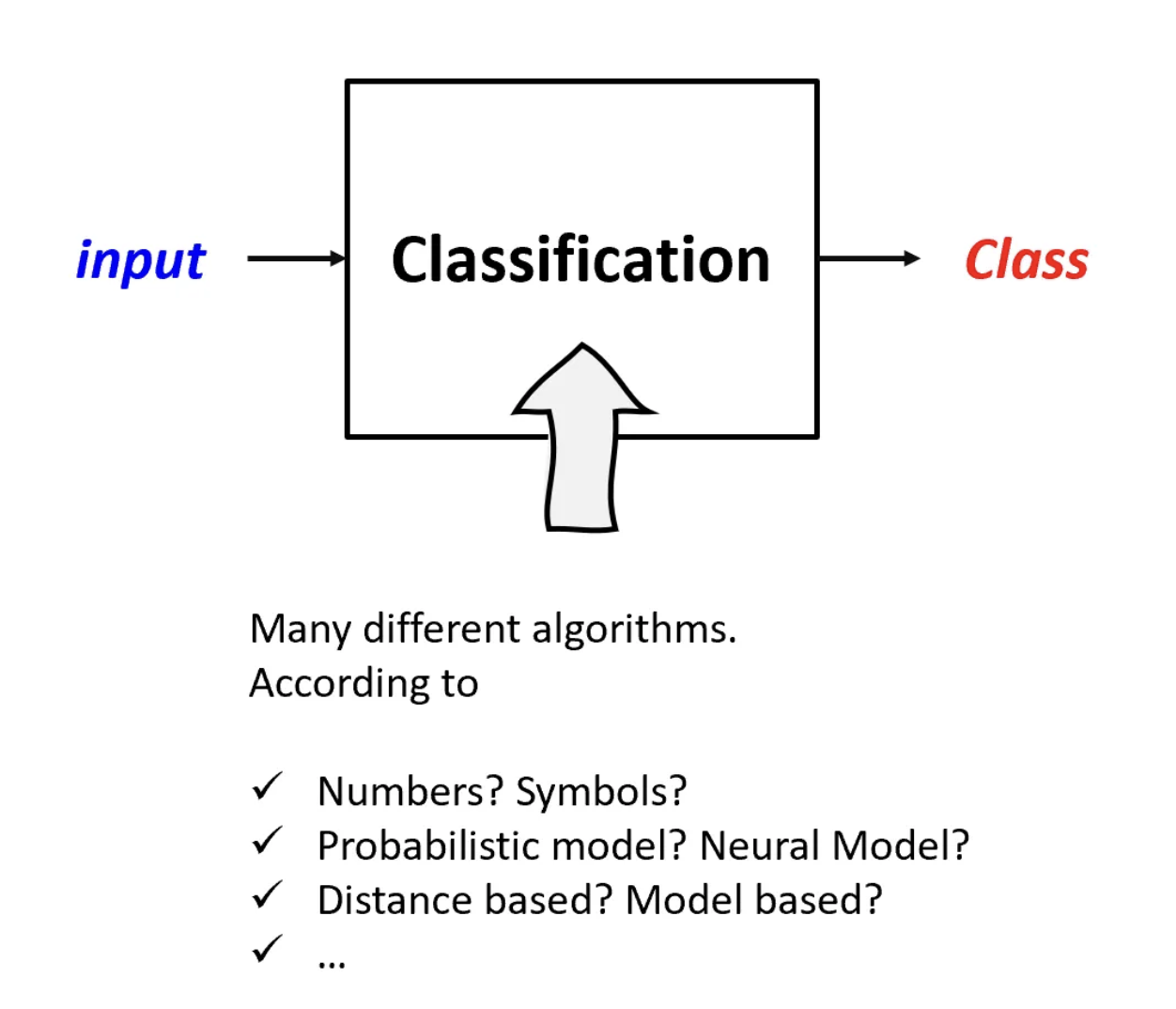
분류란, 입력 데이터가 주어졌을 때, 이를 특정 클래스에 할당하는 과정이다.이는 다양한 형태의 입력(숫자, 기호, ...)과 출력(클래스 레이블)을 처리할 수 있어야 한다.분류를 위한 여러가지 접근법이 존재하며, 각기 다른 분류기는 고유의 장단점이 존재하며 특정 상황에
7.[AI : Data representation and problem solving] Vision Transformer

ViT는 트랜스포머를 이미지 분류 작업에 적용한 신경망이다.앞서 살펴본 것처럼 트랜스포머로 텍스트 처리를 처리하기 위해선, 문장을 시퀀스(단어 리스트)로 나눠 입력으로 전달하였다.Transformer를 이미지 분류에 적용하기 위해선, 이미지를 토큰(token) 시퀀스로
8.[AI : Data representation and problem solving] Speech processing

사람 목소리와 같은 소리를 컴퓨터가 다루기 위해선 소리를 숫자로 변환하는 과정이 필요하다.Sound digitalization소리를 숫자로 변환하는 과정은 다음 단계를 따른다.Waveform extraction (파형 추출)소리를 시간에 따른 진폭(크기)로 나타낸다.S
9.[AI : Data representation and problem solving] CLIP
MotivationVision-Language integration : CLIP은 비전과 언어의 강점을 하나의 통합된 모델로 처리Natural language prompts : CLIP은 자연어 설명을 기반으로 이미지를 이해하고 분류할 수 있음Zero-shot lear
10.[AI : Data representation and problem solving] Autoencoder and VAE

이번 챕터에는 Generative Model의 시초격인 Autoencoder와 Variational Autoencoder에 대해 살펴보고자 한다.사실 엄밀히 따지자면 Autoencoder는 생성형 모델은 아니지만, VAE를 이해하기 위해선 Autoencoder를 떼놓을
11.[AI : Data representation and problem solving] GAN

생성 모델링은 기계 학습의 하위 분야로, 주어진 데이터 분포를 학습하여 새로운 데이터를 생성하는 것을 목표로 한다. GAN은 생성 모델링 분야에 매우 중요한 발자취를 남긴 네트워크이며, Unsupervised learning의 일종이다. Generative Adve
12.[AI : Data representation and problem solving] CGAN, Pix2Pix, CycleGAN
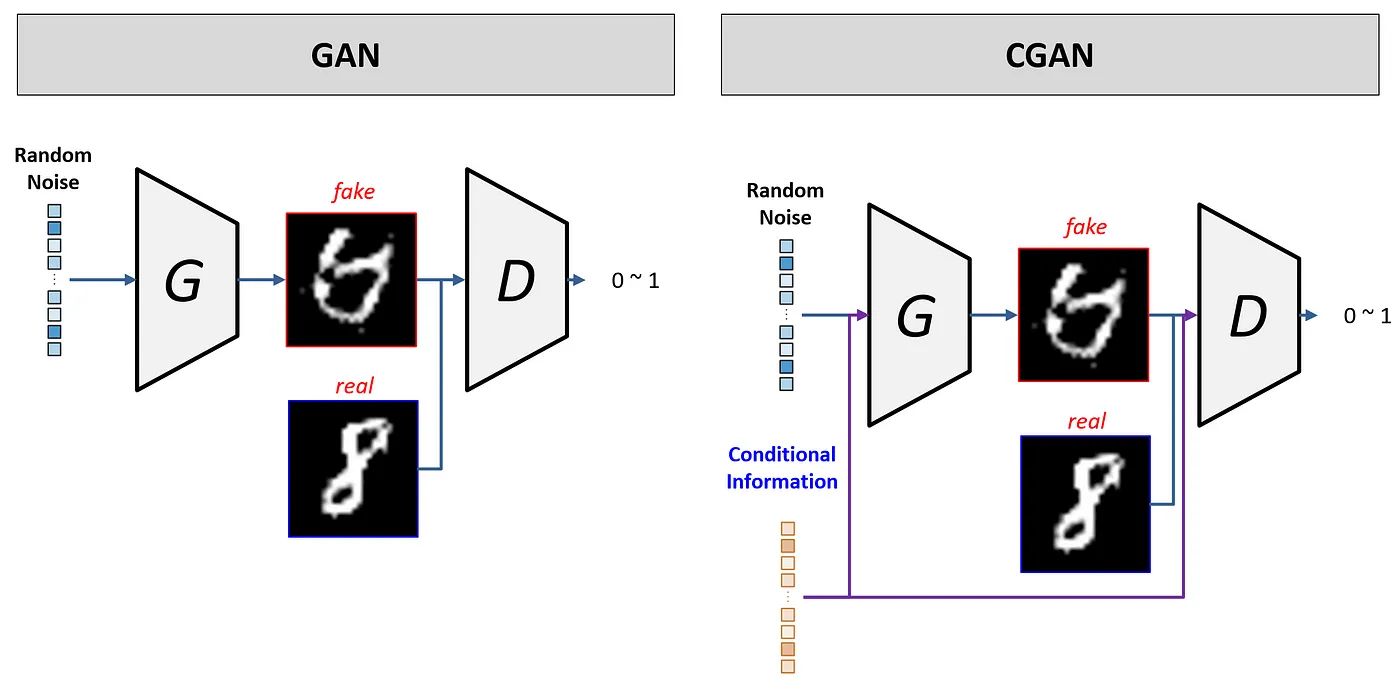
Conditional GAN은 기본적인 GAN 구조에 조건 정보를 추가하여 특정 조건에 맞는 이미지를 생성할 수 있도록 변형한 네트워크이다.기본적인 GAN에서는 생성자가 매번 랜덤하게 이미지를 생성하지만, CGAN은 생성자가 특정 조건을 고려한 이미지를 생성하게 된다.
13.[AI : Data representation and problem solving] Language Model
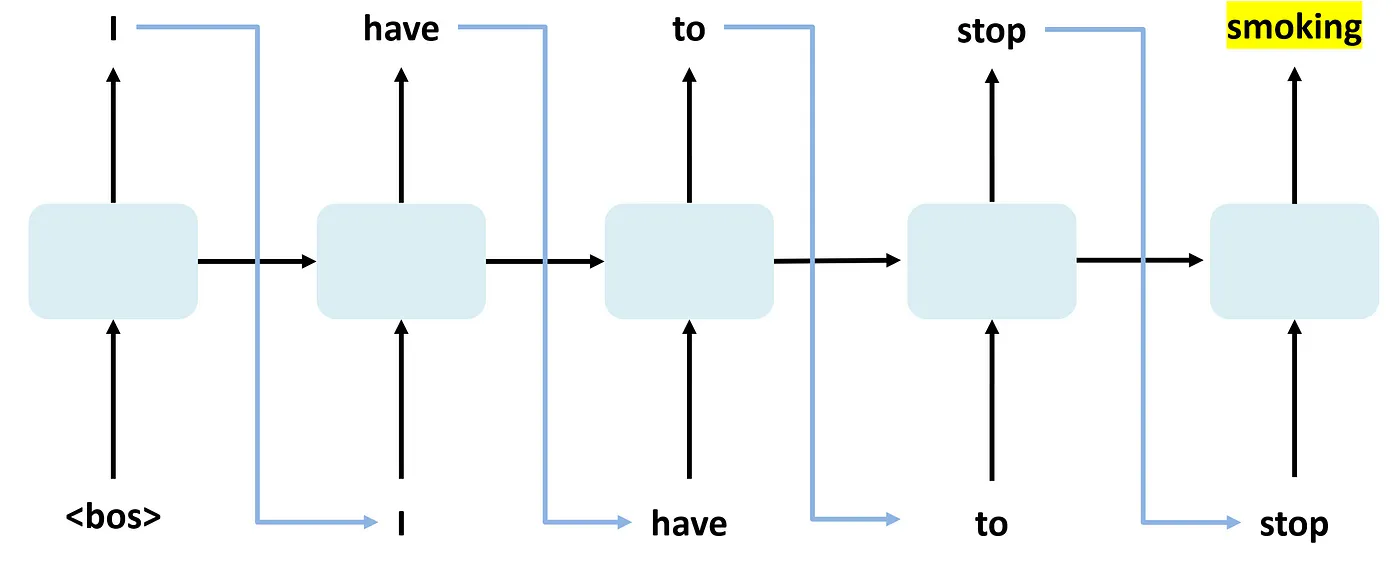
언어 모델(Language Model)이란 주어진 단어 시퀀스에서 다음에 올 단어를 예측하거나, 문장의 구조와 의미를 이해할 수 있는 모델이라고 정의할 수 있다.예를 들어, "I am going to the"라는 문장이 주어진 경우, 언어 모델은 "store", "pa
14.[AI : Data representation and problem solving] Large Language Model - Part 1
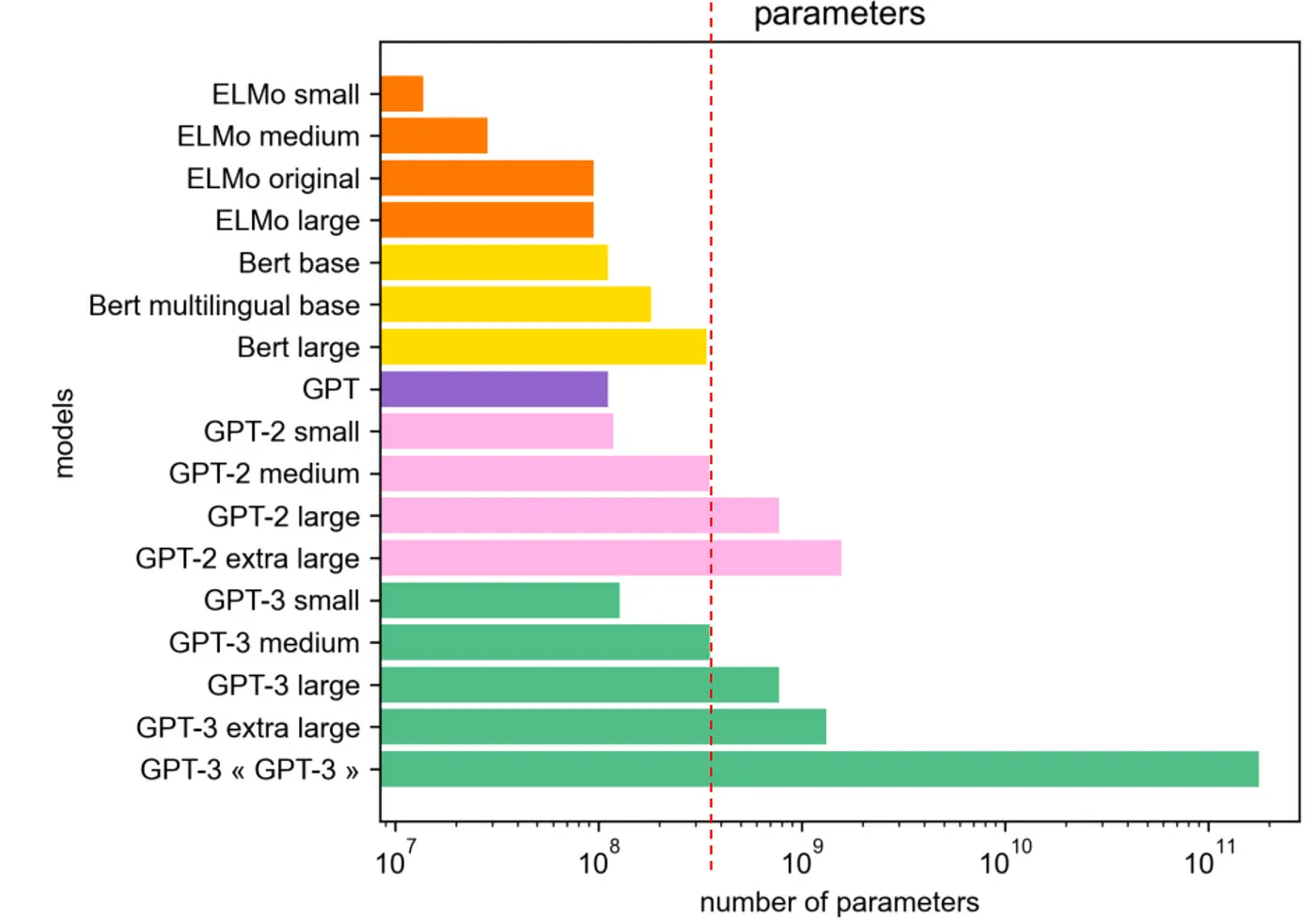
어느정도 크기부터 거대 언어 모델이라고 표현할 수 있을까? 우선 저자는 학문적 기준이 아닌 개인적 기준으로 다음 세 가지를 제시한다.개인의 훈련 가능성개인이 접근 가능한 데이터추론 능력의 유무하나씩 자세히 살펴보자.설명에 앞서, 다음 그림을 보자.다양한 언어 모델은 꾸
15.[AI : Data representation and problem solving] Large Language Model - part 2
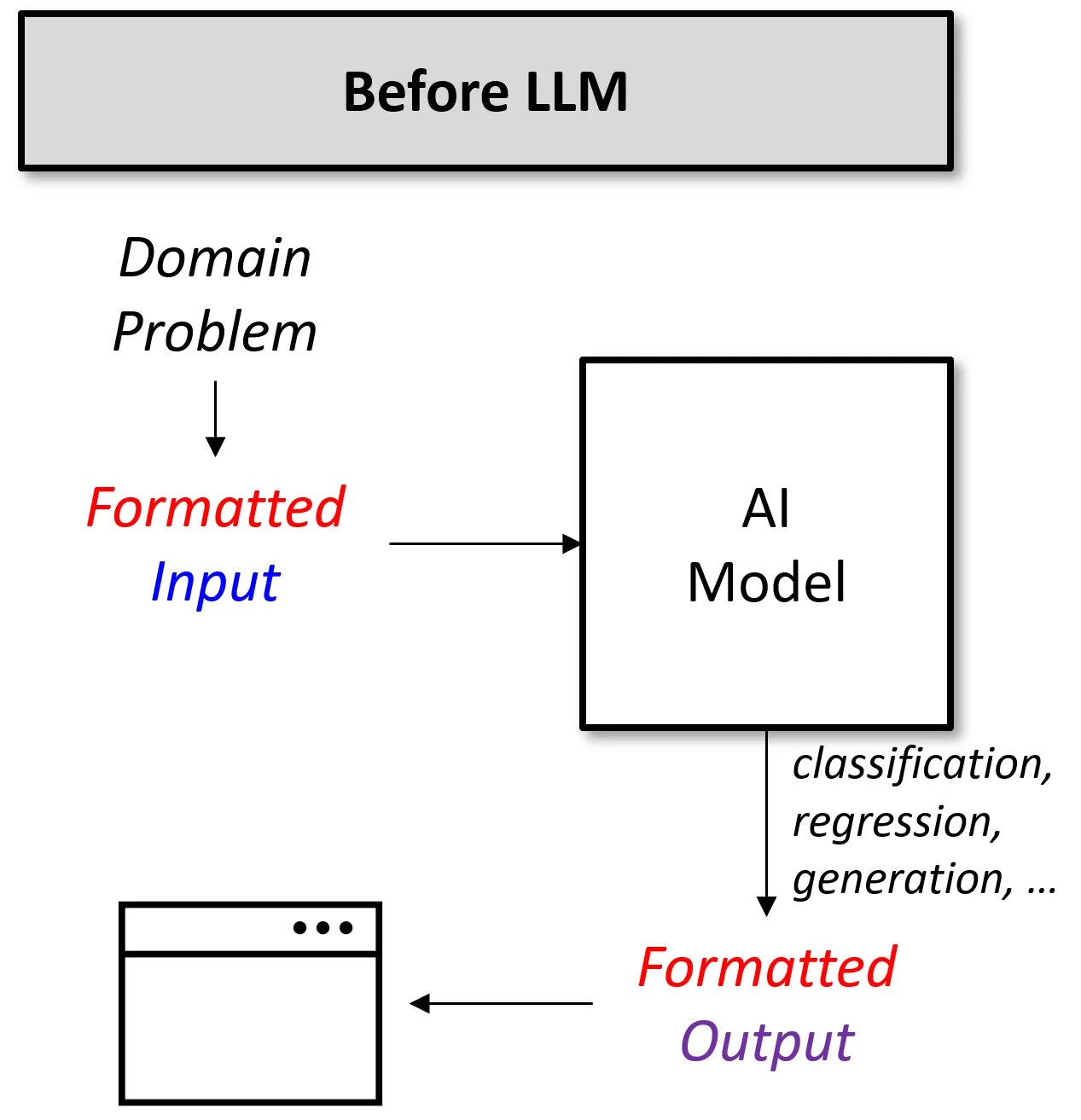
최근 거대 언어 모델들은 거의 모든 문제에 답변을 생성하고 있다. 사람과 대화는 물론이며, 소설을 쓰기도, 코드를 작성하기도, 강의 내용을 정리해주기도, ... 도대체 거대 언어 모델들은 문제를 어떻게 해결하는 것일까? 이번 챕터에서는 이러한 내용들에 대해 살펴보도
16.[AI : Data representation and problem solving] Large Language Model - part 3
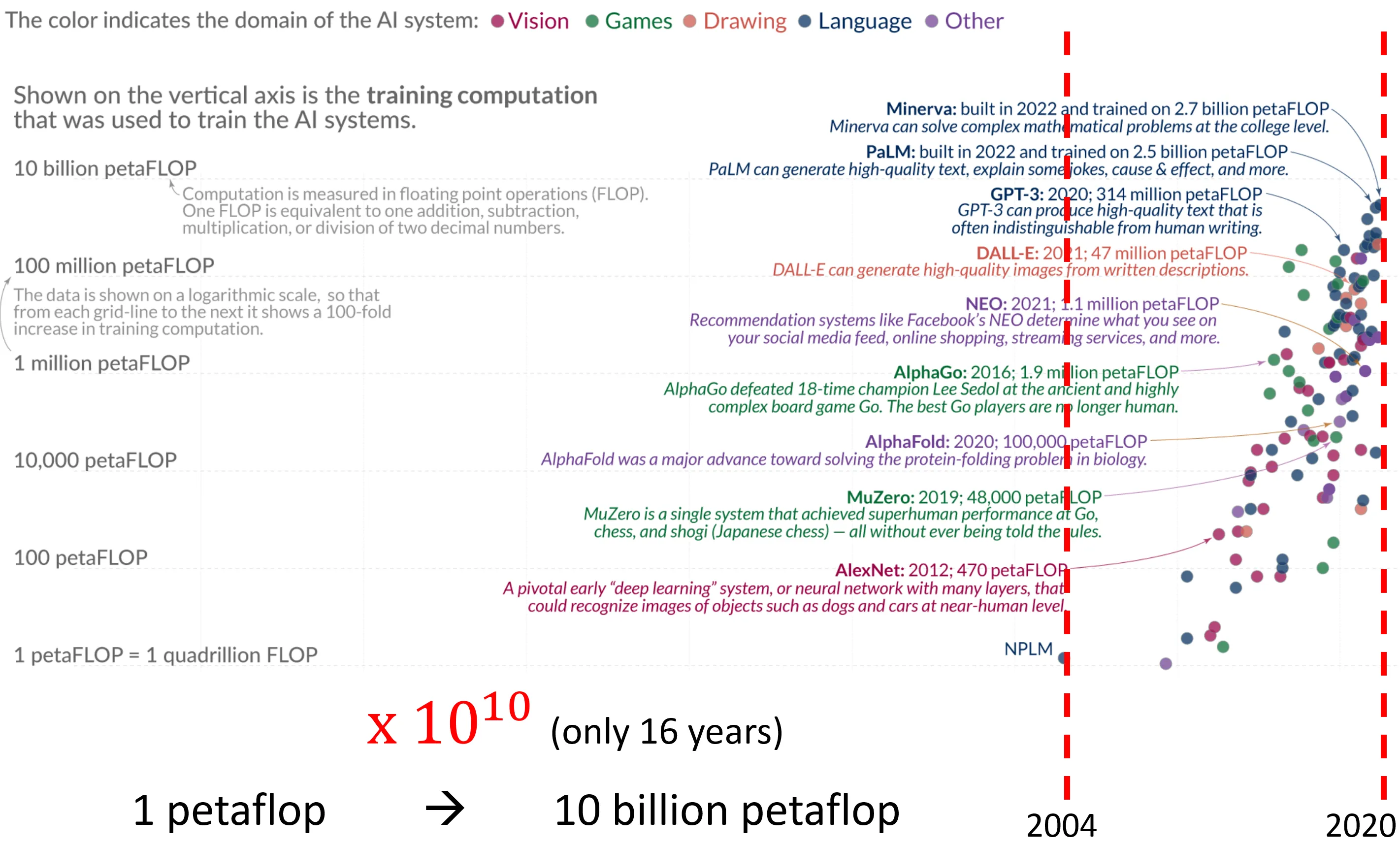
우리는 이전 챕터에서 언어 모델의 크기가 커지게 되면 어느 순간 추론 능력이 생기게 된다는 것을 알게 되었다.즉, 같은 데이터를 입력하더라도 모델의 크기가 커질수록 훨씬 추상적인 작업을 수행할 수 있고, 긴 맥락을 처리 가능하다는 의미이다.그렇다면 앞으로 거대 모델은
17.[AI : Data representation and problem solving] Exploratory AI
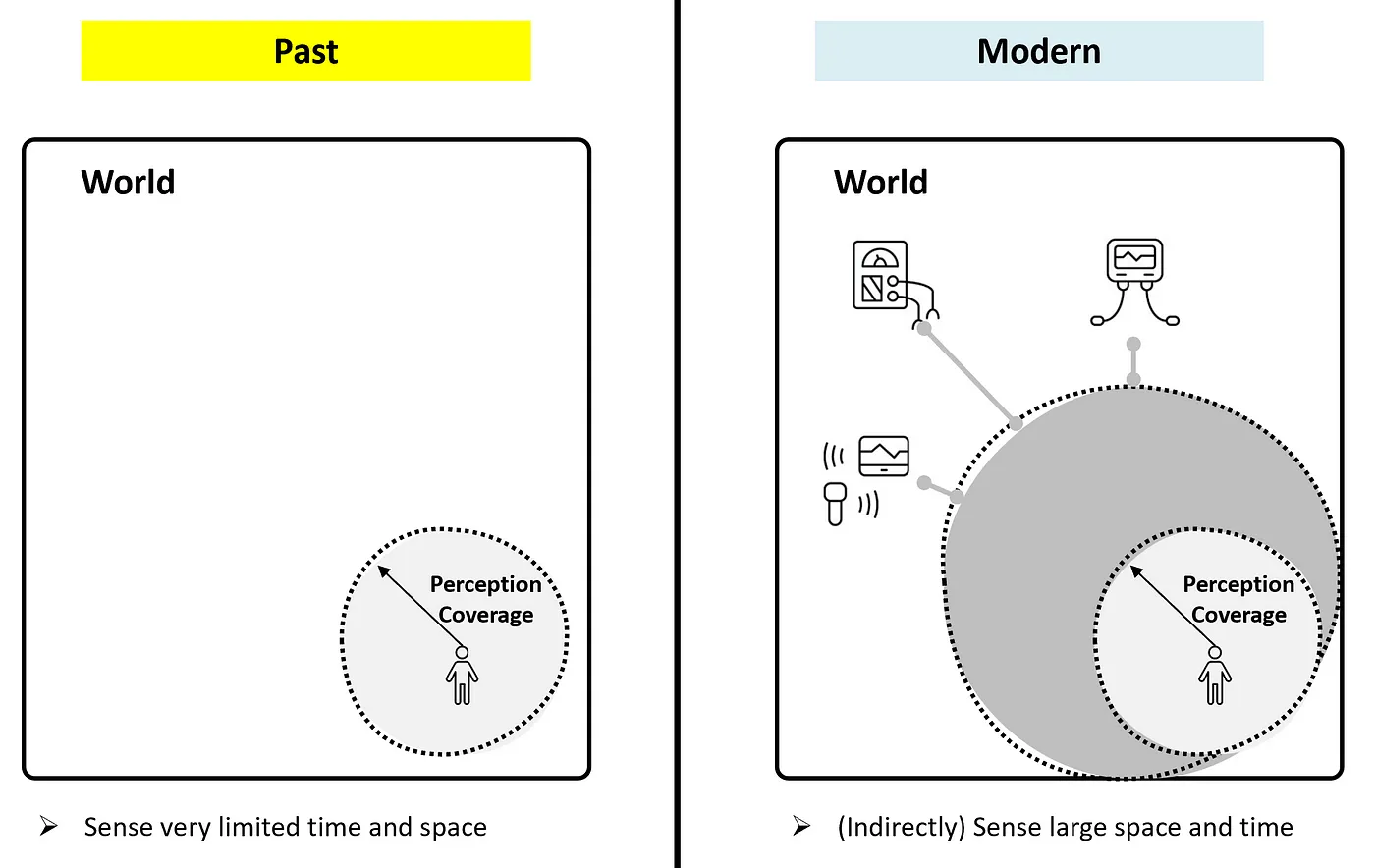
긴 인류의 역사 동안, 우리의 유전적 능력은 만 년 전과 현재는 거의 동일하다.즉, 현재 우리가 갖고 있는 물리적-인지적 능력은 만 년 전과 동일하다.따라서 우리는 매우 제한적인 경험을 할 수밖에 없고, 이는 우리가 접할 수 있는 지식과 경험의 범위를 크게 제한한다.이
18.[AI : Data representation and problem solving] Reinforcement learning
강화 학습 기술은 머신러닝 기술들 중 상대적으로 일상 생활에 적용하기 어려운 기술이었다.하지만 최근 다양한 분야에 강화 학습이 적용됨에 따라, 기계가 새로운 길을 탐색하고 이를 인간에게 제시하는 역할을 수행하고 있다.강화 학습(Reinforcement Learning,