[AI : Data representation and problem solving] Vision Transformer
Vision Transformer
ViT는 트랜스포머를 이미지 분류 작업에 적용한 신경망이다.
앞서 살펴본 것처럼 트랜스포머로 텍스트 처리를 처리하기 위해선, 문장을 시퀀스(단어 리스트)로 나눠 입력으로 전달하였다.
Transformer를 이미지 분류에 적용하기 위해선, 이미지를 토큰(token) 시퀀스로 변환해야 한다.
이를 위해 이미지를 작은 Patch(조각)들로 잘라 벡터화한다.
위의 경우, 각 패치는 16 16 3 = 768 차원의 벡터이며, 이러한 196개의 패치가 생성되는 것이다.
각 패치들은 입력으로 전해지기 전에 임베딩되어 입력을 위한 최종적인 형태로 변환된다.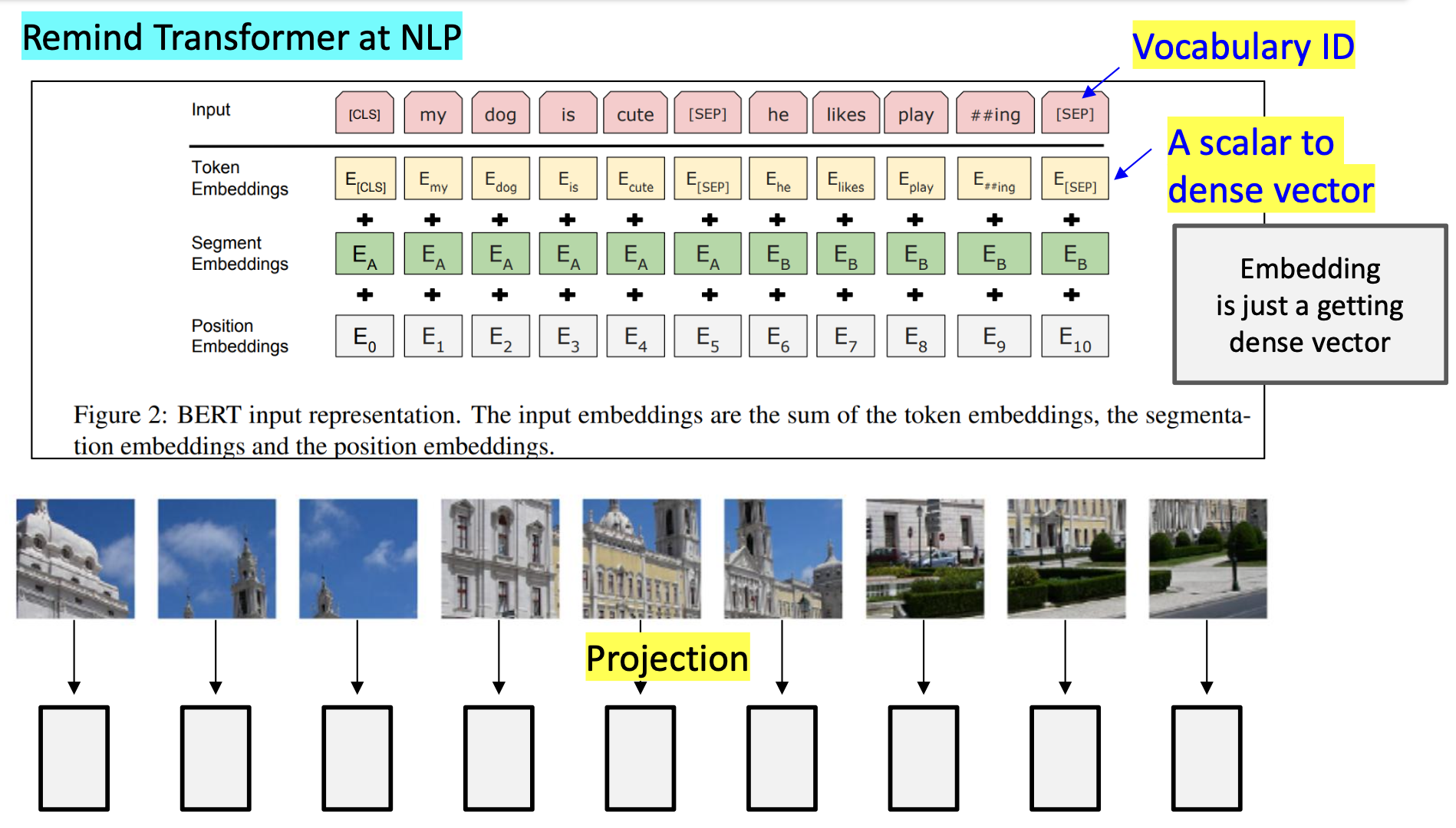
트랜스포머는 입력 시퀀스의 순서를 알지 못하므로, 포지셔널 인코딩 방식을 적용한다.
또한 이미지가 어떤 클래스에 속하는지 판단하기 위해 [CLS] Token을 시퀀스의 맨 앞에 추가한다.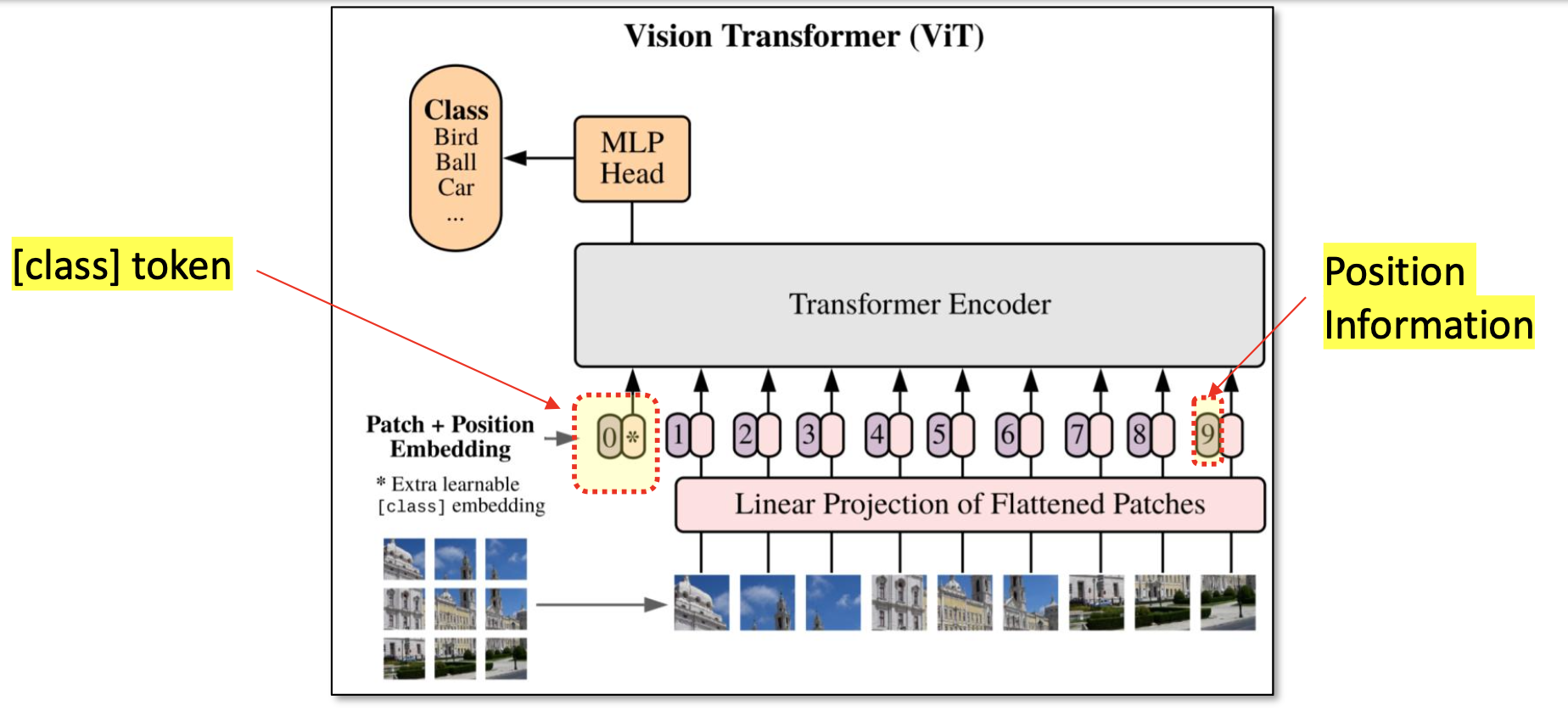
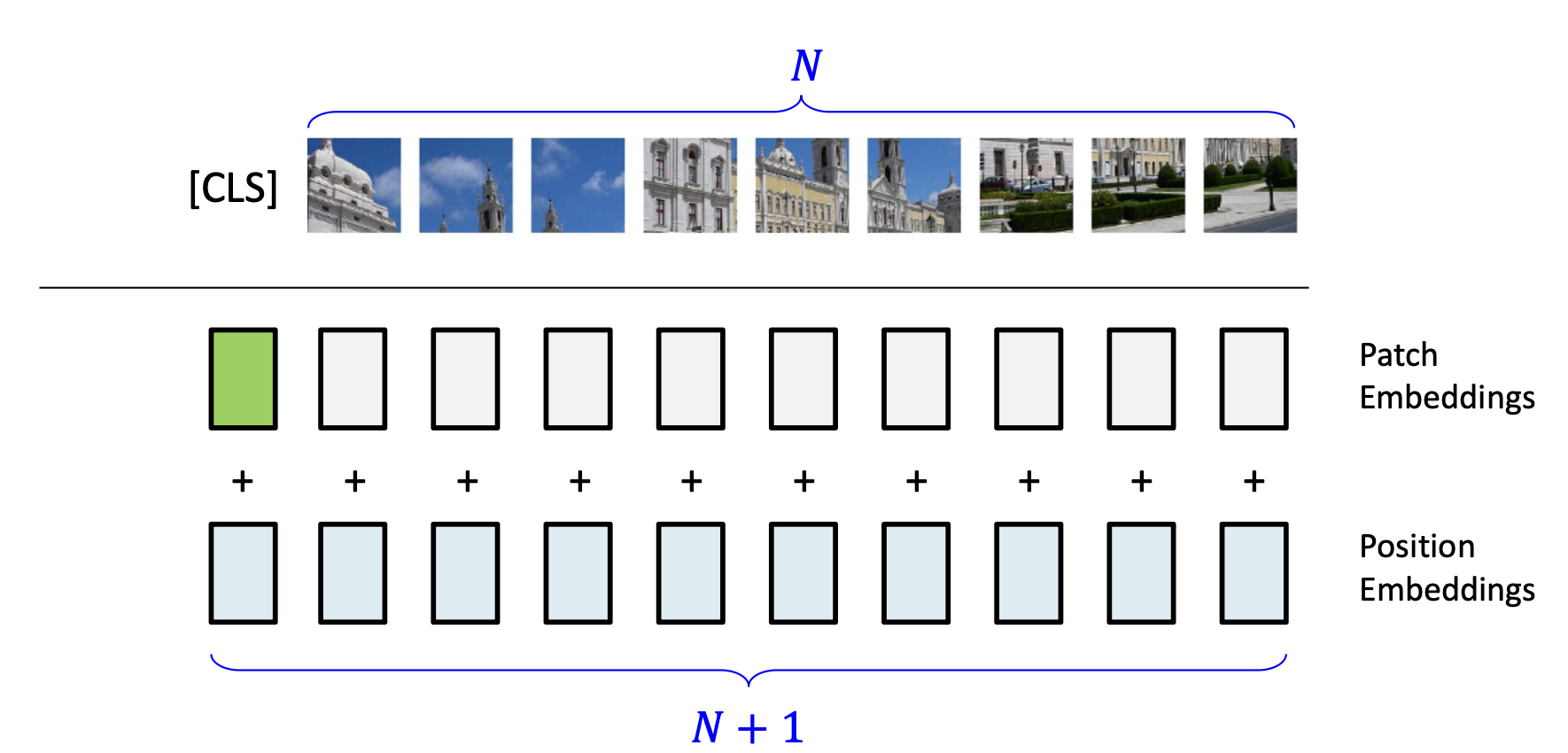
다음과 같이 흐름을 정리할 수 있다.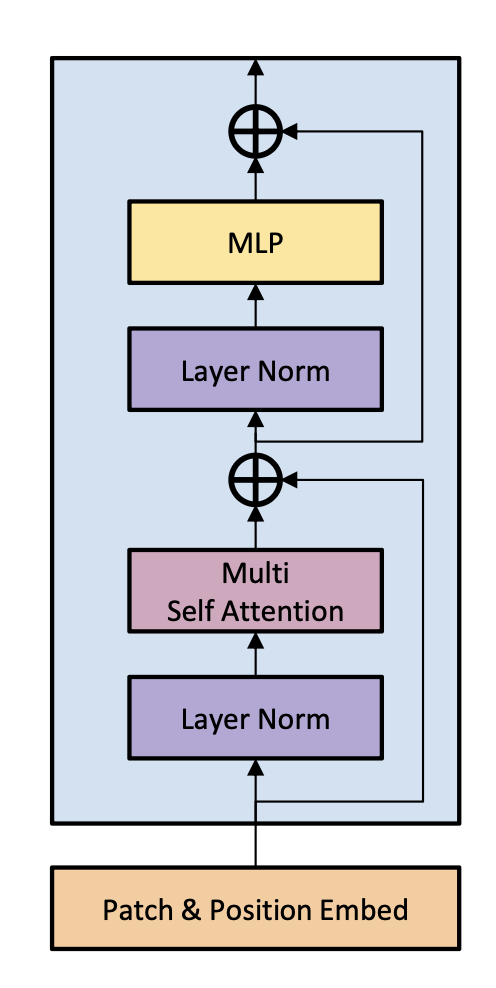
-
이미지를 패치 단위로 나눈다
-
패치를 Dense vector로 변환
-
포지셔널 인코딩, CLS token 추가
-
트랜스포머의 입력으로 전달
-
어떠한 처리 과정을 거쳐서
-
클래스 분류 결과는 출력으로 나온 [CLS] token에 저장
ViT의 특징
-
Lower layer : Global + Local features capturing
-
Higher layer : Global features capturing
-
작은 데이터셋으로는 학습하기가 어려움
-
거대한 데이터셋을 처리하기 위한 거대한 연산 시스템이 필요
CNN vs ViT
CNN
CNN은 2D 구조를 전제로 설계되어 이미지를 처리할 때 근처 픽셀들 간 차이가 크지 않다고 가정한다.
따라서 필터를 활용하여 지역 특징(Local features)를 찾는 데 특화되어 있다.
ViT
ViT는 이미지를 패치로 나눈 후, 각 패치들을 시퀀스로 다룬다.
따라서 패치 간 거리에 상관없이 Attention 메커니즘으로 모든 패치들 간 연관성을 고려할 수 있다.
