concurrency control 1 : schedule과 serializability
0. reference
https://youtu.be/DwRN24nWbEc
https://tcachu.tistory.com/13
1. schedule
여러 transaction들이 동시에 실행될 때, transaction를 횡단하는 operation(읽기 혹은 쓰기 작업)들의 실행 순서를 말한다. 당연하지만 동일한 트랜잭션 내에서 작업의 순서는 변하지 않는다.
같은 트랜잭션 집합에도 그것을 처리하는 스케줄은 다양한 것이 있다. 또한 그 스케줄에 따라 결과가 달라질 수 있다.(단일 트랜잭션의 순서는 바꾸지 않는다)
무슨 말이냐면, 은행의 계좌 이체를 하는 상황을 가정해보자. 동운이(D)는 재이(J)에게 500원을 이체해야 하고, 재이는 동운이에게 1000원을 이체해야 한다고 해보자. 그것을 처리하는 트랜잭션은 다음과 같이 정의한다.
read는 r로, write는 w, commit은 c 그 뒤의 번호는 오퍼레이션의 트랜잭션을 구분하기 위한 숫자로 하겠다. 또한, 동운의 초기 잔고는 10000원이고 재이의 초기 잔고는 20000원이다.
// 동운이 재이에게 500원을 이체하는 트랜잭션
t1 : (r1(D)=>x, w1(D=x-500), r1(J)=>y, w1(J=y+500))
// 재이가 동운에게 1000원을 이체하는 트랜잭션
t2 : (r2(J)=>z, w2(J=z-1000), r2(D)=>k, r2(D=k+1000))임의로 스케줄 두 개를 생각해보자. 첫 번째는 t1이 완전히 끝난 후에 t2가 실행되는 스케줄이다.
<schedule.1>
r1(D)=>10000
w1(D=9500)
r1(J)=>20000
w1(J=20500)
c1
r2(J)=>20500
w2(J=19500)
r2(D=9500)
w2(D=10500)
c2
<schedule.2>
r1(D)=>10000
w1(D=9500)
r1(J)=>20000
r2(J)=>20000
w2(J=19000)
w1(J=20500)
c1
r2(D)=>9500
w2(D=10500)
c2schedule.1에서 최종 결과 (D, J) = (10500, 19500)이다. 반면, schedule.2에서 최종 결과 (D, J) = (10500, 20500)이다. 결과가 다른 이유는 다른 스케줄이기 때문이다.
잘못된 것은 schedule.2이다. w2(J=19000), w1(J=20500)를 보면 t1이 t2의 업데이트를 덮어쓰는 것을 확인할 수 있다. 아무리 J에서 19000원이 되더라도 t1는 20000원을 기준으로 500원을 올려 25000원을 쓰게 된다. 이처럼 업데이트를 덮어쓰는 문제를 lost update 현상이라 한다.
이처럼 스케줄은 다양한 결과가 있을 수 있다.
schedule.1처럼 트랜잭션이 겹치지 않고 실행되는 것을 serial schedule이라고 한다. 반면 schedule.2처럼 트랜잭션이 겹쳐서 실행되는 것을 nonserial schedule이라고 한다.
serial schedule의 장단점
P : 트랜잭션이 겹치지 않아 동시성에 의한 문제가 없다.
N : 시간당 트랜잭션 처리량이 낮다.
nonserial schedule의 장단점
P : 동시성에 의한 문제가 발생한다.(lost update, dirty read...)
N : 시간당 트랜잭션 처리량이 상대적으로 높다.
트랜잭션 처리량이 무슨 말이냐면, 먼저 read와 write작업에 대해서 알아야 한다.
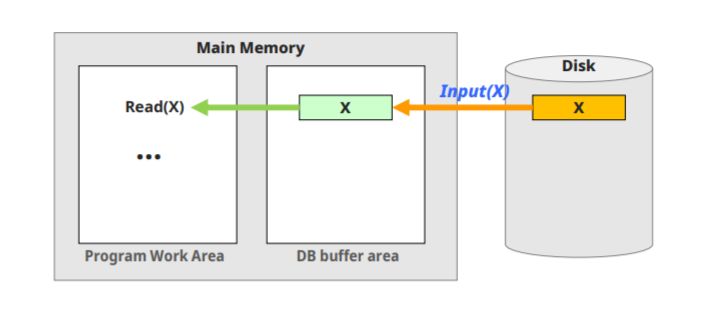
read(x)작업은 다음과 같은 과정으로 이루어진다.
- x가 위치한 disk block의 주소를 찾는다. (cpu?)
- disk block을 메모리(버퍼)에 복사한다. (disk I/O)
- 버퍼에서 x데이터를 프로그램 상으로 가져온다. (cpu)
즉, read는 cpu -> diskIO -> cpu이다.
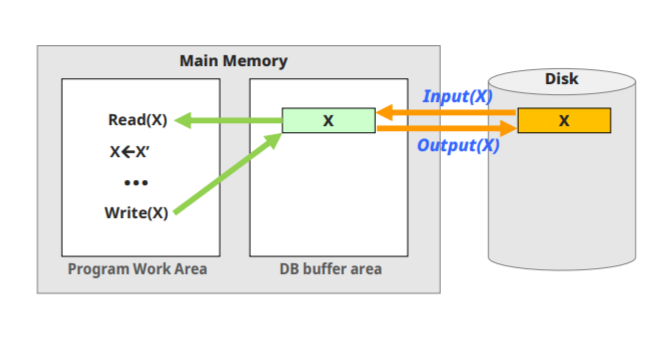
write(x)작업은 다음과 같은 과정으로 진행된다.
- x가 위치한 disk block의 주소를 찾는다. (cpu?)
- x의 주소를 디스크에서 찾는다. (disk I/O)
- 없다면 버퍼에 넣는다. (disk I/O)
- 버퍼에서 x를 가져와서 그 값을 수정한다. (cpu)
- 그 x를 다시 버퍼로 내보낸다. (cpu)
- x를 버퍼에서 disk로 옮긴다(disk I/O)
마찬가지로 cpu-> diskIO -> cpu -> diskIO 인 셈이다.
이를 통해서 트랜잭션이 read 혹은 write를 할 때, disk와 cpu가 나누어져 있으므로 해당 작업이 disk IO에 진입했을 때, cpu가 놀고 있다는 사실과, 그 시점에서 다른 작업을 시작하는 경우 보다 효율적인 처리가 가능함을 추론할 수 있다. 무슨 말이냐면
read -> read가 있을 때
cpu -> diskIO -> cpu -> cpu -> diskIO -> cpu이게 아니라
cpu -> diskIO -> cpu
cpu -> diskIO -> cpu
이런 식으로 맞물려서 딴 것이 놀고 있을때 효율적으로 실행할 수 있다는 얘기다. read -> read 뿐만 아니라 다른 조합도 마찬가지이다.
근데 이러한 효율화는 같은 트랜잭션 내에서는 이루어질 수 없다. 같은 트랜잭션에서 이전 작업이 끝나기 전에 현재 작업이 시작하면 논리적으로 말도 안되고, 현재 작업이 이전보다 먼저 끝나서 여러 문제가 발생할 수 있다. (트랜잭션 내 작업의 순서가 바뀌거나) 반면 다른 트랜잭션 끼리는 서로 번갈아 실행이 가능하다. 별개의 트랜잭션이므로 다른 트랜잭션의 작업과의 순서관계가 바뀌어도 논리적으로는 타당하기 때문이다.
가령 r1(x) 후 w1(x + 500)인데, x를 다 읽어 가져오지도 못한 채 500을 더해 쓸 수는 없다는 것을 생각해볼 수 있다. 물론 이전 작업이 끝나야 현재 작업이 실행될 수 있다는 것이 너무 당연하지만 말이다.
요지는 다른 트랜잭션끼리의 작업은 맞물릴 수 있으나, 같은 트랜잭션 내 작업은 맞물릴 수 없어서 serial하게 수행되고, 성능이 상대적으로 낮다고 할 수 있겠다. (아직 잘 몰라서 틀린 정보가 있을 수 있다. 다만 결론은 동일하다.)
2. conflict
serial schedule은 안전하나 느리고, nonserial schedule은 불안전하나 빠르다. 이들 중 장점인 속도와 안정성을 모두 가질 수 있는 방법이 고안되었다. 다시 말하면, nonserial schedule에서도 이상한 결과가 없는 schedule의 규칙을 알아내었다. 이러한 규칙이 무엇인고 하니, serial schedule과 conflict equivalant(후에 정의)한 nonserial serial schedule은 이상한 결과가 없다는 것이었다.
중요한 것은 "conflict와 conflict equivalant가 무엇인가" 이다.
conflict
conflict란 어떤 두 operation이 다음 세 가지를 만족할 경우, 그것을 conflict operations이라 한다.
- 서로 다른 transaction 소속
- 같은 데이터에 접근
- 최소 하나는 write operation(w-w 혹은 w-r)
이러한 conflict가 중요한 이유는 conflict operation이 순서가 바뀌면 결과도 바뀌기 때문이다.
schedule.2에 적용해보면
<schedule.2>
r1(D)=>10000
w1(D=9500)
r1(J)=>20000
r2(J)=>20000
w2(J=19000)
w1(J=20500)
c1
r2(D)=>9500
w2(D=10500)
c2CONFLICT_SET = {(w1(D=9500), r2(D)=>9500),
(w1(D=9500), w2(D=10500)),
(r2(J)=>20000, w1(J=20500)),
(w2(J=19000), w1(J=20500))
}
이 순서가 보존되는 conflict operations를 통해서, 왜 lost update라는 문제가 생겼는지 설명할 수 있다.
t1, t2의 serial schedule을 생각해보자. serial schedule인 schedule.1에서
<schedule.1>
r1(D)=>10000
w1(D=9500)
r1(J)=>20000
w1(J=20500)
c1
r2(J)=>20500
w2(J=19500)
r2(D=9500)
w2(D=10500)
c2CONFLICT_SET을 생각해보면 사실 위와 같다. 다만 그 순서가 달라질 것이다.
schedule.2.CONFLICT_SET = {(w1(D=9500), r2(D)=>9500),
(w1(D=9500), w2(D=10500)),
(r2(J)=>20000, w1(J=20500)),
(w2(J=19000), w1(J=20500))
}
schedule.1.CONFLICT_SET = {(w1(D=9500), r2(D)=>9500),
(w1(D=9500), w2(D=10500)),
(w1(J=20500), r2(J)=>20000),
(w1(J=20500), w2(J=19000))
}
schedule.1에서 schedule.2로 conflict operation의 순서가 바뀌었고, lost update로 인한 결과의 변화가 발생한 것을 위에 확인할 수 있다. 해결책은 w2와 r2를 w1 이후에 실행되도록 t2를 늦추면 된다. 이 경우에는 serial schedule과 동일하게 되어 성능 향상 폭이 적겠지만,
"적어도 하나의 serial schedule과 동일한(conflict equivalent를 포함) schedule"
보다는
"적어도 하나의 serial schedule과 conflict equivalent한 schedule"
이 더욱 넓은 범위인 것은 당연하고, 특히 serial하지 않다(병행 처리가 가능하다. 혹은 interleaving이 가능하다.)고 하더라도 안정성이 보장될 수 있다는 것이 중요하다. 그리고 위 정의가 conflict serializable schedule이라고 한다.
한편, schedule.2가 schedule.1과는 conflict equivalent하지 않은데, 아직 t2->t1로 반전된 schedule.1과는 conflict equivalent할 수도 있지 않을까? 생각할 수 있다. 근데 딱 보면 w2가 먼저 되니까 conflict equivalent하지 않다는 것을 알 수 있다. 즉, schedule.2는 conflict serializable하지 않은 nonserial schedule인 것이다.
구현 방법
conflict serializable을 적용한다고 해보자. 가장 간단한 생각은 트랜잭션이 겹쳐서 실행이 될 때마다 그 schedule이 위 조건에 맞는지 검사하는 것이다. 근데, 이러면 매번 트랜잭션의 conflict를 구하고(아마 N^2?) 순서를 비교(아마 N)인 작업을 추가로 해야 한다.
그래서 현실에서는 프로토콜(2PL)을 활용해서 여러 병행 트랜잭션의 schedule이 conflict serializable 할 수밖에 없게 만든다.
3. 정리
문제 상황 : 성능 향상을 위해 transaction을 겹쳐 실행하고 싶다(nonserial schedule) 하지만, 그것에 의한 이상한 현상은 피하고 싶다.
해결책 : conflict serializable한 nonserial schedule을 허용하자.
schedule equivalent serial schedule serializability
schedule conflict equivalent serial schedule conflict serial...
schedule view equivalent serial schedule view serializability

그니까 저게 갱동운(D)이랑 밍재이(J)죠?