Multi-task learning
if one task doesn't have enough labels, can we borrow signals from related tasks?
Multi-task Learning이 필요한 이유
현실문제
- 실제 산업 데이터는 라벨이 극도로 부족
- 개별 모델을 각각 학습하면 학습 신호가 너무 희박함
-> 여러 예측 task가 서로 관련되어 있음
- ex) 클릭할 확률이 높은 아이템 -> 만족할 확률도 높을 가능성 큼
- 즉, 하나의 task를 학습하면 다른 task의 힌트가 됨
결론 : 관련된 여러 task를 하나의 모델에서 함께 학습하면 라벨 부족 문제를 완화할 수 있다.
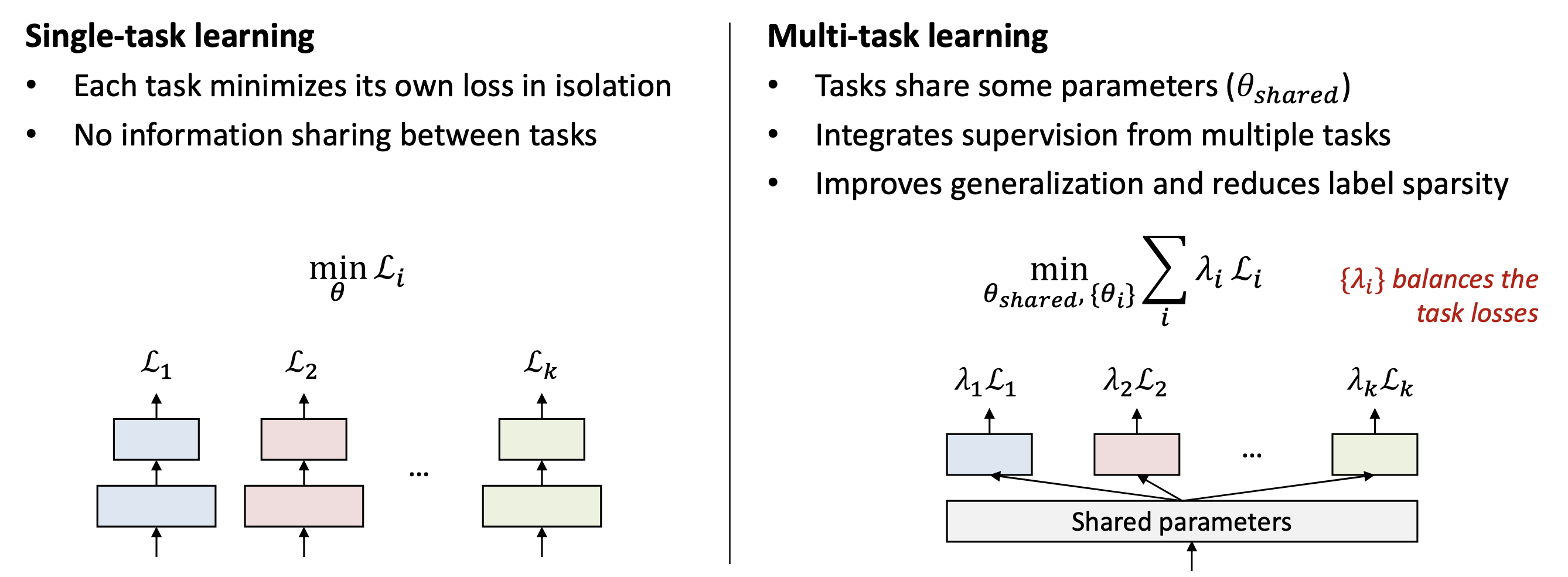
1. Multi-Task Learning(MTL)의 기본 개념
정의
- 여러 관련된 task를 하나의 모델에서 동시에 학습 하는 방식
- 모델의 일부 파라미터를 공유(shared)하여 학습하고 각 task별로 개별 head를 만들어두어 최종 예측
구성 요소
- shared parameters
여러 task가 공동으로 사용하는 feature extractor - Task-specific parameters(Heads)
각 task 문제에 특화된 classifier - Loss balancing λᵢ
여러 task loss를 어떻게 조절해 균형 있게 학습할지 결정
장점
- Task간 지식 공유 -> 라벨 부족 문제 완화
- Generalization 향상 (편향된 task에 overfit 방지)
2. MTL의 문제점 : Negative Transfer
Negative Transfer란?
- 여러 task를 함께 학습했더니 오히려 성능이 나빠지는 현상
- 이유:
여러 task가 완전히 동일한 정보를 필요로 하지는 않음
task 간 discrepancy(차이)가 커질수록 공유된 파라미터가 혼란을 야기함 ex) 클릭은 즉각적행동이고 만족도는 사후적 감정평가로 이 두 task는 관련성은 있지만 필요한 feature가 다르다.
결론 :
"모든 task가 같은 비율로 공유해야한다"는 고정된 방식은 비효율적이다.
해결책 : MMoE (Multi-gate Mixture-of-Experts)
MMoE는 task discrepancy 를 해결하고 동적으로 sharing 정도를 조절하는 방법.
핵심 아이디어
- Shared bottom을 단일 네트워크로 두는 대신 여러개의 전문가(Expert) 네트워크를 둔다. 각각의 expert는 input값의 다양한 측면을 학습
- 각 task는 자기 전용 게이트(gate)를 통해
- 어떤 expert를 얼마나 사용할지 스스로 선택
- softmax로 weight를 결정
- gate로 부터 나온 output인 w들의 합은 1
3 task간 유사도가 높으면 gate의 weight 분포가 비슷해짐
4 유사도가 낮으면 각 task는 다른 expert에 높은 weight 부여
즉 MMoE는 "공유는 하되, 공유의 강도는 task가 스스로 결정하도록 한다"
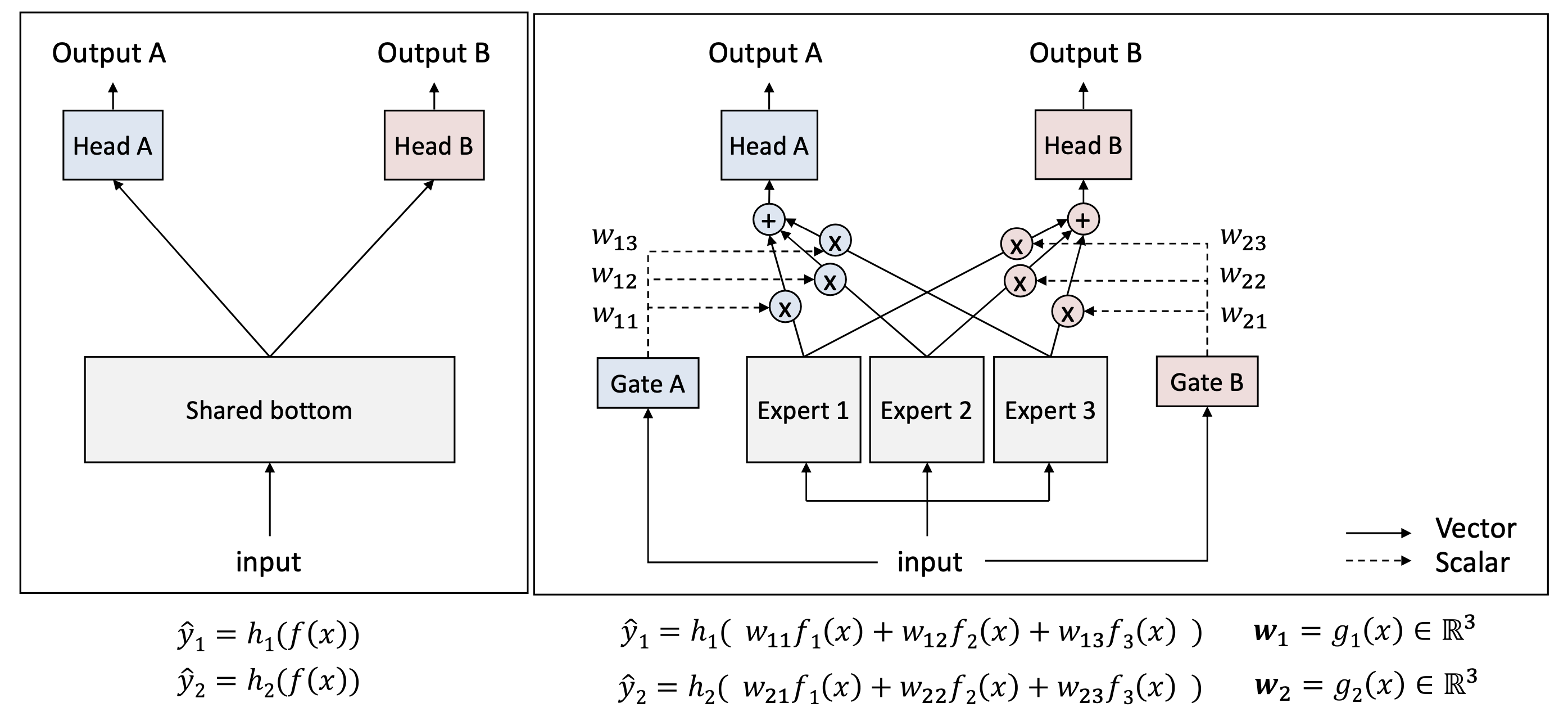
MMoE 모델 구조 정리
1) Experts(E₁, E₂, …, Eₖ)
- 여러개의 작은 신경망(subnetwork)
- 입력의 다양한 측면을 학습
- "전문가" 역할
2) Task-specific Gates
- 각 task마다 gate network 존재
- 입력을 받아 softmax(weight over experts) 생성
- 어떤 expert를 얼마나 사용할지 결정
3) Weighted combination
- 각 task의 representation = sum(gate weight x expert output)
4) Task-specific heads
- 최종 classification
- CE(Cross-Entropy) loss 등 standard loss 사용
MMoE의 장점
1) Dynamic sharing
- Gates가 자동으로 유사한 task는 공유 많이, 다른 task는 공유 적게
- Task discrepancy 문제 해결
2) 자동 전문가 분화(Specialization)
- 학습 중 gate는 자신에게 이득을 주는 expert에 더 높은 weight
- Expert들은 특정 task에 점점 특화됨
- self-organizing behavior 발생

2KT