해시테이블
Key를 활용해 값을 저장하고 빠르게 직접적으로 접근할 수 있는 테이블 형 자료구조. 직접적으로 접근하기 때문에 탐색 진행 시 시간복잡도 로 빠른 속도로 가능하다.
해시테이블의 원리
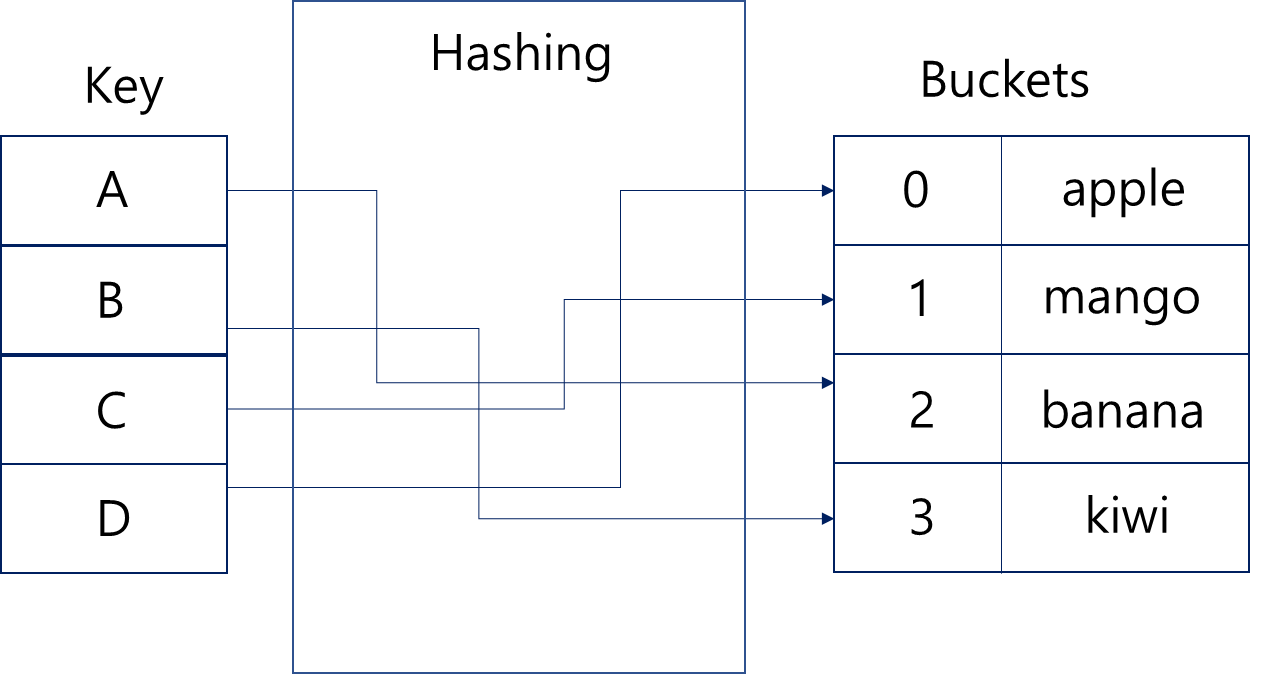
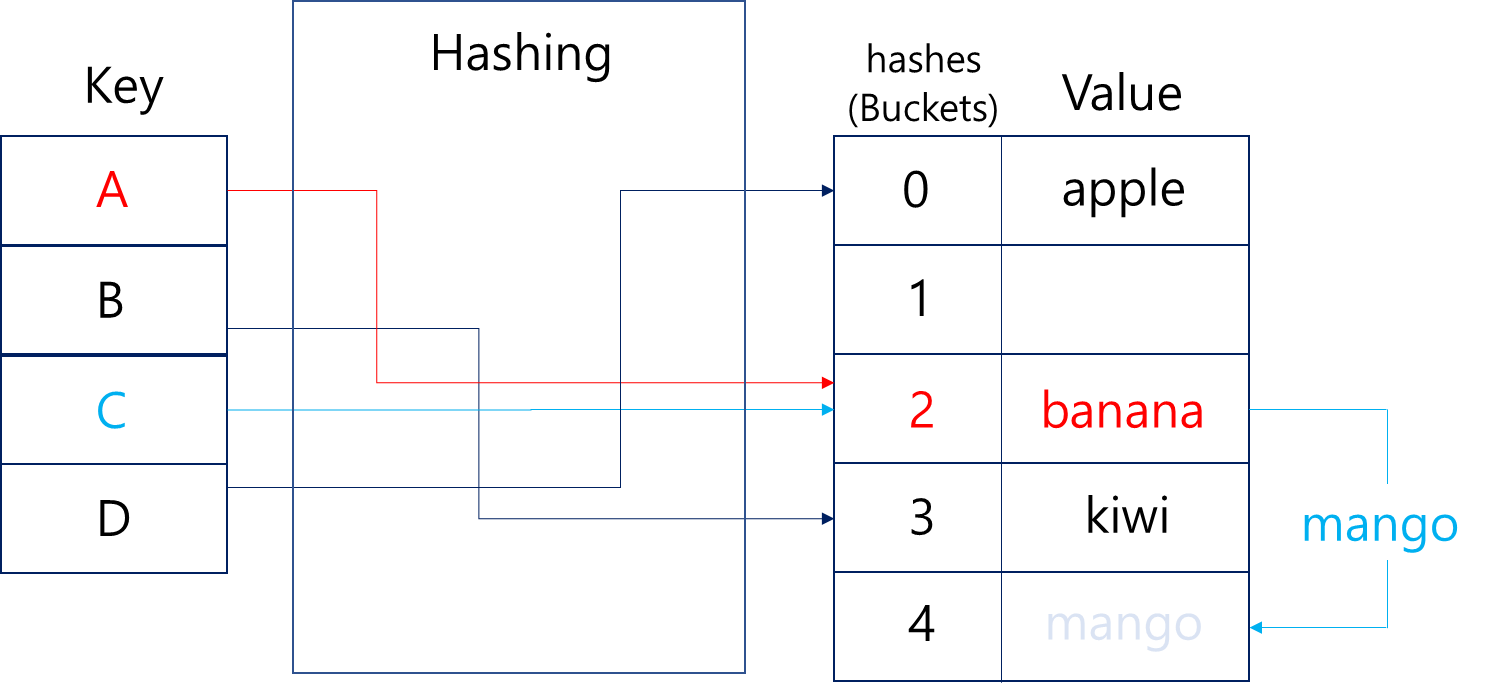
Key 값에 해당하는 Value를 자체적으로 가진 해시함수를 통해 index를 구분해서 저장하기 때문에 해당 Key를 입력하면 그에 해당하는 위치에서 바로 꺼내오는 원리이다.
위 이미지와 같이 A라는 Key를 넣으면 내부 해시함수에서 연산을 진행해 Key값에 맞는 hash값 2를 반환받고, 이 2번 바구니에 들어있는 Banana라는 Value를 찾아 반환할 수 있다.
위에 언급되었지만, 이렇게 Key값을 통해 바로 제 위치를 파악하여 반환하기 때문에 시간복잡도가 이 된다.
해시테이블 관련 용어
해시 함수(Hash Function):
여러 Key를 Hash값(integer)로 변환하여 매칭(또는 mapping)하는 역할
Key값들에 대해 Unique한 Hash값을 내놓을 수 있도록 설정하는 것이 중요
해싱(Hashing):
Key와 매칭되는 값을 검색하는 과정. 자료구조 내에서의 검색을 목적으로 한다.
해시(Hash):
해시함수를 통해 나온 값을 의미하며, 저장소로써 버킷(Bucket)에 담겨진다.
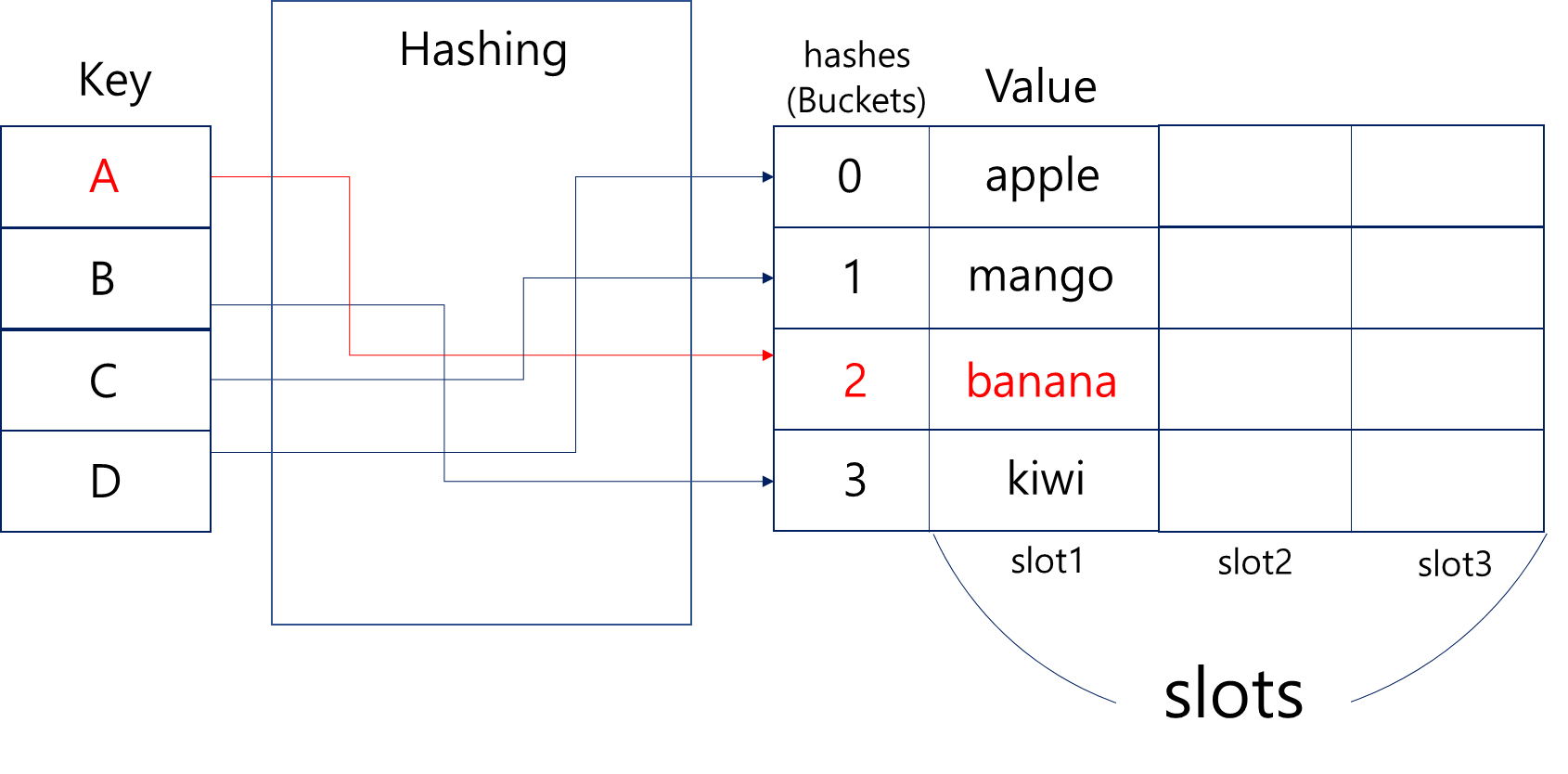
슬롯(Slot):
해시 충돌 발생시를 대비해 이미 다른 Key에 대한 Value 값이 들어있는 Bucket에 같은 Hash값을 가진 다른 Key의 Value값이 들어가게 되는 장소. 연결리스트를 통해 다음 값을 연결해준다.
로드 팩터(Load Factor):
해시테이블에 원소가 차있는 비율. 해시테이블의 충돌을 줄여 성능을 높이기 위해 중요한 요소이다. 전체 테이블 내 버킷 공간 수를 원소의 개수에서 나눈 값이다.
로드 팩터 비율에 따라 해시함수, 테이블 크기 조정 여부를 결정한다.
제대로 된 동작을 위해선 이 적재율이 1이 넘지 않도록 유지한다
해시 함수(Hash Function)
- 해시 함수는 위 설명과 같이 Key를 Hash값으로 매핑해줄 어떠한 로직을 설정한다.
- 입력값의 데이터 타입은 다양하며 해시 함수를 통해 나온 값은 숫자로 보통 정수형을 가진다.
- 각 해시값은 Key 별로 Unique할수록 좋다.
- Key가 다름에도 해시함수를 거쳐 Unique하지 않고 이미 존재하는 값이 나와 충돌(Collision)이 발생할 수 있다.
좋은 해시 함수를 작성하기 위해선 해시 충돌에 잘 대처될 수 있는 함수를 짜야한다. 그러한 방법들을 적용해본다.
나눗셈을 통한 해시
가장 기본적인 해시 방법. 입력값을 나눈 나머지를 해시값으로 하는 해시방법이다.
def hash_divide(nums):
print(f'{nums}의 해시값')
a= list()
for i in nums:
a.append(i%7)
return a
hash_divide([135,2654,2435,956,9996])[output]
[135, 2654, 2435, 956, 9996]의 해시값
[2, 1, 6, 4, 0]입력값에 7을 나눈 숫자를 이용해 임의의 숫자가 담긴 리스트의 원소들 각각의 해시값을 구해보았다. 물론 이것은 해시값만 구한 것으로 이러한 해시함수를 통해 해시값의 버킷에 Value를 저장하고 탐색하는 것이 해시함수의 주 목적이다.
encode()를 이용한 해시
1) .encode()를 이용해 문자열(string)을 byte 객체화 한다.
2) byte화된 객체는 for문을 통해 비로소 수치화 가능하며 이를 모두 합친 것을 해시 값으로 지정
to_byte = "hello".encode() # 문자열을 encoding하여 바이트 화 한다.
print('to_byte의 byte화 객체:',to_byte)
sum = 0 # sum 초기화
for byte in to_byte: # 문자열 바이트 하나하나(정수)를 꺼낸다
sum += byte # sum에 더해주길 반복
print('byte화된 객체의 부분:', byte)
print('최종 byte들의 합:',sum)[output]
to_byte의 byte화 객체: b'hello'
byte화된 객체의 부분: 104
byte화된 객체의 부분: 101
byte화된 객체의 부분: 108
byte화된 객체의 부분: 108
byte화된 객체의 부분: 111
최종 byte들의 합: 532문자열에 .encode()를 통해 byte화 하면 print() 했을때 b'string'의 형태로 객체가 반환된다. 이를 반복문을 통해 모두 더한 값을 이용해 해시값으로 사용할 수 있다.
hashlib을 이용한 해시
단순히 encode()를 통한 변환 외에 해시함스를 위한 라이브러리도 존재한다.
- import hashlib을 위해 간편히 사용할 수 있다.
- 실제 sha256에 사용되는 라이브러리
- sha256은 블록체인의 블록 암호화 기법으로도 알려져있다.
import hashlib
# 함수작성
def hash_func(string):
enc = string.encode() # 문자열의 바이트 화
hexed = hashlib.sha256(enc).hexdigest() # 라이브러리를 이용한 해시함수 적용
return hexed
string = 'string'
hash_func(string)[output]
473287f8298dba7163a897908958f7c0eae733e25d2e027992ea2edc9bed2fa8함수 사용 결과, 'string'이란 문자열에 대한 해시값이 매우 복잡하게 변경되어 나온것을 볼 수 있다.
해시 충돌(Hash Collision):
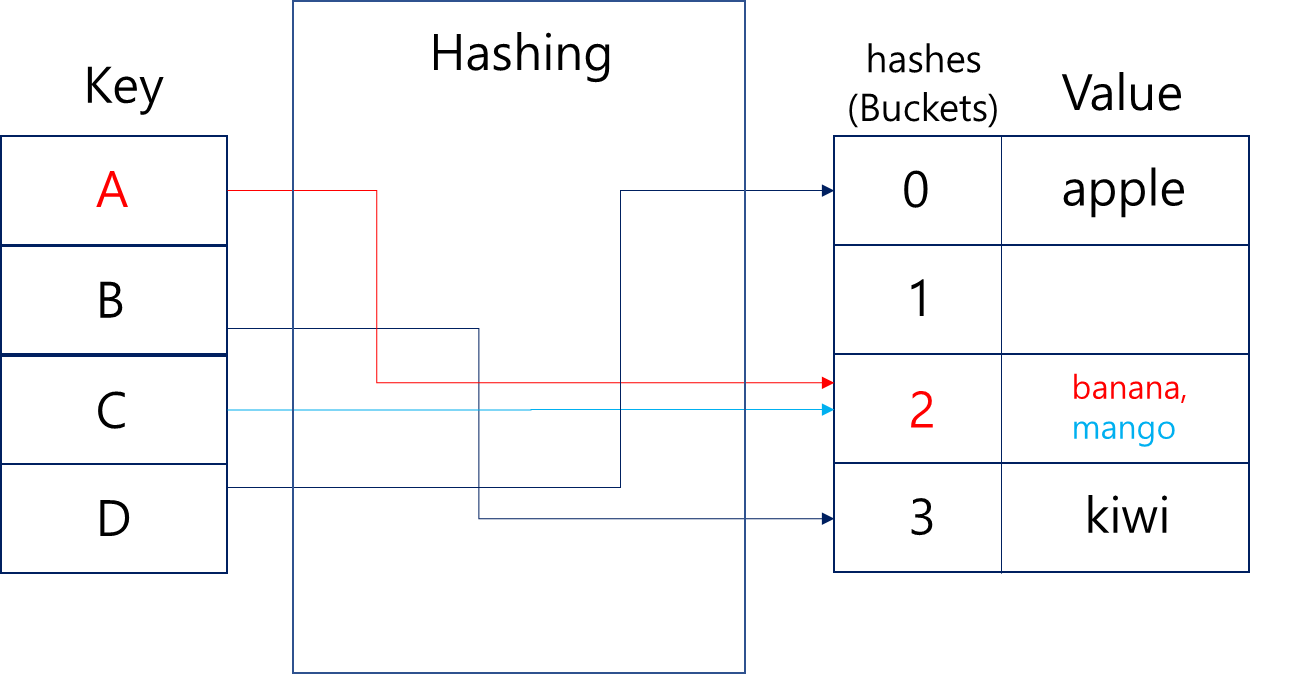
Hash Function을 통해 한 개 이상의 Key값이 동시에 같은 Hash값을 얻는 경우를 일컫는다.
위 이미지에선 Key A가 Mapping되어있는 2번 버킷에 Banana가 들어있는 상황에 해시함수를 통과한 Key C의 해시값이 동일하게 2가 나와 2번 버킷에 mango가 담기게 해시 충돌 상황이다.
해시 함수를 작성할 때 충돌을 아예 피할 수는 없다. 하여 이를 최소화 하여 작성해야 한다.
다양한 충돌 방지법이 있는데 대표적으로 체이닝(Chaining)과 오픈 어드레싱(Open addressing) 방법이 있다.
체이닝(Chaining)
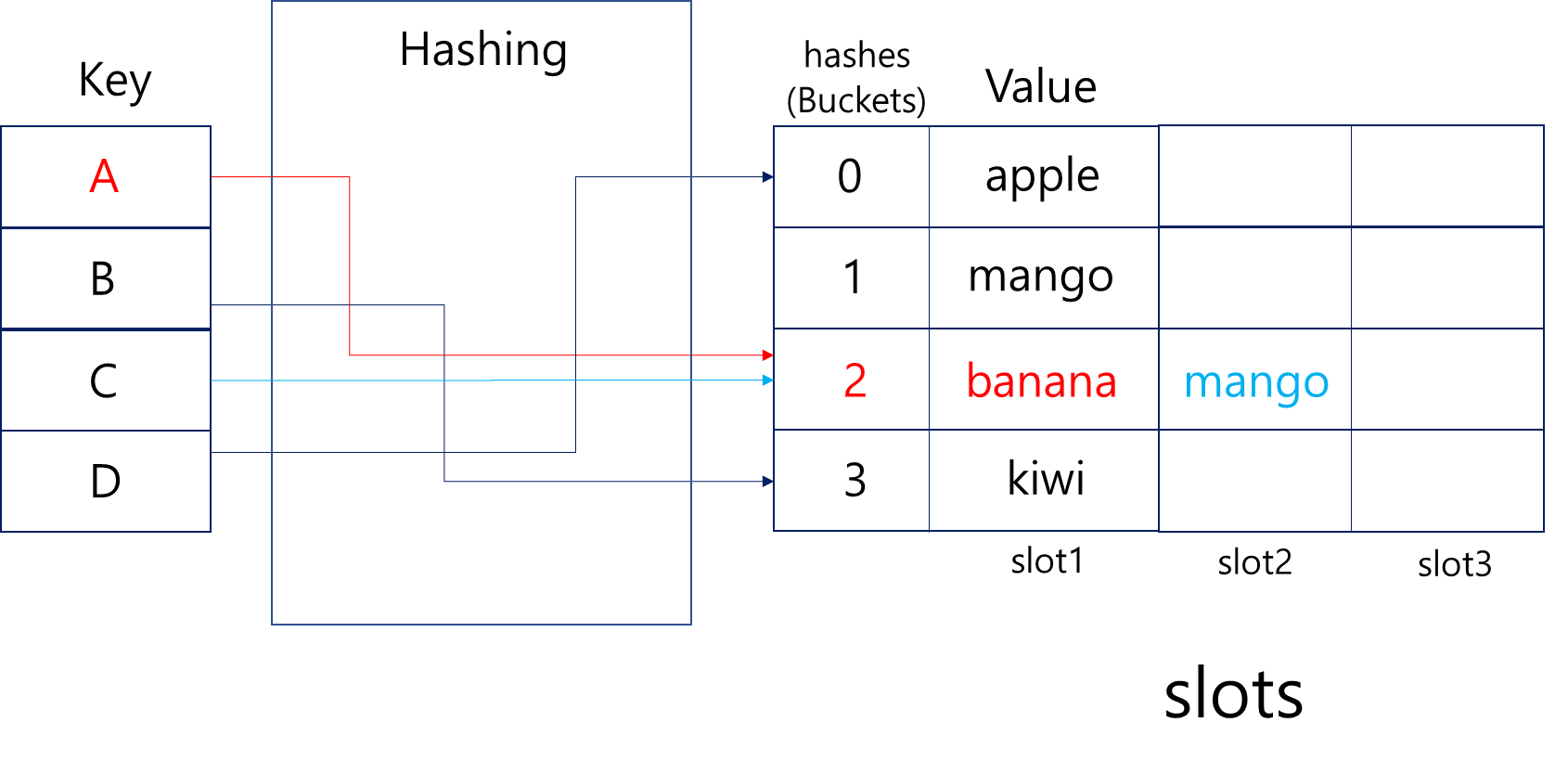
맨 위 개념에서 설명한 슬롯(Slot)을 이용하는 방법으로, 이미 버킷에 값이 들어있을 때 같은 Hash값을 같는 값을 같은 버킷의 다음 슬롯에 연이어서 넣어주는 방법이다.
데이터가 중복되더라도 새로운 버킷을 활용하지 않으므로 로트 팩터가 상대적으로 덜 증가할 수 있으나, 전체 해시 테이블이 찰 수록 선형적으로 성능은 떨어지게 된다.
체이닝을 이용한 해시 함수 구현
# 10개 인덱스의 해시 테이블에 체이닝을 이용한 해시함수 적용해보기
hash_table = [[] for _ in range(10)]# 빈 테이블 작성
# 해시함수
def hash(key):
return key % 5
# 체인해싱함수
def chain_hashing(hash_table, key, value):
h_key = hash(key) # 키값의 해시값을 받는다
hash_table[h_key].append(value) # 테이블에 해당 해시값 위치에 value를 넣는다.
return hash_table
chain_hashing(hash_table, 30, 'david') # 0번 인덱스
chain_hashing(hash_table, 29, 'chloe') # 4번 인덱스
chain_hashing(hash_table, 32, 'jake') # 2번 인덱스
chain_hashing(hash_table, 40, 'helen') # 0번 인덱스 -> 충돌이 아닌 체이닝[output]
[['david', 'helen'], [], ['jake'], [], ['chloe'], [], [], [], [], []]체이닝을 이용한 해시함수를 리스트 형식으로 구현했다. 이는 파이썬의 리스트 메소드 append를 이용한 방식인데, 이를 연결리스트로 구현한다면 더 빠르게 탐색이 된다고 한다.
오픈 어드레싱(Open addressing)
체이닝 방법과 달리 충돌 발생시, 같은 버킷에 넣지 않고 다음의 다른 버킷을 찾는 탐사(probing)을 통해 넣도록 하는 방법이다.
내부적으로 선형탐색, 이차 탐색으로 다음 버킷을 찾는 방법이 있고, 함수를 한번 더 적용해 충돌시 함수로 인한 새로운 해시값으로 충돌을 비하는 방법이 있다.
* 오픈 어드레싱의 경우 로드팩터가 0.75~0.8 도달시 버킷 공간을 늘려주는 일종의 장치를 해두는 편이 로드팩터 유지를 위해 좋을 수 있다.
오픈 어드레싱을 이용한 해시 함수 구현
# 10개 인덱스의 해시 테이블에 오픈 어드레싱을 이용한 해시함수 적용해보기
hash_table = [[] for _ in range(10)]# 빈 테이블 작성
# 해시함수
def hash(key):
return key % 5
# 오픈 어드레싱 해싱 함수
def oe_hashing(hash_table, key, value):
h_key = hash(key) # 키값의 해시값을 받는다
if len(hash_table)-hash_table.count([]) >= int(len(hash_table)*0.75): # 추가해주면 좋은 부분,
# 테이블 내 차있는 공간이 75% 이상이면
hash_table.extend([[] for _ in range(int(len(hash_table)*0.5))]) # 새로운 테이블 공간을 생성해준다.
while True:
if len(hash_table[h_key]) == 1: # 해당 해시값 버킷 내에 값이 있다면:
h_key+=1 # 해시값 인덱스를 올린 뒤
if h_key == len(hash_table): # 인덱스를 끝까지 밀었는데 없는 경우:
h_key = 0 # 인덱스를 0으로 돌려서 앞쪽을 찾는다.
else:
hash_table[h_key].append(value) # 비어있으면 바로 넣어준다.
return hash_table
oe_hashing(hash_table, 30, 'david') # 0번 인덱스
oe_hashing(hash_table, 29, 'chloe') # 4번 인덱스
oe_hashing(hash_table, 32, 'jake') # 2번 인덱스
oe_hashing(hash_table, 40, 'helen') # 0 > 1번 인덱스
[['david'], ['helen'], ['jake'], [], ['chloe'], [], [], [], [], []]위는 아까와 같은 입력값들을 갖고 있지만, 'david'와 'helen'이 해시값이 0으로 같아도 'helen'이 빈 인덱스를 찾아 들어간 것을 볼 수 있다.
또한 언급되었던 것처럼 오픈 어드레싱의 경우 로트 팩터를 유지하기 위해 75~80%정도의 공간이 차면 추가적으로 메모리를 준비해 두는것이 좋다. 아래는 메모리가 어느정도 찼을 때의 결과를 보도록 한다.
oe_hashing(hash_table, 31, 'jimin') # 1 > 2> 3번 인덱스
oe_hashing(hash_table, 13, 'amy') # 3 > 4 > 5번 인덱스
oe_hashing(hash_table, 25, 'bob') # 0 > 1 > 2 > 3 > 4 > 5 > 6번 인덱스
oe_hashing(hash_table, 24, 'mason') # 4 > 5 > 6 > 7번 인덱스
print(len(hash_table))[output]
[['david'],
['helen'],
['jake'],
['jimin'],
['chloe'],
['amy'],
['bob'],
['mason'],
[],
[],
[],
[],
[],
[],
[]]print(hash_table, end = '')
print('\n길이:',len(hash_table))[output]
[['david'], ['helen'], ['jake'], ['jimin'], ['chloe'], ['amy'], ['bob'], ['mason'], [], [], [], [], [], [], []]
길이: 15오픈 어드레싱 조건에 따라 80% 이상이 찬 뒤 추가적으로 0.5배의 수만큼 빈 공간을 추가해주는 작업이 진행됐다.
해싱함수(Hash Functiong)와 기본적인 충돌(Collision) 최소화 방법으로 체이닝(Chaining)과 오픈 어드레싱(Open addressing)을 알아보았다.
