Deep Learning - 전이학습(Transfer Learning)의 미세조정(Fine Tuning) 방법 및 괴현상 원인분석 (feat. BN, ResNet50)
사전학습된 ResNet50 모델을 이용한 전이학습에 대한 실습을 진행하면서 겪었던 여러가지 사례들에 대해 다뤄보고자 한다.
우선 여러가지 실습관련 내용, 그리고 다양한 리뷰들을 보면서 '미세 조정을 위한 정답은 없다, 하지만 오답은 있다' 라는 잠정적 결론을 가질 수 있었다. 여기서 말하는 오답이란 미세조정의 목적이 오히려 역행, 즉 성능을 저하시키는 것을 말한다.
무엇이 문제였고, 그것을 해결하는 것부터 파악해보도록 한다.
Learning Late와 Optimizer의 중요성
학습률은 이전보다 낮게, 옵티마이저는 모델과 데이터에 맞게, 설계는 올바르게
위와 같은 괴현상을 경험한 사람들이 있을 것이다.
글에 대한 의견이 궁금하지 않은 사람들을 위해 오답을 먼저 이야기 하자면,
-
초기화가 어떻게 되었건, Learning late(학습률)이 너무 높아 minima에 들어가기도 전에 딴 곳으로 튀어버렸을 가능성이 매우 높다.
미세조정이라 함은 성능을 내 모델에 맞게 조금더 어울리게 하는것으로 대폭상승을 기대하긴 힘들 수 있다. 현재 가진 데이터의 상황과 파라미터 상으로 이전 학습의 결과에 이어서 소폭으로 gradient descent를 해나가며 minima를 찾는 것이 중요하다. -
1번과 마찬가지지만, 시간이 지나며 많은 optimizer들이 나왔다. 여기에도 정답을 없지만, 작성한 모델과 내가 가진 데이터에 맞는 optimizer 및 그 파라미터를 찾기 위해 부단히 노력을 해보는 것이 중요하다.
모델에 맞지 않는 보폭을 갖거나 방향성을 띄는 optimizer를 사용하게 되면 다른 곳으로 튈 수 밖에 없는 것을 인지하고 다른 방식으로 학습을 유도해야한다. -
미세조정 구간을 설정한 뒤, 학습률 조정을 위해서도 하겠지만, 반드시 컴파일을 해줘야한다. 컴파일을 진행하지 않으면 미세조정 구간을 위해 trainable = True로 지정한 것이 적용되지 않는다.
-
모델 레이어 설계의 문제를 고려해본다. 여러 가지 실험을 하면서 실수도 적잖이 있었는데, 미세조정 후에 마구잡이로 Dense를 쌓아 올리다가 Model 레이어 삽입으로 마무리를 안하니 괴현상이 발생하기도 했다. (Model 레이어 때문이라 확신할 수 있냐며 의심스러울 수 있으나 인과관계를 확인했다)
외에도 원인은 많을 수도 있지만, 초보자의 관점에서 이해가 부족한 상황에 생길 수 있는 오답들에 대한 해답을 찾아 위와 같이 기재해봤다.
아래에선 본격적으로 전이학습에 대한 모델 구현을 해보고 그 트러블 슈팅을 해나가면서 알게 된 과정을 기재해보겠다.
1. 미세조정의 구간 설정
전이학습을 구현해보기 위해 아래같이 tensorflow doc의 전이학습 내용을 참고하고, 기타 다른 전이학습 구현을 참고해 실습을 해보았다. 여러 데이터 증강 및 전처리 조건들이 있었지만 이는 건너뛰고 진행한다.
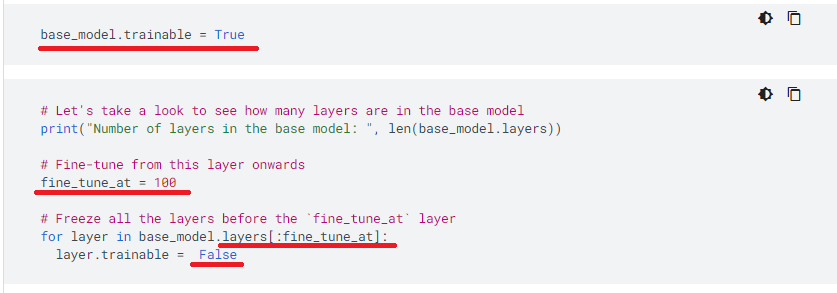
출처: https://www.tensorflow.org/tutorials/images/transfer_learning?hl=ko
Docs에서는 위와 같이 모델을 불러온 뒤, 미세조정을 진행할 구간을 100번 layer로 정해 이전까지는 재 동결 시키는 방식으로 진행하는 것을 확인 했다.
그렇다면 99번째, 100번째 layer가 무엇인지 알고싶었다. 인덱스로 치기 때문에 0부터 시작하는것이 동일하여 enumerate를 이용해 파악해본다.
for i,j in enumerate(base_model.layers):
print(i, j.name)0 input_1
1 Conv1
2 bn_Conv1
3 Conv1_relu
4 expanded_conv_depthwise
...
96 block_10_project
97 block_10_project_BN
98 block_11_expand # Conv
99 block_11_expand_BN # Batch Norm
100 block_11_expand_relu # ReLU
101 block_11_depthwise
102 block_11_depthwise_BN
...
130 block_14_depthwise_relu
131 block_14_project해당 Doc에선 MobileNet을 이용했고 131개 층을 가진 모델이다.
99층까지 학습을 동결했으니 블록 11의 맨 처음 Conv layer와 BN layer를 닫고난 뒤 이후 레이어들의 파라미터만 학습한다고 보면 된다.
'음.. 딱히 규칙을 두지 않고 그냥 100번째에서 잘랐구나' 라는 것을 깨닫고 ResNet50을 구현하면서 대충 mobilnet보다 10개층 높은 110층까지만 동결할 것을 목적으로 진행했다.
미세조정 구간에 대한 결론: 정답이 없다, 상관이 없다. 성능이 개선된다면, 그리 진행해도된다 라고 답할 수 있겠다. 그 이유와 내용에 대해선 BN(Batch Normalization)을 이야기하며 함께 다루겠다.
어찌됐든 전이학습 모델링을 진행해본다.
2. 학습을 위한 모델링 진행
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, MaxPooling2D
from tensorflow.keras import datasets
from tensorflow.keras.applications.resnet50 import ResNet50
# 데이터 불러오기
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# ResNet50 가져오기
base_model = ResNet50(include_top=False, pooling = 'avg' , input_shape = (32,32 ,3), weights = 'imagenet')
# resnet50 가중치 프리징
base_model.trainable = False
inputs = tf.keras.Input(shape=(32,32,3))
x = tf.keras.applications.resnet50.preprocess_input(inputs)
x = base_model(x, training=False)
x = Flatten()(x)
outputs = Dense(10, activation='softmax')(x)
model_res = tf.keras.Model(inputs, outputs)
# 모델 컴파일
sgd = tf.keras.optimizers.SGD(lr=0.01, decay=1e-6, momentum= 0.9, nesterov = True)
model_res.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics = ['accuracy'])
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
# 모델 fitting
save = model_res.fit(train_images, train_labels, epochs = 10, validation_data=(test_images, test_labels), batch_size= 256, callbacks=[early])Epoch 7/10
196/196 [==============================] - 6s 31ms/step - loss: 1.5271 - accuracy: 0.6529 - val_loss: 2.4222 - val_accuracy: 0.5606위와같이 일차적인 결과를 얻었다. 옥의 티라 하면 optimizer를 adam이 아닌 sgd의 customized라고 볼 수 있는데, 이는 실습을 진행하기 위해 다른 Docs를 참고 했던 터라 그랬다.
문제는 아래에서 발생한다.
3. 미세조정 진행, 컴파일 및 학습 재진행
base_model.trainable = True # resnet의 학습 동결을 해제하고.
for layer in base_model.layers[:110]: # 109층 까지 재동결 > 110층부터 175층까지는 동결이 해제된 것
layer.trainable = False
# 모델 컴파일
sgd = tf.keras.optimizers.SGD(lr=0.01, decay=1e-6, momentum= 0.9, nesterov = True)
model_res.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics = ['accuracy'])
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
# save 변수에 넣어둔 model_res의 에폭에 이어서 학습을 진행한다.
save_fine = model_res.fit(train_images, train_labels, epochs = 50, initial_epoch = save.epoch[-1],validation_data=(test_images, test_labels), batch_size= 256, callbacks = [early])Epoch 7/50
196/196 [==============================] - 16s 59ms/step - loss: nan - accuracy: 0.1037 - val_loss: nan - val_accuracy: 0.1000
Epoch 8/50
196/196 [==============================] - 10s 49ms/step - loss: nan - accuracy: 0.1000 - val_loss: nan - val_accuracy: 0.1000
Epoch 9/50
196/196 [==============================] - 10s 52ms/step - loss: nan - accuracy: 0.1000 - val_loss: nan - val_accuracy: 0.1000
Epoch 10/50
196/196 [==============================] - 10s 49ms/step - loss: nan - accuracy: 0.1000 - val_loss: nan - val_accuracy: 0.1000
Epoch 11/50
196/196 [==============================] - 10s 52ms/step - loss: nan - accuracy: 0.1000 - val_loss: nan - val_accuracy: 0.1000미세조정으로 인한 성능 저하??
Learning Rate, Optimizer의 조정
무엇이 문제일까.. 일차적으로 데이터의 문제를 생각했다. resnet50을 preprocess_input 모듈을 이용해 데이터를 자동 변환해서 넣고 있었는데, 이미지 스케일을 스스로도 /255.0을 통해 한번 줄여주었기에 그것을 삭제했음에도 위와 동일한 결과가 발생했다.
문제는 learning rate와 optimizer. 코드 구현을 그대로 따라했으면 모를까, 내 것으로 만든다고 적당히 복붙하고 실행한다면서 중요한 포인트에 신경을 쓰지 못했다.
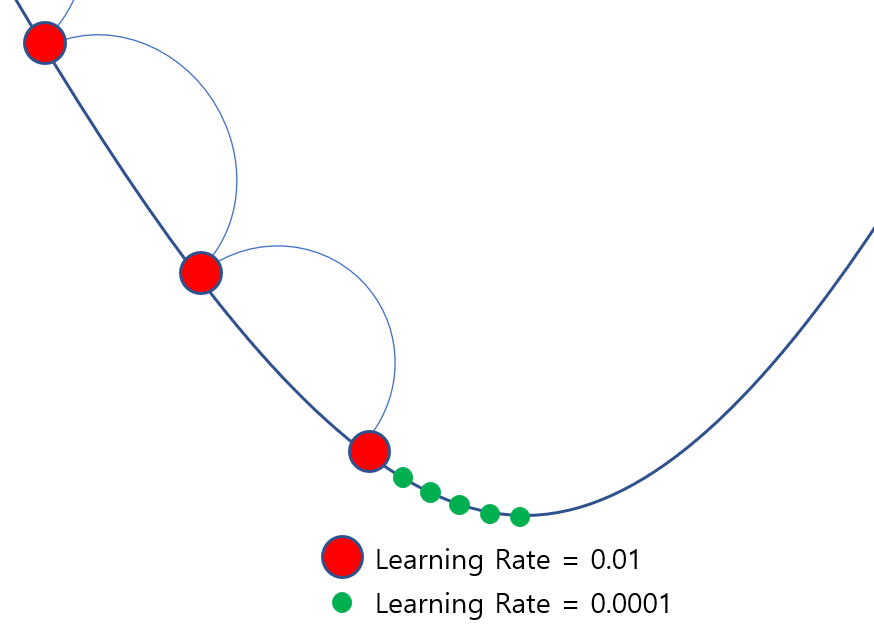
항상 그렇다 할 순 없지만, 미세조정은 2차적인 학습을 진행하는 것이기 때문에 기존에 학습되어있는 것에서 추가적인 학습을 진행한다.
위 그림은 쉽게 표현하기 위해 저렇게 그렸는데, 빨간색 폭 만큼 기존 학습률로 경사하강을 진행했었다면 그 다음에는 초록색과 같이 조금씩 살펴가는 방법을 취해야한다. 그러므로 기존보다 Learning Rate를 낮추어 낮은 폭으로 loss를 줄여나가고, 성능을 개선하는 것이 좋다.
전이학습이 아니라 일반학습에서도 똑같은거 아니냔 의문이 들 수 있고, 그 말이 맞다. 그래서 일반 학습에서도 사용하는 것이 Learning Rate Scheduler, Decay 인것이다.
그만큼 기본적으로 중요한 것이었음에도 미세조정으로 가중치가 더 예민해진 모델을 같은 폭으로 이어서 학습하려니 모델이 민감하게 반응하고 튀어 나갔을 것이다.
# 모델 컴파일
sgd = tf.keras.optimizers.SGD(lr=0.0001, decay=1e-6, momentum= 0.9, nesterov = True)
# model_res.compile(optimizer=tf.keras.optimizers.Adam(learning_rate = 0.01), loss='sparse_categorical_crossentropy', metrics = ['accuracy'])
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)Epoch 10/50
196/196 [==============================] - 14s 53ms/step - loss: 0.9134 - accuracy: 0.7205 - val_loss: 1.2858 - val_accuracy: 0.6519
Epoch 11/50
196/196 [==============================] - 9s 48ms/step - loss: 0.6921 - accuracy: 0.7749 - val_loss: 1.2631 - val_accuracy: 0.6620
Epoch 12/50
196/196 [==============================] - 9s 47ms/step - loss: 0.5772 - accuracy: 0.8111 - val_loss: 1.2470 - val_accuracy: 0.6645
Epoch 13/50
196/196 [==============================] - 9s 47ms/step - loss: 0.4915 - accuracy: 0.8413 - val_loss: 1.2419 - val_accuracy: 0.6697
Epoch 14/50
196/196 [==============================] - 9s 47ms/step - loss: 0.4250 - accuracy: 0.8637 - val_loss: 1.2316 - val_accuracy: 0.6713
Epoch 15/50
196/196 [==============================] - 9s 48ms/step - loss: 0.3699 - accuracy: 0.8841 - val_loss: 1.2306 - val_accuracy: 0.6749
Epoch 16/50
196/196 [==============================] - 9s 47ms/step - loss: 0.3249 - accuracy: 0.9025 - val_loss: 1.2361 - val_accuracy: 0.6752
Epoch 17/50
196/196 [==============================] - 9s 47ms/step - loss: 0.2861 - accuracy: 0.9190 - val_loss: 1.2348 - val_accuracy: 0.6766
Epoch 18/50
196/196 [==============================] - 9s 47ms/step - loss: 0.2545 - accuracy: 0.9308 - val_loss: 1.2425 - val_accuracy: 0.6794
Epoch 19/50
196/196 [==============================] - 9s 47ms/step - loss: 0.2264 - accuracy: 0.9421 - val_loss: 1.2425 - val_accuracy: 0.6809
Epoch 20/50
196/196 [==============================] - 9s 47ms/step - loss: 0.2018 - accuracy: 0.9514 - val_loss: 1.2495 - val_accuracy: 0.6838코랩에서 진행했으며, 런타임을 초기화 한 후, 1차 학습을 진행한 뒤에 같은 조건에서 학습률만 올려서 진행해봤다. 런타임을 초기화 하지 않고 0.1000의 val_accuracy를 학습한 상태에서 learning rate만 줄여봤자 이미 1차학습의 gradient 구간을 벗어나 엉뚱한 곳에서 신중한 학습을 하고 있는 것과 마찬가지이기 때문이다.
실제로 런타임 때문에 엄청난 시행착오를 겪으며, 뭐가 잘못됐는지 파악하기가 어려운 때가 많았다. ㅜ
여튼 결과를 보면 개선의 폭은 낮지만, 확실히 성능이 개선되는 것을 볼 수 있다. 현재는 SGD보다 훨씬 개선된 보편적으로 사용되는 adam과 같은 optimizer들이 있기 때문에 단순히 learning rate를 줄이는 것 외에도 optimizer의 변화를 주어도 확실한 개선이 이뤄진다.
Batch Normalization
다음은 미세조정의 구간 설정과 관련된 공부를 좀 하다 딥러닝 모델의 중요한 요소인 배치 정규화 레이어(BN-Batch Normalization)에 대한 이야기를 해보고자 한다.
전이학습을 위한 'imagenet' weights를 가진 유명한 사전학습 모델들 중엔 그 내부 구조에 Convolution Layer 다음에 Batch Normalization(일명 BN)이라는 Layer를 가진 녀석들이 있다.
0 input_1
1 Conv1
2 bn_Conv1
3 Conv1_relu
4 expanded_conv_depthwise
...
96 block_10_project
97 block_10_project_BN # Batch Norm
98 block_11_expand
99 block_11_expand_BN # Batch Norm
100 block_11_expand_relu
101 block_11_depthwise
102 block_11_depthwise_BN # Batch Norm
...
130 block_14_depthwise_relu
131 block_14_project위에서 잠깐 보았던 mobilnet의 계층에도 BN Layer가 있는 것을 볼 수 있다.
이 BN은 그저 딥러닝 모델의 정규화 도우미 정도로 알고 있었는데 이녀석이 사전학습에 어떤 영향을 미치는 것인지 알아보았다.
배치정규화 관련 내용 참고: https://velog.io/@dltjrdud37/Batch-Normalization
배치 정규화가 무엇인가?
위 링크를 통해 배치정규화 관련 내용을 알 수 있는데, 자세한 이론적인 내용은 링크를 참고하길 바라며, 단계별로 설명을 하면 아래와 같다.
Training mode:
- 입력값 x가 Dense layer(히든레이어)를 1개 지난다.
- 해당 값을 BN 레이어를 들어가면서 분산을 1로, 평균을 0으로 정규분포와 같이 조정해준다.
1.Mini Batch()에 들어있는 data()들의 평균 과 분산()을 구한다.
2.각각의 데이터()에서 평균()를 빼줌으로써 평균을 0으로 만든다.
3.또한 그상태에서 분산()를 이용해서 표준편차()로 나누어준다. (=분모 0 방지)
4.각 데이터에서 위에서 구한 Training 시 학습이 되는 별도의 가중치 를 곱하고 를 더해준다. - 이를 활성함수를 적용시킨다.
- 변환된 아웃풋은 다음 Dense Layer(히든레이어, 만약 있다면)의 인풋이 된다.
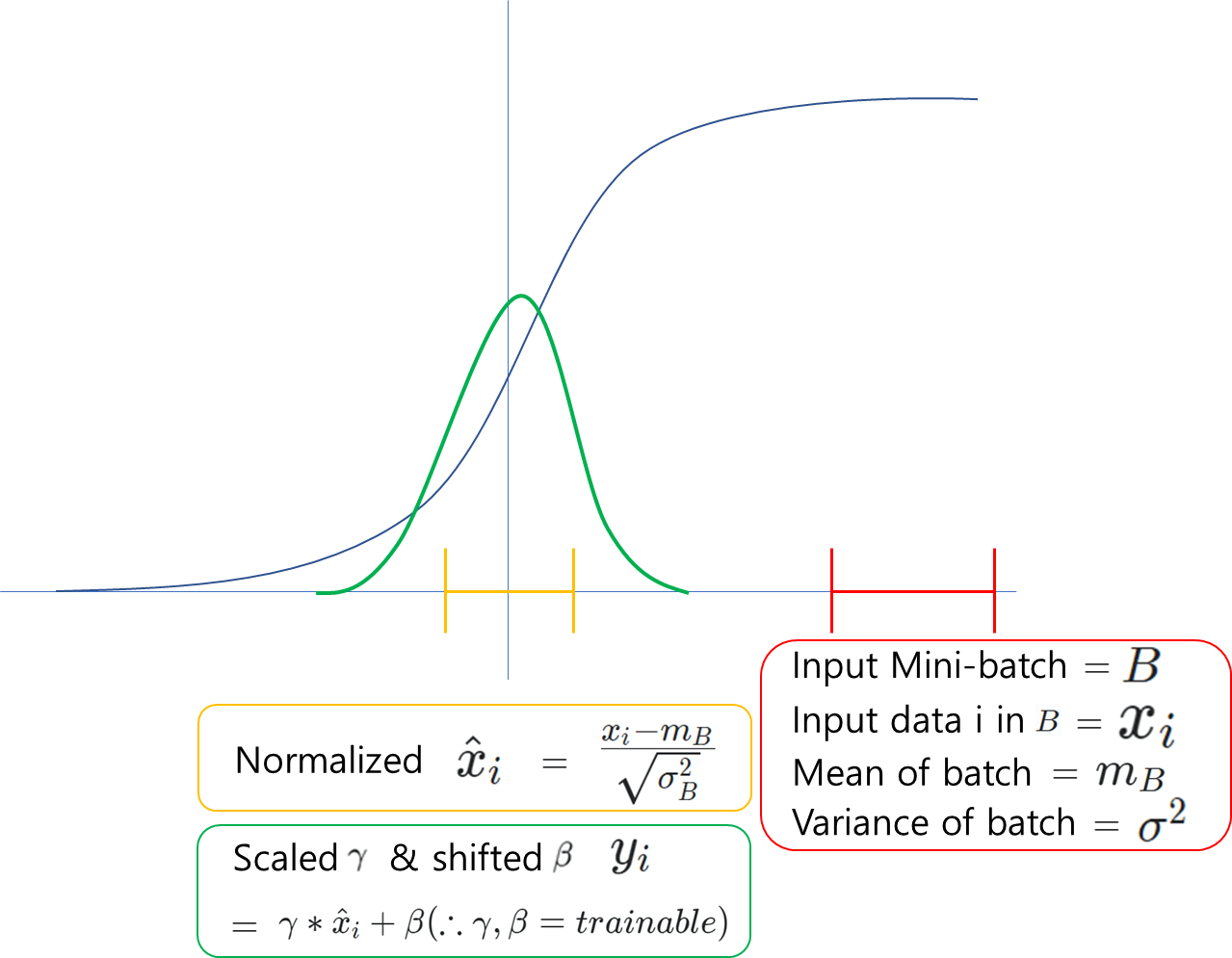
이를 표현하면 위와같이 그림으로 나타낼 수 있다.
시그모이드의 한 예인데 활성화 함수를 적용시키기 이전의 인풋 배치들의 분포를 붉은색에 위치한 뒤, 그 다음 분포가 또 다른곳에 위치하면 인풋 배치들에 의해 가중치 학습이 불안정해질 수 있다.
또한, 해당 붉은색과 같이 분포했을 때, 미분을 진행하면 시그모이드에 의해 0에 가깝게 수렴이 되어 gradient vanishing이 발생할 수 있다. 물론 ReLU, Leaky ReLU를 사용해 완화 하지만, 이는 어디까지나 완화를 위한 예방차원이기에 층이 깊어지면 결국 다시 발생한다.
이를 보완하고자 하는것이 배치정규화이다. 배치정규화를 했다고 모두 이미지의 초록색처럼 가우시안 형태를 띄는 것은 아니지만, 포인트는 분포가 제각각인 인풋 값들을 가능한 평균 0, 분산 1의 데이터로 정규화 및 초기화를 해놓은 상태에서 학습을 진행하겠다는 뜻으로 보면 된다.
Test mode(Inference mode):
- Inference mode는 모델을 fit하면 학습을 하면서 검증역시도 하는데, val_loss, val_accuracy를 파악하는 상태를 의미한다.
- Test할때는 batch의 개념이 없다. 그러므로 학습 과정의 mini batch단위로 보던 평균과 분산을 이용할 수 없다.
- 그러므로 batch 단위로 보면 평균들()과 분산들()의 평균을 통해 Val_set을 통과시켜 모델을 평가한다.
- 이때 평균은 지수이동평균(Exponential Move Average)를 이용해 기왕이면 더 자리가 잘 잡힌 최근의 (평균 및 분산)의 평균값을 대입시켜 검증한다.
여기서의 Test mode는 추론모드를 말하며, 코드 상에서 모델 레이어의trainable = False를 통해 학습 불가능한 상황에서 이뤄진다.
CNN에서의 Batch Normalization
많은 Docs에서 Inference Mode에 대한 언급이 있었는데, 정확히 Training과 뭐가 다른지 이제 알게되었다. 근데 이 BN이라는 것이 CNN에서는 약간의 달라지는 점이 있다.
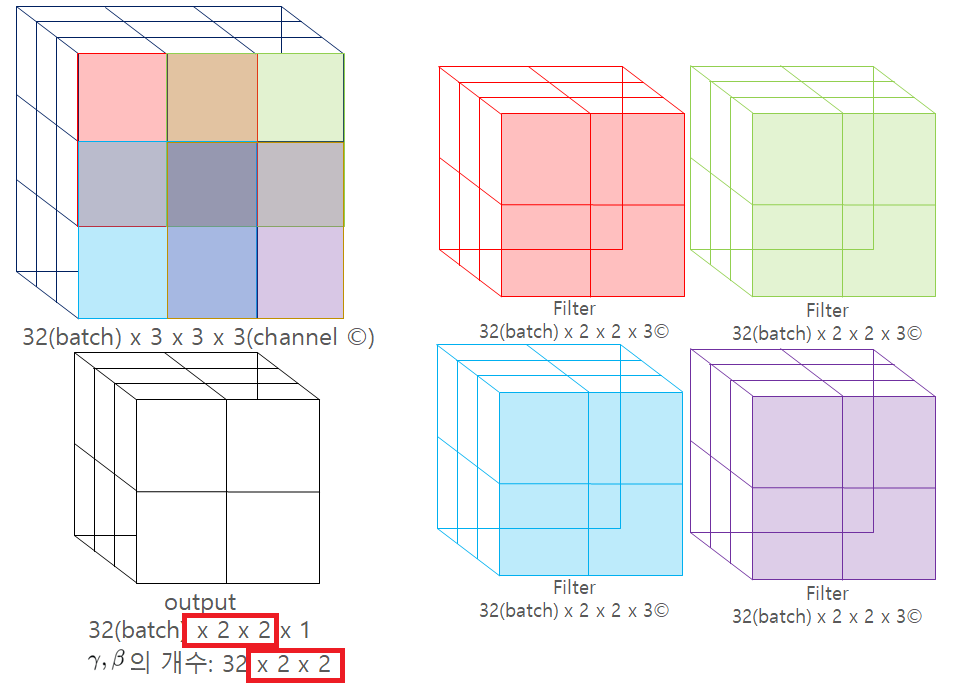
위 그림에서 Batch size가 32일때, 채널이 3개인 3x3 사이즈의 인풋데이터를 Convolution Layer에 넣는 상황을 이미지로 표현해봤다.
Conv Layer의 Filter를 2x2로 설정했을 때 BN을 사용하면 겹치는 부분의 와 는 같은 값을 가지게 되며, output feature map의 사이즈는 2x2가 되므로 그에 맞는 각각의 및 값을 2x2배 더 갖게 된다.
따라서 일반적인 신경망 모델은 와 가 32개인 반면 convolution layer 다음의 BN은 32x2x2(batch_size X height X width)개 만큼 더 생기게 된다.
Fine Tuning 시
Batch Normalization
위 내용과 같이 BN layer에 대해 알긴 했는데, 전이학습에서의 미세조정 시, 그 내부의 BN Layer를 어떻게 하면 좋을까? 하는 의문이 생길 수 있다.
수많은 포스팅과 Docs를 보면서 헷갈릴 수밖에 없었다. 어디에서는 BN을 동결해야한다 하고, 어떤이는 모두 학습해야 한다는 등 단정지어 말하는 글들이 상당했다.

출처: https://keras.io/examples/vision/image_classification_efficientnet_fine_tuning/
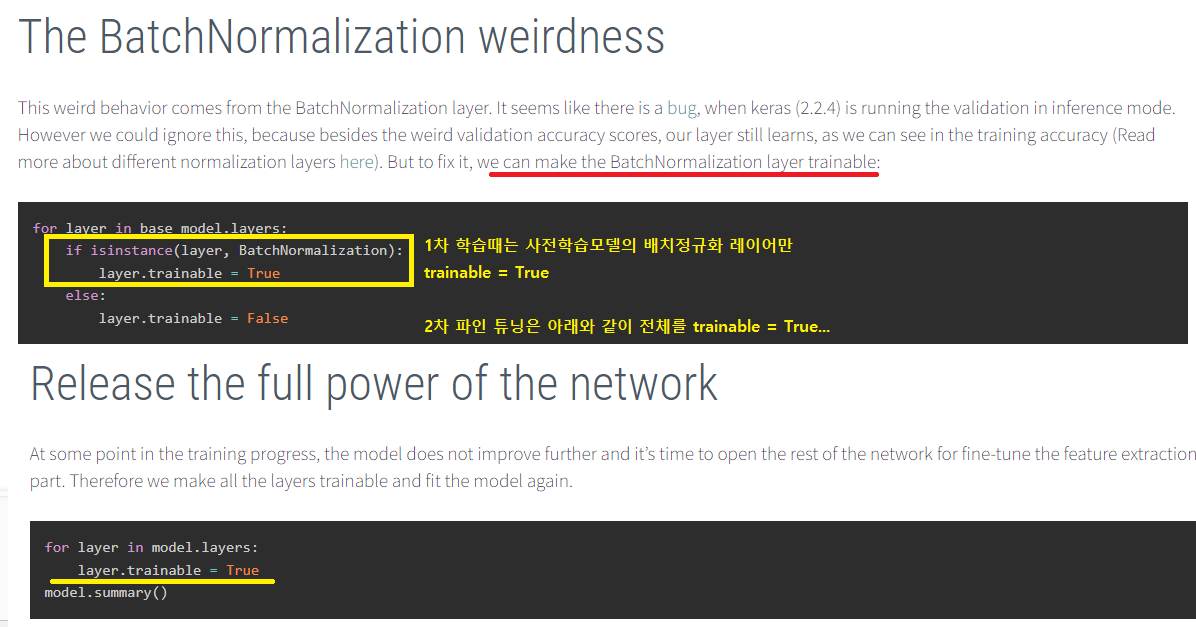
출처: http://digital-thinking.de/keras-transfer-learning-for-image-classification-with-effificientnet/
위 글이 사실이 아니라는 얘기는 아니지만, EfficiantNet과 관련된 전이학습 미세조정의 얘기만 두고도 keras docs와 사람들의 연구 결과들이 일치하지 않는다.
하여 며칠간 계속해서 실험을 진행해봤지만 cifar10의 데이터가 적어서인지 크게 눈에 띄는 차이는 없었다.
다만 계속해서 이론상으로 파악하여, 동결을 해제할 경우 그 뒤에 나오는 BN Layer를 같이 풀어주는 것이 좋다는 결론을 내렸다.
예를 들어 Conv Layer의 동결을 해제한다면, BN이 있는데 풀어주지 않을 경우 그 이전까지는 inference 모드로 학습된 와 로 입력이 되었다가 Conv Layer부터 새로운 값으로 변하게 됨에도 지수이동평균으로 배치를 하게 되므로 효과가 없어진다.
미세조정의 구간 설정
결국 이에 대한 결론으로는 '정답이 없다'라고 내렸다. 허무한 결과 같지만, 며칠간 수많은 시도를 통해 얻은 값진 결론이었다.
경우에 따라, 내가 가진 데이터의 수, 데이터의 형태에 따라서도 최적의 방법은 달라질 수 있다.
전이학습 모델은 초반부 층에서 저수준의 표현을 학습하고, 마지막 레이어에서 가장 고수준의 특징을 학습한다. 이 점을 고려해서 많은 글들에서 마지막 블록 또는 층을 해제하곤 하는데, 이 역시도 꼭 그래야만 하는 것은 아니다.
내가 가진 데이터 이미지가 사전학습모델과 많이 다르다면 동결해제를 앞쪽으로 진행해서 할 수도 있는 것이다. 또한 resnet의 경우는 블록단위로 residual connection이 있으니 기왕이면 어느 블록의 동결 해제시 블록 전체를 해제해주면 더 좋지않을까 하는 생각도 해본다.
많은 층을 학습한다고 꼭 좋은 것이 아니고, 마지막 층만 학습한다고 많은 성능 개선이 된다고 단정지을 수 없기에 최적의 방법을 찾기 위한 다양한 시도가 필요하다.
