
Batch Normalization
Batch Normalization은 최근 딥러닝에서 거의 필수적으로 사용하고있는 방법으로 역전파(backpropagation)에서 기울기의 사라짐, 가중치 초기화의 의존성 문제를 개선하고 dropout을 대체하는 효과를 가지고있다.
Covariate Shift
Batch Normalization을 이해하기 위해서는 우선 Covariate Shift라를 개념을 먼저 알아야한다.
Covariate Shift는 아래와 같이 훈련데이터와 테스트데이터의 분포가 다른 것을 말하며 이렇게 학습할 때와 실제 검증할 때 데이터 분포가 달라지면 당연히 예측 정확도는 떨어질 수 밖에없다.
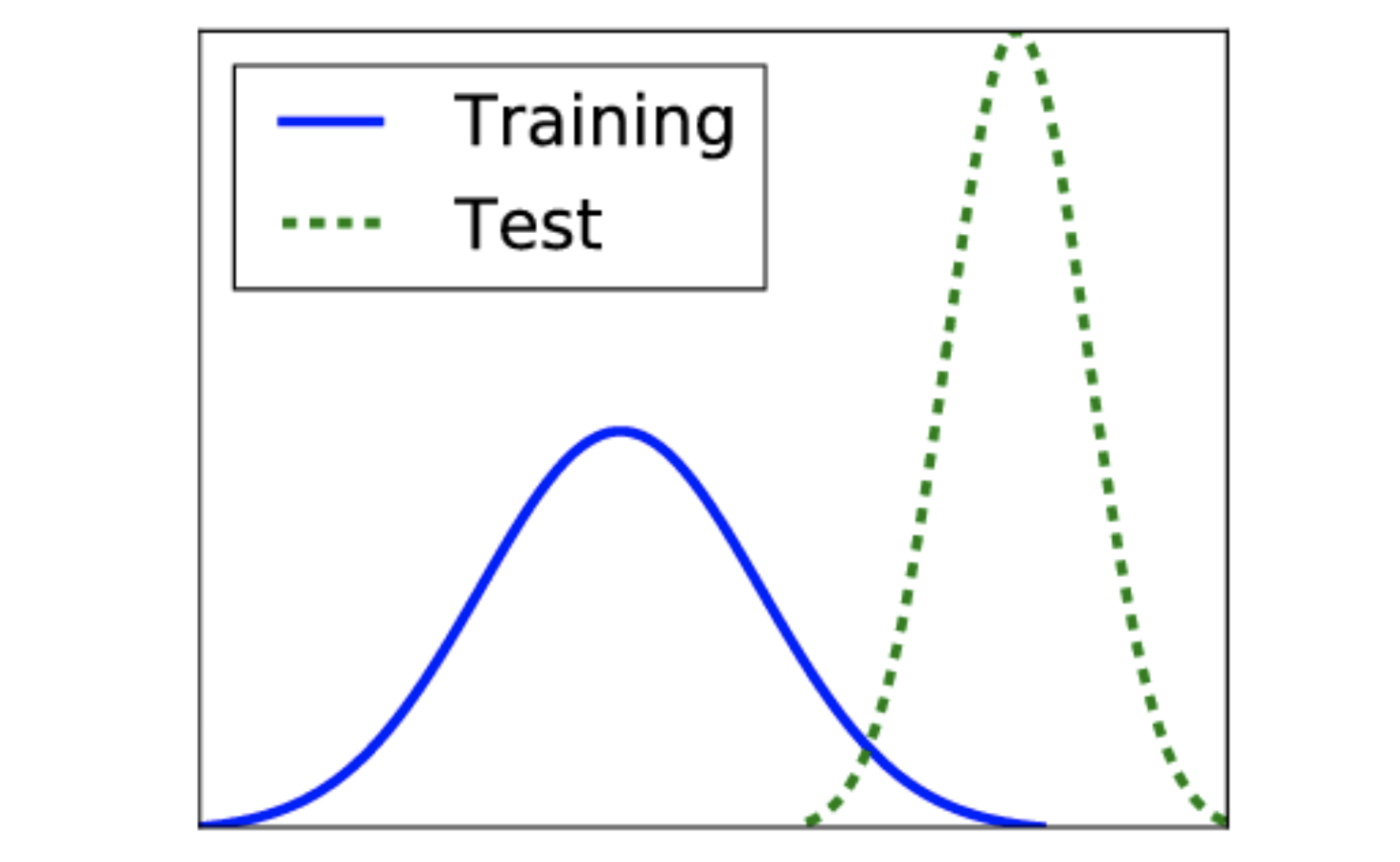
이러한 Covariate Shift 문제는 깊은 신경망의 각 layer에서도 발생한다. 입력이 가중치 w와의 곱 정확히는 내적에의해 layer를 거칠 때마다 분포가 조금씩이지만 계속 변하기 때문이다. 이렇게 신경망 내부에서 Covariate Shift가 발생하는 현상을 Internal Covariate Shift라고 부른다.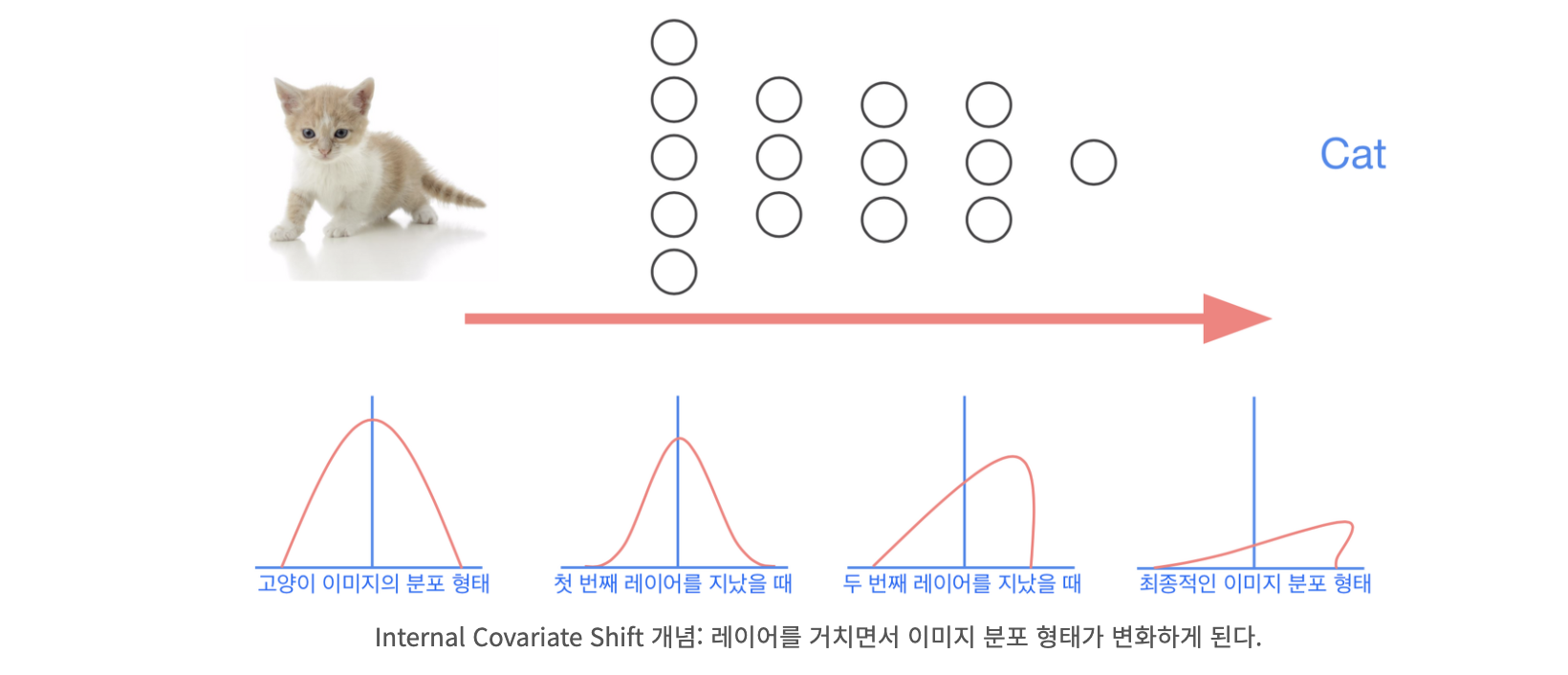
Parameter γ(감마), β(베타)
따라서 가중치의 내적에의해 입력의 분포가 달라지는 것을 방지하기위해 정규화(일반적으로 평균을 0 분산을 1로 변환)과정을 거치며 이 과정은 가중치의 내적인 선형연산과 active function이 동작하는 비선형 연산 중간에서 동작한다.
만약 모델이 CNN이라면 Batch Normalization은 Convolution layer를 통과한 결과인 feature map에 이루어질 것이다. 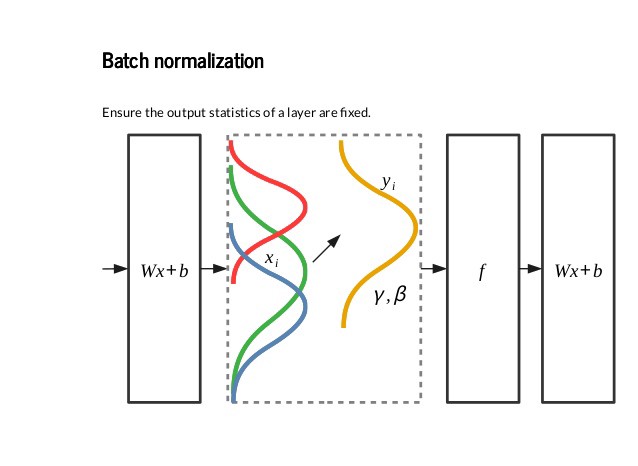
이러한 정규화는 훈련집합 전체가아닌 미니배치(mini-batch)단위로 평균과 분산을 구한 값으로부터 이루어지며 여기서 γ, β라는 파라미터가 등장한다. 이 값들은 학습에의해 결정되는 값이다.
γ : 정규화된 분포를 스케일링하는 파라미터로 분포를 좁게 혹은 넓게 만든다
β : 정규화된 분포를 이동시키는 파라미터로 분포를 shift 시킨다
Batch Normalization의 장점
- 정규화를 거쳐 γ, β에의해 입력 데이터 분포가 활성화함수의 입력에 최적화 될 수 있도록 조절되므로 Gradient Vanishing 문제가 개선된다.
- 보다 안정적인 분포를 만들어주기 때문에 높은 학습률(learning rate)를 허용한다. 따라서 더 빠른 학습이 가능해진다.
- 가중치 초기화를 하지않아도 후처리작업에의해 분포가 조정되므로 초기화에대한 의존도가 적어진다.
- 결국에는 Dropout 기법이 노드를 무작위로 삭제해 특징을 조금 더 세분화하고 이를 앙상블 결합하는 것인데 이는 Batch Normalization이 최적의 분포를 만들어 활성화함수에의해 특징이 잘 발현되게끔하는 것과 같은 효과라고 볼 수있다. 따라서 Batch Normalization을 사용함으로써 Dropout을 대체할 수 있다.
예측단계에서의 후처리 작업
정규화를 과정을 거친 후 예측(prediction) 단계에서는 학습데이터의 평균, 분산과 미니배치 단위에서 얻어진 γ, β로 부터 다음과 같은 변환 과정이 이루어진다. 아래 식에서 평균과 분산은 학습(train)데이터의 평균과 분산이라는 것을 주의해야한다. 이는 학습데이터의 평균과 분산이 전체 모수의 그 것과 비슷한 분포를 가진다고 가정으로하기 때문이다. 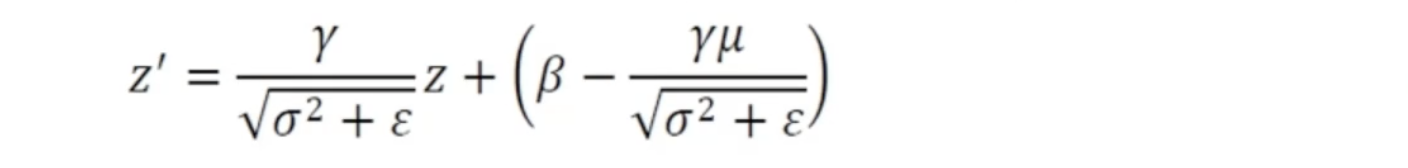
참고
https://hcnoh.github.io/2018-11-27-batch-normalization
https://wegonnamakeit.tistory.com/47
https://shuuki4.wordpress.com/2016/01/13/batch-normalization-%EC%84%A4%EB%AA%85-%EB%B0%8F-%EA%B5%AC%ED%98%84/
