Feature Engineering - 범주형 feature에 대한 처리Encoders(OneHotEncoder / OrdinalEncoder)
특성공학이란?
원핫인코딩에 대한 정리에 앞서 특성공학에 대해 알아본다. 기계학습을 진행하면서 더 좋은 예측으로 성능을 개선하기 위해 특성공학(Feature Engineering)을 진행하게 된다. 이러한 특성공학은 특성선택(Feature Selection), 조합, 제거 등을 통해서 모델링 하기 좋은 상태를 만들어 원하는 예측 성능을 더욱 높이기 위해 진행된다.
df.corr() 등을 통해서 특성들의 상관계수를 파악해 Target과의 상관관계가 낮은 특성을 제거하기도 하고, 비슷한 뉘앙스의 특성을 더해 새로운 특성을 만들기도 하지만, 범주형 데이터는 상관계수가 표시가 안되고, 숫자가 아니기 때문에 컴퓨터가 이를 잘 인식하지 못할 수 있어 이러한 범주를 숫자로 치환하여 사용할 수 있다.
그 때 사용하는것이 OneHot / Ordinal Encoding이다.
OneHotEncoding이란?
Categorical Feature(범주형 특성)는 String으로 되어있거나 그 의미가 수치와 관련있지 않은 경우 이를 수치화 하여 해당 범주를 특성으로 만들어 그 범주 별로 영향력을 높이기 위한 인코딩 방법중 하나이다.
예를 들어, 샘플별로 정해진 컬러가 있는 COLOR feature가 있고, 그 범주들이 각각 RED, YELLOW, BLUE로 정해져 있을 때, 기계학습 진행 시 이 특성과 타겟간의 상관관계를 파악하지 못해 그 특성의 중요도가 떨어질 수 있다.
이 때, One hot encoding을 통해 각 컬러들을 특성으로 만들고, 이 특성을 가진 샘플에 대한 학습을 진행하도록 유도할 수 있다.
아래 one hot encoding의 예시를 한번 들어보겠다.
import pandas as pd
import numpy as np
# 예시용 데이터셋 작성
df = pd.DataFrame({'Fruit': ['시과', '딸기', '바나나', '수박', '포도'],
'color':['red','red','yellow','red','purple'],
'price': [2000,300,400, 30000, 150]})
df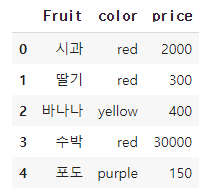
위와 같이 과일 컬러와 개당 가격이 기재되어있는 데이터셋을 준비했다(정말 열매 개당으로 계산하는 바보같은 데이터). 컬러로는 red, yellow, purple이 있는데, 이는 각 다른 샘플들에 정해진 3개의 범주라고 볼 수 있으며, 이를 수치화하기 위한 one hot encoding을 진행해보도록 하겠다.
colab에서 version차이로 안될 경우 'pip install category_encoders'를 이용해 설치해야한다.
from category_encoders import OneHotEncoder
enc = OneHotEncoder(cols = 'color', use_cat_names = True)
df = enc.fit_transform(df)
df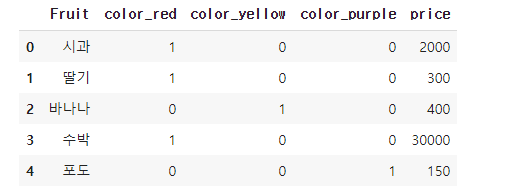
one hot encoding을 진행해 color 특성의 범주들을 수치화 및 분리하여 데이터프레임을 변경했다.
use_cat_name = True : 기존 특성인 'color'를 각 범주 앞에 달 수 있도록 한다.
cols = 'feature' : 원하는 특성만 골라서 인코딩을 수행할 수 있다. 위와 같은 상황에서는 Fruit 역시도 범주형으로 인식하므로 cols로 원하는 column을 지정해줘야 한다. 이 cols의 default는 None이며, default값으로 진행 시, 자체적으로 모든 범주형 feature를 파악해 encoding을 수행한다.
* 특성의 범주가 너무 많은 경우, 중요치 않은 특성들이 많아질 수 있어 one hot encoding은 오히려 성능저하를 일으킬 수 있다.
# 예시용 데이터셋 작성
df1 = pd.DataFrame({'Fruit': ['시과', '딸기', '바나나', '수박', '포도', '메론','자두','체리','화이트베리', '무화과'],
'color':['red1','red2','yellow','red','purple','green','light red','pink','white','brown'],
'price': [2000,300,400, 30000, 150, 8000,1000,100,300,800]})
df1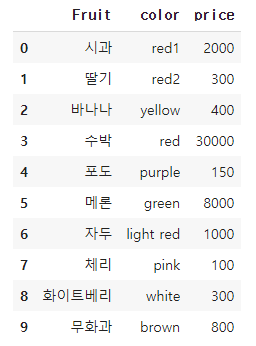
enc = OneHotEncoder(cols = 'color', use_cat_names = True)
df1 = enc.fit_transform(df1)
df1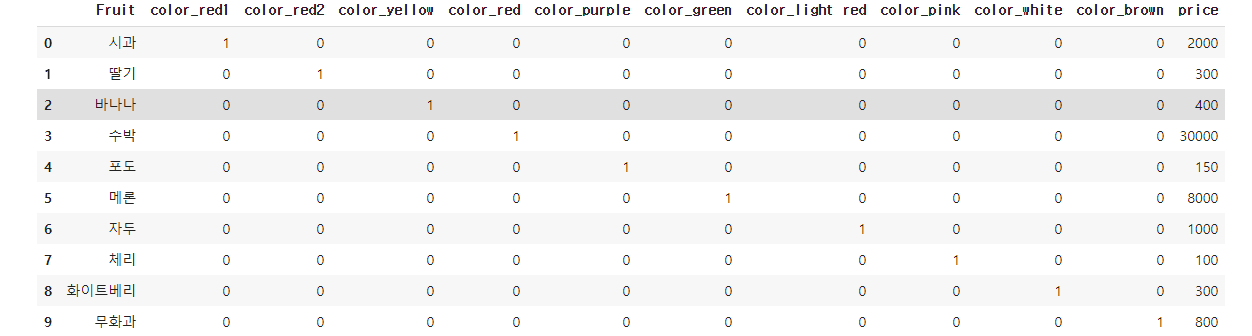
범주를 전부 다른것으로하여 총 10가지 범주에 대한 one hot encoding을 해보았다.
위와 같이 너무 많은 특성들이 발생해서 범주의 수에 따라 one hot encoding을 사용을 할 지 잘 생각해봐야한다. 물론, 특성이 너무 많고 적음의 기준은 내가 직면한 문제에 따라, 어떻게 풀어나갈지에 따라 특성이 많음에도 사용할 지 말지 결정할 수 있다.
또한, 이렇게 범주가 굉장히 많은 경우 대안으로 쓸 수 있는 다른 인코딩 방법이 있다. 바로 Ordinal Encoding이다.
OrdinalEncoding이란?
Categorical feature(범주형 특성)에 대한 순서형 코딩이라고 하며, 각 범주들을 특성으로 변경하지 않고, 그 안에서 1,2,3 등의 숫자로 변경하는 방법이다. 범주가 너무 많아 one hot encoding을 하기 애매한 상황에서 이용하기 좋은 인코딩 방법이다. 또한 트리모델은 중요한 feature가 상위 노드를 점하여 분할을 하게 되는데, one hot encoding을 한 특성은 뽑히기에 불리한 상태가 되므로 대안으로 Ordinal Encoding을 한다.
# 예시용 데이터셋 작성
df2 = pd.DataFrame(
{'Fruit': ['시과', '딸기', '바나나', '수박', '포도',
'메론','자두','체리','화이트베리', '무화과'],
'color':['red1','red2','yellow','red','purple','green','light red','pink','white','brown'],
'price': [2000,300,400, 30000, 150, 8000,1000,100,300,800]})
from category_encoders import OrdinalEncoder
enc1 = OrdinalEncoder(cols = 'color')
df2 = enc1.fit_transform(df2)
df2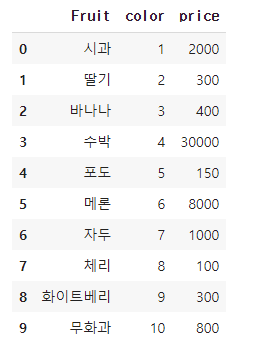
이 전과 같은 데이터셋을 만들어 cols = 'color'로 지정해 Ordinal encoding을 진행 해봤다.
컬러가 전부 달랐기 때문에 1~10까지로 변경된 것을 볼 수 있다. 데이터셋을 줄여 같은 것들이 구분되는지 보도록 한다.
# 예시용 데이터셋 작성
df3 = pd.DataFrame(
{'Fruit': ['시과', '딸기', '바나나', '멜론','레몬'],
'color':['red','red','yellow','green','yellow'],
'price': [2000,300,400, 30000, 500]})
df3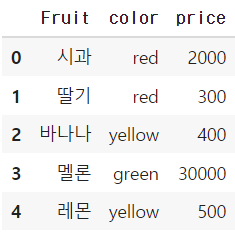
데이터셋을 줄여보았고, red 두개, yellow 두개, green 한개를 두어 순서형 인코딩을 진행해본다
enc2 = OrdinalEncoder(cols = 'color')
df3 = enc2.fit_transform(df3)
df3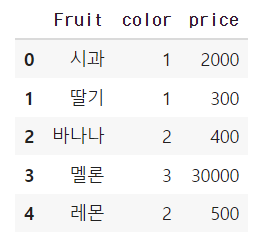
red가 1로 변경되고 yellow가 2, green이 3으로 변경되어 해당하는 color에 해당 number가 들어간 것을 볼 수 있다.
