RAG (Retrieval Augmented Generation)
- RAG는 외부 데이터를 참조하여 LLM이 답변할 수 있도록 해주는 프레임워크이다.
- RAG는 파인튜닝과 함께 엮어서 설명된다. 이들은 모두 LLM이 기존에 가지고 있지 않은 지식을 포함해서 답변할 수 있도록 만들어주는 프레임워크라고 할 수 있다. 파인튜닝의 경우 LLM이 가지고 있지 않은 지식을 학습시키기 위해서 학습을 시키는 과정이 필요하고, 그 과정에서 GPU와 같은 장비가 필요하기 때문에 RAG라는 것이 대두되었다.
RAG 구조
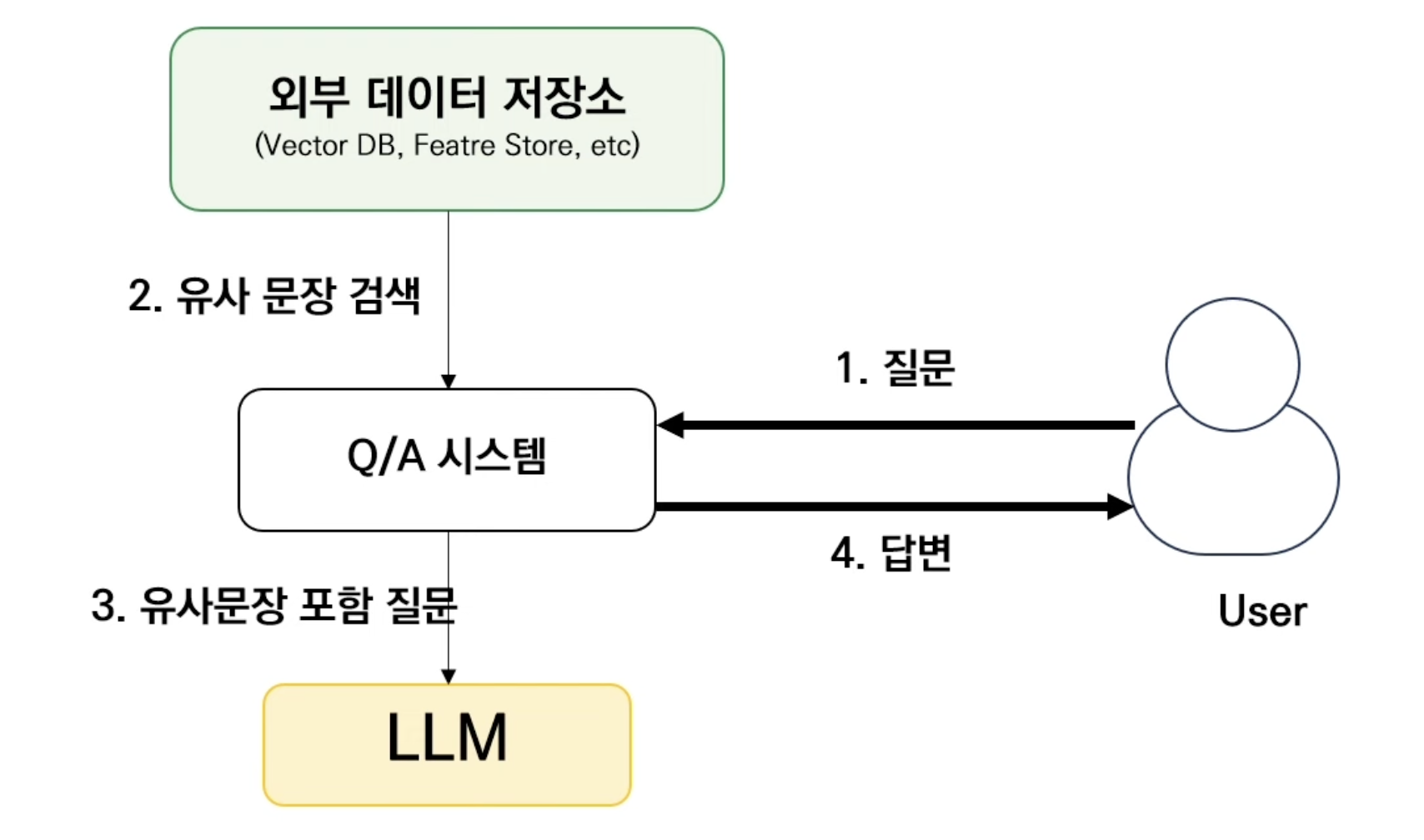
- 사용자들이 질문을 했을 때 Q/A 시스템이 외부 데이터 저장소에서 사용자의 질문과 유사한 문장이 무엇인지 검색하는 과정을 거친다. 이렇게 출력된 유사 문장과 사용자 질문을 합쳐서 LLM에게 프롬포트로 전달하게 되고 전달받은 LLM은 이런걸 다 포함해서 답변하게 된다. 이렇게 되면 외부 데이터 문장을 참조하여 답변하기 때문에 기존의 없던 지식도 포함해서 답변할 수 있게 된다.
LangChain
-
LangChain에서 Retrieval은 RAG의 대부분의 구성요소를 아우르며 구성 요소 하나하나가 RAG의 품질을 좌우한다.
-
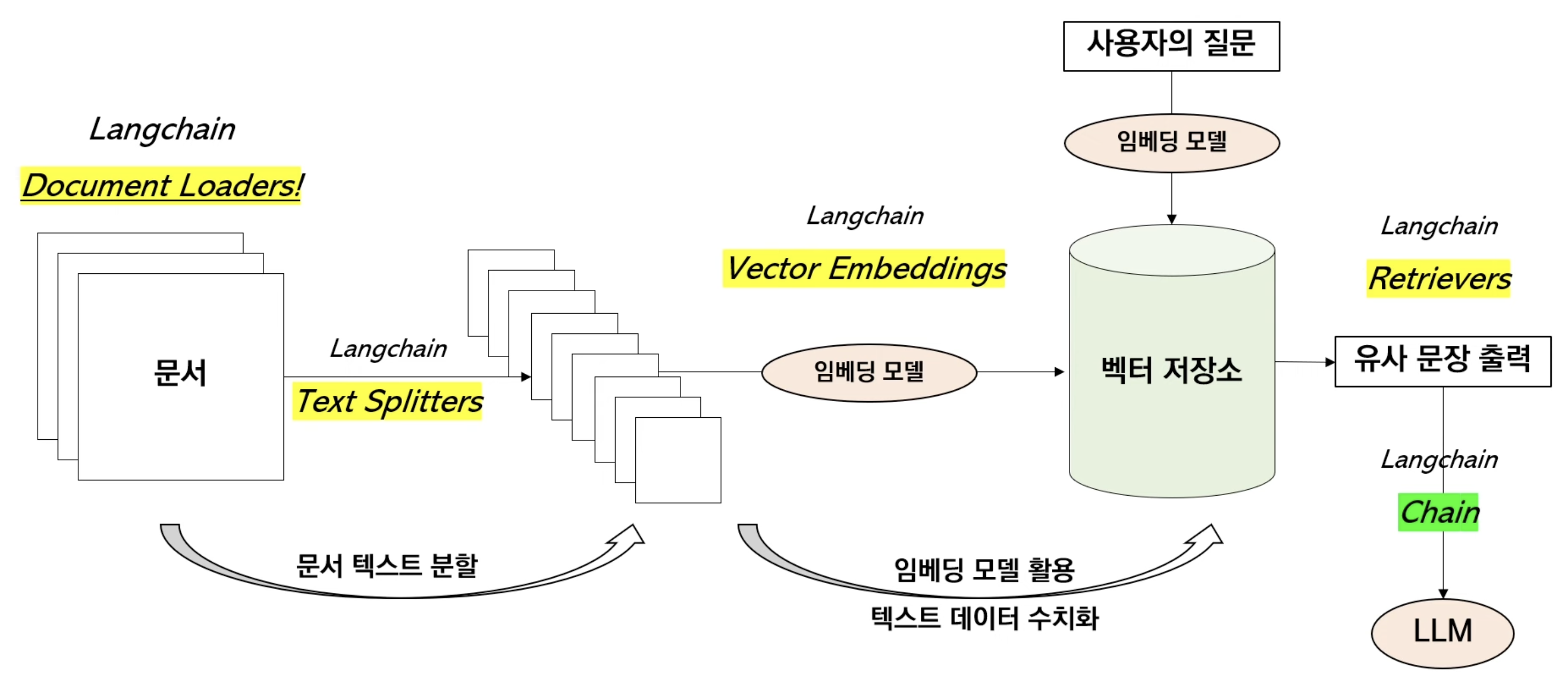
RAG 프레임워크는 아래와 같은 순서를 따른다.
-
문서를 불러오는 작업을
Document Loaders가 담당하며 그 후 여러 텍스트를 분할하는 걸Text Splitters가 담당하며 이러한 텍스트들을 그대로 저장하는 것이 아니라 Vector Embedding 형태로 저장하기 위해서 임베딩 모델을 한 번 거치고 이러한 모델을 통해서 수치화된 임베딩 값들을 벡터 저장소에 저장을 한다. 이러한 과정 또한Vector Embeddings가 담당을 한다. 그리고 나서 수치화된 텍스트 데이터들을 벡터 저장소에 저장을 하고 사용자의 질문과 가장 유사한 문장을 검색하는 역할은Retrievers가 담당한다. -
이러한 것들을 통해서 사용자들의 질문과 유사한 문장을 외부데이터에서 가져오게 되고 이를 LangChain의 Chain을 통해서 LLM이 문장을 생성하게 된다.
LangChain - Document Loaders
- 다양한 형태의 문서를 RAG 전용 객체로 불러들이는 모듈로 URL Document Loader는 웹에 기록된 글을 텍스트 형식으로 가져와 LLM에 활용할 수 있다.
Page_content: 문서 내용
Metadata: 문서의 위치, 제목, 페이지 넘버 등
pip install langchain unstructured pypdf pdf2image docx2txt pdfminer
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://n.news.naver.com/adsf")
data = loader.load()
print(data[0].page_content)from langchain.document_loaders import UnstructuredURLLoader
urls = [
"https://asdf1",
"https://asdf2"
]
loader = UnstructuredURLLoader(urls = urls)
data = loader.load()
data# PDF Document Loader
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("파일 경로")
# PDF를 page별로 자르는 작업
pages = loader.load_and_split()
# 첫 페이지
print(pages[1].page_content)LangChain - Text Splitters
Text Splitter는 토큰 제한이 있는 LLM이 여러 문장을 참고해 답변할 수 있도록 문서를 분할하는 역할이다.- 여러개의 문서를 더 작은 단위로 나눈 chunking을 통해 chunk들이 만들어지고 임베딩 벡터로 변환되는 과정을 거치고 사용자 질문을 하나의 임베딩 벡터로 수치화하는 과정을 거친다. 그것과 가장 유사한 수치를 벡터 스토어에서 찾고 이 임베딩 벡터에 해당하는 chunk와 사용자의 질문이 합쳐져서 최종 prompt가 완성되고 이 prompt를 통해 LLM이 답변을 한다. 또한 chunk 하나당 하나의 vector가 매칭이 된다. vector store안에 있는 임베딩 벡터들이 각각의 chunk들이 수치로 변환된거라고 생각하면 된다.
1) CharacterTextSplitter
- 구분자 1개 기준으로 분할하므로 max_token을 지키는 못하는 경우 발생
with open('/Users/kimjehyeon/study/강의대화1.pdf', 'rb') as f:
state_of_the_union = f.read()
print(state_of_the_union)
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n", # 구분자
chunk_size = 1000, # chunk_size
chunk_overlap = 100, # chunk 가 문단별로 나눈다고 했을 때 앞부분을 겹치게 왜냐면 문맥 파악이 필요하니
length_function = len,# chunk size를 측정할 때 무슨 기준으로 1000이냐 -> 글자수를 기준으로 하겠다.
)2) RecursiveCharacterTextSplitter
- 줄바꿈, 마침표, 쉼표 순으로 재귀적으로 분할하므로, max_token 지켜 분할
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter2 = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)Token 단위 텍스트 분할기
- 텍스트 분할의 목적은 LLM이 소화할 수 있을 정도의 텍스트만 호출하도록 만드는 것이다. 따라서 LLM이 소화할 수 있는 양으로 청크를 제한하는 것은 LLM 앱을 개발할 때 필수적인 과정이다.
- LLM은 텍스트를 받아들일 때, 정해진 토큰 이상으로 소화할 수 없게 설계되어 있다. 따라서 글을 토큰 단위로 분할한다면 최대한 많은 글을 포함하도록 청크를 분할할 수 있다.
- 토큰이라는 것은, 텍스트와 달리 Transformer에서 처리하는 방식에 따라서 그 수가 달라질 수 있다. 따라서, LLM 앱을 개발하고자 한다면 앱에 얹힐 LLM의 토큰 제한을 파악하고, 해당 LLM이 사용하는 Embedder를 기반으로 토큰 수를 계산한다. 예를 들어, OpenAI의 GPT 모델은 tiktoken이라는 토크나이저를 기반으로 텍스트를 토큰화한다. tiktoken encoder를 기반으로 텍스트를 토큰화하고, 토큰 수를 기준으로 텍스트를 분할하는 것은 필수라고 할 수 있다.
import tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=0, length_function=tiktoken_len)
texts = text_splitter.split_documents(pages)참고
모두의 AI
