Text Embeddings
-
텍스트를 숫자로 변환하여 문장 간의 유사성을 비교할 수 있도록 한다.
-
분할된 문서들을 각각의 하나의 Embedding Model로 변환
-
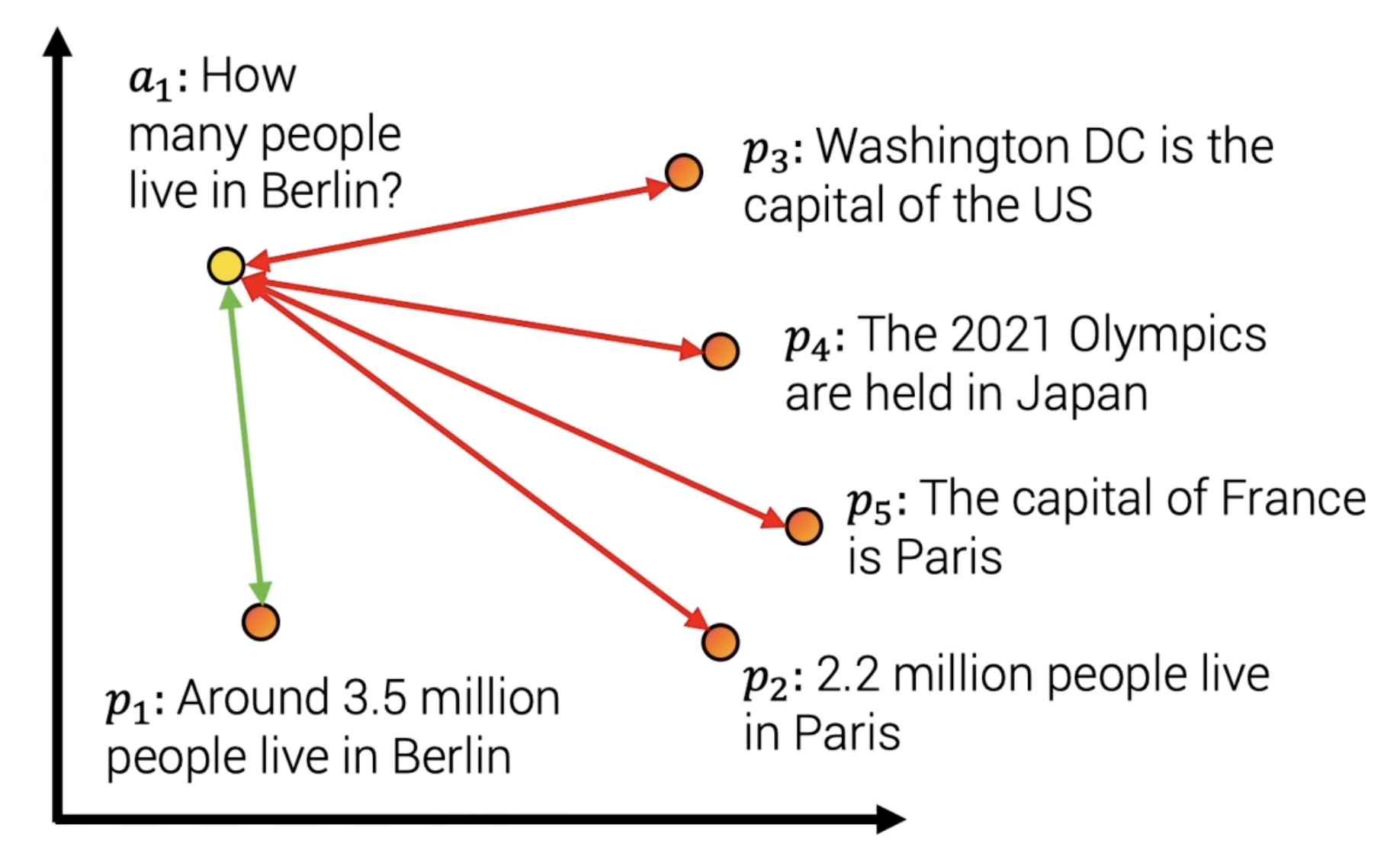
비정형 데이터를 숫자로 표현해 좌표 안에 위치시킬 수 있다. 이러한 좌표 상에서 가장 가까운 벡터를 찾음으로써 유사한 문장을 찾는다.
-
이러한 문장들을 어떻게 수치로 나타낼까..... 그건 보통 대용량의 말뭉치로 사전 학습된 모델을 사용하게 된다. 그렇게 되면 Pre-trained Embedding Model이 된다. Bard, Chatgpt와 같은 모델들이 이에 해당한다. 이러한 사전학습 모델을 사용해 학습시킬 것.
-
유료 임베딩 모델 (OpenAI, Cohere, Amazon)
- 사용하기 편리하지만 비용 발생
- API 통신 이용하므로 보안 우려
- 한국어 포함 많은 언어 임베딩 지원
- GPU 없이도 빠른 임베딩
-
로컬 임베딩 모델 (HuggingFace)
- 무료지만 다소 어려운 사용
- 오픈소스 모델 사용하므로 보안 우수
- 모델마다 지원 언어가 다름
- GPU 없을 시, 느린 임베딩
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="API_KEY")
embeddings = embeddings_model.embed_documents(
[
"안녕하세요",
"제 이름은 홍길동입니다.",
"이름이 무엇인가요?",
]
)
# 문장 하나마다 임베딩 하나씩 추가됨
print(len(embeddings)) # 3벡터 유사도 측정
from numpy import dot
from numpy.linalg import norm
import numpy as numpy
embedded_query_q = embeddings_model.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = embeddings_model.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
def cos_sim(A,B):
return dot(A,B)/(norm(A)*norm(B))
print(cos_sim(embedded_query_q, embedded_query_a))
Huggingface Embedding
pip install sentence_transformers
from langchain.embeddings import HuggingFaceBgeEmbeddings
# 영어로 잘 학습된 모델
model_name = "BAAI/bge-small-en"
# 한국어로 잘 학습된 모델 -> "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
embeddings = hf.embed_documents(
[
"todaay is monday",
"weather is nice today",
"what's the problem?",
]
)
BGE_query_q = hf.embed_query("Hello? who is this?")
BGE_query_a = hf.embed_query("hi this is harrison")
print(cos_sim(BGE_query_q, BGE_query_a))참고
모두의 AI
