
행과 열을 이용해 데이터를 관리하는데 굉장히 유용한 모듈인 Pandas에대해 학습했다. 그 중에 전부는 아니고 내가 그동안 헷갈렸거나 몰랐던 부분들만 정리해보겠다.
Pandas로 1차원 데이터 다루기 - Series
- 리스트를 이용한 Series 생성
s = pd.Series([1,4,9,16,25])
s
- 딕셔너리를 이용한 Series 생성
t = pd.Series({'one':1, 'two':2, 'three':3,, 'four':4, 'five':5
t
- numpy 이용
s = pd.Series([1,4,9,16,25])
np.array(s)
4. Series에 이름 붙이기
## N(0,1) 가우시안 표준정규분포에서 랜덤하게 5개를 뽑은 시리즈를 random_nums라고 이름붙임
s = pd.Series(np.random.randn(5), name ='random_nums')
s
Pandas로 2차원 데이터 다루기
- DataFrame 생성
d = {'height': [1,2,3,4], 'weight':[10,40,50,60]}
df = pd.DataFrame(d)
df
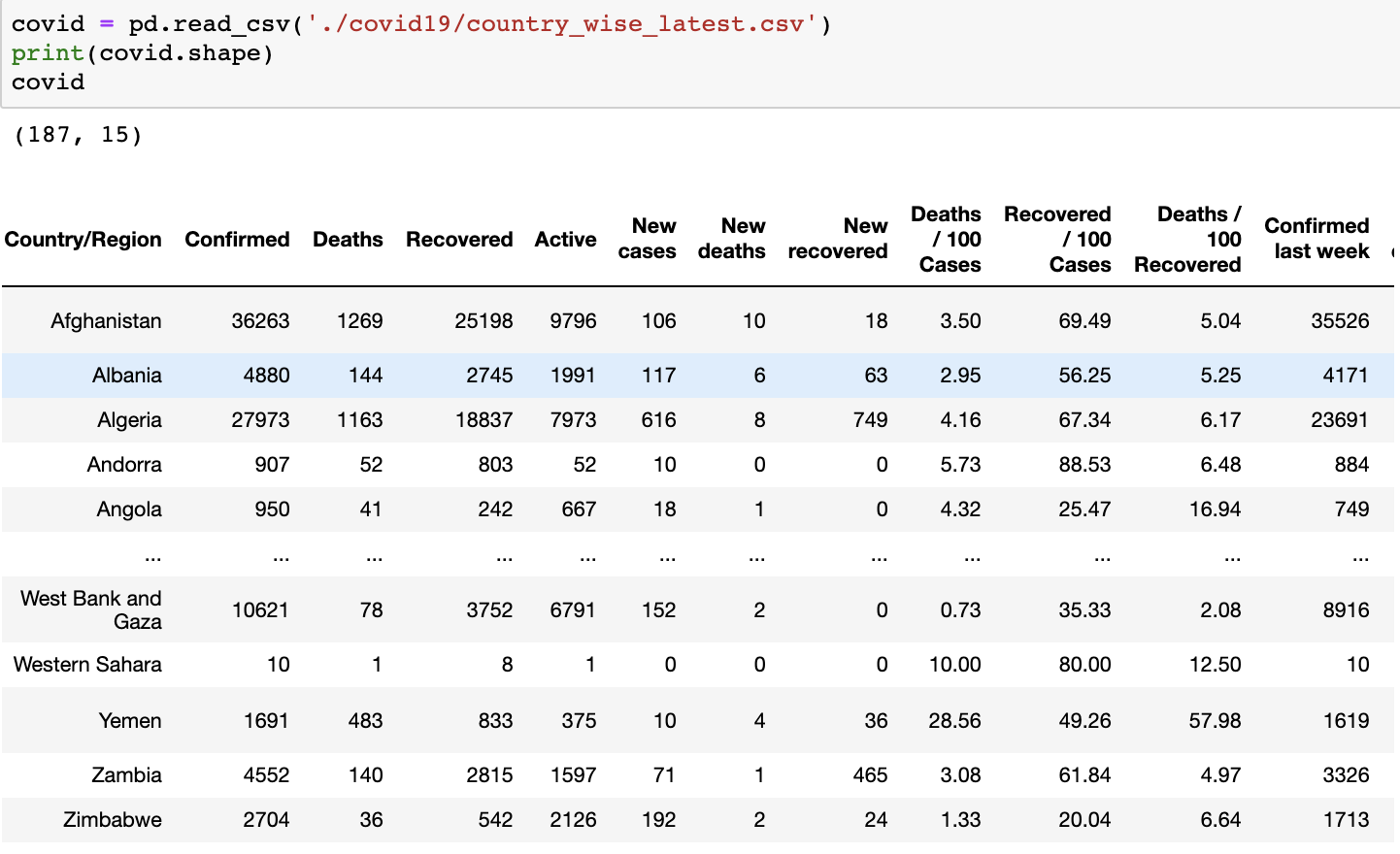
- CSV파일 읽어오기
- 아래는 country_wiseP_latest.csv 파일이 현재 작업하는 파일위치 기준으로 covid19라는 폴더에 있는 경우이다.
- 특정열의 데이터를 중복없이 확인하기
## WHO Region 열의 데이터 중복없이 확인
covid['WHO Region'].unique()
- groupby 메소드
1) Split : 특정한 기준을 바탕으로 DataFrame을 분할
2) Apply : 통계함수 - sum(), mean(), median() 등을 적용해서 각 데이터를 압축
3) Combine : apply된 결과를 바탕으로 새로운 Series를 생성 (group_key : applied_value)
## WHO Region 별 확진자수
# 1. covid에서 확진자수 column만 추출한다.
# 2. 이를 covid의 WHO Region을 기준으로 groupby한다.
covid_by_region = covid['Confirmed'].groupby(by= covid['WHO Region'])
covid_by_region.sum()
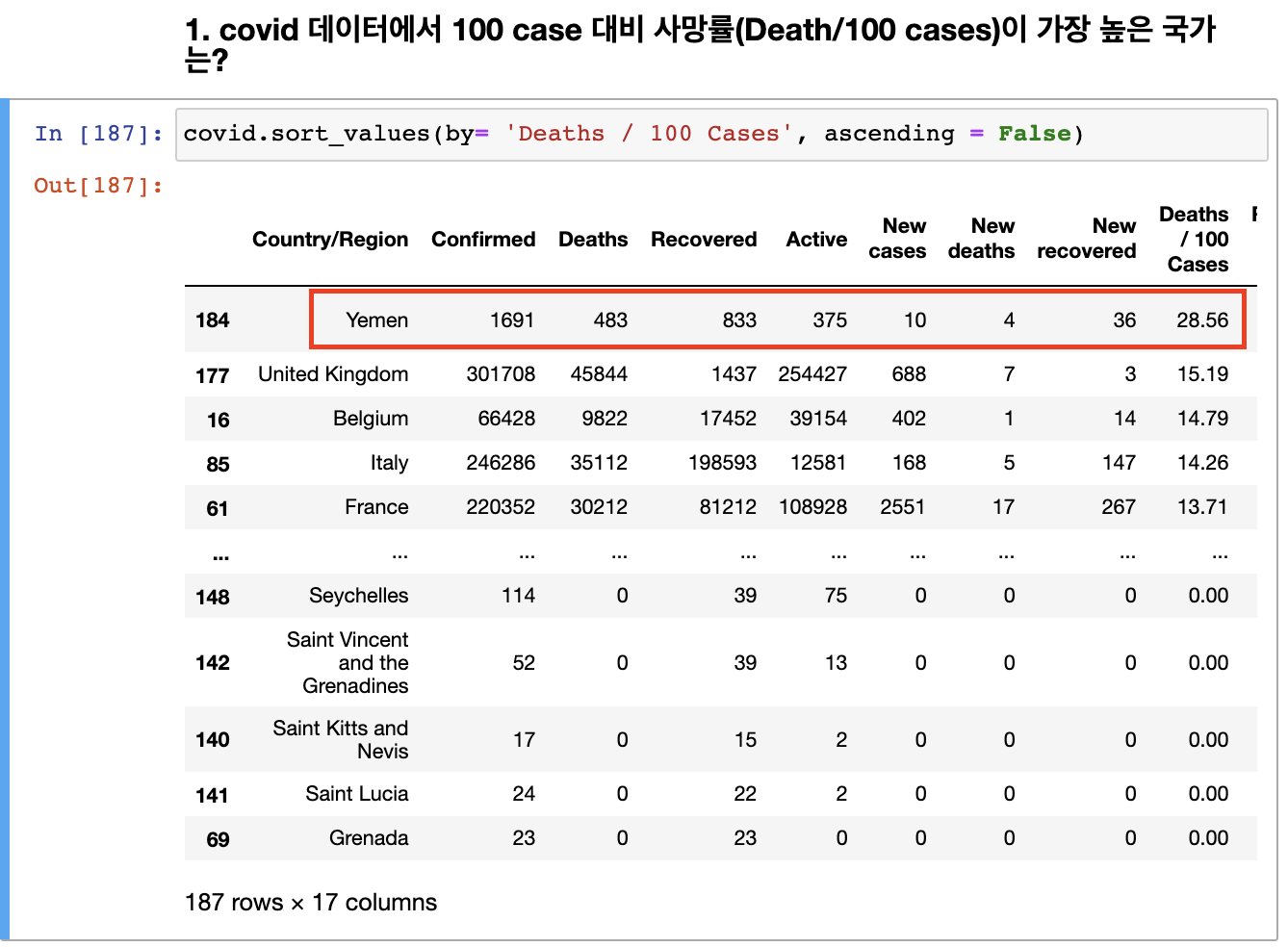
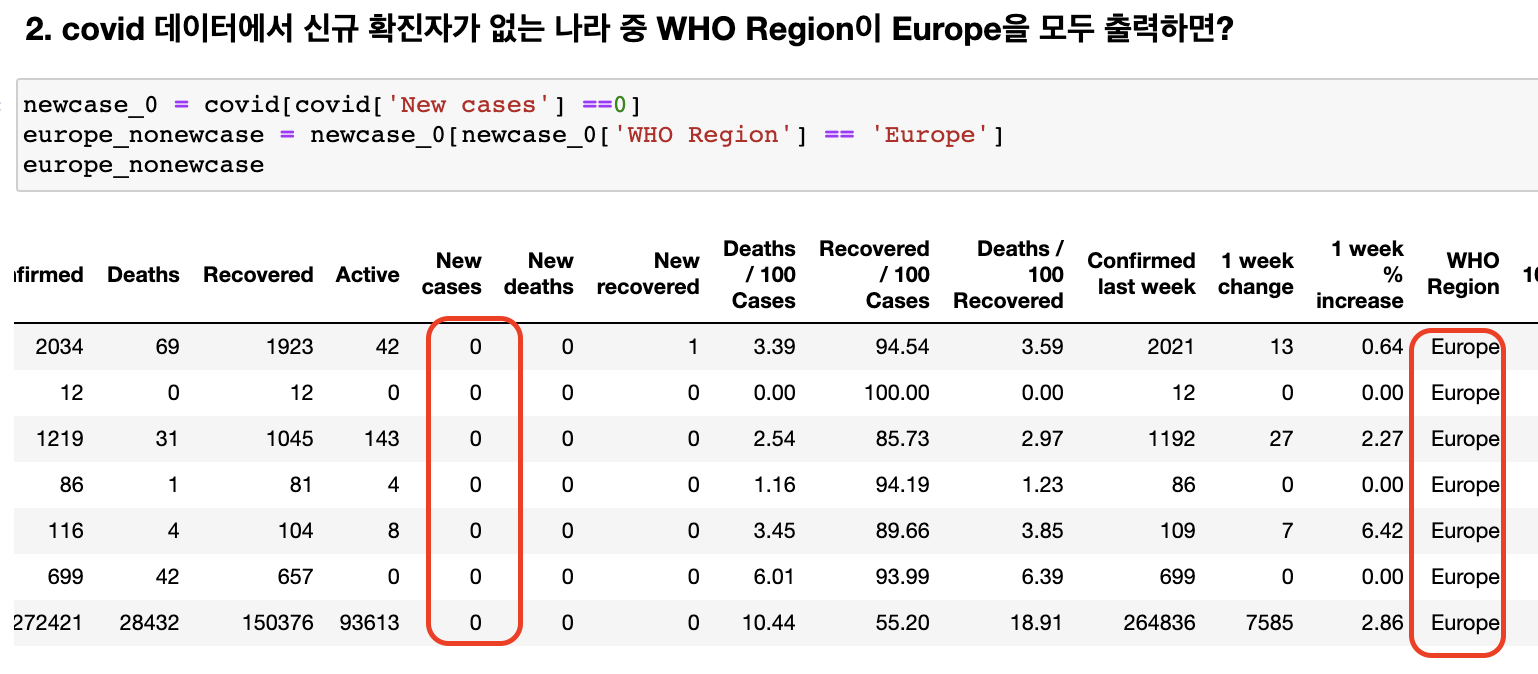
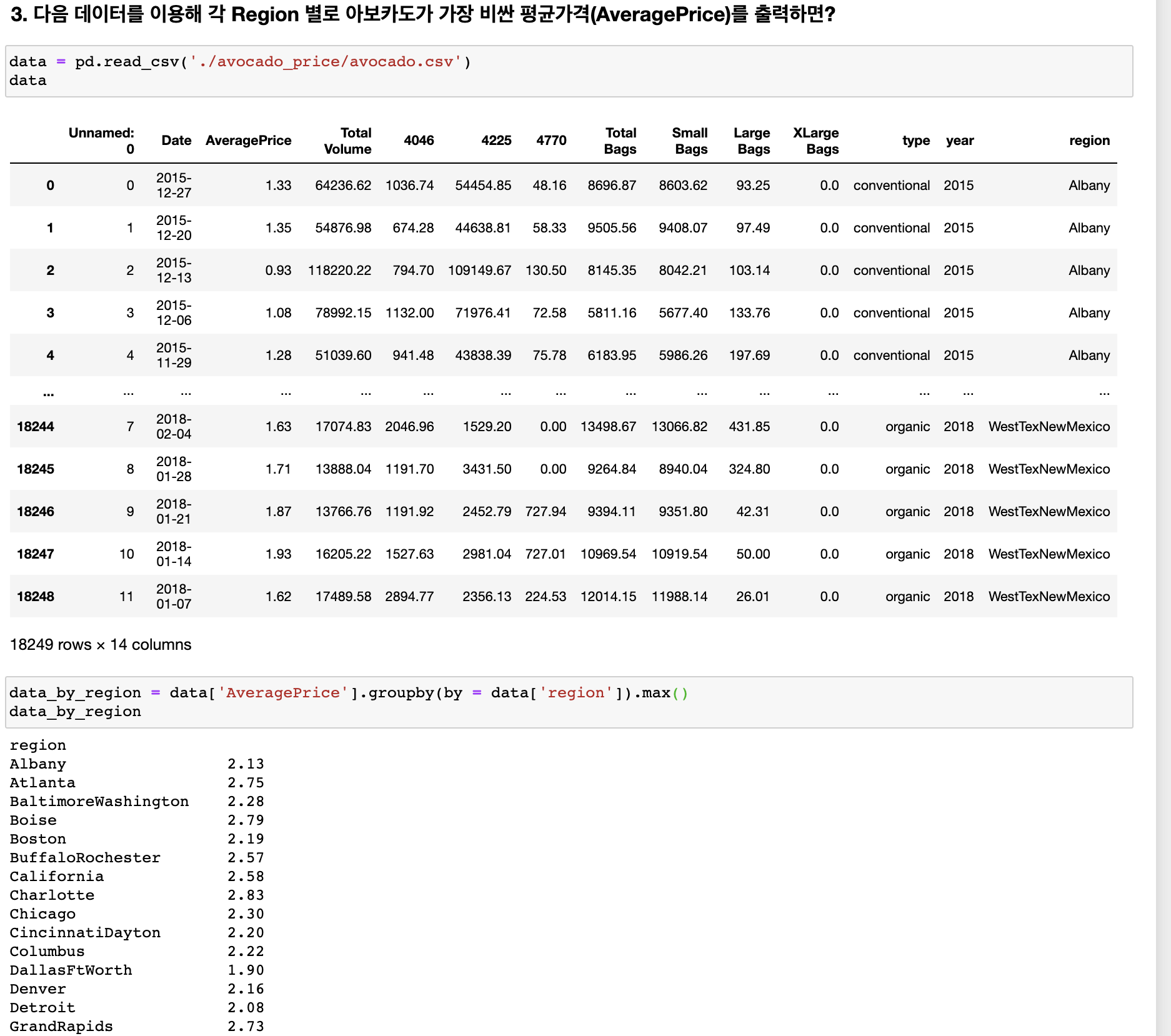
Mission

원하는 대로 살자