
블로그에 첫 논문으로 2017년 Google에서 발표한 이래 약 17,000회(2021년 2월 기준)나 인용되었고 자연어처리 분야의 발전에 크게 기여한 Attention Is All You Need을 리뷰해 보고자 한다.
내가 그동안 NLP 분야를 공부하면서 가장 굉장히 익숙하게 들어왔던 모델인 BERT와 GPT 역시 이 논문에서 제안하는 Attention Mechanism기반의 Transformer 기술을 적용했다고한다.
따라서 이 논문을 이해하는 것이 최신의 NLP분야의 모델에대해 알고 높은 퍼포먼스의 자연어처리 모델을 개발하는데 필수적이라고 할 수 있겠다. 또한 그렇기때문에 NLP를 관심있게 공부하는 나에게있어서도 첫 논문 리뷰로 Attention Is All You Need를 택한 것이 의미가있다고 생각했다.
비록 완벽하지는않지만 배우고 이해한 것을 최대한 간략하고 쉽게 정리해보도록 하겠다.
Background
기존의 RNN(Recurrent Neural Network)모델의 경우 기계번역, 요약, 감정분석, 예측 등 다양한 자연어처리 분야에 주로 사용되고 어느정도 성과를 보였었다. 하지만 다음과 같은 한계들 또한 지니고 있었는데,
- 첫째로 RNN 모델의 특징인 깊은 layer 때문에 Gradient vanishing & explosion 문제가 여전히 잔존했고
- 둘째로 순차적으로 데이터를 처리해야하는 이유로 parallel 연산이 어려웠다는 점
- 그리고 가장 큰 문제는 긴 문장이 입력으로 들어왔을 때 번역이나 예측에 한계를 보였다는 것이다. 문장이 길어 앞의 단어와 뒷 부분의 단어가 서로 의존성이 떨어지는 문제를 long term dependency라고하는데, 이는 첫 번째 단어가 hidden state를 통해 뒤로 전달되는 과정에서 정보가 점점 희석되어져 최종 출력에서 앞 부분의 정보를 제대로 반영하지 못해 정확도가 떨어지는 현상을 말한다.
seq2seq model
: 인코더의 출력을 고정된 벡터형태로 압축해서 디코더에 전달하려다보니 긴 문장의 입력이 들어왔을 때 정보를 제대로 담지 못해 long term dependecy와 마찬가지로 정확도가 떨어지는 문제가 발생하게 된다.
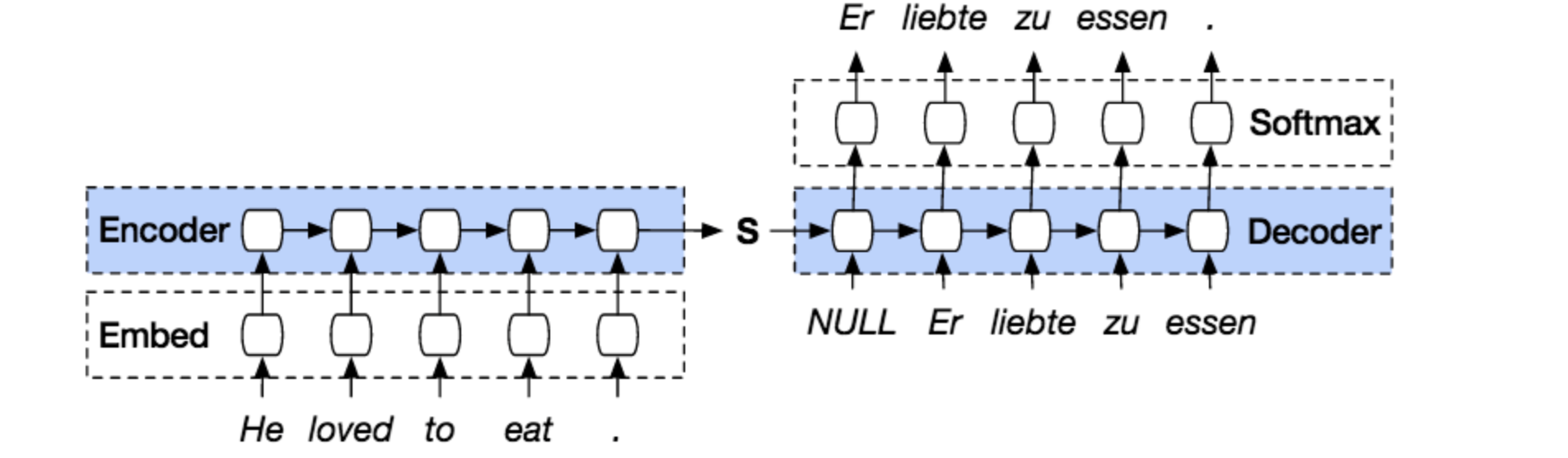
Attention Mechanism
위에서 설명한 RNN 모델의 고질적인 문제들을 해결하는 방안으로 등장한 것이 Attention 메커니즘이다.
기존의 RNN기반의 seq2seq모델이 인코더에서 최종적으로 나오는 hidden state의 정보를 압축(context vector형태)해서 디코터로 전달해왔다면 attention 메카니즘은 각 time step(각 입력단어별)에서 나오는 hidden state의 벡터 정보를 모두 이용하는 기법을 사용한다.
따라서 디코더에서 출력을 예측할 때 그때 그때 인코더 부분의 전체 hidden state를 참고할 뿐만아니라 그 중에서 출력과 연관이 가장 크다고 판단하는 단어를 더욱 관심(attention)있게 보기 때문에 문장이 길어도 앞 부분의 정보를 유지할 수 있다.
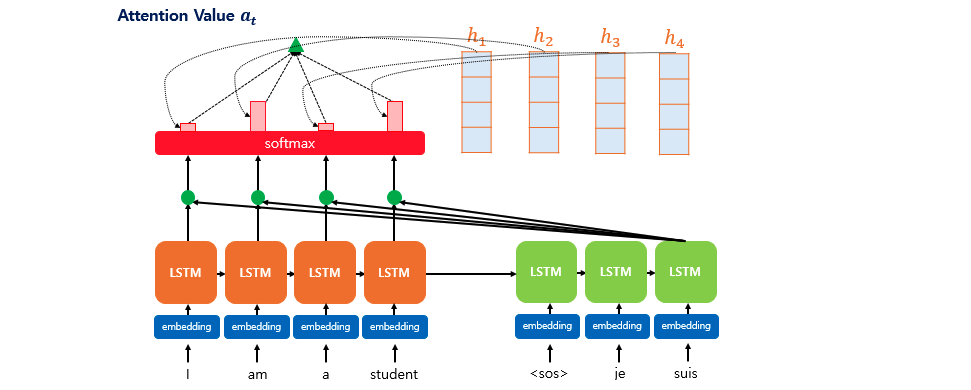
위 그림은 LSTM 기반의 attention mechanism를 나타내는 그림으로 디코더는 세번째 단어를 출력하기위해 인코더의 모든 정보를 참고하는 것을 확인할 수 있다. 또한 인코더의 각 입력단어는 임베딩과 LSTM셀 그리고 softmax함수 통과하면서 최종적으로 확률값을 출력하며 이 결과를 디코더로 전송하여 더 주목해야할 단어(확률이 가장 높은)를 알려줌으로써 보다 정확한 예측을 가능케했다.
잠깐 이 논문이 제시하는 Transformer에 대한 이야기를 하자면, 위에서 설명한 것처럼 기존 RNN 모델은 여러 한계가 있었고 attention mechanism을 통해서 이를 개선할 수 있었다. 하지만 이 논문에서는 한걸음 더 나아가 RNN 모델을 아예 사용하지않고 attention mechanism 과 인코더-디코더의 컨셉만을 가지고 모델을 만들자는 아이디어를 제시하였고 이를 Transformer 모델이라고 한다.
즉 여기서 말하는 RNN을 사용하지않고 attention mechanism만을 이용한 방법이 이 논문에서 제시하는 Transformer 모델의 핵심이라고 할 수 있겠다.
Scaled Dot-Product Attention
Attention Mechanism의 종류는 다양하게 있지만 그 기본적인 컨셉은 거의 동일하며 논문에서는 Scaled Dot-Product Attention을 사용하였으므로 이에 대해서만 설명을 하도록 하겠다.
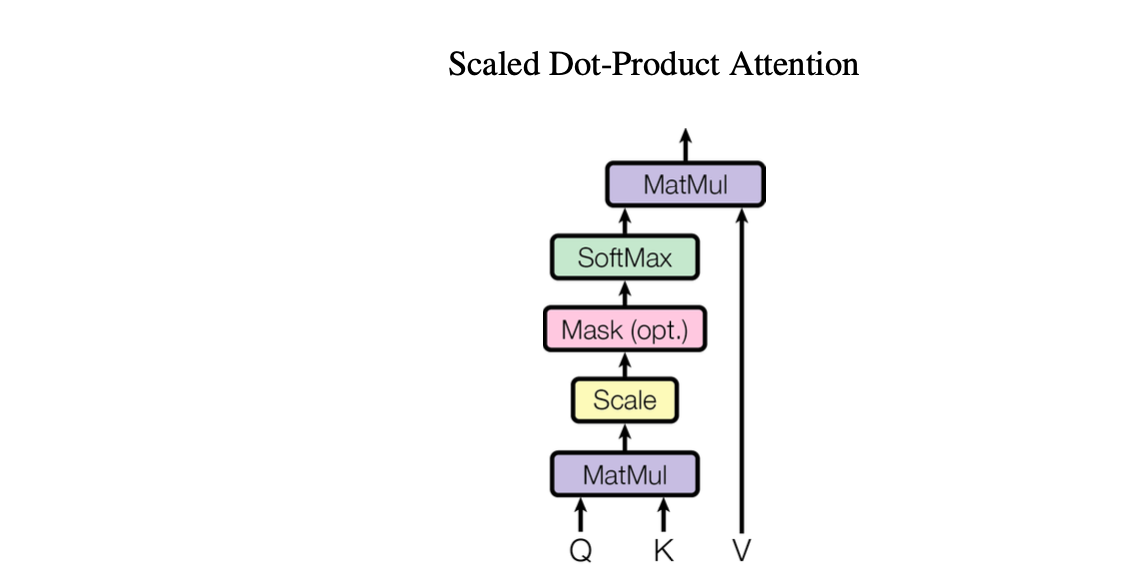 위 그림이 Scaled Dot-Product Attention 과정을 나타내며 입력은 dk차원의 Q(query), K(key) 벡터와 dv차원의 V(value)로 주어진다.
위 그림이 Scaled Dot-Product Attention 과정을 나타내며 입력은 dk차원의 Q(query), K(key) 벡터와 dv차원의 V(value)로 주어진다.
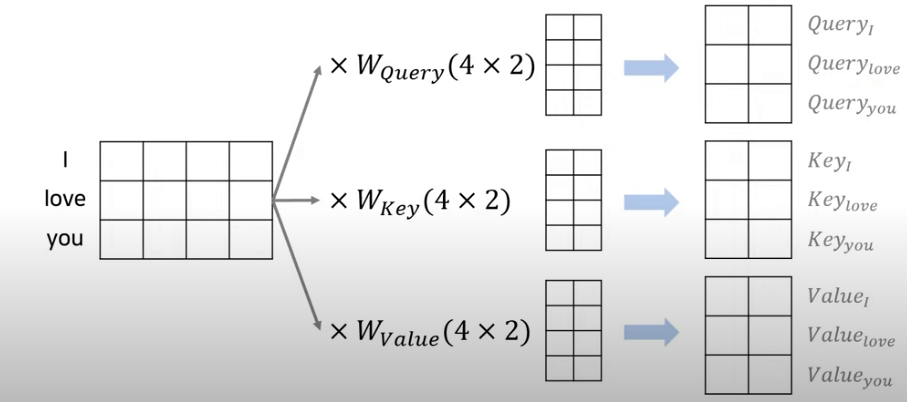
< Q(query), K(key), V(value) >
전체 입력 단어는 아래와 같이 행렬로 표현되며 가중치 곱을 통해 벡터Q, K, V를 생성한다. 아래 예시는 dmodel=4, h=2, dk=2, dv=2 인 경우이다.참고로 논문에서는 값이 dmodel=512, h=8, dk과 dv= 64로 주어졌다.
Scaled Dot-Product Attention 목적은 특정 단어(Q)가 문장내 다른 단어들 K와 그 K에 대응하는 V를 통해 어떠한 연관성과 가중치를 가지는지 알기위함으로 연산의 순서는 아래와 같다.
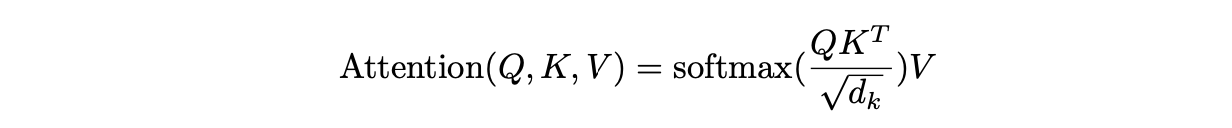 1. Q와 K에 대해 선형연산인 내적을 진행한다.
1. Q와 K에 대해 선형연산인 내적을 진행한다.
2. gradient vanishing 문제를 예방하기위해 dk의 루트 값으로 scaling을 해준다. 나중에 통과하게될 softmax함수의 특성 중 큰 값에서 기울기가 작아지는 문제가 발생하기 때문이다.
3. 필요시(optional) 마스크를 적용한다.(mask에 대해서는 뒤에서 설명)
4. softmax함수를 거친 후 V와의 내적을 통해 가중치(attention value)를 구한다.
Multi-head attention
dmodel 차원의 Q, K, V들에 단일 attention을 취하는 대신 각각 dk, dk, dv 차원으로 projection 된 값에 h번 attention을 취할 때 더 성능이 좋다고한다.
따라서 위에서 설명한 Scaled Dot Product Attention을 head의 개수인 h번 만큼 parallel로 진행한 후 각 dv차원의 출력을 concatenate(하나로 합치는 작업)한 결과를 선형연산하여 최종적으로 출력으로 attention value를 구하는데 이를 Multi-head Attention이라고한다.
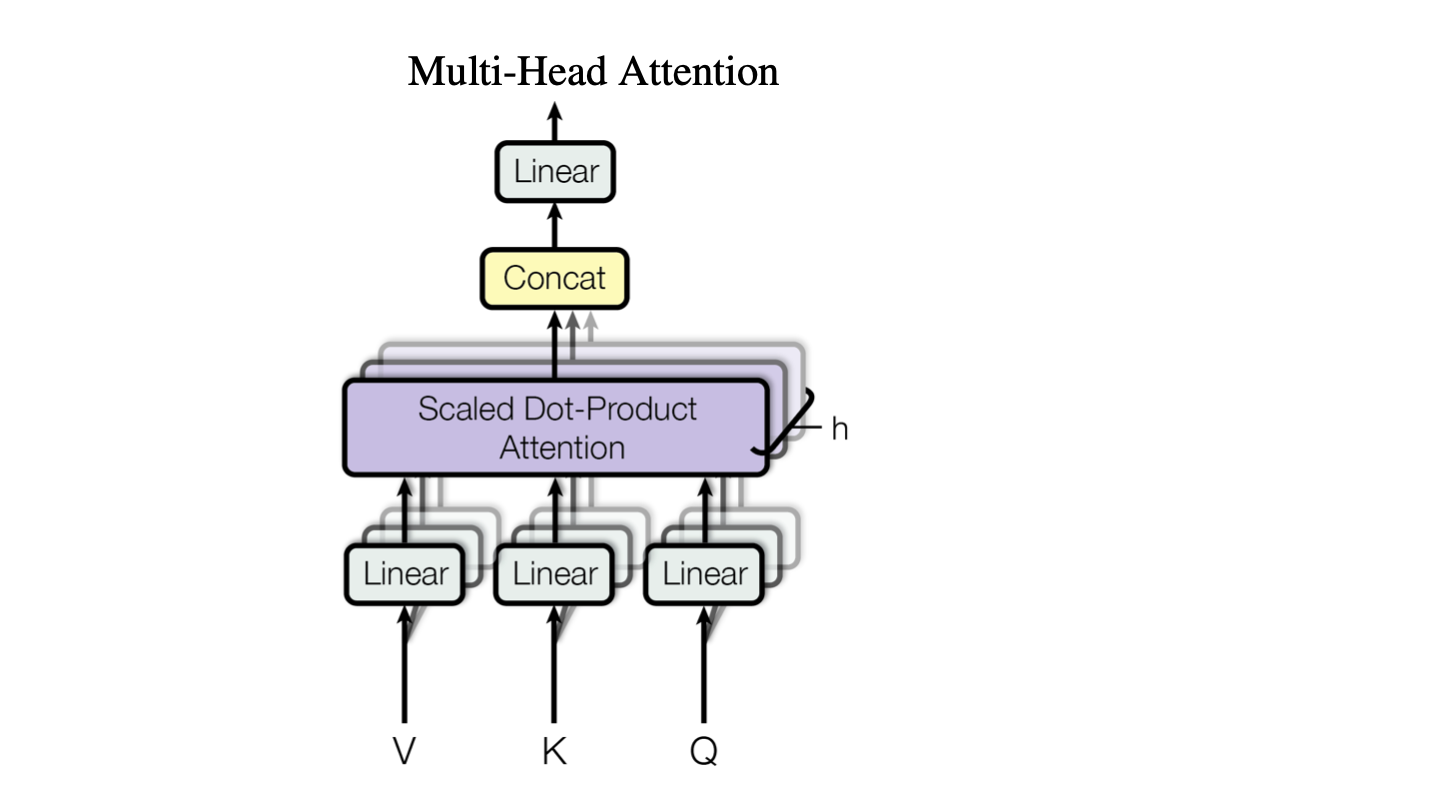

이렇게 진행한 연산은 multi라는 용어 때문에 효율이 낮을 것 같지만 projedtion을 통해 차원을 감소시킨 후(dmodel -> dk) 병렬연산을 진행하므로 단일 attention과 계산 효율 측면에서도 거의 차이가 없다고한다.
Transformer Model Architecture
Transformer 모델의 전체적인 구조는 아래와 같은 Encoder-Decoder 컨셉을 가지며 Encoder layer를 N번 반복한 후 마지막 layer의 출력을 Decoder로 전달하며 마찬가지로 Decoder layer역시 N번 반복한 후 출력을 내보내 최종 예측 확률을 얻는다.
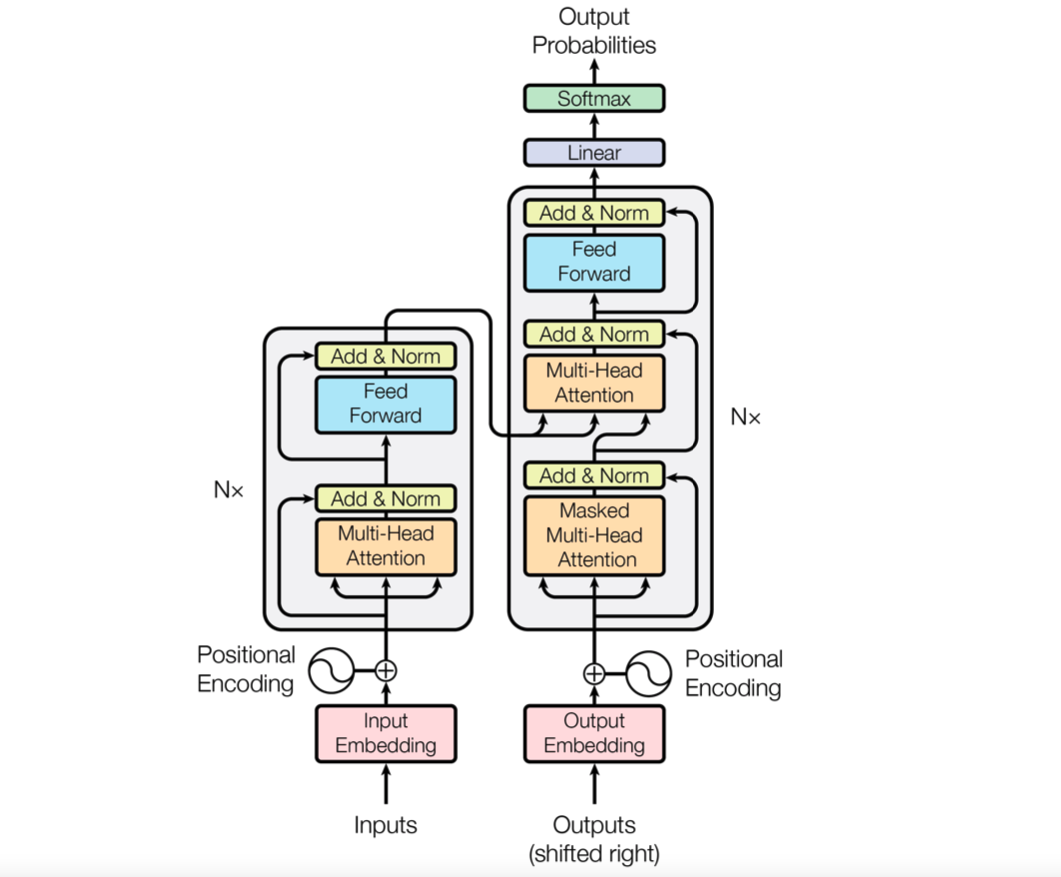
Encoder
먼저 인코더는 동일한 N개(논문에서는 6개)의 layer를 반복하며 각 layer는 Multi-Head Attention과 Feed Foward sub-layer로 이루어져있다. 주의할 점은 ecoder N개는 동일한 구조를가지지만 파라미터를 서로 공유하지 않는다는 점이며 이 것은 decoder 역시 마찬가지이다. 그리고 각 sub-layer는 학습해야할 정보를 줄이고 gradient-vanishing 문제에 효과적인 residual-connection(skip-connection)과 정규화(normalization) 작업을 거친다.
1. Embedding and Positional Encoding
input과 output의 단어들(tokens)은 embedding을 통해 dmodel 차원의 벡터로 convert된 후 위치 정보를 더해주는 Positional Encoding과정을 거친다. 이는 Transformer 모델은 recurrence와 convolution을 사용하지 않기 때문에 별도의 위치 정보를 더해 입력을 받기 위함이다.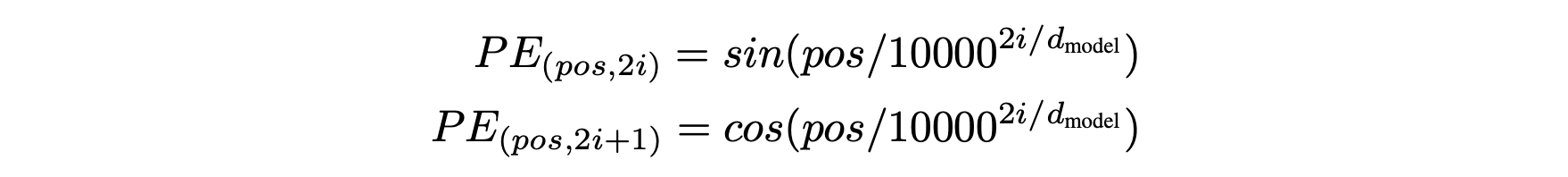
논문에서는 positional encoding방법으로 sin & cos 함수를 사용하였으며 인자인 pos는 위치, i는 dimension을 의미한다.
2. Self-Attention
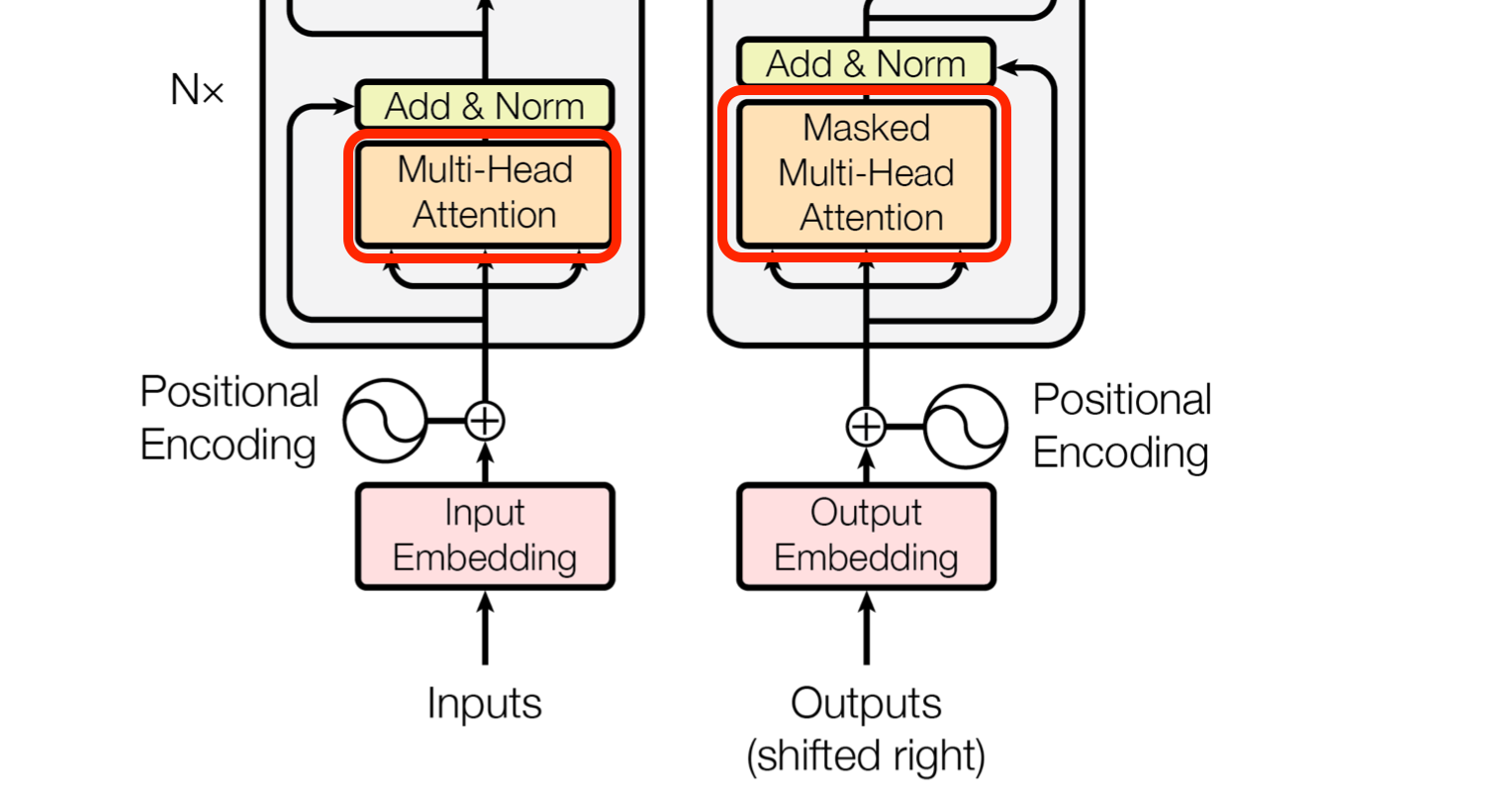
Encoder와 Decoder의 그림을 보면 처음에 동일한 값 3개(Q, K, V)가 입력되는 Multi-Head Attention 과정이있는데 이를 Self-Attention이라고 한다.
위에서 설명한 것처럼 attention mechanism은 특정 Q에 대해 K와의 유사도를 가중치로 나타낸 후 이를 K와 맵핑된 V에 반영해 주는 과정인데 Self-Attention은 이 과정을 자기 자신에게 수행함으로써 입력되는 문장내의 단어의 유사도를 구하는 방법이다.
다만 차이점은 기존의 multi-head attention에서는 K와 V의 값이 인코더를 통과한 최종 결과이고 Q가 디코더의 이전 layer의 출력으로 부터 온 것이라면 self-attention에서는 Q, K, V 모두 이전 단계인 임베딩값에 positional encoding을 더한 결과로부터 얻은 벡터라는 점이다.
논문에서는 self-attention을 적용함으로써 아래와 같은 장점을 얻는다고 이야기한다.
- layer당 전체 연산의 복잡도가 작아진다 : 일반적으로 n(sequential length)이 d(dimension) 보다 작기 때문에
- 병렬연산이 가능하며 sequential한 연산은 최소로 요구된다
- Long range dependency 학습에 유리하다

3. Position-wise Feed-Forward Networks
Encoder와 Decoder는 fully connected feed-forward network(FNN)를 가진다. FNN은 두번의 선형변환(linear transformation)과 활성화 함수 ReLu를 거치며 아래와 같은 수식으로 표현된다.
이러한 선형변환은 각 position 마다 동일하게 적용되지만 layer별로는 다른 parameter를 사용한다.
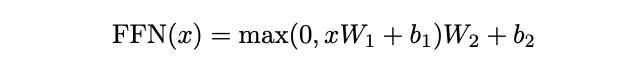
Decoder
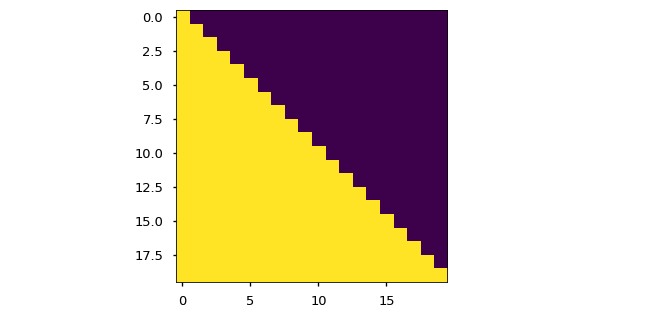
1. Masked Multi-Head Attention
Decoder의 self-attention은 encoder와 달리 masking 과정이 포함된다. 이는 아직 예측하지 않은 단어들에 대해서는 attention을 하지 않기위함이며 mask 행렬의 원소에 음의 무한대값을 취해 추후 softmax함수를 거치면 해당 부분의 확률 가중치가 0이 되게끔 동작한다.
아래 그림을 참고하면 대각선 윗부분(보라색)이 현재 시점보다 이후 시점들의 단어를 masking함으로써 attention 하지 않게끔 만들어주는 부분이다. 이러한 작업은 마치 dropout과 비슷하지만 dropout은 무작위로 네트워크를 제거하는데 반해 mask는 특정 부분의 연결을 삭제하므로 보다 결정론적(deterministic) 이라고 할 수 있겠다.
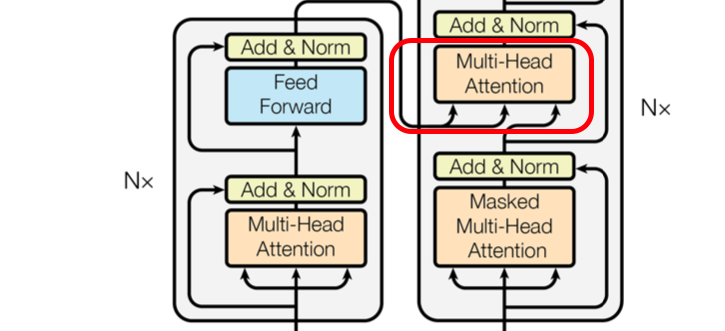
2. Multi-Head Attention
Multi-head라는 말에서 알 수 있듯이 attention 과정을 여러번 attention matrix에 적용하여 모델의 성능을 향상시키기위한 과정이다. 마치 CNN 모델에서 여러개의 필터를 사용해 특징을 다양하게 뽑아 모델 성능을 향상시키는 것과 비슷한 맥락으로 생각하면 될 것이다.
또한 Encoder에서(self-attention으로 모든 입력이 동일한 벡터로부터 생성)와는 달리 Decoder의 multi-head attention에서는 query는 decoder의 이전 layer에서 들어오며 key와 value는 encoder의 최종 출력으로부터 들어온다.
이러한 과정은 decoder가 출력을 내보낼 때마다 encoder 부분을 참고함으로써 입력 문장의 어느 곳에 더 비중을 둬야할지 attention하기 위함이다.
Optimizer
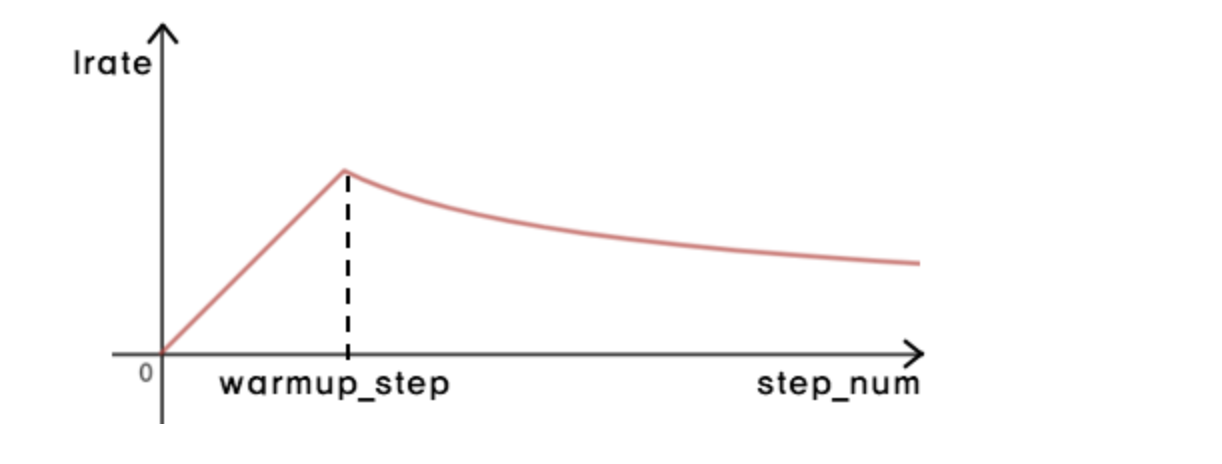
논문에서 transformer 모델에는 Adam optimizer를 사용하였다. 주목할 점은 일정한 learning rate가 아닌 아래 그림과 같이 warmp_steps = 4000을 기준으로 그 이전까지는 learning rate의 값이 선형적으로 증가하다가 이후부터는 step_num의 루트값에 비례적으로 조금씩 감소한다. 이렇게 lr를 가변적으로 설정해줌으로써 학습 속도를 유연하고 효율적으로 만들어줄 수 있다.
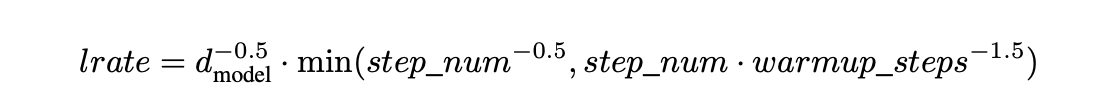
Regularization
규제화(regularization)는 모델의 overfitting을 방지하기위한 방법으로 transformer 모델에서는 아래과 같은 3가지 규제화 기법을 적용하였다.
- Dropout
- random하게 연결을 삭제해 model을 특정 데이터에 치우치지않게 보다 generalization하게 만들어준다
- Residual + Normalization
- layer를 건너뛰어 이전 입력을 전달해주는 방법, 새로운 정보만 학습하면 되므로 학습 난이도가 낮아진다
- Label Smoothing
- logistic regression모델이 있다고 가정하면 학습데이터는 label에 0 또는 1로 100%로 매핑되어져 있을 것이다. 이 때 100%로 매핑이 되었다는 것을 confidence라고하는데 실제 학습데이터에서는 label이 항상 완벽하게 매핑되어있다고 확신할 수가 없다.(사람이 분류하는 경우도 있고 인터넷에서도 틀린 경우가 종종 있다)
따라서 이러한 confidence를 보다 스무~~스하게 1이면 0.9로 0이면 0.1과 같은 식으로 매핑해주는 것을 label smoothing이라고한다. label smoothing 기법을 사용하면 0 또는 1로 매핑했을 때 가중치(w)가 점점 커지커나 작아져서 극단적으로 결과를 예측하는 것을 방지할 수 있다.
Conclusion
Attention is all you need 논문에서 처음으로 sequence 모델에 encoder-decoder 구조의 오로지 attention에만 의존하는 Transformer 모델을 처음 제시하였다.
Transformer 모델은 기존에 RNN, CNN기반의 모델보다 학습이 빠르고 성능면에서도 우수한 것이 확인되었으며 이 논문에서는 2014 English-to-German와 WMT 2014 English-to-French 기계번역을 진행함으로써 모델의 우수성을 검증하였다.
17년 이 논문이 발표된 이후로 최근까지도 많은 주요한 자연어 처리모델에 transformer 기술이 적용되었으며 덕분에 NLP 분야의 큰 진전과 가능성이 더욱 주목받게 되었다는 점에서 이 모델이 가지는 가치와 의미는 매우 크다고 할 수 있겠다.
참고
https://wikidocs.net/22893
https://pozalabs.github.io/transformer/
https://3months.tistory.com/465
https://www.youtube.com/watch?v=AA621UofTUA
