1) 앙상블은 여러 개의 모델을 결합하여 훨씬 강력한 모델을 생성하는 기법이다.
2) 앙상블은 1. 보팅 2. 배깅 3. 부스팅 4. 스태킹 방법이 있다.
3) 보팅(voting)
하나의 데이터셋에 여러개의 알고리즘을 사용하는 기법이다.
하드 보팅은 다수의 모델이 예측한 값을 최종 결과값으로 사용한다.
소프트 보팅은 각 모델이 확률 평균을 구한 뒤, 가장 확률이 높은 값을 결과값으로 사용한다.
4) 스태킹(stacking)
하나의 데이터셋에 3개 이상의 알고리즘을 사용하여 예측 값을 만든다. 그리고 최종 모델의 학습 데이터로 사용한다.
ex) KNN,Logistic, XGBoost, 모델을 사용해 3종류 예측 값을 구하고, RandomForest 학습 데이터로 사용하여, 최종 예측값을 구한다.
5) 배깅(bagging, bootstrap aggregating)
데이터 분할 시 중복을 허용하는 복원 랜덤 샘플링 방식을 사용하며, 여러개의 샘플링 데이터셋에 하나의 알고리즘을 사용하는 기법이다.
여러개의 Decision Tree 모델들이 학습을 수행한 뒤, 모든 결과를 집계하여 최종 결과값으로 사용한다.
배깅에서의 random은 1) 데이터를 랜덤하게 샘플링 2) 개별 모델이 트리를 구성할 때 분할 기준이 되는 feature를 랜덤하게 선정. 총 2개의 의미를 지닌다.
6) 부스팅(boosting)
이전 모델이 제대로 예측하지 못한 데이터에 대해서 가중치를 부여하여, 다음 모델이 학습과 예측을 진행하는 방법이다.
실제값이 20일 때, 모델1이 15를 예측하면, 모델 2는 오차값 5를 데이터셋으로 사용하여 예측값을 내놓고, 모델3은 모델 2의 오차값을 데이터셋으로 사용하는 과정이 오차가 없을 때까지 반복하며, 예측값의 총합을 통해 최종 예측값을 산출한다.
배깅에 비해 성능이 좋지만, 속도가 느리고 과적합 발생 가능성 있다.
7) 5단계에서
XGBoost, LightGBM, RandomForest 알고리즘을 추가적으로 학습했다.
sklearn. 을 사용하지 않는 XGB,LGB는 다른 알고리즘과 다르게 target의 데이터 유형이 object이면 안된다.
기존에 배웠던 DecisionTree와 마찬가지로, 1. max_depth / 2. Random_state를 매개변수로 사용한다.
# - model.feature_importance_ 를 확인해준다.
종합실습(총 집합)
1. 환경준비
# 라이브러리 불러오기 import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import warings warings.filterarings(action='ignore') %config InlineBackend.figure_format='retina' # 데이터 준비
2. 데이터 이해
# 데이터 살펴보기 data.head(3) -> target 컬럼 확인 data.tail(3) data.info() -> 가변수화 대상 파악 // 제거 대상 확인 data.describe() data.isna().sum() -> 결측치가 많으면 칼럼을 삭제하고, 별로 없으면 채우기
3. 데이터 준비
# 변수 제거 colum_drop = 'id' data.drop(colum_drop, axis = 1, inplace = True) # 데이터 분리 target = 'CHURN' x = data.drop(target, axis = 1) y = data.loc[:. target] # 분리 데이터 가변수화 colum_dummi = ['REPORTED_SATISFACTION', 'REPORTED_USAGE_LEVEL', 'CONSIDERING_CHANGE_OF_PLAN'] x = pd.get_dummies(x, columns = colum_dummi, drop_first = True) # 분리 데이터 (학습용, 테스트용) 재분리 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 1) # 정규화 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() x_train_s = scaler.fit_transform(x_train) x_test_s = scaler.transform(x_test)
4. 성능 예측
# 불러오기 from sklearn.neighbor import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegressor from sklearn.ensamble import RandomForest from xgboost import XGBClassifier from lightgbm import LGBMClassifier from sklearn.metrics import confusion_matrix, classification_report from sklearn.model_selection import cross_var_score, GridSearchCV ----------------------------------------------------------------- # 1) KNN model = KNeighborsClassifier(n_neighbor = 5) cv_score = cross_var_score(model, x_train_s, y_train, cv=5) result = {} result['KNN'] = cv.score.mean() print(cv_score) print(cv_score.mean()) ----------------------------------------------------------------- # 2) DecisionTreeClassifier model = DecisionTreeClassifier(max_depth=5, random_state=1) cv_score = cross_var_score(model, x_train, y_train, cv=5) result['tree'] = cv_score.mean() print(cv_score) print(cv_score.mean()) ----------------------------------------------------------------- # 3) LogisticsRegressor 동일 ----------------------------------------------------------------- # 4) RandomForest model = RandomForest(max_depth=5, random_state=1) cv_score = cross_var_score(model, x_train, y_train, cv=5) result['RandomForest'] = cv_score.mean() print(cv_score) print(cv_score.mean()) ----------------------------------------------------------------- # 5) xgboost model = XGBClassifier(max_depth=5, random_state=1) cv_score = cross_var_score(model, x_train, y_train, cv=5) result['RandomForest'] = cv_score.mean() print(cv_score) print(cv_score.mean()) ----------------------------------------------------------------- # 6) lightgbm 동일 -----------------------------------------------------------------
5. 결과 확인
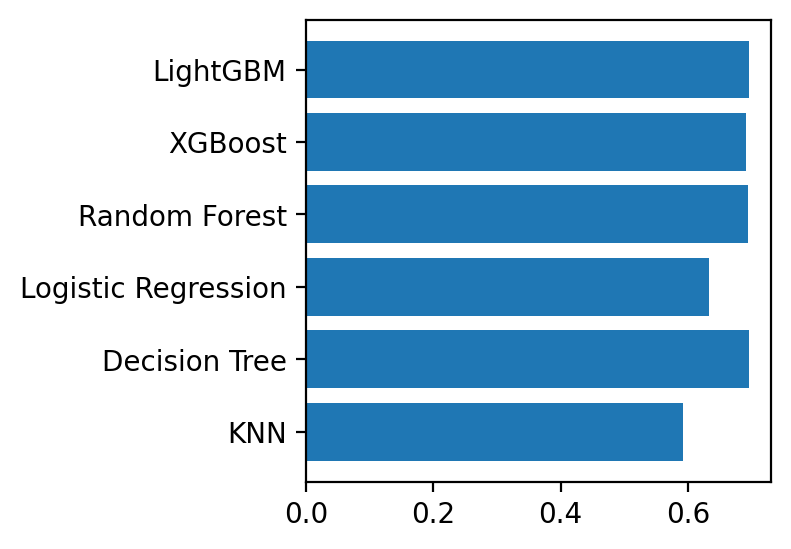
# 성능 비교 print('=' * 40) for m_name, score in result.items(): print(m_name, score.round(3)) print('=' * 40) <출력> ======================================== KNN 0.593 Decision Tree 0.696 Logistic Regression 0.633 Random Forest 0.695 XGBoost 0.692 LightGBM 0.696 ======================================== # 성능 비교 시각화 plt.barh(list(result), result.values()) <출력>
- 그래프를 확인했을 때, LightGBM이 가장 성능이 좋을 것이라고 판단할 수 있다.
6. 성능 튜닝
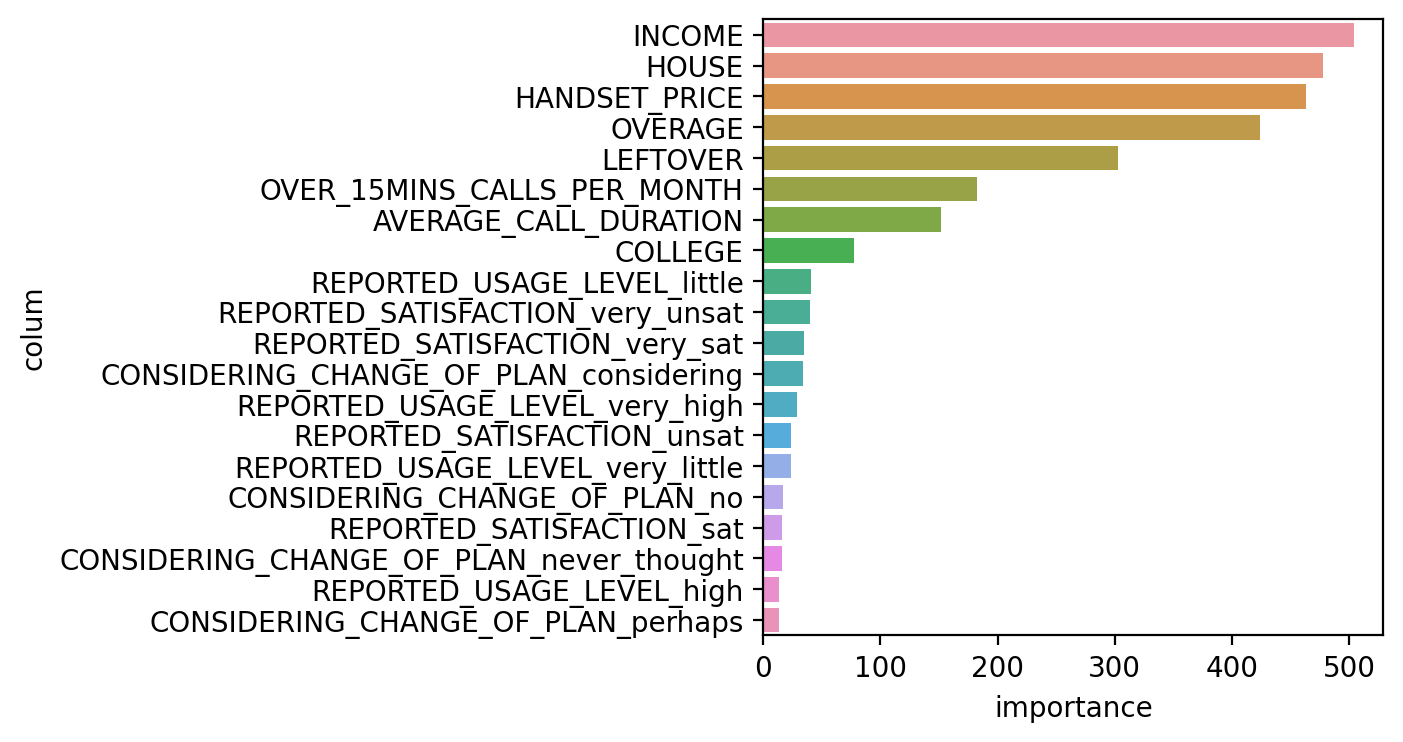
# 모델 선언 model_dt = LGBMClassifier(ramdom_state = 1) param = {'max_depth' : range(1, 51)} model = GridSearchCV(model_dt, param, cv=5) # 모델 학습 model.fit(x_train, y_train) # 최적 파라미터, 최고 성능 예측 prnt(model.cv_results_['mean_test_score']) print(model.best_params_) print(model.best_score_) print(model.best_estimator_.feature_importance_) print(list(x)) <출력> ================================================================================ [0.67542857 0.69185714 0.69821429 0.69692857 0.69878571 0.69828571 0.697 0.6945 0.69464286 0.69671429 0.69342857 0.6965 0.69792857 0.69692857 0.69585714 0.69771429 0.69685714 0.69778571 0.69835714 0.69714286] -------------------------------------------------------------------------------- 최적파라미터: {'max_depth': 5} -------------------------------------------------------------------------------- 최고성능: 0.6987857142857143 =============================================================================== [ 77 504 424 303 478 463 182 152 16 24 35 40 13 41 29 24 34 16 17 13] -------------------------------------------------------------------------------- ['COLLEGE', 'INCOME', 'OVERAGE', 'LEFTOVER', 'HOUSE', 'HANDSET_PRICE', 'OVER_15MINS_CALLS_PER_MONTH', 'AVERAGE_CALL_DURATION', 'REPORTED_SATISFACTION_sat', 'REPORTED_SATISFACTION_unsat', 'REPORTED_SATISFACTION_very_sat', 'REPORTED_SATISFACTION_very_unsat', 'REPORTED_USAGE_LEVEL_high', 'REPORTED_USAGE_LEVEL_little', 'REPORTED_USAGE_LEVEL_very_high', 'REPORTED_USAGE_LEVEL_very_little', 'CONSIDERING_CHANGE_OF_PLAN_considering', 'CONSIDERING_CHANGE_OF_PLAN_never_thought', 'CONSIDERING_CHANGE_OF_PLAN_no', 'CONSIDERING_CHANGE_OF_PLAN_perhaps'] -------------------------------------------------------------------------------- ### 변수 중요도 시각화 df = pd.DataFrame() df['colum'] = list(x) df['importance'] = model.best_estimator_.feature_importances_ df = df.sort_values(by='importance', ascending = False) sns.barplot(x = 'importance', y = 'colum', data = df) <출력>
7. 성능 평가
y_pred = model.predict(x_test) print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred)) <출력> [[1943 1122] [ 748 2187]] precision recall f1-score support 0 0.72 0.63 0.68 3065 1 0.66 0.75 0.70 2935 accuracy 0.69 6000 macro avg 0.69 0.69 0.69 6000 weighted avg 0.69 0.69 0.69 6000
