1. k분할교차검증 개념
- 1) 이전 단계까지는 데이터를 1) x와 y로 분리하고 2) 훈련용(70%), 테스트용(30%)로 분할했다.
- 2) 테스트를 하기 전에, 사전 테스트를 함으로써, 더 나은 알고리즘을 체택하고, 정확도를 향상시키기 위해 k분할교차검증을 돌려준다.
- 3) 훈련용 데이터를 cv = 10이면 10등분해서 한 블록을 검증용으로 사용하며, 총 10번의 검증 테스트를 진행한다.
- 4) 검증 테스트를 할 때는, 정확성을 위해서 데이터가 섞이면 안된다.
- 5) k분할은 x_train과 y_train만 해당된다.
- 6) k분할은 데이터 분리 과정(+정규화 과정)을 진행한 후, 수행되며, 그 다음에 모델링 단계를 진행한다.
- 7) 회귀 유형에서 cv_score의 값은 R2이다.
- 8) 분류 유형에서 cv_score의 값은 accuracy_score이다.
ex)
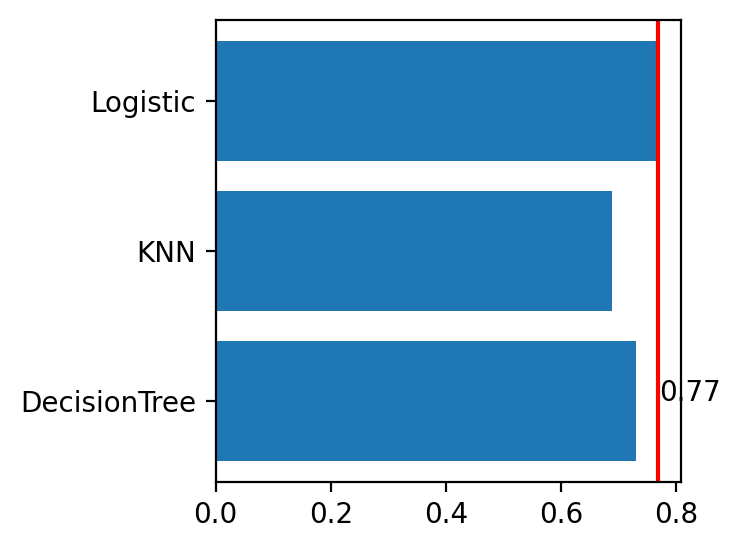
# x, y 데이터 분리 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1) ______________________________________________ # 정규화 (KNN에 사용하려고, x_train_s 분류 해줌) from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(x_train) x_train_s = scaler.transform(x_train) x_test_s = scaler.transform(x_test) _____________________________________________________________________ _____________________________________________________________________ # 성능 예측(k분할교차검증) 1) Decision Tree # 불러오기 from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import cross_val_score #선언하기 model = DecisionTreeClassifier(max_depth=5, random_state=1) # 검증하기 cv_score = cross_val_score(model, x_train, y_train, cv=10) # 확인 print(cv_score) print('평균:', cv_score.mean()) print('표준편차:', cv_score.std()) <출력> [0.66666667 0.75925926 0.74074074 0.64814815 0.7037037 0.74074074 0.75925926 0.81132075 0.79245283 0.67924528] 평균: 0.7301537386443047 표준편차: 0.05141448587329709 # 기록 result = {} result['DecisionTree'] = cv_score.mean() _____________________________________________________________________ 2) KNN # 불러오기 from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import cross_val_score # 선언하기 model = KNeighborsClassifier(n_neighbors=5) # 검증하기 cv_score = cross_val_score(model, x_train_s, y_train, cv = 10) # 분류에서 cv_score의 값은 accuracy이다. # 확인 print(cv_score) print('평균:', cv_score.mean()) print('표준편차:', cv_score.std()) result['KNN'] = cv_score.mean() _____________________________________________________________________ 3) Logistic Regression # 불러오기 from sklearn.linear_model import LogisticRegression from sklearn.model_selection import cross_val_score # 선언하기 model = LogisticRegression() # 검증하기 cv_score = cross_val_score(model, x_train, y_train, cv = 10) # 확인 print(cv_score) print('평균:', cv_score.mean()) print('표준편차:', cv_score.std()) result['Logistic'] = cv_score.mean() _____________________________________________________________________ 4) 성능 비교 시각화 print(result) <출력> {'DecisionTree': 0.7301537386443047, 'KNN': 0.6889587700908455, 'Logistic': 0.7690426275331936} plt.barh(list(result), result.values()) plt.axvline(result['Logistic'], color = 'r')
- 이를 통해, Logistic 알고리즘을 사용하는게 효과적임을 알 수 있다.
- 다음 과정은 LogisticRegressor를 이용하여 동일하게 성능 평가 및 시각화 단계를 수행하면 된다.

큐브가 필요하다...!!!