SpanBERT: Improving Pre-training by Representing and Predicting Spans (TACL / 2020) paper review
paper review
Contribution
-
BERT에 대하여 contiguous한 random span에 대하여 masking을 하였고, span 내의 individual token representation에 의존하는 대신에 masked span의 전체 context를 예측하기 위하여 span boundary representation을 학습하였다.
-
question answering이나 coreference resolution 같은 span prediction task에서 outperform함을 보였다.
-
OntoNotes coreference resolution task에서 state-of-the-arts를 달성하였고 TACRED와 GLUE에서도 strong performance를 보였다.
Differences with BERT
-
individual token에 대하여 masking 처리를 한 것이 아니라 span의 token에 대하여 masking 처리를 하였다.
-
span의 경계에 있는 token의 representation만 사용하여 전체 masked span을 예측하기 위하여 span boundary objective(SBO)를 도입하였다.
-
각 training example에서 text의 single contiguous segment를 사용하였고, 따라서 BERT의 next sentence prediction objective를 사용하지 않았다.
Span Masking
-
sequence of tokens X = (x1, x2, ..., xn)가 주어졌을 때, text span을 반복적으로 sampling하여 x의 subset Y를 select한다.(X의 15%가 될 때까지)
-
각 iteration에서 먼저 geometric distribution으로부터 span length를 sampling한다. 그 후, masking 처리될 span의 starting point를 random하게 선택한다.
-
언제나 complete word의 sequence만 선택을 하고, starting point는 무조건 한 단어의 시작이어야 한다.
-
BERT에서 전체 단어의 15%의 비율로 masking처리 된 단어들의 80%를 [MASK] token으로 대체를 하듯, SpanBERT에서는 각 단어 대신에 span 내의 단어들을 [MASK] token으로 대체한다. (즉 span 내에 있는 모든 단어를 [MASK]로 replace)
Span Boundary Objective(SBO)
-
Span selection model은 전형적으로 span의 boundary token(start & end)을 이용하여서 그 span의 fixed-length representation을 만든다. 이러한 model을 돕기 위하여, 이 논문에서는 span의 경계의 representation이 가능한 한 span 내부의 content를 많이 summarize하기를 바란다고 한다.
-
이를 위하여, span boundary token의 representation만 이용하여서 각 masked span을 predict하는 Span Boundary Objective(SBO)를 도입하였다.
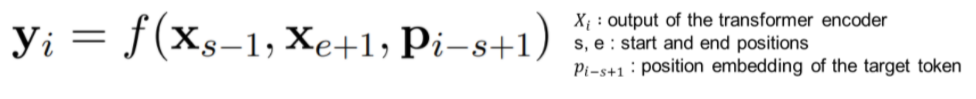
representation function f는 아래와 같이 2-layer feed-forward network with GeLU activations과 layer normalization으로 정의된다.
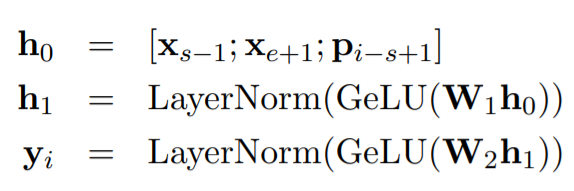
최종적으로 loss는 위와 같이 MLM loss와 SBO loss의 합으로 정의된다.
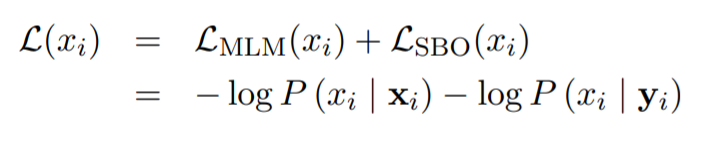
Single-Sequence Training
-
이 논문에서는 Next Sentence Prediction(NSP)를 사용하는 것이 단순히 single sequence를 사용하는 것보다 성능을 떨어뜨린다고 말하고 있다. 그리고 그렇게 추정되는 이유로 아래 두가지를 꼽았다.
- model은 longer full context text로부터 benefit을 얻을 수 있다.
- 다른 document에서 온 context를 사용하는 것이 masked language model에 noise를 줄 수 있다.
-
SpanBERT에서는 NSP objective와 two-segment sampling procedure를 없애고 단순히 하나의 contiguous segement를 사용하였다. (up to 512 tokens)
Architecture
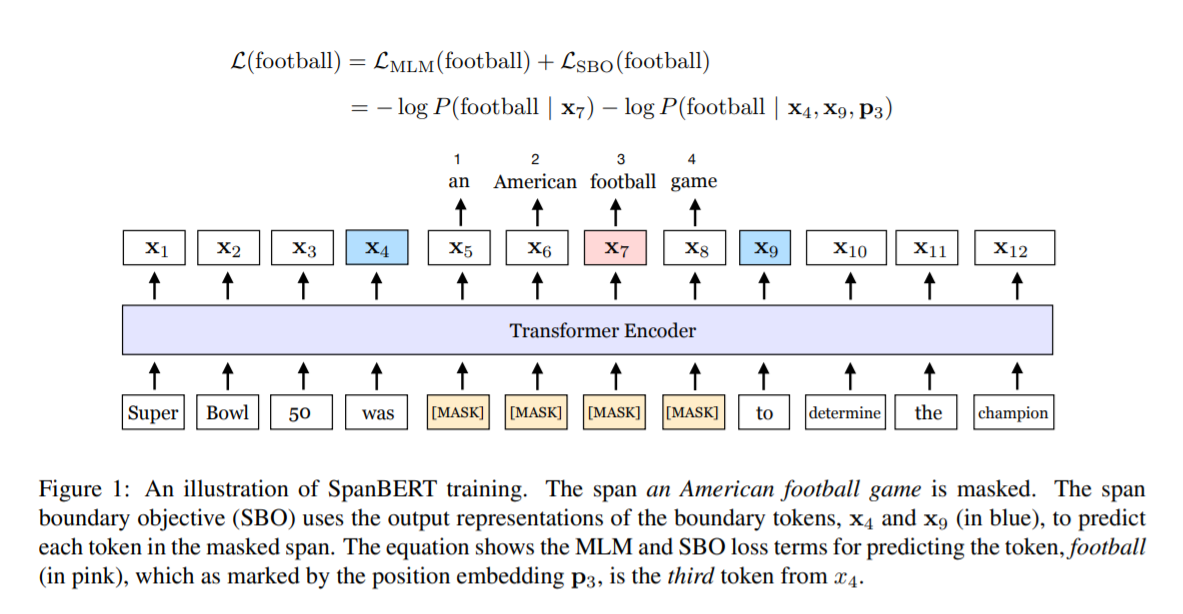
-
randomly select된 span 내의 모든 token을 masking 처리 하였다.
-
single sequence data pipeline을 이용하여 MLM objective와 더불어 보조적으로 span boundary objective를 optimizing한다.
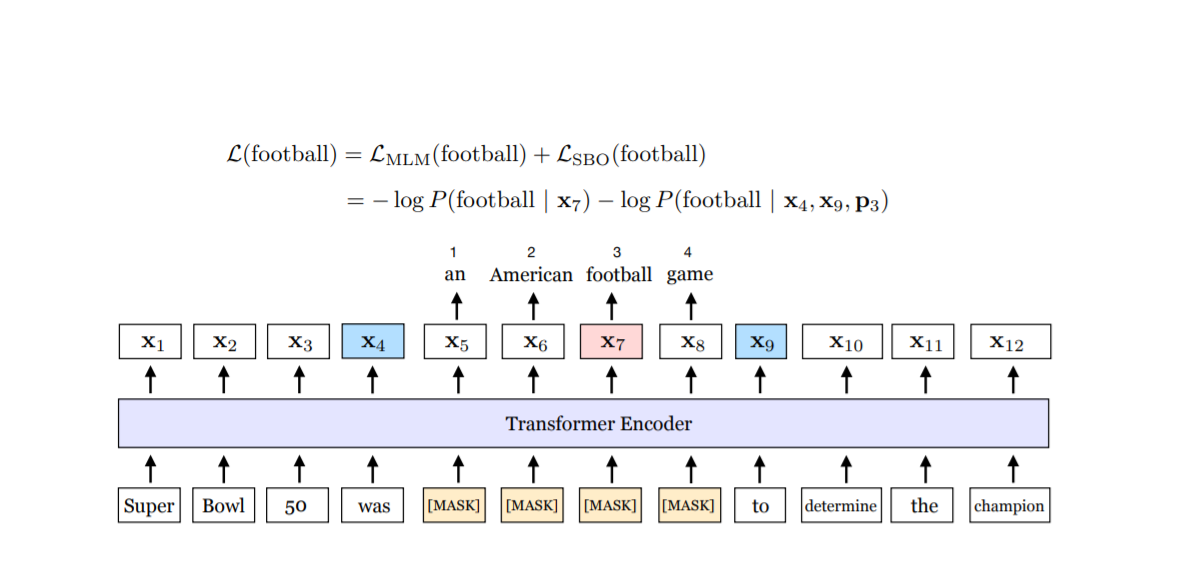
-
위의 Figure 1을 보면 span의 경계인 x4와 x9, 그리고 현재 predict하려는 token x7의 position embedding인 p3을 이용하여 SBO objective를 계산하는 것을 볼 수 있다.
p3: span의 시작인 x5으로부터의 상대적 positoin을 이용
Experiments
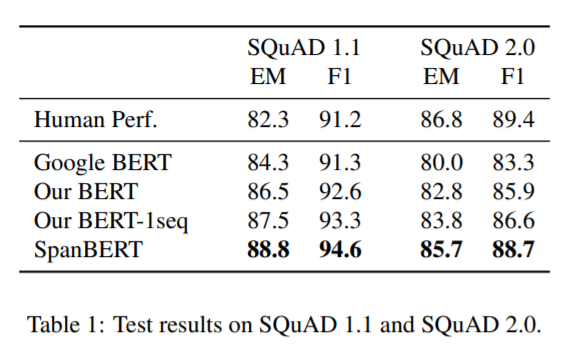
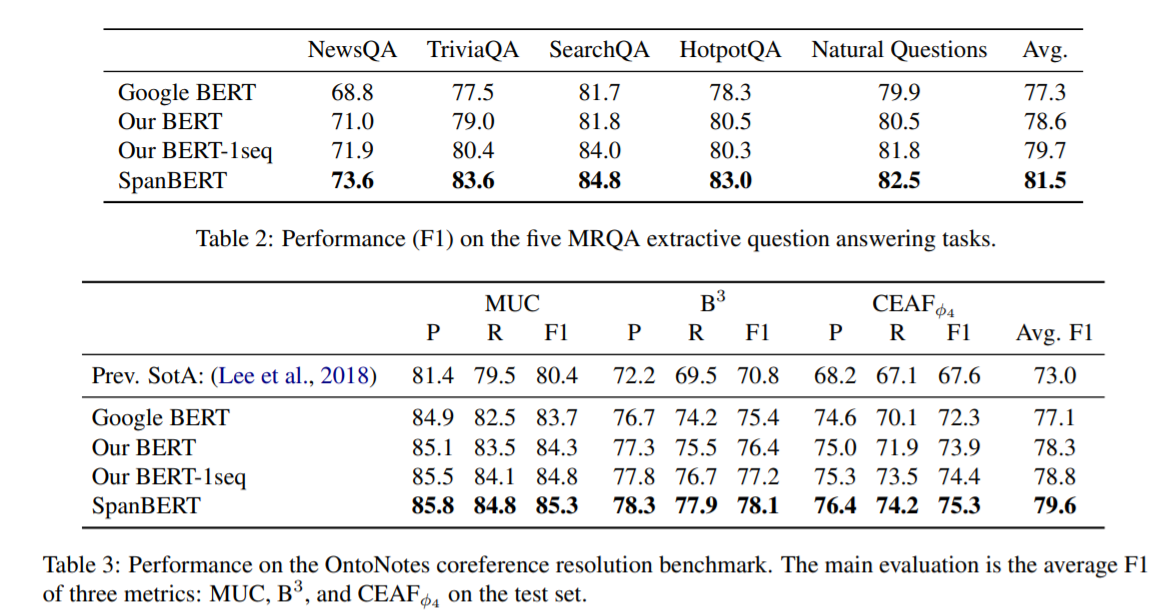
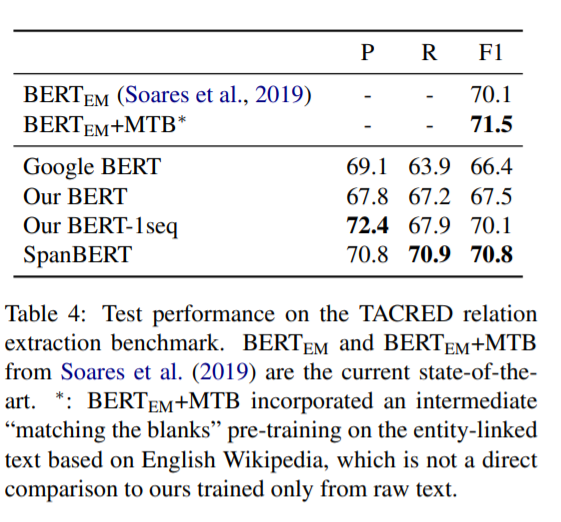
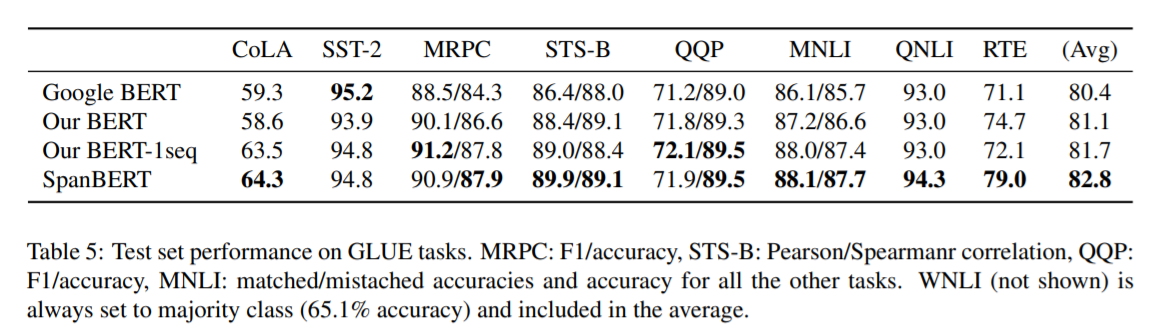
여기서 말하는 our BERT는 BERT에서 약간의 조건을 수정한 것으로 매 epoch마다 다른 mask를 사용하고, short-sequence strategy를 없앤 model이다. 대부분의 task에서 SpanBERT가 가장 좋은 성능을 내는 것을 확인할 수 있다.
Conclusion
-
contiguous random span을 masking하고 masked span의 전체 content를 예측하기 위하여 span boundary representation을 학습하는 BERT의 extension인 span-based pre-training method를 제시하였다.
-
이러한 method를 사용하여 model은 다양한 task에서 BERT의 baseline을 outperform하였고 특히 span selection task에서 상당히 좋은 performance를 보였다.
