개념 정리
- Residual: Y-X 즉, 결과의 오류 정도를 말한다.
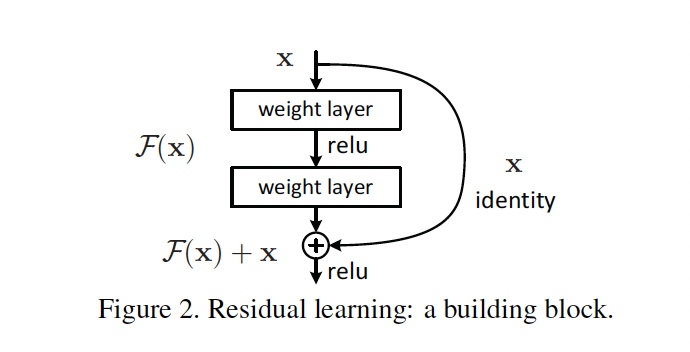
본 논문은 이미지 인식 성능을 극대화하기 위한 딥러닝 모델인 "ResNet(Residual Networks)"을 소개한다. 일반적으로 신경망의 깊이가 깊어질수록 성능이 향상될 것으로 기대되나, 실제로는 학습이 어려워지고 성능이 저하되는 문제를 겪게 된다. ResNet은 이 문제를 해결하기 위해 잔차 연결(residual connections)을 도입하여 딥러닝 네트워크의 깊이를 크게 늘리면서도 높은 성능을 유지할 수 있도록 한다. 이 모델은 ImageNet 데이터셋에서 혁신적인 성능을 보였으며, 100층 이상의 네트워크에서도 성능이 유지됨을 보여준다.
1. Introduction
신경망의 깊이를 늘리면 더 복잡한 패턴을 학습할 수 있어 성능 향상에 유리하지만, 지나치게 깊어질 경우 기울기 소실(vanishing gradient) 등의 문제로 학습이 어려워진다. 기존의 여러 연구는 이러한 문제를 해결하려 했지만, 깊이의 증가가 모델의 일반화 성능과 무조건 비례하지 않는다는 결과를 보였다. Residual Learning은 네트워크가 학습하는 함수를 직접적으로 최적화하는 대신, 입력과 출력의 차이인 ‘잔차(residual)’를 학습하게 하여 이러한 문제를 해결한다.
Deep CNN 의 발전
컴퓨터 비전 분야에서 깊은 합성곱 신경망(Deep CNN)은 이미지 분류에 있어 연속적인 혁신을 이루어냈다.
- low / mid / high level의 특징을 통합적으로 학습
- 층간 연결을 통한 전반적 학습 가능
- 네트워크 깊이가 증가할수록 더 풍부한 특징 표현 가능
주요 문제점과 해결 과정
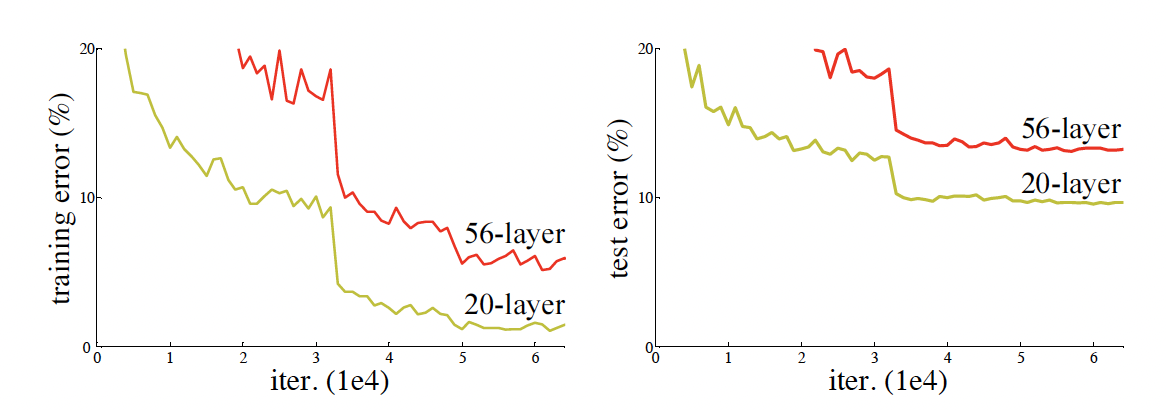
1) 기울기 소실/폭발
- 깊은 네트워크 학습의 첫 번째 장애물
- 해결책: 정규화된 초기화와 중간 정규화 층 도입
2) 성능 저하 문제
- 네트워크 깊이 증가 → 정확도 포화 및 급격한 저하
- 과적합에 의한 것이 아니며(trining error도 함께 높아짐) 더 깊은 모델이 오히려 더 높은 학습 오류 발생
- 해결책: 깊은 잔차 학습(Deep Residual Learning) 프레임워크
Residual Learning 핵심 개념
- 직접적인 함수 학습 대신 잔차 함수 학습
- H(x): 원하는 매핑
- F(x): 잔차 매핑 (H(x) - x)
- 최종 매핑: F(x) + x
장점
- 최적화가 더 용이
- 항등 매핑이 최적일 경우, 잔차를 0으로 만드는 것이 더 쉬움
- shortcut connections을 통한 간단한 구현
- 추가 매개변수나 계산 복잡도 증가 없음
- 일반적인 딥러닝 프레임워크에서 쉽게 구현 가능
2. Related Work
본 논문에서는 기존 연구에서의 신경망 깊이와 관련된 성능 문제를 소개하고, 다양한 신경망 구조들이 이 문제를 해결하려 했음을 설명한다. LeNet, AlexNet, VGGNet, GoogLeNet 등의 구조들이 깊이와 성능 간의 관계를 연구하면서, 네트워크의 깊이가 성능에 중요한 영향을 미침을 입증하였다. 그러나, 깊이를 늘릴수록 성능이 더 좋아진다는 것은 보장되지 않았고, 이를 극복하기 위해 다양한 모듈과 연결 방식을 도입하려는 시도가 이어졌다.
잔차 표현(Residual Representations)
이미지 처리 분야
- VLAD: 사전 기반 잔차 벡터 인코딩
- Fisher Vector: VLAD의 확률적 버전
- 두 방식 모두 이미지 검색과 분류에서 효과적인 얕은 표현 방식
- 벡터 양자화에서 원본보다 잔차 벡터 인코딩이 더 효과적임
- Multigrid 방법:
- 문제를 여러 스케일의 하위 문제로 분해
- 각 하위 문제는 서로 다른 스케일 간의 잔차를 해결
- 계층적 기반 선조건화: 두 스케일 간 잔차 벡터를 활용
→ 핵심 시사점: 잔차 기반 접근이 최적화를 단순화하고 성능을 향상시킬 수 있음
Shortcut Connections
초기 연구
- 다층퍼셉트론(MLP)에서 입력-출력 간 직접 연결 시도
- 기울기 소실/폭발 문제 해결을 위한 중간층-보조 분류기 연결
고속도로 네트워크(Highway Networks)
- 게이팅 기능이 있는 지름길 연결 사용
- ResNet과의 주요 차이점:
- 게이트가 파라미터를 가짐 (ResNet: 파라미터 없음)
- 게이트가 닫힐(0에 수렴) 수 있음 (ResNet: 항상 열려있음)
- 100층 이상 깊은 네트워크에서의 성능 입증 부족
3. Deep Residual Learning
3.1 잔차 학습 (Residual Learning)
-
기본 개념
- 목표 함수 H(x)를 층으로 근사하지 않고, 잔차 함수 ( F(x) = H(x) - x )를 근사하는 방식을 채택함.
- 이렇게 하면 최종 출력은 ( F(x) + x ) 형태로 표현됨.
-
학습 용이성
- 잔차 함수 F(x)를 학습하는 방식이 원래 함수 H(x)를 직접 학습하는 것보다 학습하기 쉬울 수 있음.
-
성능 저하 문제 해결
- 층을 더 쌓으면 성능이 좋아져야 하지만, 항등 매핑을 근사하는 데 어려움을 겪으면서 오히려 성능이 떨어질 수 있음.
- 잔차 학습 방식은 항등 매핑이 최적일 때 가중치를 0으로 수렴시켜 항등 매핑에 더 가까워지도록 함.
-
항등 매핑과 선조건화
- 최적의 매핑이 항등에 가까우면, 항등 매핑을 기준으로 하는 작은 변화(perturbation) 를 찾는 것이 더 쉬움.
- 실험 결과, 학습된 잔차 함수가 작게 반응함을 보여주며, 항등 매핑이 유용한 선조건화 역할을 할 수 있음을 시사.
3.2 Identity Mapping by Shortcuts
-
잔차 학습 블록
- 잔차 학습 블록 구조: 형태로, x와 y는 입력과 출력 벡터.
- 잔차 함수 F(x)는 두 층을 가지며 로 정의
-
Shortcuts과 덧셈
- F와 x를 Shortcuts과 요소별 덧셈으로 결합해 성능을 높임.
- 추가 매개변수나 계산 비용 없이 항등 매핑을 가능하게 함.
-
차원 맞추기
- 입력과 출력 차원이 다르면 선형 투영 ( W_s )를 사용해 차원을 맞춤.
- 실험 결과, 항등 매핑이 충분한 성능을 보여, 차원 조정 시에만 ( W_s ) 사용.
-
잔차 함수 F의 유연성
- 잔차 함수 F는 다양한 층 수로 구성 가능.
- 완전 연결 층뿐만 아니라 합성곱 층에도 적용 가능.
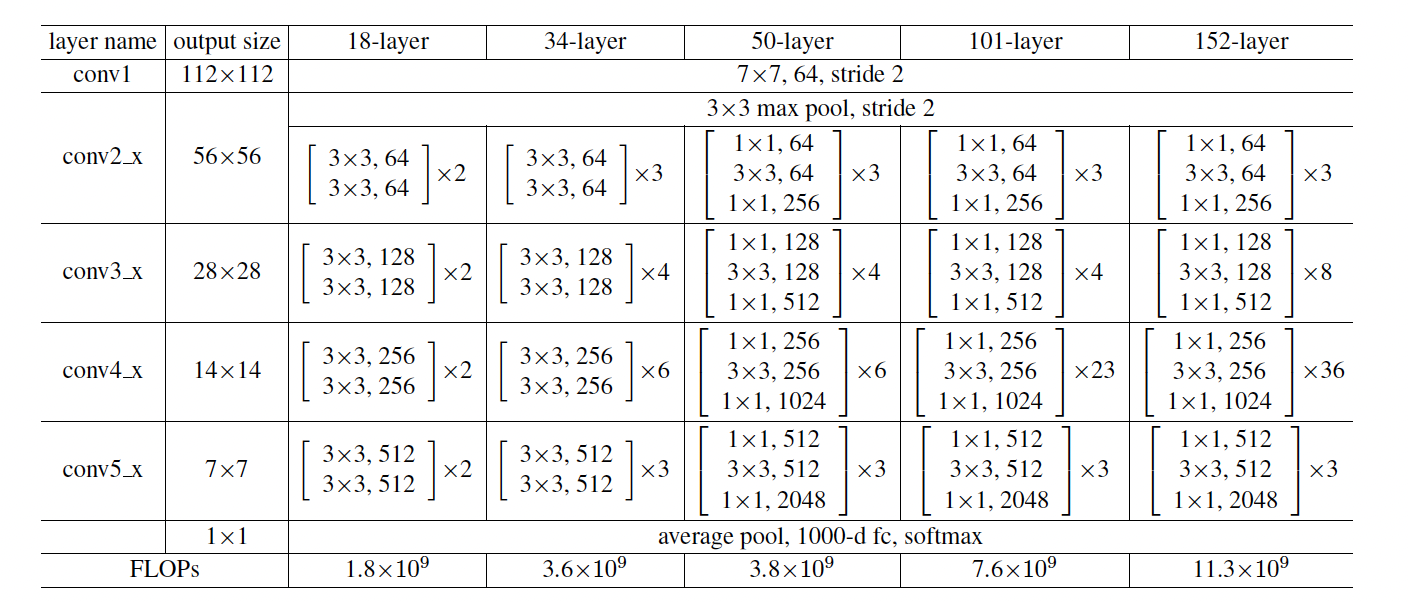
3.3 Network Architecture
ResNet의 네트워크는 여러 층의 Residual Block으로 구성된다. 특히, ResNet-34와 ResNet-50, ResNet-101 등의 모델은 층 수를 늘려 깊이를 조절할 수 있으며, 각 모델은 블록의 수와 구조에 따라 성능 차이가 발생한다. 모델은 점진적으로 블록을 쌓아 깊이를 늘리고, 깊이에 따른 성능을 평가하였다.
-
평범한 네트워크
- VGG 네트워크에서 영감을 받아 설계된 기준 모델로, 34층 구조.
- conv filter (3x3) 를 사용하며, 출력 피처 맵 크기와 필터 수 규칙을 따름.
-
복잡도
- VGG 네트워크보다 가벼운 구조로, VGG-19 대비 FLOPs가 18% 수준.
- VGG 네트워크보다 가벼운 구조로, VGG-19 대비 FLOPs가 18% 수준.
3.4 Implementation
ResNet은 일반적인 CNN 모델처럼 SGD를 기반으로 학습되며, Batch Normalization과 He Initialization을 사용하여 안정적인 학습을 도모하였다. 이러한 기법들은 깊은 네트워크에서 발생할 수 있는 학습 불안정 문제를 해결하는 데 기여하며, ResNet의 높은 성능을 뒷받침한다.
-
데이터 증강
- 이미지 크기 조정 및 색상 증강을 통해 다양한 데이터를 학습에 사용.
-
정규화 및 초기화
- 각 합성곱 후 배치 정규화 적용, 가중치 초기화 사용.
-
학습 설정
- SGD로 학습, 초기 학습률 0.1, 학습이 포화되면 10배 감소.
- 모멘텀 0.9, 가중치 감소 0.0001 설정, 드롭아웃 사용하지 않음.
-
테스트
- 10-크롭 테스트와 여러 스케일로 점수 평균화하여 성능 평가.
4. Experiments
4.1 ImageNet 분류
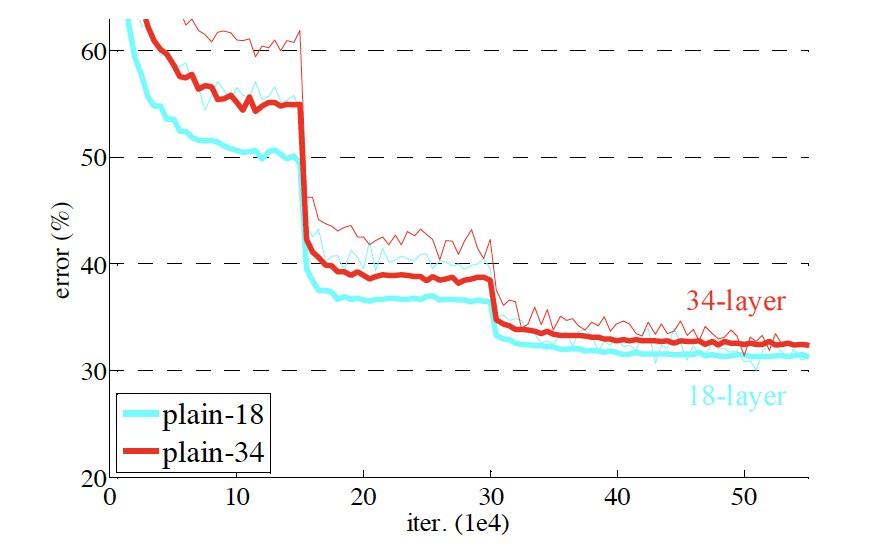
평범한 네트워크 (Plain Networks)
- 모델: 18층과 34층 네트워크 평가.
- 결과: 34층 네트워크는 18층보다 높은 학습 오류를 보임 (기울기 소실 문제 아님).
- 검증 오류: 34층 네트워크가 18층보다 높은 검증 오류를 가짐.
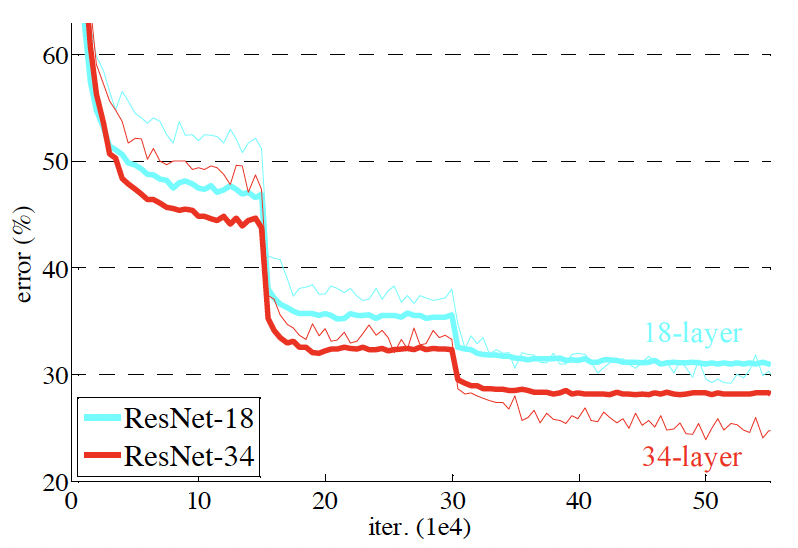
잔차 네트워크 (Residual Networks)
- 모델: 18층과 34층 잔차 네트워크(ResNets) 평가.
- 결과:
- 34층 ResNet이 18층 ResNet보다 성능이 더 우수 (2.8% 개선).
- 34층 ResNet이 34층 평범한 네트워크보다 top-1 오류율을 3.5% 감소.
- 18층 잔차 네트워크가 평범한 네트워크보다 빠르게 수렴함.
Identity vs. Projection Shortcuts
- 옵션 비교:
- 옵션 A: zero-padding shortcuts
- 옵션 B: projection shortcuts & identity
- 옵션 C: aoo projection shortcuts
- 결과: 세 옵션 모두 평범한 네트워크보다 성능이 뛰어났으며, 옵션 간 차이는 미미.
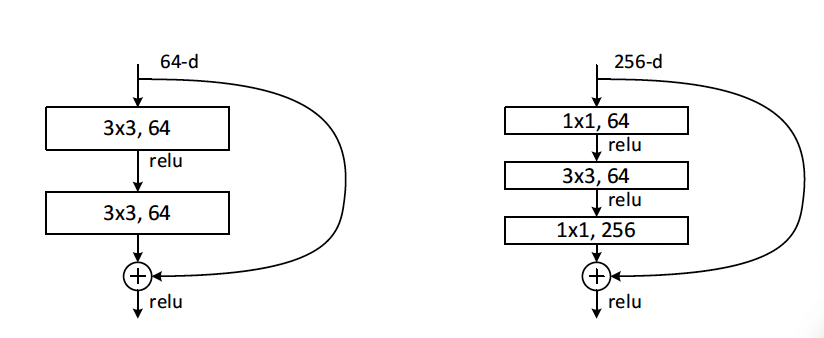
Deeper Bottleneck Architectures
1. 병목 구조: 3층 블록(1x1, 3x3, 1x1 합성곱)으로 구성된 병목 설계를 도입.
2. 구성:
- 50층 ResNet: 34층의 2층 블록을 병목 블록으로 교체.
- 101층, 152층 ResNet: 병목 블록을 더 많이 쌓아 만듦.
Reference
https://phil-baek.tistory.com/entry/ResNet-Deep-Residual-Learning-for-Image-Recognition
