이 논문은 R-CNN(Region-Based Convolutional Neural Networks)을 처음 제안하며 객체 탐지(Object Detection)와 의미론적 분할(Semantic Segmentation)의 성능을 크게 개선한 연구이다. 논문의 핵심은 고수준의 피처 계층 구조를 활용해 객체의 정확한 탐지를 가능하게 한 점이다.
Abstract
R-CNN은 selective search와 CNN을 결합하여 객체 탐지 문제를 해결하는 혁신적인 접근법을 제안하였다. 기존 방식보다 높은 성능을 달성했으며, PASCAL VOC 데이터셋에서 우수한 성능을 기록하였다. 또한, R-CNN의 특징은 다른 비전 문제에도 활용 가능하다는 가능성을 열어주었다.
1. Introduction
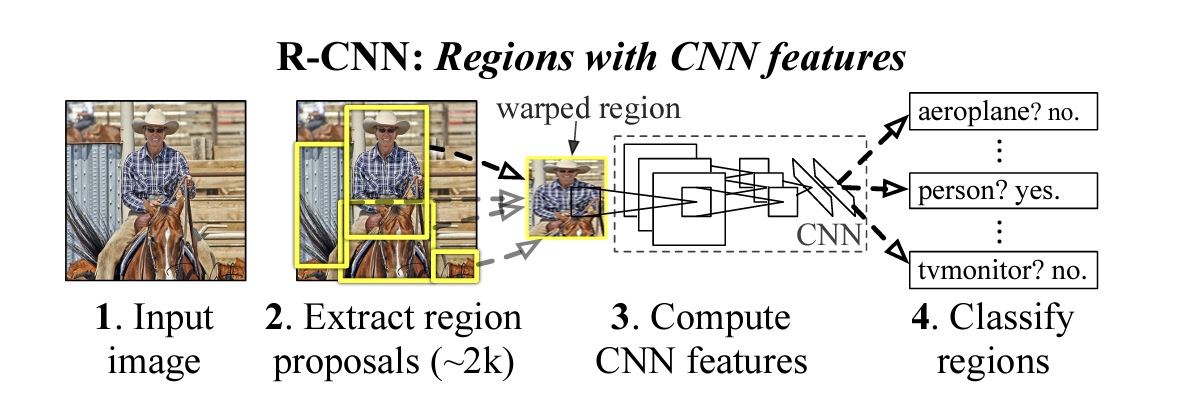
컴퓨터 비전에서 객체 탐지와 분할은 중요한 과제이다. 기존 방법론은 특징을 수작업으로 설계하거나, Haar-like 특징과 같은 제한적인 표현력을 갖는 피처를 사용하였다. 반면, CNN은 학습 가능한 고수준의 피처 표현력을 제공한다. 하지만 CNN을 객체 탐지에 직접 적용하기에는 계산 비용이 크고, 위치 정보를 효과적으로 활용하지 못했다.
R-CNN은 selective search를 통해 객체 후보영역(region proposals)을 생성하고, 각 영역에 대해 CNN을 적용하여 객체 여부를 분류하는 새로운 접근법이다.
2. Object detection with R-CNN
R-CNN은 두 가지 주요 연구 흐름을 결합하였다:
-
Region Proposals 기반 탐지
Selective search는 객체가 있을 법한 영역을 생성하는 방법으로, 계산 효율성과 탐지 성능 사이의 균형을 맞춘다. -
Deep Learning 기반 탐지
AlexNet 이후 CNN은 이미지 분류에서 강력한 성능을 보여주었지만, 이를 객체 탐지에 적용한 연구는 부족하였다.
2.1 Module Design

- Region Proposal
R-CNN은 Selective Search를 활용하여 입력 이미지에서 약 2,000개의 후보 영역을 생성한다. 이는 객체 탐지의 후보를 효과적으로 좁히는 단계이다. - Feature Extraction
각 후보 영역은 CNN을 통해 4096차원의 고수준 피처로 변환된다. 이를 위해 후보 영역을 227×227 픽셀로 왜곡(warping)하여 CNN 입력 형태에 맞춘다. - Classification
추출된 피처는 클래스별 선형 SVM을 사용해 분류된다.
2.2 Test-time Detection
테스트 시에는 다음 과정을 따른다:
1. Region Proposal: Selective Search를 빠른 모드로 실행하여 후보 영역을 생성
2. Feature Computation: 각 후보 영역을 CNN에 입력하여 피처를 추출
3. Classification and NMS: 각 클래스별 SVM을 사용해 후보를 분류하며, Non-Maximum Suppression(NMS)으로 중복된 탐지를 제거
특히 CNN 피처가 모든 클래스에서 공유되기 때문에 탐지 속도가 상대적으로 효율적이다.
2.3 Training
- Supervised Pre-training
ILSVRC2012 데이터셋에서 CNN을 사전 학습하여 기본 피처를 학습 - Domain-specific Fine-tuning
PASCAL VOC 데이터셋의 왜곡된 후보 영역에서 SGD(확률적 경사 하강법)를 통해 세부 조정을 진행
SVM은 Ground Truth와의 Intersection-over-Union(IoU) 임계값을 사용하여 양성과 음성 샘플을 구분하며, Hard Negative Mining 기법을 통해 효율적으로 학습한다.
3. Visualization, Ablation, and Modes of Error
3.1 Visualizing Learned Features
R-CNN의 각 CNN 레이어가 학습한 피처를 시각화하여 네트워크가 학습한 패턴과 변이 불변성(invariance)을 이해하였다. 특히, Pool5 레이어의 일부 유닛은 특정 객체(예: 사람, 텍스트)나 텍스처(예: 점 배열)에 반응하였다.
3.2 Ablation Studies
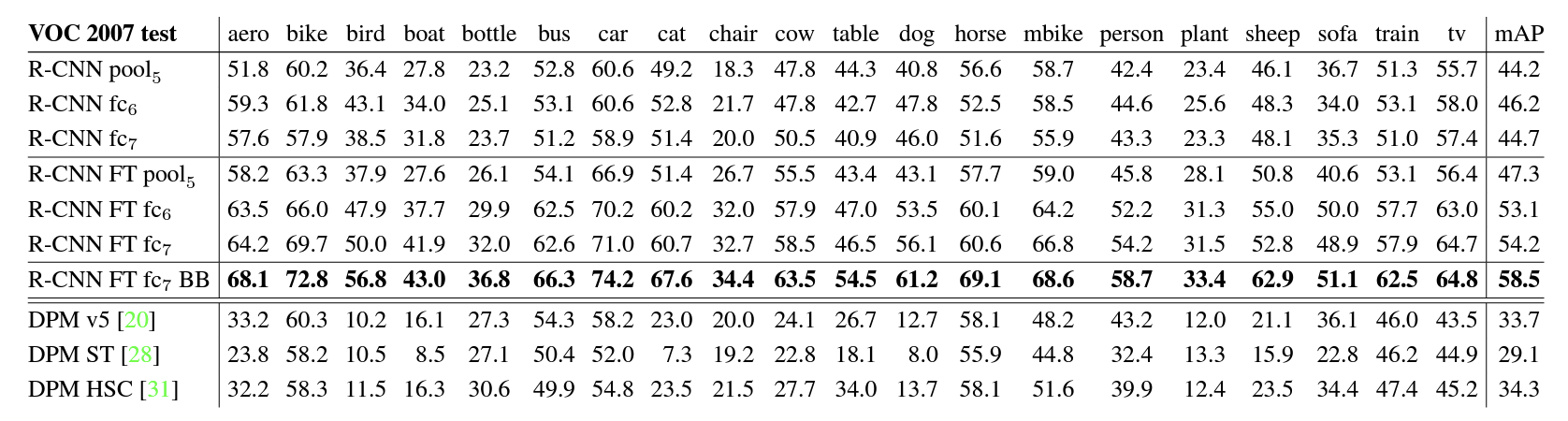
R-CNN의 구성 요소별 성능 영향을 분석하였다:
- Fine-tuning 전후의 성능 변화를 비교한 결과, Fine-tuning은 fc6, fc7 레이어의 성능을 크게 개선
- Pool5 레이어는 사전 학습만으로도 일반화 성능이 뛰어난 반면, fc6와 fc7는 Fine-tuning을 통해 도메인 특화된 정보를 학습
4. The ILSVRC2013 Detection Dataset
ILSVRC2013 데이터셋은 복잡한 장면을 포함하며, PASCAL VOC 데이터셋보다 다양한 객체와 클러터를 제공한다. R-CNN은 Selective Search와 Fine-tuning을 통해 이 데이터셋에서도 높은 mAP(31.4%)를 기록하였다.
4.1 Dataset Overview
ILSVRC2013 데이터셋은 PASCAL VOC보다 다양한 장면과 객체를 포함하며, 다음과 같은 특징이 있다.
- 데이터 분할:
train: 395,918개 이미지val: 20,121개 이미지test: 40,152개 이미지
- 주요 특징:
val과test는 모든 객체가 철저히 라벨링되었지만,train은 일부 객체만 라벨링되어 있다.- PASCAL VOC와 비교하면 더 복잡한 장면과 더 많은 객체 클래스(200개)를 포함한다.
4.2 Region Proposals
ILSVRC2013에서도 PASCAL VOC에서와 마찬가지로 Selective Search를 사용하여 Region Proposal을 생성하였다.
- 이미지 크기 조정: Selective Search는 크기 불변성을 보장하지 않으므로 모든 이미지를 가로 500 픽셀로 조정
- 결과: 평균적으로 이미지당 2403개의 후보 영역이 생성되었으며, 91.6%의 Recall을 달성(0.5 IoU 기준).
4.3 Training Data
훈련 데이터는 val1과 train의 일부를 결합하여 구성되었다:
val1: Validation 세트 일부를 훈련에 사용trainN: 클래스당 최대 N개의 Ground Truth 상자를 포함- SVM 훈련 시 Hard Negative Mining을 통해
val1에서 음성 샘플을 수집 - Bounding Box Regression 훈련은
val1데이터를 사용
4.4 Validation and Evaluation
모든 Hyperparameter와 모델 구성은 PASCAL VOC 실험에서 사용한 설정을 그대로 적용하였다.
val2에서 검증한 결과와test세트 성능이 거의 동일하게 나타나val2를 테스트 성능 예측 지표로 활용할 수 있음을 확인
4.5 Ablation Study
훈련 데이터, Fine-tuning, Bounding Box Regression의 효과를 분석:
- 훈련 데이터 크기:
val1만 사용한 경우보다val1+trainN을 사용했을 때 mAP가 24.1%로 향상되었다. - Fine-tuning: Fine-tuning을 통해 mAP가 26.5%에서 29.7%로 증가하였다.
- Bounding Box Regression: Localization 성능을 개선하여 mAP를 31.0%로 증가시켰다.
4.6 Relationship to OverFeat
OverFeat는 R-CNN과 유사한 접근법(sliding window)을 사용하였으나, Region Proposal을 warp하지 않고 공유 계산을 사용해 속도를 개선
- OverFeat는 R-CNN보다 약 9배 빠르지만 성능(mAP)은 24.3%로 R-CNN(31.4%)에 비해 낮았다.
5. Semantic Segmentation
5.1 Overview of Methodology
Semantic Segmentation은 Region Proposal 기반 분류를 통해 R-CNN을 PASCAL VOC 분할 문제에 적용하였다.
- O2P 시스템과 비교: O2P는 고차원 피처(SIFT, LBP)와 Selective Search를 사용했으나, R-CNN은 CNN 피처를 활용하여 더 효율적인 접근법을 제시
5.2 CNN Feature Strategies
- Full: Region Proposal의 전체 영역에서 CNN 피처를 추출
- Foreground (fg): Region Proposal의 전경만 사용해 CNN 피처를 추출
- Full+fg: Full과 Foreground 피처를 결합
R-CNN은 PASCAL VOC 2010 및 2012 데이터셋에서 기존 방법보다 높은 mAP(mean Average Precision)을 달성하였다.
- PASCAL VOC 2010: 기존 DPM(Deformable Part Model)보다 약 30% 이상 성능 향상을 기록
- Ablation Study를 통해 CNN의 깊이가 성능 향상에 중요한 역할을 한다는 점을 밝힘
- Bounding Box Regression은 예측된 경계의 정확도를 크게 개선
이 논문은 객체 탐지의 패러다임을 바꾼 기념비적인 연구이다. 특히 selective search와 CNN의 결합은 직관적이면서도 효과적인 접근으로, 객체 탐지의 성능을 크게 향상시켰다. 다만, R-CNN의 높은 계산 비용과 느린 처리 속도는 실시간 애플리케이션에는 부적합하며, 이는 후속 연구에서 지속적으로 해결되고 있다.
개인적으로, 이 논문은 딥러닝 모델의 모듈화와 재사용성을 강조한 점에서 큰 인사이트를 주었다. 각 구성 요소의 독립성을 유지하면서도 상호 보완적인 효과를 극대화한 설계는 다른 AI 모델 개발에서도 유용한 전략이 될 것이라 생각한다. R-CNN 이후 발전된 모델들과 비교하며 읽는다면, 객체 탐지 연구의 흐름과 딥러닝의 진보를 더욱 깊이 이해할 수 있을 것이다.
