논문 리뷰 스터디
1.[논문 리뷰] Attention is all you need
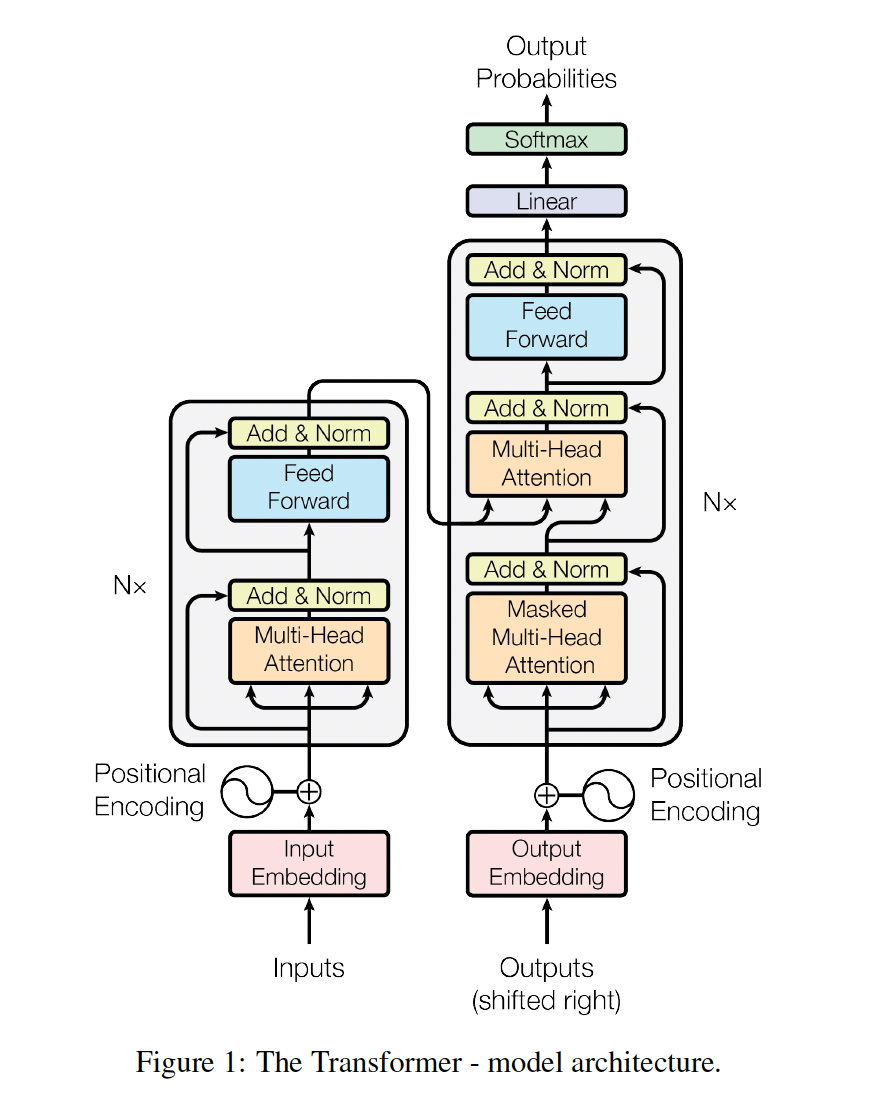
Transformer는 2017년에 Google Brain 팀이 발표한 모델로, 자연어 처리(NLP) 및 시퀀스 변환 작업에서 큰 혁신을 가져온 모델이며 NLP뿐만 아니라 컴퓨터 비전, 음성 처리 등 다양한 분야로 확장되고 있다.오늘은 Transformer를 처음 제안
2.[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
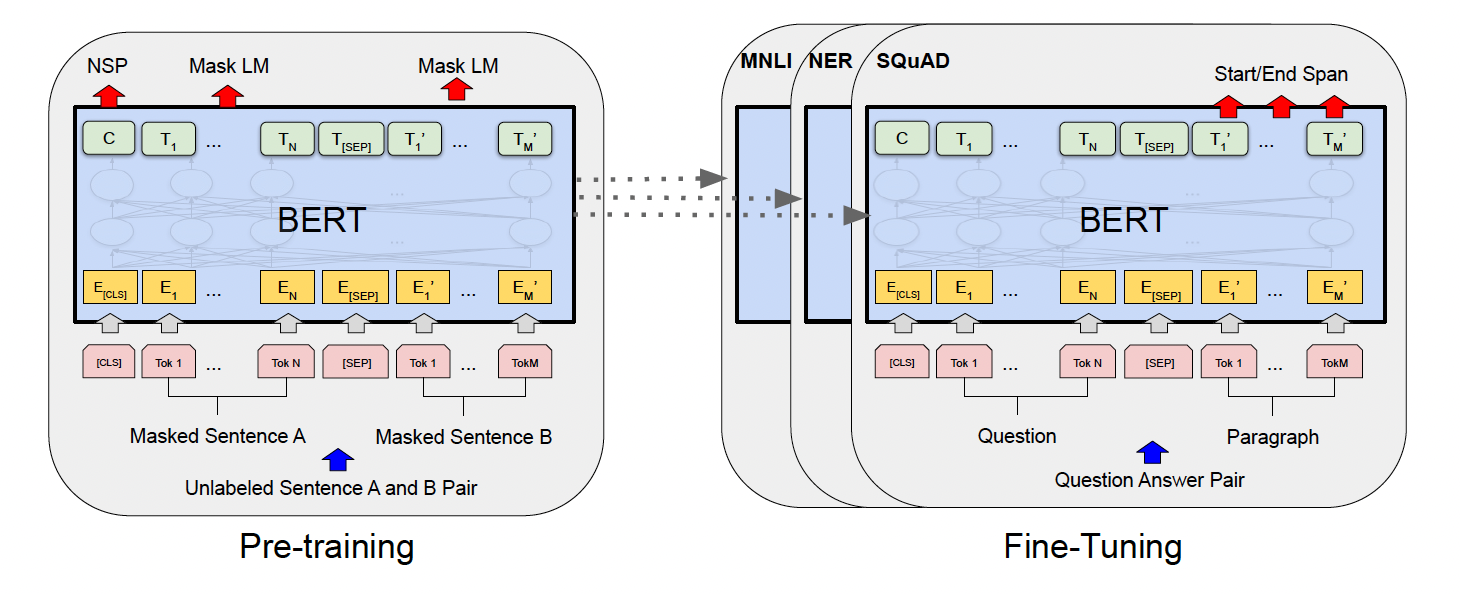
BERT(Bidirectional Encoder Representations from Transformers)는 Google에서 개발한 자연어 처리 모델로, 문장의 양방향 문맥을 동시에 이해할 수 있는 능력을 가진 사전 훈련된 언어 모델이다. 이 모델은 다양한 NLP
3.[논문 리뷰] GPT3 : Language Models are Few-Shot Learners
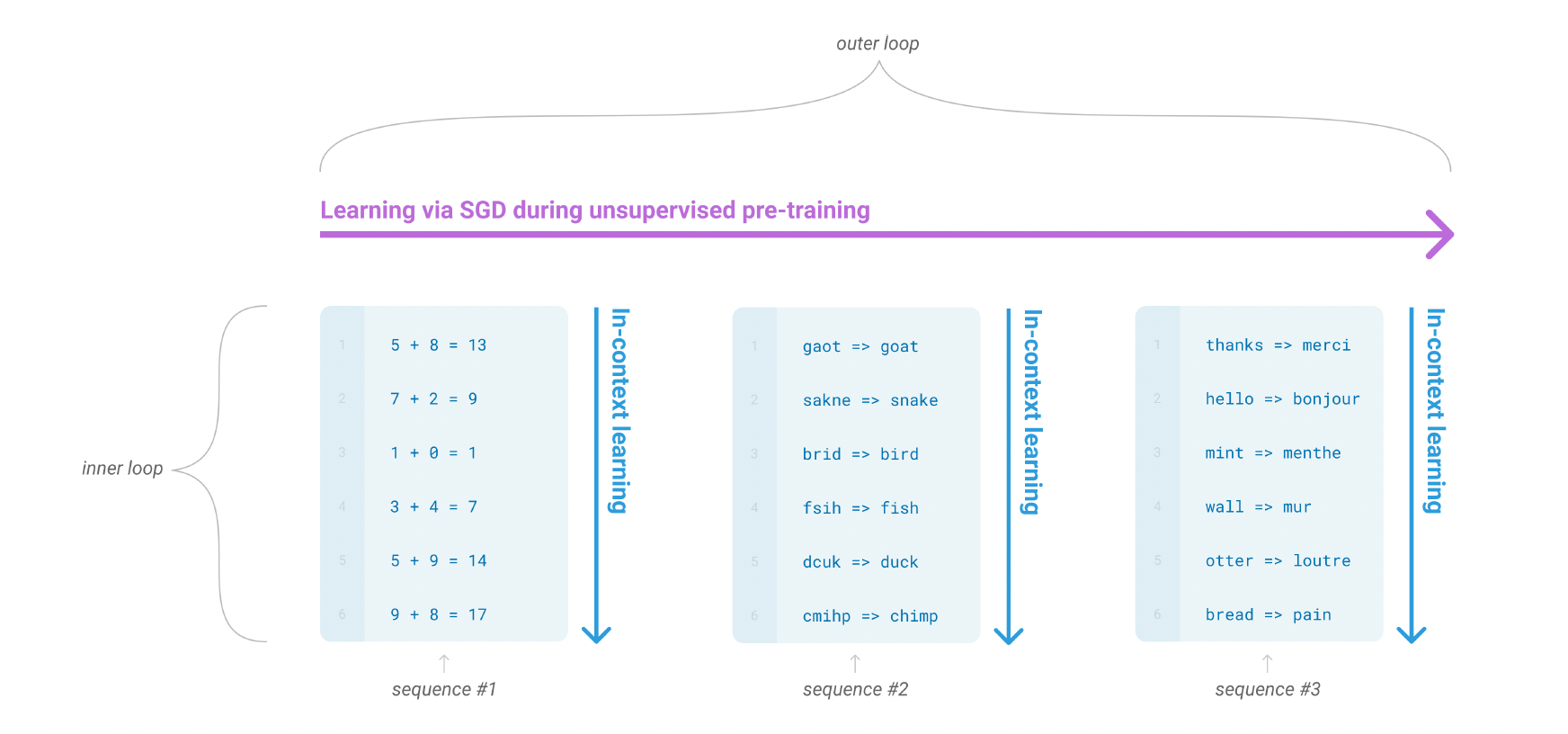
GPT-3는 인공지능의 자연어 처리 성능을 크게 향상시키기 위해 OpenAI가 개발한 언어 모델로 2020년에 등장했다. 이 모델의 등장은 자연어 처리 분야에서의 거대한 도약으로 평가되며, 언어 모델의 규모가 성능에 미치는 영향을 보여주는 중요한 사례가 되었다. 이후
4.[논문 리뷰] Constitutional AI: Harmlessness from AI Feedback
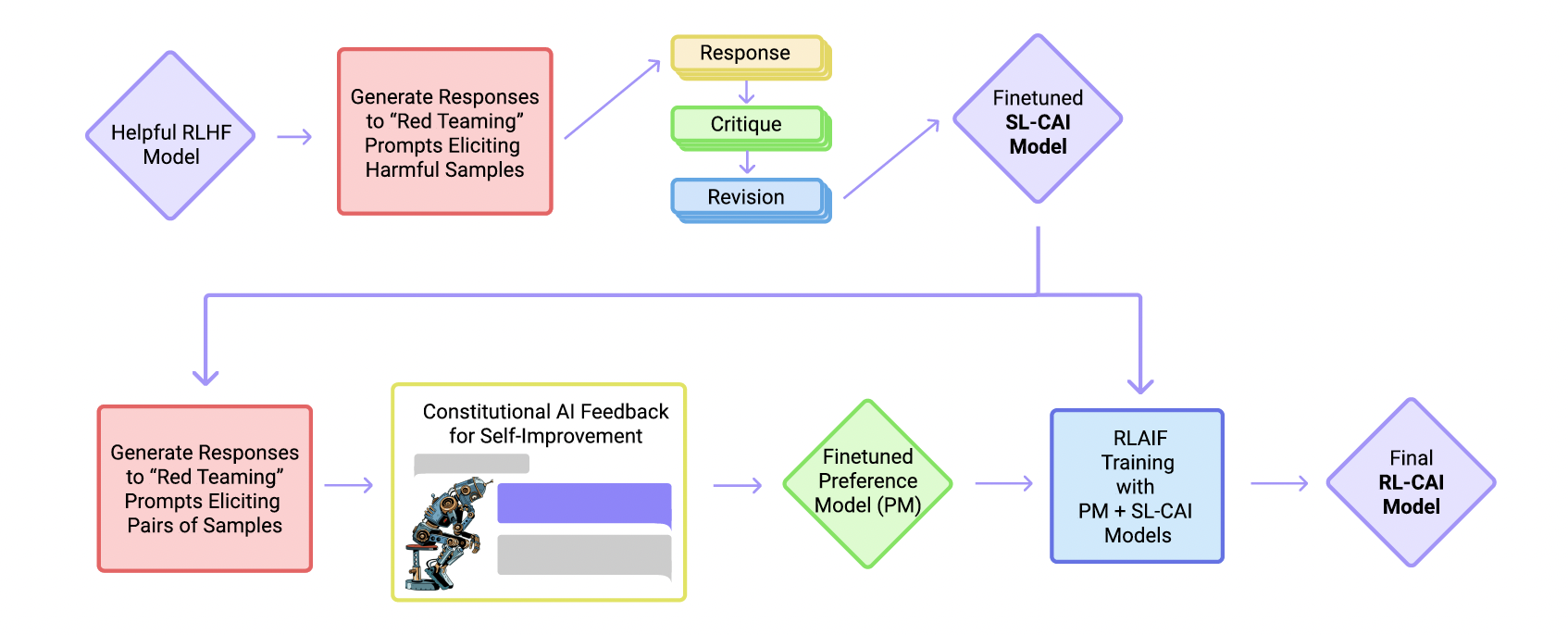
헌법적 AI(Constitutional AI)인간의 라벨링 없이 AI가 스스로 개선하며 유해하지 않은 AI 어시스턴트를 훈련하는 방법CAI(Constitutional AI) 과정 1) 지도 학습 단계: AI가 자체 출력을 비판하고 수정하여 모델을 미세 조정 2) 강화
5.[논문 리뷰] Very Dep Convolutional Networks For Large-Scale Image Recognition

2014년 발표된 VGGNet은 컨볼루션 신경망(ConvNet)의 깊이가 모델 성능에 미치는 영향을 체계적으로 연구한 선구적인 논문이다. 당시 ImageNet과 같은 대규모 데이터셋과 GPU의 발전으로 딥러닝이 컴퓨터 비전 분야에서 획기적인 성과를 내고 있었으며, V
6.[논문 리뷰] Deep Residual Learning for Image Recognition | ResNet
개념 정리 Residual: Y-X 즉, 결과의 오류 정도를 말한다.본 논문은 이미지 인식 성능을 극대화하기 위한 딥러닝 모델인 "ResNet(Residual Networks)"을 소개한다. 일반적으로 신경망의 깊이가 깊어질수록 성능이 향상될 것으로 기대되나, 실제로는
7.[논문리뷰]Rich feature hierarchies for accurate object detection and semantic segmentation | R-CNN
이 논문은 R-CNN(Region-Based Convolutional Neural Networks)을 처음 제안하며 객체 탐지(Object Detection)와 의미론적 분할(Semantic Segmentation)의 성능을 크게 개선한 연구이다. 논문의 핵심 기여는
8.[논문 리뷰]YOLOv3: An Incremental Improvement

YOLOv3는 YOLO 시리즈의 세 번째 모델로, 속도와 정확도를 개선하여 실시간 객체 탐지에서 효율성을 극대화했다. 간단한 설계 변경과 훈련 기법을 통해 이전 모델 대비 발전을 이루었으며, COCO 데이터셋 기준으로 SSD와 RetinaNet 등과 경쟁할 만한