BERT(Bidirectional Encoder Representations from Transformers)는 Google에서 개발한 자연어 처리 모델로, 문장의 양방향 문맥을 동시에 이해할 수 있는 능력을 가진 사전 훈련된 언어 모델이다. 이 모델은 다양한 NLP 작업에 미세 조정되어 최첨단 성능을 보여주며, NLP 연구와 실무에 큰 영향을 미쳤다. 오늘은 BERT 논문을 읽고 리뷰 해보려고 한다.
0. Abstract
BERT(Bidirectional Encoder Representations from Transformers)는 자연어 처리(NLP)에서 텍스트의 양방향 컨텍스트를 학습하여 뛰어난 성능을 보여주는 모델이다. BERT는 마스크된 언어 모델링과 다음 문장 예측을 통해 사전 훈련되며, 다양한 NLP 태스크에서 미세 조정을 통해 최고의 성능을 달성한다. 이 리뷰에서는 BERT 논문의 주요 구조, 훈련 방법, 실험 결과 및 성능 분석을 상세히 다루고, 기존 연구들과 비교하여 BERT의 기여를 설명한다.
1. Introduction
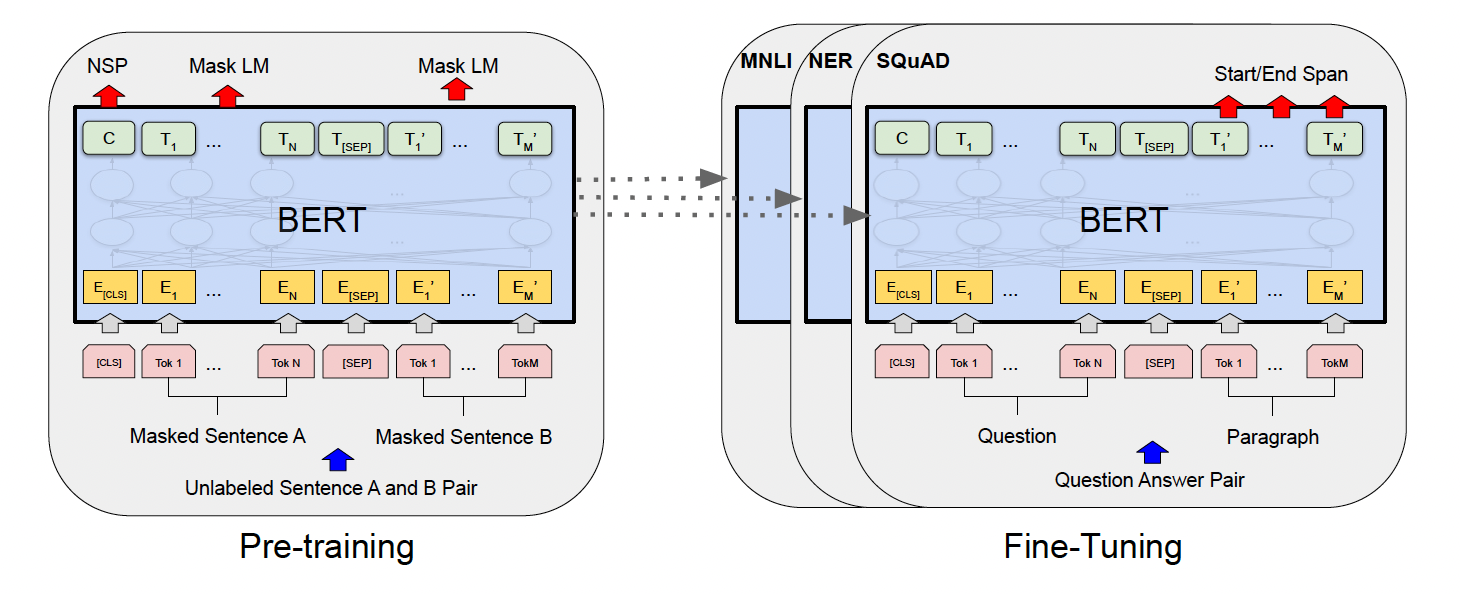
기존 자연어 처리 모델은 대개 단방향 컨텍스트를 활용하여 문장을 이해했으나, 이는 문맥을 완전히 이해하는 데 한계가 있었다. BERT는 Transformer 아키텍처를 사용하여 텍스트의 양방향 컨텍스트를 학습하는 사전 훈련 언어 모델로, 이 문제를 극복하고 더 나은 성능을 보여준다. 특히, BERT는 사전 훈련 후 특정 작업에 맞게 미세 조정하는 접근 방식을 통해 다양한 NLP 작업에서 최첨단 성능을 달성했다. 본 논문 리뷰는 BERT의 주요 개념, 관련 연구, 실험 결과 및 분석을 중점적으로 다룬다.
- 기존의 언어모델 사전 훈련 접근법은 피처 기반(ELMo)과 미세 조정(Generative Pre-trained Transformer) 두 가지로 나뉜다.
- 기존 접근법들의 주요 한계는 단방향 언어 모델을 사용한다는 점이다.
- BERT(Bidirectional Encoder Representations from Transformers)는 이러한 한계를 극복하기 위해 제안되었다.
- BERT는 "마스크된 언어 모델"(MLM)과 "다음 문장 예측" 작업을 통해 양방향 문맥을 학습합니다.
- BERT의 주요 장점:
- 양방향 사전 훈련의 중요성을 입증
- 복잡한 작업별 아키텍처의 필요성 감소
- 다양한 NLP 작업에서 최고 성능 달성
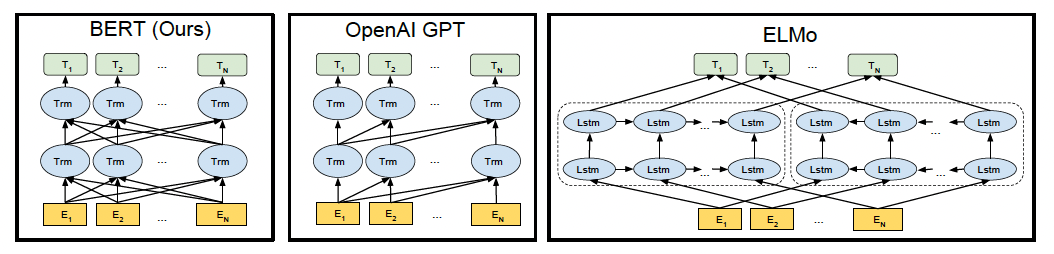 BERT, GPT, ELMo 비교
BERT, GPT, ELMo 비교
2. Related Work
BERT의 발전 배경을 이해하기 위해서는 관련된 기존 연구들을 살펴볼 필요가 있다. BERT가 등장하기 전까지의 연구들은 다음 세 가지 주요 접근법으로 구분된다.
2.1 Unsupervised Feature-based Approaches
이 접근법은 대규모 텍스트 코퍼스에서 비지도 학습을 통해 단어 및 문장 표현을 학습하는 방식이다. 대표적인 예로 Word2Vec, GloVe, 그리고 ELMo가 있다. Word2Vec과 GloVe는 단어 수준에서의 임베딩을 제공하여 단어 간의 유사성을 학습했으며, ELMo는 문장의 양방향 컨텍스트를 고려한 표현을 제공했다. 그러나 이들 모델은 주로 단일 문장 내에서의 컨텍스트를 고려하므로, 문장 간 관계를 이해하는 데는 한계가 있었다.
2.2 Unsupervised Fine-tuning Approaches
이 접근법은 사전 훈련된 모델을 특정 NLP 작업에 맞게 미세 조정하는 방법이다. 대표적으로 ULMFiT(Universal Language Model Fine-tuning)가 있다. ULMFiT는 텍스트 분류 작업에서 큰 성능 향상을 보여주었으며, BERT의 개발에 중요한 영감을 주었다. 이 방법은 비지도 학습으로 사전 훈련된 모델을 다양한 태스크에 맞춰 추가적인 학습을 통해 성능을 극대화한다는 점에서 BERT와 유사한 점이 있다.
2.3 Transfer Learning from Supervised Data
이 접근법은 대규모의 레이블된 데이터로 학습된 모델을 다른 작업에 전이 학습(transfer learning)하는 방법이다. 대표적인 예로는 ImageNet에서 학습된 모델이 다양한 컴퓨터 비전 작업에 적용된 사례가 있다. NLP에서는 이러한 접근이 제한적으로 사용되었으나, BERT는 비슷한 원리를 NLP에 적용하여 대규모 비지도 사전 훈련과 후속 작업에서의 미세 조정을 결합함으로써 이를 성공적으로 구현했다.
3. BERT
BERT는 두 가지 주요 단계인 사전 훈련(Pre-training)과 미세 조정(Fine-tuning)을 통해 학습된다.
Model Architecture
-
기본 구조:
- 다층 양방향 Transformer 인코더 사용
- BERTBASE와 BERTLARGE 두 가지 버전 소개
-
주요 특징:
- 양방향 자기 주의(self-attention) 메커니즘 사용 (GPT와 차별점)
- 단일 문장과 문장 쌍 모두 처리 가능
-
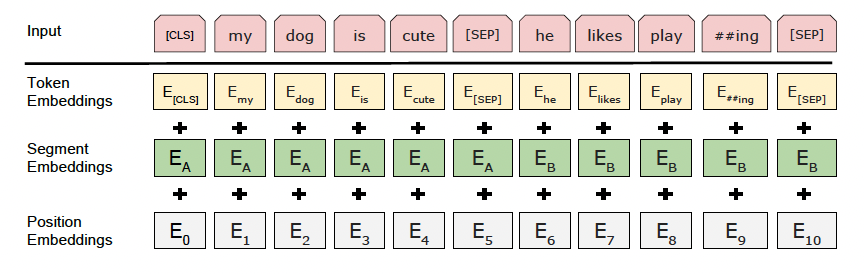
입력/출력 표현:
- WordPiece 임베딩 사용 (30,000 토큰 어휘)
- 특수 토큰 사용: CLS, [SEP](문장 구분용)
- 문장 구분을 위한 학습된 임베딩 추가
-
입력 구성:
- 토큰 임베딩 + 세그먼트 임베딩 + 위치 임베딩
3.1 Pre-training BERT
BERT의 사전 훈련 단계에서는 대규모 텍스트 데이터셋에서 마스크된 언어 모델링(Masked Language Modeling, MLM)과 다음 문장 예측(Next Sentence Prediction, NSP)을 수행한다. MLM은 입력 문장에서 랜덤하게 선택된 단어를 마스크하고, 모델이 마스크된 단어를 예측하도록 훈련하여 단어의 양방향 문맥을 학습하게 한다. NSP는 두 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지 예측하는 작업으로, 문장 간의 관계를 이해하는 능력을 강화한다. 이 과정을 통해 BERT는 언어의 정교한 표현을 학습하게 된다.
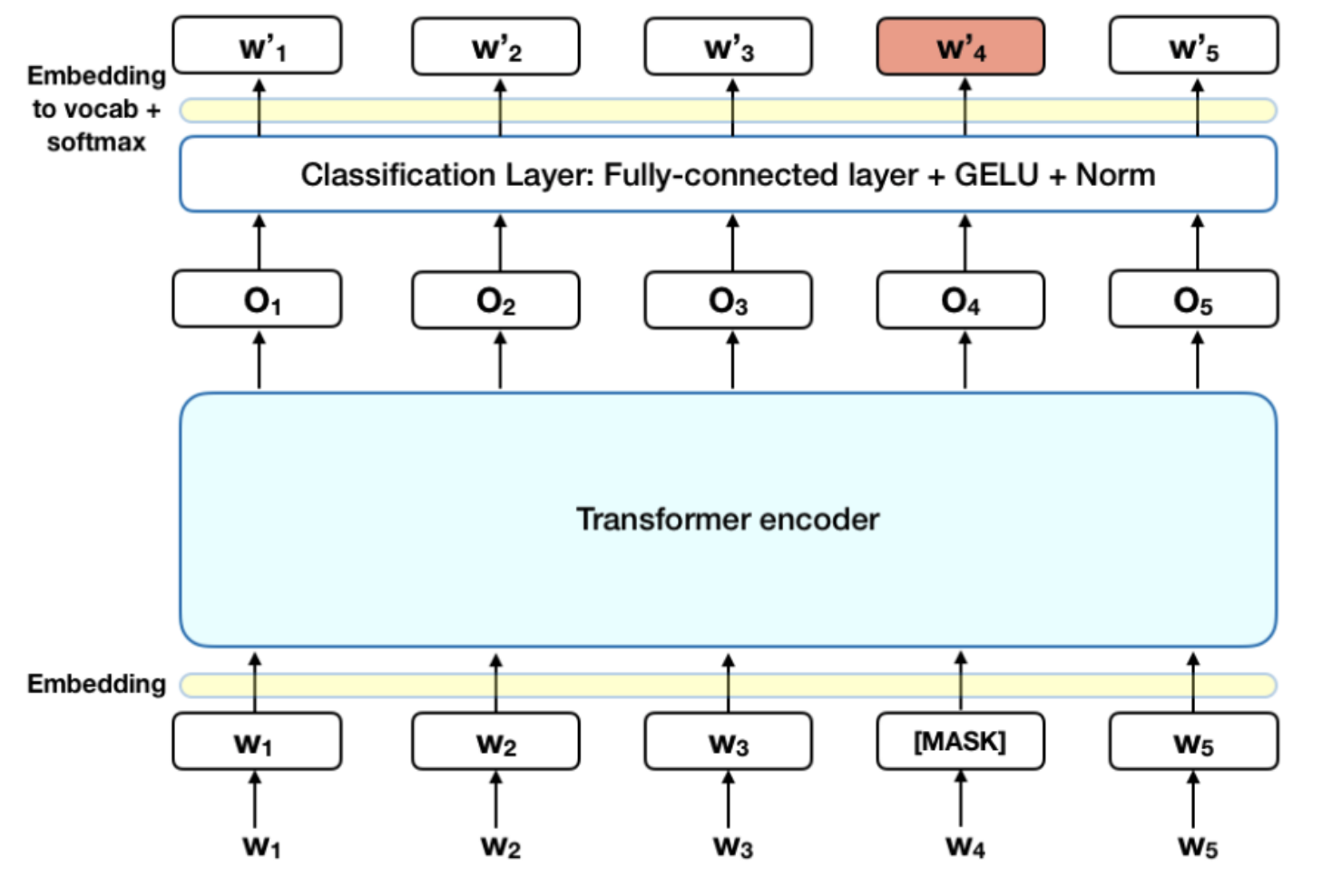
3.1.1 Masked LM
-
목적: 깊은 양방향 표현을 학습하기 위함
-
방법:
- 입력 토큰의 일부(15%)를 무작위로 마스킹
- 마스크된 토큰을 예측하는 과제 수행
-
마스킹 전략:
- 80%: [MASK] 토큰으로 대체
- 10%: 무작위 토큰으로 대체
- 10%: 원래 토큰 유지
-
장점:
- 양방향 컨텍스트를 활용한 학습 가능
- 사전 훈련과 미세 조정 간의 불일치 완화
-
평가:
- 마스크된 토큰의 원래 단어를 예측하는 크로스 엔트로피 손실 사용
- 마스크된 토큰의 원래 단어를 예측하는 크로스 엔트로피 손실 사용
3.1.2 Next Sentence Prediction (NSP)
-
다음 문장 예측(NSP) 작업:
- 목적: 문장 간 관계 이해 능력 향상
- 방법: 두 문장이 연속적인지 예측하는 이진 분류 작업
- 구성: 50% 실제 연속 문장, 50% 무작위 문장 쌍
- 효과: QA와 NLI 작업에서 성능 향상
-
사전 훈련 데이터:
- 사용 데이터:
- BooksCorpus (8억 단어)
- 영어 위키피디아 (25억 단어, 본문만 사용)
- 특징: 문서 단위의 연속적인 텍스트 사용
- 중요성: 긴 연속 시퀀스 추출을 위해 문서 단위 코퍼스 활용
- 사용 데이터:
3.2 Fine-tuning BERT
사전 훈련이 완료된 후, BERT는 특정 NLP 작업에 맞게 미세 조정된다. 이 단계에서 BERT는 해당 작업에 맞는 데이터셋을 사용하여 추가 학습을 수행하며, 학습된 가중치는 사전 훈련에서 얻어진 초기화된 상태를 기반으로 조정된다. BERT는 미세 조정 단계에서 최소한의 파라미터 변경만으로도 높은 성능을 달성할 수 있어, 다양한 NLP 작업에 쉽게 적용 가능하다. 예를 들어, 질문 응답, 자연어 추론, 감정 분석 등 다양한 태스크에서 우수한 성능을 보인다.
4. Experiments
BERT 논문에서는 여러 NLP 태스크에 대해 실험을 수행하여 그 성능을 입증했다.
4.1 GLUE
GLUE(General Language Understanding Evaluation)는 다양한 자연어 처리 작업으로 구성된 벤치마크로, 문장의 유사도 측정, 자연어 추론, 문장 분류 등의 작업을 포함한다. BERT는 GLUE 벤치마크의 9개 작업에서 모두 최고의 성능을 기록했으며, 이는 BERT가 일반적인 언어 이해 능력에서 매우 뛰어나다는 것을 입증한다.
4.2 SQuAD v1.1
SQuAD(Stanford Question Answering Dataset) v1.1은 문서에서 주어진 질문에 대해 정답을 찾는 태스크로 구성된다. BERT는 SQuAD v1.1에서 이전 모델들을 뛰어넘는 성능을 보여주었으며, 특히 인간 성능에 매우 근접한 결과를 달성했다. 이는 BERT의 강력한 문맥 이해 능력과 정교한 질문 응답 능력을 입증한다.
4.3 SQuAD v2.0
SQuAD v2.0은 SQuAD v1.1에 비해 난이도가 증가된 버전으로, 질문에 대한 답이 없는 경우를 포함한다. BERT는 이 난이도 높은 태스크에서도 높은 성능을 유지했으며, 특히 답이 없는 경우를 정확하게 식별하는 능력을 보여주었다. 이는 BERT가 단순히 답을 찾는 것뿐만 아니라, 문장의 의미와 관계를 깊이 있게 이해할 수 있음을 의미한다.
4.4 SWAG
SWAG(Situations With Adversarial Generations)는 문장의 상황 이해와 다음 상황을 예측하는 태스크로, BERT는 여기서도 높은 성능을 기록했다. 이 태스크는 문장의 일관성과 논리적 흐름을 이해하는 능력을 평가하는데, BERT의 양방향 문맥 학습이 이러한 작업에서도 유효함을 보여준다.
5. Ablation Studies
BERT 논문에서는 BERT의 구성 요소가 모델 성능에 미치는 영향을 분석하기 위해 여러 Ablation Study를 수행했다.
5.1 Effect of Pre-training Tasks
마스크된 언어 모델링(MLM)과 다음 문장 예측(NSP)의 중요성을 평가하기 위해 각 작업을 제거한 상태에서 실험을 수행했다. 실험 결과, 두 작업 모두 BERT의 성능에 중요한 기여를 한다는 것이 확인되었다. 특히, MLM은 단어의 양방향 문맥 이해를 강화하는 데 큰 역할을 했으며, NSP는 문장 간 관계를 파악하는 데 중요한 영향을 미쳤다.
5.2 Effect of Model Size
BERT의 모델 크기와 계층 수가 성능에 미치는 영향을 평가하기 위해 BERT-Base와 BERT-Large를 비교했다. 실험 결과, BERT-Large는 더 깊고 넓은 네트워크 구조를 가지고 있으며, 대부분의 태스크에서 BERT-Base보다 우수한 성능을 보여주었다. 이는 모델 크기와 깊이가 언어 표현 학습에 중요한 요소임을 나타낸다.
5.3 Feature-based Approach with BERT
BERT의 사전 훈련된 표현을 사용하여 특정 태스크에 적용할 때, 단순히 특징을 추출(feature extraction)하는 방법과 미세 조정을 결합한 방법을 비교했다. 미세 조정을 통한 접근이 훨씬 높은 성능을 보였으며, 이는 BERT의 가중치가 특정 작업에 맞게 조정될 때 성능이 크게 향상된다는 것을 보여준다.
6. Conclusion
BERT는 자연어 처리의 새로운 패러다임을 제시한 모델로, 양방향 문맥 이해를 통해 다양한 NLP 작업에서 혁신적인 성능 향상을 이루었다. BERT의 사전 훈련 및 미세 조정 접근법은 이후 연구들에 큰 영향을 미쳤으며, NLP 모델 개발의 중요한 기준점으로 자리 잡았다. 향후 연구는 BERT의 효율성을 높이거나 새로운 작업에 적용하는 방법을 탐구할 것이다.
