GPT-3는 인공지능의 자연어 처리 성능을 크게 향상시키기 위해 OpenAI가 개발한 언어 모델로, 2020년에 등장했다. GPT-3의 등장은 자연어 처리 분야에서의 거대한 도약으로 평가되며, 언어 모델의 규모가 성능에 미치는 영향을 보여주는 중요한 사례가 되었다.
오늘은 GPT-3 모델을 발표한 논문인 Language Models are Few-Shot Learners를 리뷰해보고자한다. 논문과 함께 다양한 블로그 정보들을 취합해서 나름의 논리로 정리한 글이라는 점을 먼저 밝힌다.
0. Abstract
기존의 NLP 연구는 대규모 사전학습 후 특정 작업에 대해 fine-tuning하는 방법으로 상당한 성과를 달성했으나, 이런 방식은 태스크가 달라질 때마다 매번 데이터를 확보하고 fine-tuing 해야한다는 한계가 있다. 반면에 인간은 몇가지 예제나 간단한 지시만으로 새로운 언어 작업을 수행할 수 있다. 이렇게 몇 개의 예시만 보고 태스크에 적응하여 문제를 푸는 것을 'few-shot learning' 이라고 한다.
- 연구 목적 : 대규모 언어 모델을 통한 few-shot 학습 성능 향상 입증
- 방법론 : 1,750억개의 파라미터 GPT-3 모델 훈련 (기존 모델의 10배 규모), 파인튜닝 없이 텍스트 상호작용만으로 작업 수행
1. Introduction
GPT-3 이전의 NLP 연구는 사전학습된 RNN 혹은 Transformer 언어 모델을 사용하는 등 작업에 구애받지 않는 아키텍처로 발전해왔다. 그러나 새로운 작업마다 작업별 데이터셋과 fine-tuning이 필요하다는 한계는 여전했다. 이러한 한계를 극복하는 것은 다음의 세 가지 관점에서 의미가 있다. 첫째, 새로운 작업마다 대규모 레이블링 예제 데이터셋을 확보하지 않아도 된다면 언어 모델의 적용 가능성이 넓어질 것이다. 둘째, 미세조정 과정에서 훈련 분포에 과도하게 특화될 위험성을 낮추고 일반화 성능을 높여준다. 셋째, 인간은 대부분의 언어 작업을 학습하기 위해 대규모의 지도 학습 데이터셋을 필요로하지 않는다. 한계 극복을 통해 NLP 시스템이 인간과 같은 유연성과 일반성을 갖추기를 기대할 수 있다.
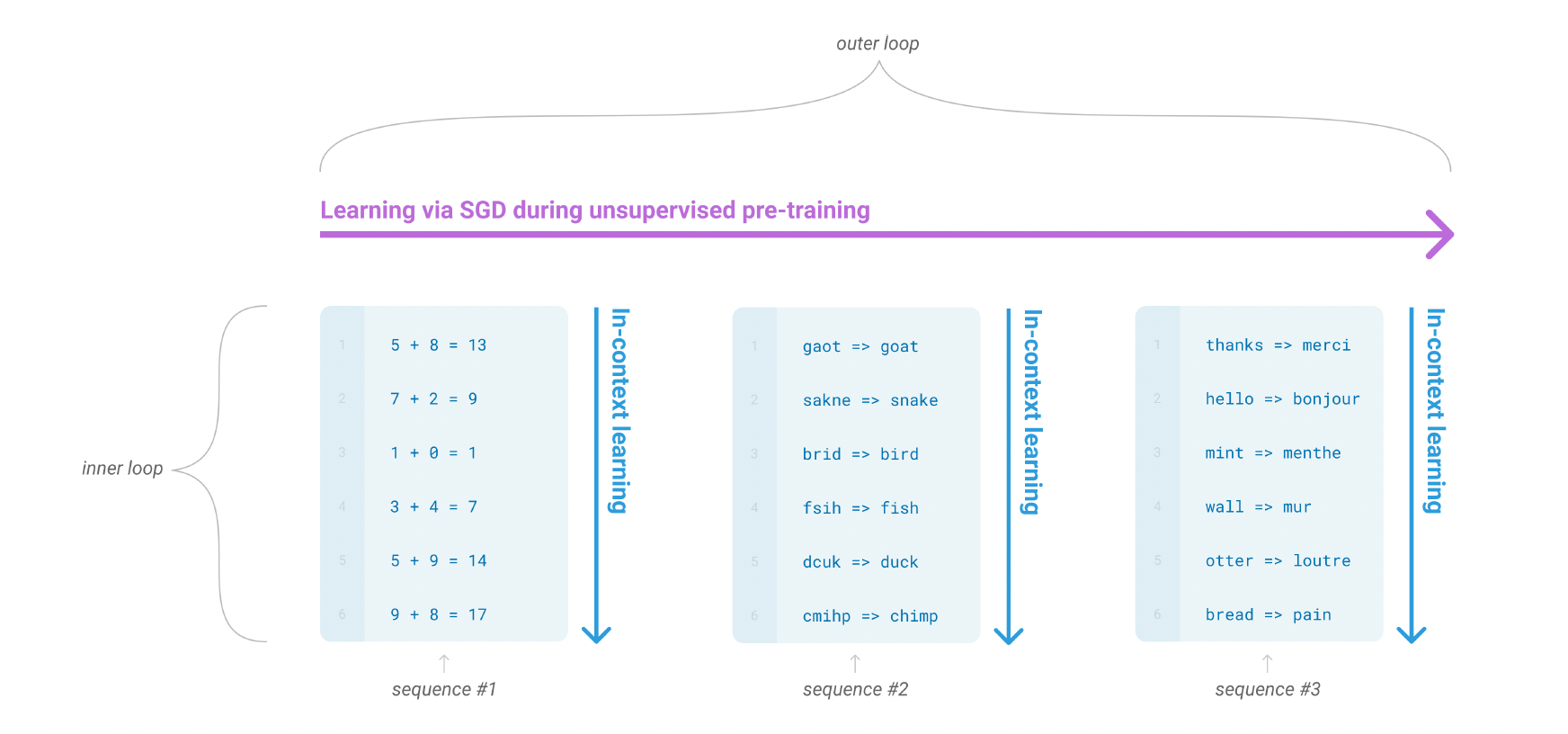
- meta-learning: 언어 모델의 맥락에서 메타 학습이란 모델이 훈련 시점에 광범위한 기술과 패턴 인식 능력을 개발하고, 추론 시점에 이러한 능력을 사용하여 원하는 작업에 빠르게 적응하거나 이를 인식하는 것을 의미
- in-context learning: 사전 학습된 언어 모델의 텍스트 입력을 작업 명세의 한 형태로 사용하는 방식으로 모델은 자연어 지시나 몇 가지 작업 시연을 조건으로 하여 이후 작업 인스턴스를 예측하는 방식으로 작업을 수행
Meta Learning
- Task-Agnostic: 다양한 작업에서 일반화할 수 있는 능력을 키움
- Fast Adaptation: 새로운 작업을 적은 양의 데이터로 빠르게 학습
- Few-shot learning: 메타 학습은 적은 양의 데이터로도 새로운 작업을 학습할 수 있는 모델을 만드는 데 중점
메타 학습은 초기에 어느 정도 가능성을 보였지만 여전히 fine-tuning에 비해 훨씬 성능이 뒤쳐졌다.
NLP 연구의 새로운 트렌드는 모델 크기를 키우는 것이다. 트랜스 포머 언어 모델의 용량이 크게 증가해왔고, 파라메터 수가 1억 개(GPT-1), 3억 개(BERT), 14억 개(GPT-2), 80억 개(Megatron), 110억 개(T5), 170억 개(Project Turing)까지 늘어나며 다운스트림 태스크에서의 성능은 점점 더 좋아졌다. in-context learning 방식은 최대한 다양한 스킬과 태스크를 모델의 파라미터에 저장해야 하고, 모델의 스케일이 증가할 때 성능이 증가할 가능성이 있다.
GPT-3는 1750억개의 파라미터를 학습하며 각 작업에 대해 아래 세 가지 조건에서 평가된다.
- (a) few-shot learning, 모델의 context window에 넣을 수 있는 만큼의 예제(보통 10개에서 100개)를 허용
- (b) one-shot learning, 단 하나의 예제만을 허용
- (c) zero-shot learning, 예제 없이 자연어로 된 지시사항만을 모델에 제공
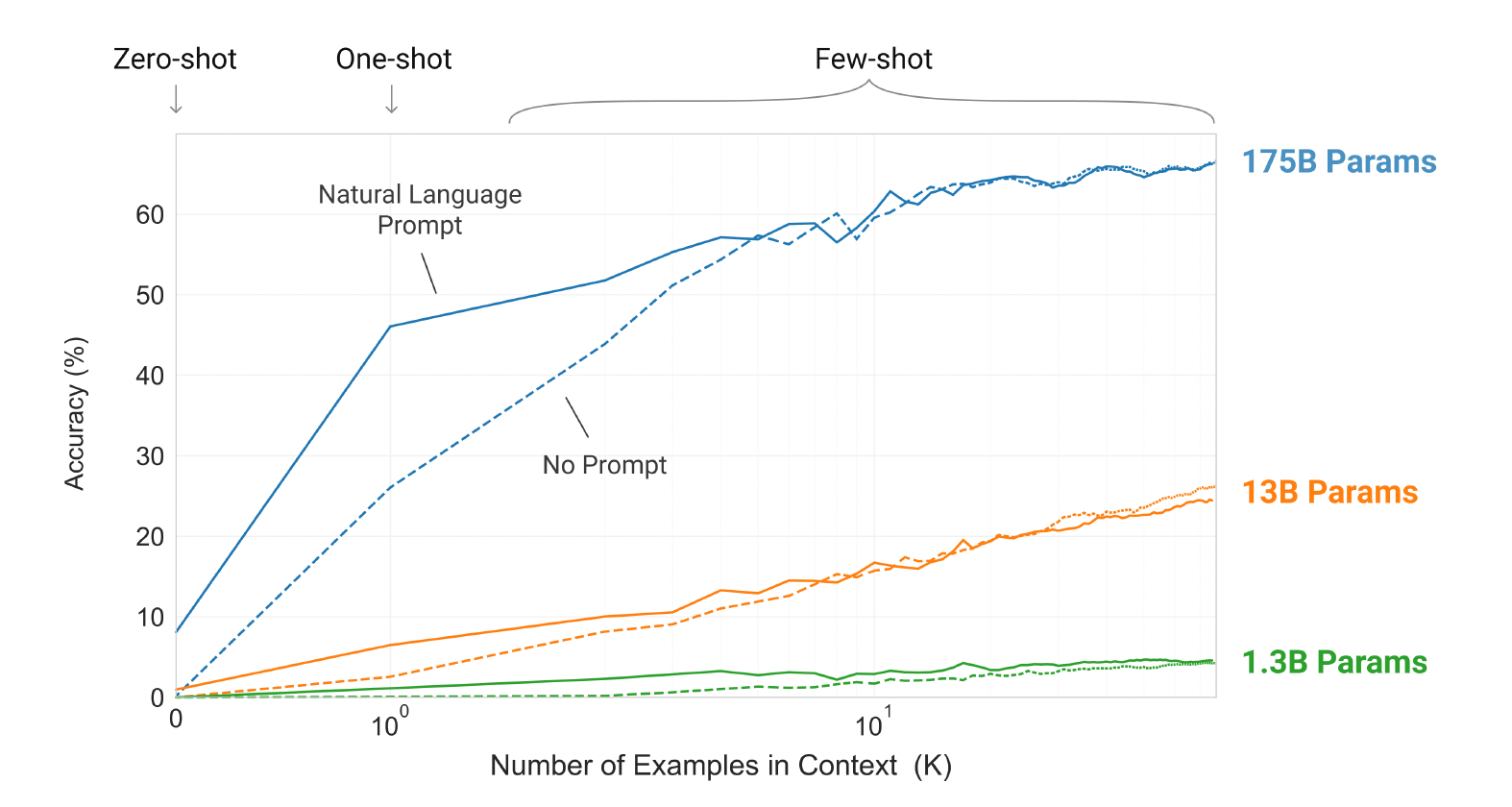
위 그림은 세 가지 조건에 따른 결과를 보여주고 있다.
-
태스크에 대한 자연어로 된 지시를 추가하면 모델 성능이 향상된다.
(Natural Language Prompt > No Prompt) -
모델에 제공되는 예제가 많을수록 성능이 향상 (K에 비례하여 정확도 증가)
-
큰 모델일수록 in-context 정보를 잘 활용
(175B params > 13B params > 1.3B params)
위 과정에서는 그래디언트 업데이트나 미세조정을 포함하지 않는다.
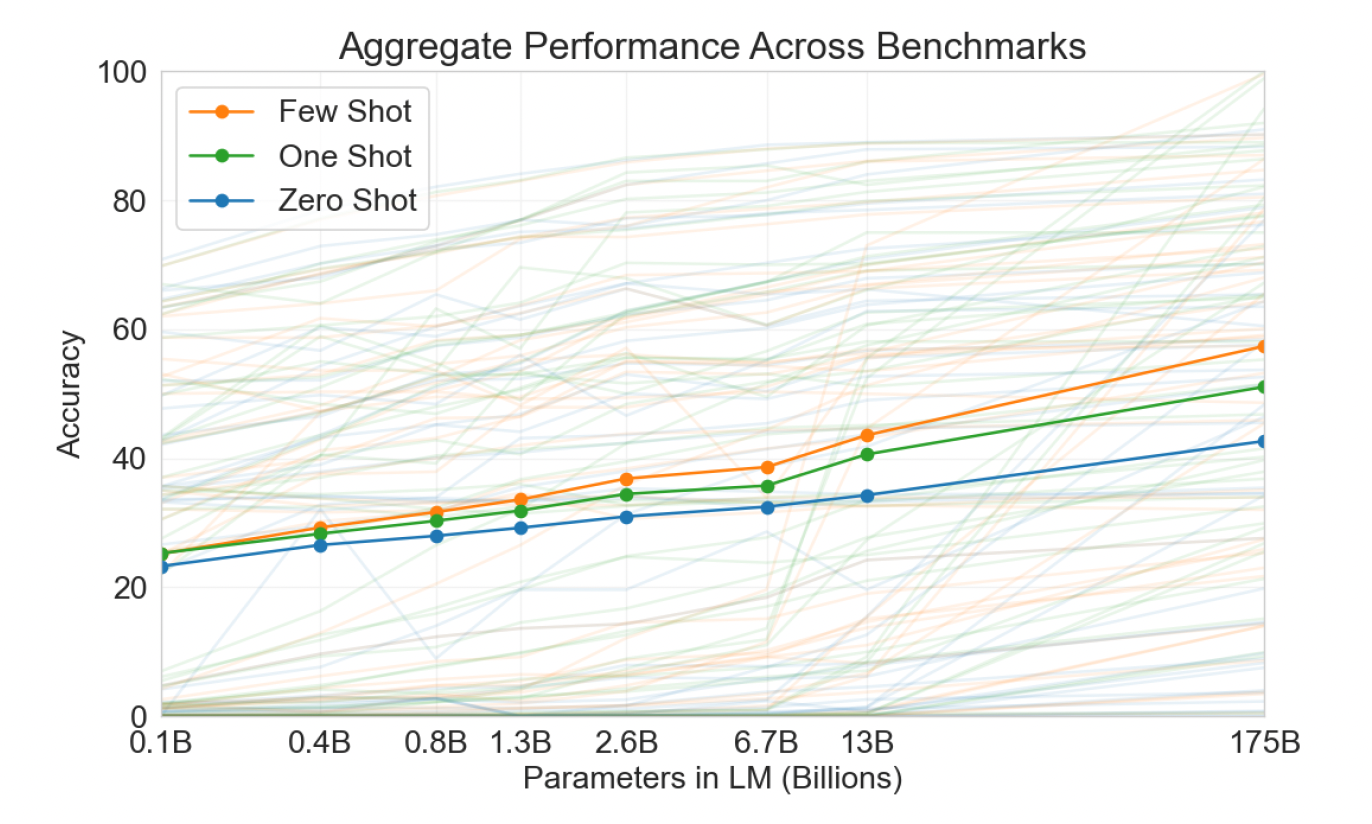
파라미터 개수가 많을수록, 예제수가 많을수록 성능이 개선된다는 점을 위 그래프로 확인할 수 있다.
추가 논의
-
GPT-3의 한계:
- 일부 자연어 추론 작업(예: ANLI)과 독해 데이터셋(예: RACE, QuAC)에서 어려움 발견
- 이러한 한계점 분석을 통해 향후 연구 방향 제시
-
데이터 오염 문제:
- 대규모 웹 데이터셋 사용 시 발생 가능한 문제로 테스트 데이터셋의 내용이 잠재적으로 훈련 데이터에 포함 될 수 있음
- 본 연구에서는 데이터 오염을 측정하고 왜곡 효과를 정량화 하기 위한 도구 개발
2. Approach
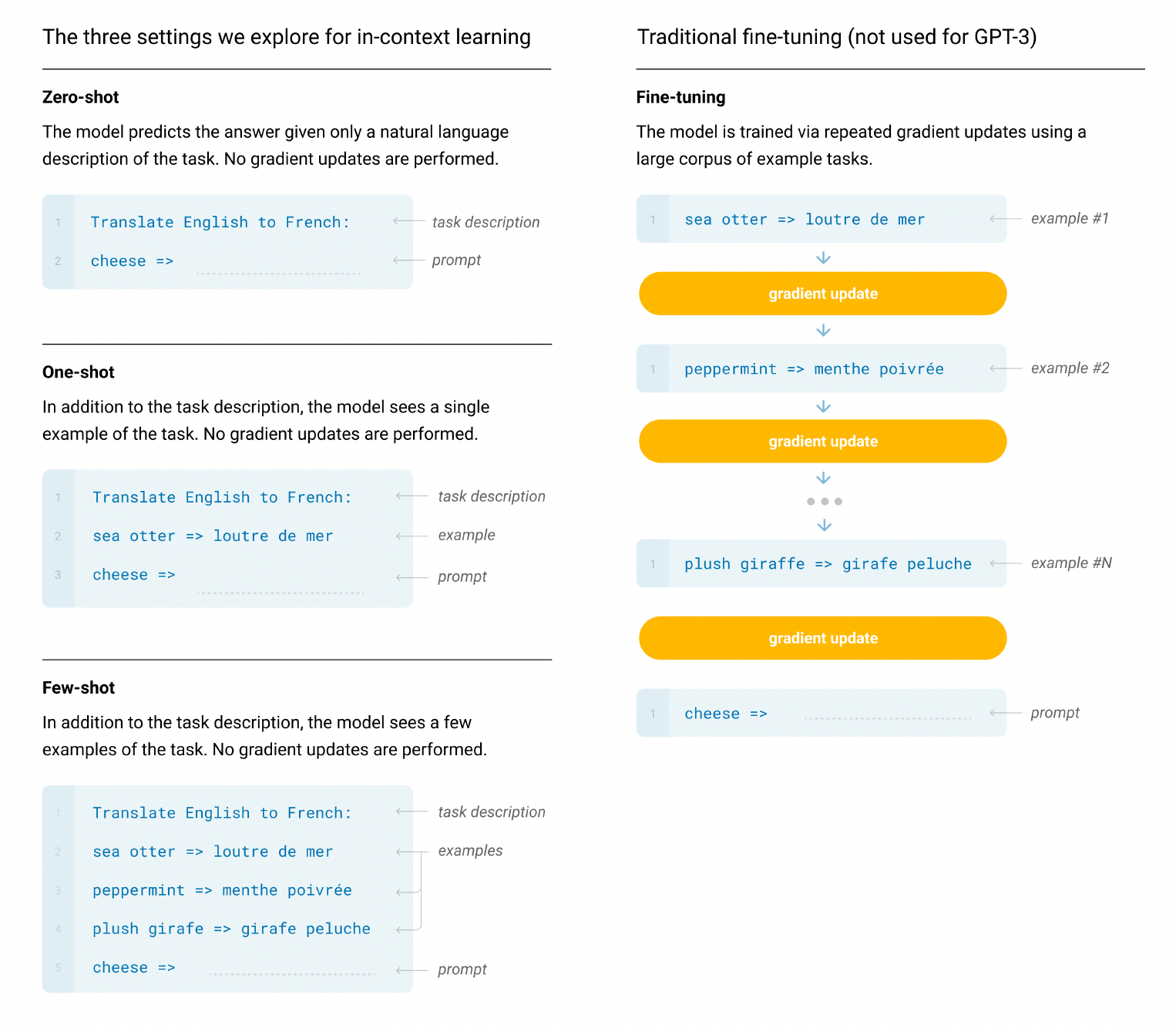
기본적인 사전학습 접근법(모델, 데이터, 훈련)은 GPT-2와 유사하다. 다만 모델 크기, 데이터셋 크기 및 다양성, 훈련 길이의 확장 작업이 추가되었다. In-context 학습법도 GPT-2와 비슷하다. 본 논문에서는 GPT-3을 평가하는 조건을 다음과 같이 네 가지로 세분화하여 제시한다.
1) Fine-Tuning(FT) : 다운스트림 작업에 특화된 지도 학습 데이터셋으로 사전 학습된 모델의 가중치를 업데이트하는 방법이다. 보통 수천~수만개의 라벨링 된 데이터를 사용한다. 이 방법은 성능 향상에 크게 도움되지만, 매 태스크마다 대규모 데이터셋이 필요하다는 단점이 있다.
2) Few-Shot(FS) : 모델은 추론 과정에서 예시 작업 몇가지를 제공 받지만, 가중치 업데이트는 허용되지 않는다. 예제는 예를들어, 영어->프랑스어 번역 작업이라고 가정할 때, 영어 문장과 번역된 프랑스어 문장 결과를 포함한다. 또한 모델이 완성할 것이라고 기대하는 마지막 예제를 제시해준다. 일반적으로 K개의 예제는 10에서 100사이로 설정하며 이는 모델의 context window에 맞는 크기이다. 하지만, 대부분의 모델에서 few-shot learning의 성능은 fine-tuning 결과를 따라가지 못한다.
3) One-Shot(1S) : FS 세팅과 같으나, 하나의 예제만을 예시로 준다.
4) Zero-Shot(0S) : 태스크에 대한 예제 없이, 태스크 지시어만 제공한다.
2.1 Model and Architectures
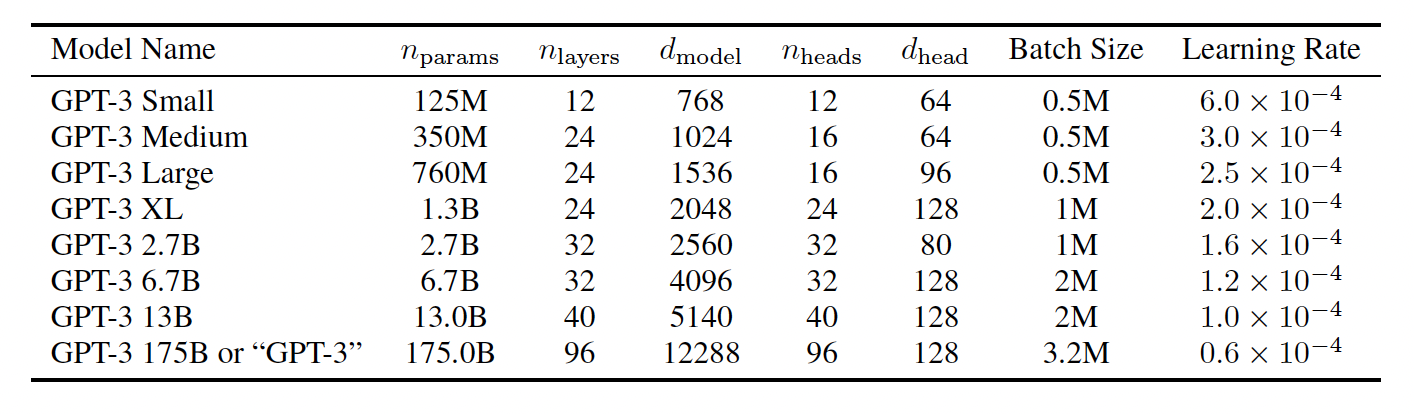
-
모델 아키텍처
-
GPT-2와 기본적으로 동일(modified initialization, pre-normalization, reversable tokenization)
-
트랜스포머 레이어의 attention 패턴에 대해 dense와 locally banded sparse attention을 번갈아 사용
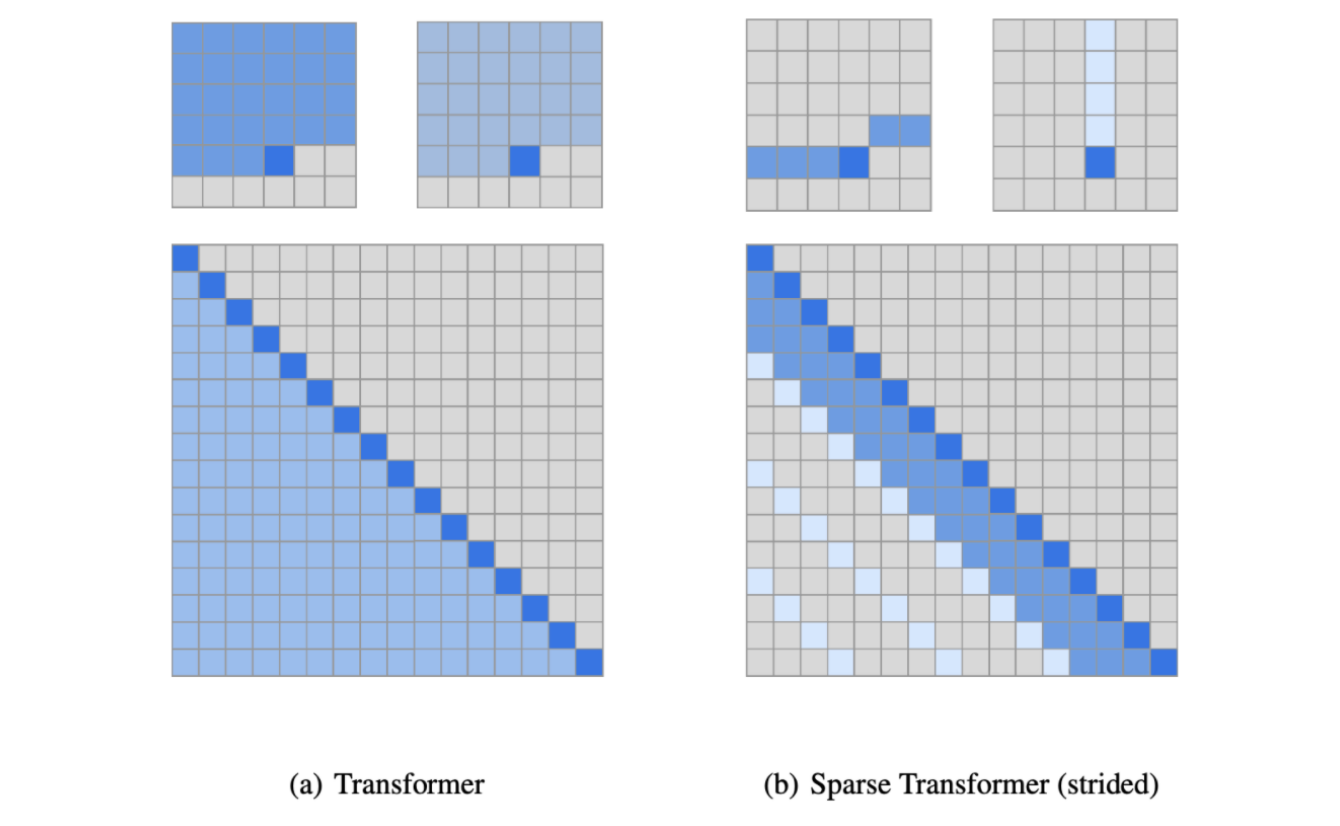
-
-
모델 크기 스케일링:
- 1억 2500만 ~ 1,750억 파라미터의 8가지 모델 훈련
- 가장 큰 모델이 GPT-3
-
연구 목적:
- 모델 크기와 성능간의 관계 탐구
-
모델 배치:
- 모델을 너비와 깊이 차원으로 GPU에 분할
- 계산 효율성과 로드 밸런싱 고려하여 아키텍처 매개변수 선택
2.2 Training Dataset
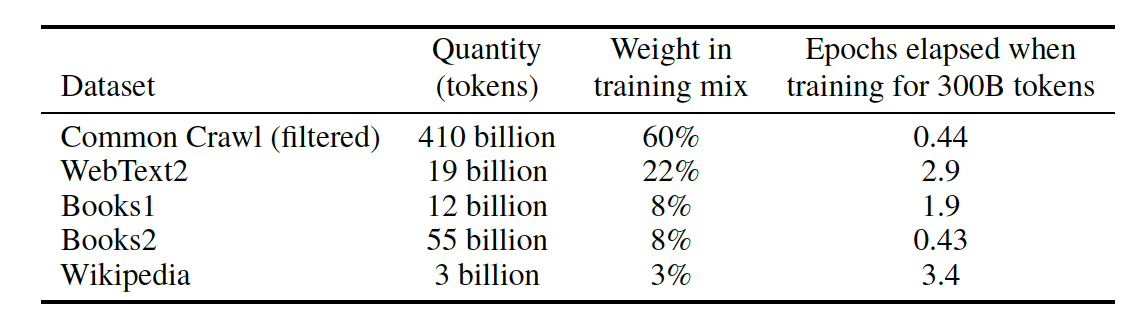
학습의 주가 되는 데이터셋은 Common Crawl 데이터이다. 해당 데이터는 양적인 측면에서는 훌륭하지만 몇가지 정제 과정을 필요로 한다.
-
low-quality filtering
1) WebText를 high-quality document로 labeling
2) Common Crawl을 low-quality document로 labeling해 데이터셋을 구축
3) 이를 분류하는 classifier를 학습
4) classifier를 사용해 Common Crawl 중 high-quality로 분류되는 데이터만 필터링 -
fuzzy deduplication
n-gram 단위로, 다른 데이터와 겹치는 데이터는 삭제한다. 이를 통해 data contamination과 overfitting을 방지할 수 있다.
최종적으로, 45TB를 570GB(400B BPE Tokens) 정도로 줄였다.
다만, 이 데이터를 그대로 사용한 것이 아니라 crawling 데이터셋의 단점을 보완하기 위해 다른 고품질의 데이터셋을 섞어서 데이터셋을 구축한다. 이때, 가중치를 두어, 깔끔한 데이터셋이 실제 양에 비해 상대적으로 높은 빈도로 학습되도록 한다.
-
데이터 샘플링 방식:
- 데이터셋 크기에 비례하지 않음
- 품질이 높다고 판단되는 데이터셋 더 자주 샘플링(더 높은 품질의 훔련 데이터를 얻기 위해 약간의 과적합 수용)
- Common Crawl 과 Book2 데이터셋은 샘플링 X, 그외 데이터셋은 2-3회 샘플링
-
데이터 오염 문제:
- 벤치마크의 개발 및 테스트 세트와의 중복 제거 노력
- 필터링 과정의 버그로 일부 중복 남음
- 향후 연구에서 더 적극적인 데이터 오염 제거 계획
3. Result
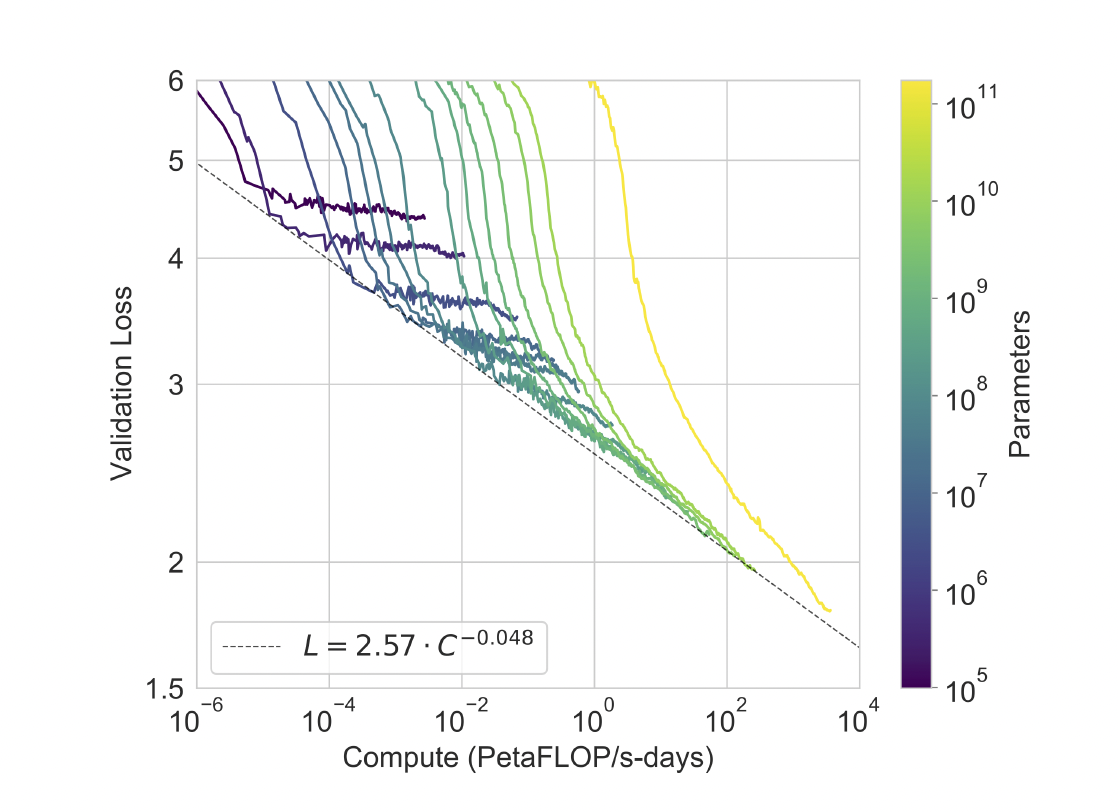
위 그림은 스케일에 따른 8개의 모델에 대한 훈련 곡선을 나타낸다. 그래프에 표시된 곡선들이 일정한 패턴을 따르고 있는데 이 패턴을 power-law라고 한다. power-law에 따르면 더 많은 컴퓨팅 파워를 사용하면 성능이 향상된다는 것을 알 수 있다.
그래프에서 보라색에서 노란색으로 이어지는 곡선들은 다양한 크기의 모델들을 나타내는데, 노란색으로 갈수록 더 큰 모델임을 나타낸다. 큰 모델일수록 더 많은 컴퓨팅 파워를 사용해도 계속해서 성능이 향상되는 것을 볼 수 있다.
평가 범위:
- 8개의 주요 모델(GPT-3 포함)을 다양한 데이터셋에서 평가
- 데이터셋을 9개의 유사한 작업 범주로 그룹화
평가 방식:
- 모든 작업을 few-shot, one-shot, zero-shot 학습 설정에서 평가
3.1 Language Modeling, Cloze, and Completion Tasks
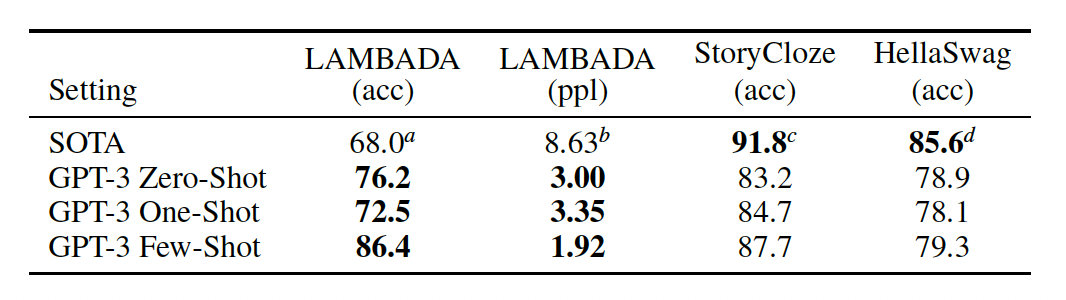
이 섹션에서는 전통적인 언어 모델링 작업과 단어 예측, 문장이나 단락 완성, 또는 텍스트 조각의 가능한 완성 중 하나를 선택하는 작업에서 GPT-3의 성능을 테스트한다.
1) Language Modeling
- PTB에서 20.50 퍼플렉시티로 15포인트 차이로 새로운 SOTA(최첨단 성능)를 달성
- PTB는 전통적인 언어 모델링 데이터셋이기 때문에 원샷이나 몇 가지 예제 학습을 평가할 명확한 분리가 없어, 제로샷으로만 측정
2) LAMBADA
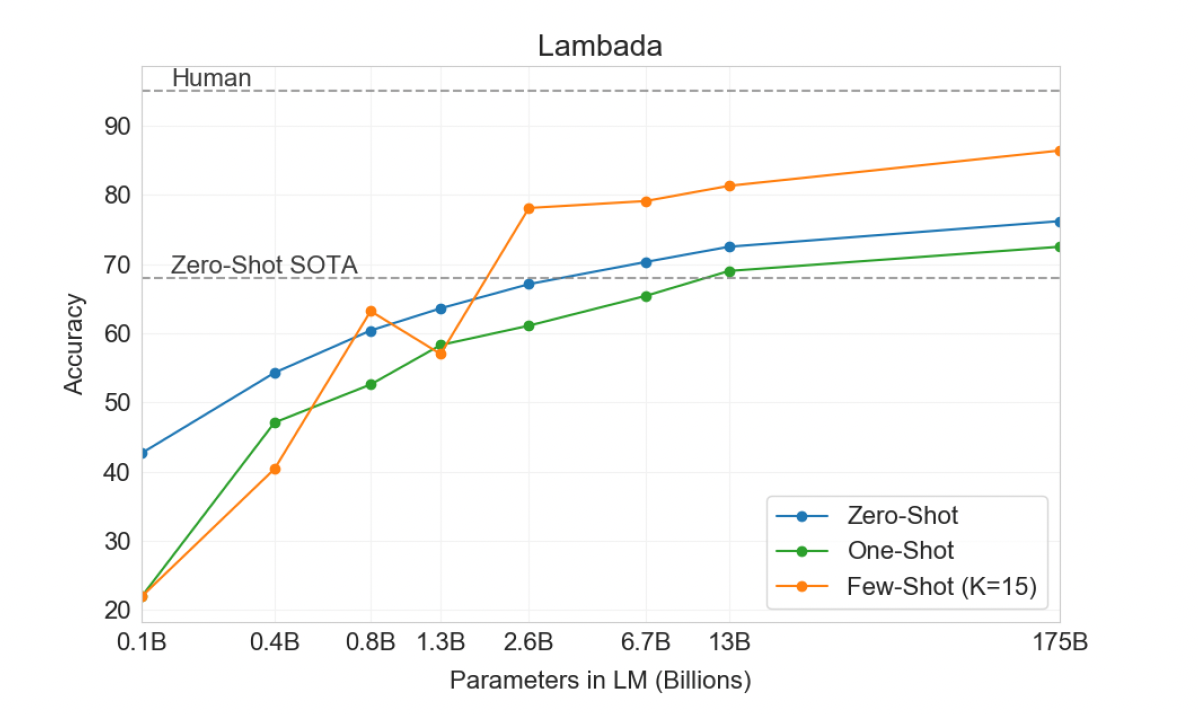
- 언어의 장기 의존성을 모델링하는 태스크
- 모델은 아래 예문과 같이 문단을 읽고 나서 문장의 마지막 단어를 예측하도록 요청받는다.
- GPT-3는 LAMBADA 데이터셋에서 제로샷 설정으로 76% 정확도를 달성하여 이전 최고 성능보다 8% 향상

3) HellaSwag
- 짧은 글이나 지시사항을 끝맺기에 가장 알맞은 문장을 고르는 태스크
- GPT-3는 one-shot 설정에서 78.1%, few-shot 예제 학습 설정에서 79.3%의 정확도를 달성
- 미세 조정된 다중 작업 모델 ALUM이 달성한 전체 SOTA(최첨단 성능)인 85.6%보다는 낮음
4)StoryCloze
- 다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 태스크
- GPT-3는 zero-shot 설정에서 83.2%, few-shot 예제 학습 설정에서 87.7%(K = 70) 정확도 달성
- BERT 기반 모델을 사용한 미세 조정된 SOTA보다 여전히 4.1% 낮지만, 이전 제로샷 결과보다 약 10% 향상
3.2 Closed Book Question Answering
-
GPT-3가 폭넓은 사실 기반의 지식에 대한 질문에 답변할 수 있는지 측정
-
open-domain QA 형태의 태스크에 대해 closed-book 테스트를 진행
-
Natural Questions
- 위키피디아에 대해 fine-grained 지식을 요구하는 task
- 14.6% (zero-shot), 23.0% (one-shot), 29.9% (few-shot)
- sota: 36.6% for fine-tuned T5 11B+SSM.
-
WebQuestions
- 14.4% / 25.3% / 41.5%
- sota: 44.7% for fine-tuned T5-11B+SSM
-
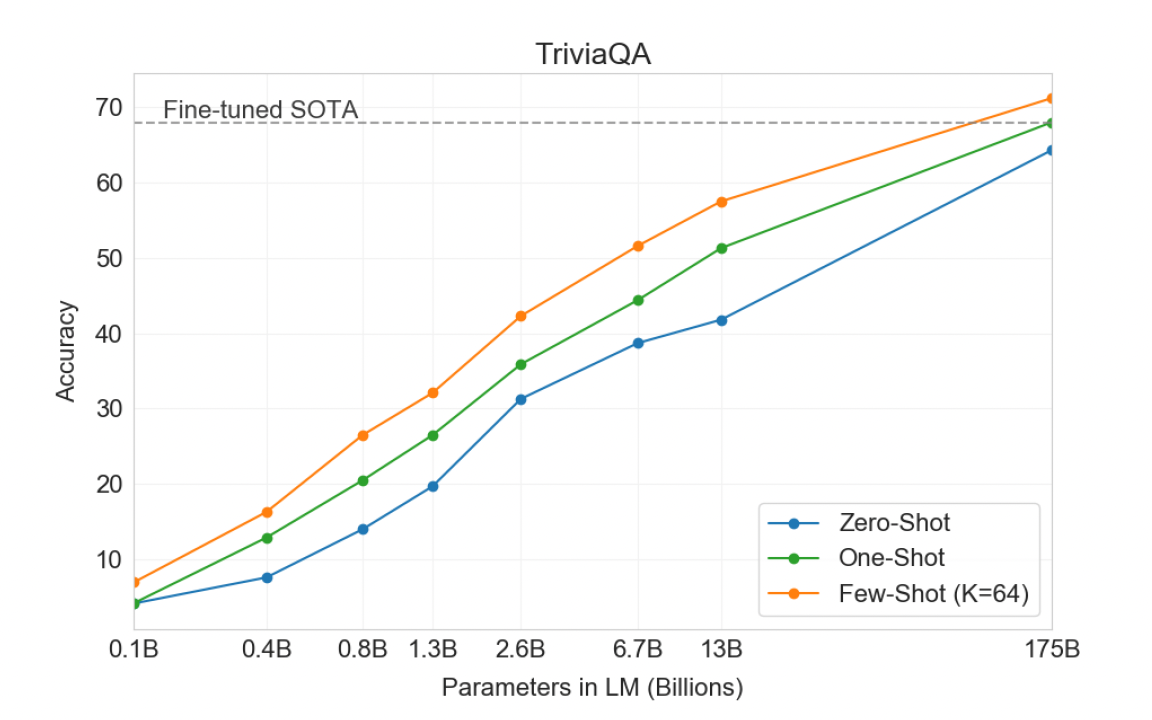
TriviaQA
- SOTA 달성
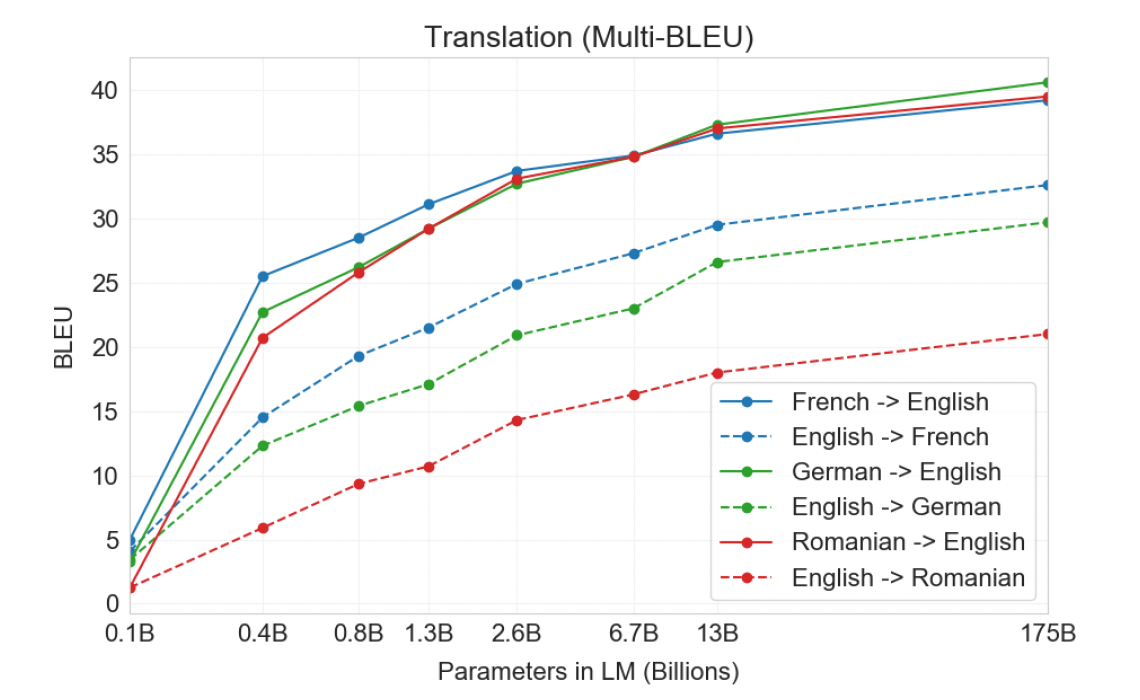
3.3 Translation
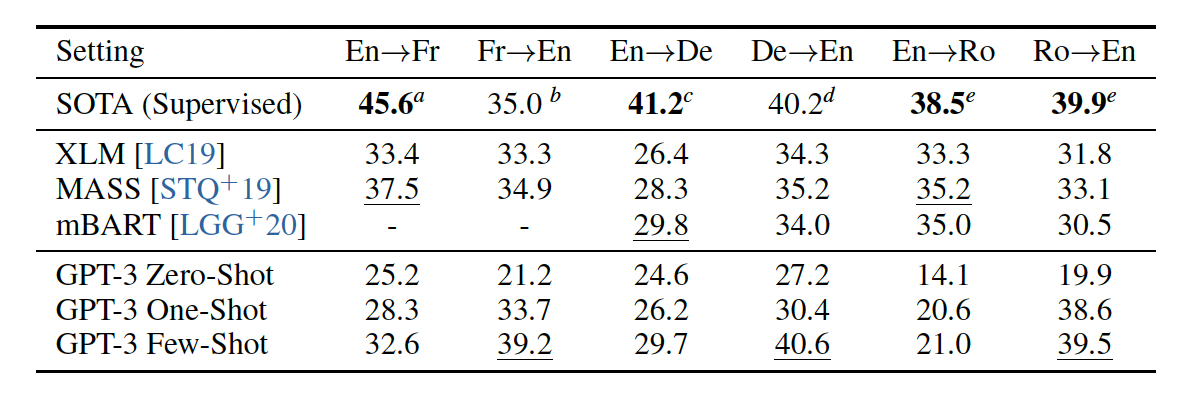
- GPT-3의 다국어 번역 능력을 평가했으며, 특히 프랑스어, 독일어, 루마니아어와 영어 간의 번역을 중점적으로 살펴봄
- 특별한 번역 훈련 없이, 다국어가 혼합된 데이터로 학습
- zero-shot 설정에서 GPT-3의 번역 성능은 기존 비지도 학습 방식보다 낮았지만, one-shot 설정만으로도 성능이 크게 향상
- few-shot 예제 학습 설정에서 GPT-3는 기존 비지도 학습 기계 번역 연구와 유사한 평균 성능을 달성
- GPT-3는 특히 외국어에서 영어로의 번역에서 뛰어난 성능을 보였으며, 일부 경우 최고의 지도 학습 결과를 능가
- 영어에서 다른 언어로의 번역은 상대적으로 성능이 낮음
4. Measuring and Preventing Memorization Of Benchmarks
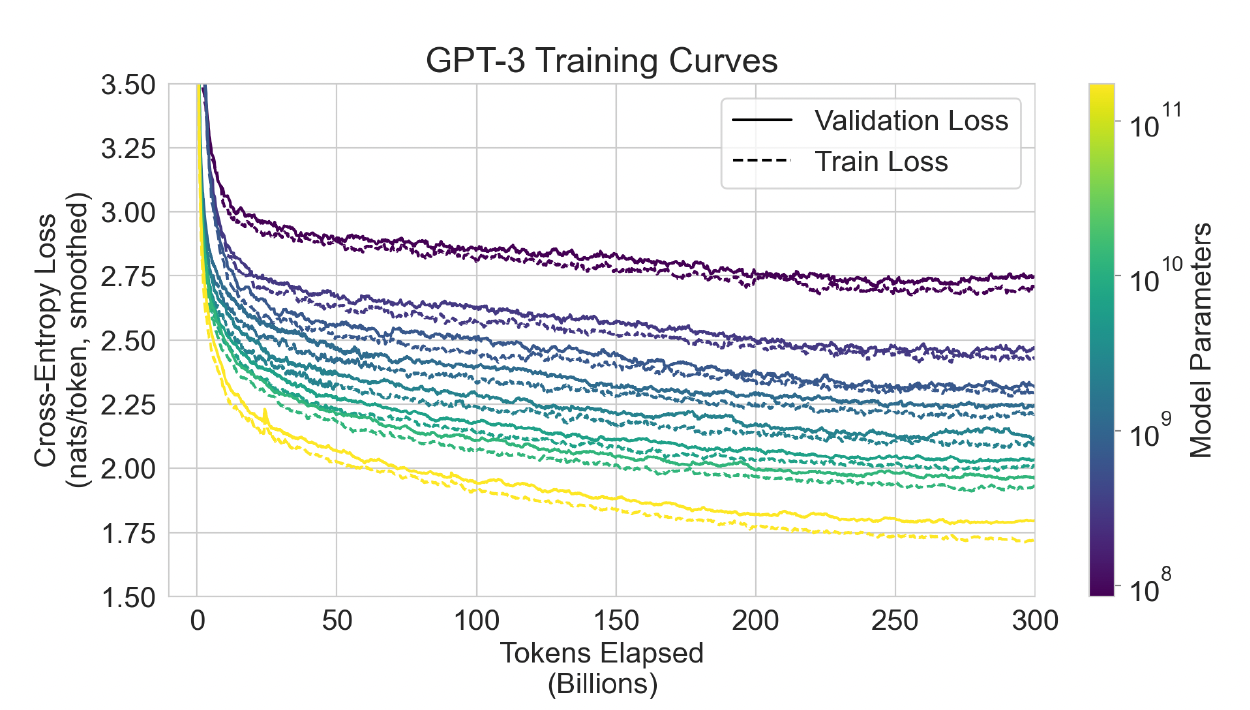
훈련 데이터셋은 인터넷에서 수집되었기 때문에, 모델이 테스트 데이터셋 중 일부를 훈련 데이터로 사용했을 가능성이 있다. 사전 학습 데이터셋의 규모가 커짐에 따라 데이터 오염 감지의 중요성은 점점 더 중요해지고 있다. 그러나 GPT-3의 경우 데이터의 양이 매우 많아 훈련 데이터셋에 과적합되지 않았으며 이는 위 그림에서 확인할 수 있다. 따라서 오염이 빈번할 가능성은 있지만, 그 영향은 크지 않다고 예상된다.
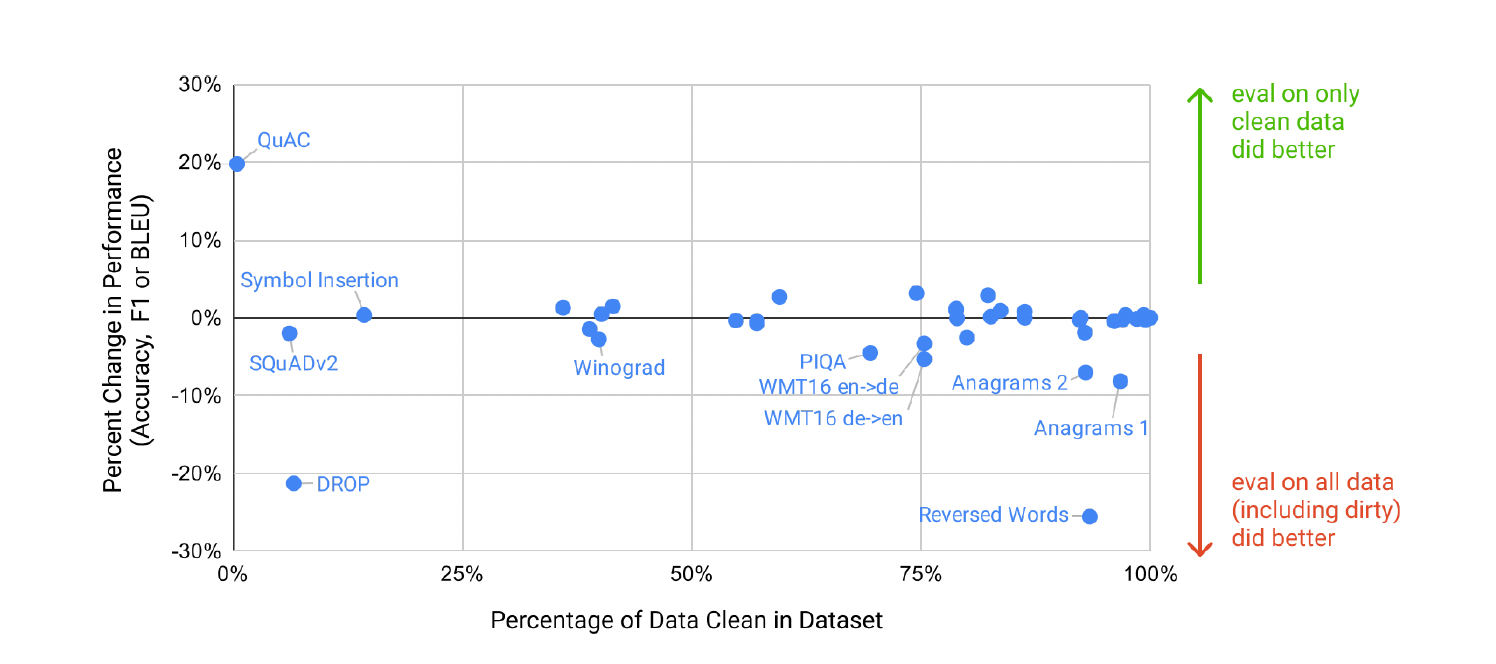
위 그래프는 GPT-3 모델을 평가할 때 사용된 데이터셋 중 일부가 훈련 데이터와 중복되어 성능에 영향을 미쳤을 가능성을 조사한 결과를 보여준다. 각각의 벤치마크에 대해 사전학습 데이터와 13-gram(13개 단어) 중복이 있는 예제 데이터를 삭제하는 clean버전의 테스트 셋을 생성하여 benchmark로 두고 평가를 진행한 후 원래 점수와 비교한다. 위의 그림에서도 볼 수 있듯이 대부분의 데이터셋에서 cleansing 후 성능 변화는 미미하다. 즉, 일부 데이터에서 테스트 데이터셋이 훈련 과정에서도 사용되는 오염이 있을 수는 있으나 성능에 영향을 거의 미치지 않는 것으로 보아, 모델이 사전학습을 통해 테스트 데이터셋을 "외움"으로써 성능이 높아진 것은 아니라는 것이다.
5. Limitations
- 텍스트 생성의 한계
- 문서 수준의 의미적 반복
- 긴글의 가독성 저하
- 모순되거나 비논리적인 내용 생성 등
-
양방향 태스크에서의 성능 저하
- 두 문장에서 단어의 사용을 비교하는 작업(WIC)
- 한 문장이 다른 문장을 암시하는지 비교하는 작업(ANLI)
- 독해 작업(예: QuAC 및 RACE)
-
본질적 한계
- 자기 지도 학습(self-supervised) 목표에서는 원하는 작업을 예측 문제로 강제하는 반면, 언어 시스템은 궁극적으로 '목적 지향적'으로 액션을 취할 수 있어야 하고, 단순히 예측하는 것을 넘어서야 한다.
- 큰 규모의 사전학습 모델은 동영상이나 실제 물리 세상에서의 상호작용 등에서는 적용된 바가 없다. 따라서 세상에 대한 방대한 양의 컨텍스트가 부족할 수 있는데, 이러한 이유로 self-supervised 예측에는 단순히 규모만 키우는 것이 아닌 다른 접근법이 필요할 것이다.
-
학습 효율성 문제
- GPT-3는 추론시에는 인간처럼 몇개의 예제만으로 문제를 풀 수 있지만, 사전학습 과정에서는 방대한 양의 데이터를 봐야한다.
- 사전학습 시 하나의 샘플이 모델에게 주는 정보에 대한 효율성을 높이는 것은 중요한 연구 과제이다.
-
few-shot 셋팅의 불확실성
- few-shot learning이 추론 시에 새로운 태스크를 새롭게 배우는 것인지 아니면 훈련하는 동안 배운 태스크 중 하나를 인식해서 수행하는지는 정확히 알 수 없다.
-
비용 문제
- 대규모 모델은 추론 비용이 많이들기에 모델을 압축(distillation)하는 것은 새로운 연구 과제이다.
-
해석 가능성
- GPT-3는 대부분의 딥러닝 시스템과 마찬가지로 추론 과정을 쉽게 해석할 수 없다.
- 새로운 입력에 대한 예측이 잘 조정되 지 않을 수 있다.
- 표준 벤치마크에서 인간보다 훨씬 높은 성능 변동성을 보이는 것으로 관찰되었다.
- 훈련 데이터의 편향을 유지하고 있다.
- 데이터의 편향이 모델이 고정관념적이거나 편견을 가진 콘텐츠를 생서하게 만들 수 있다는 사회적 우려가 있다.
6. Broader Impacts
NLP 모델은 코드 작성, 검색 엔진 개선 등 유익한 응용 프로그램에 적용 가능하다. 하지만 모델이 발전한 만큼 잠재적으로 악용될 가능성이 있기에 잠재적 해악을 연구하고 완화하려는 노력이 필요하다.
6.1 Misuse of Language Models
1) Potential Misuse Applications
- hallucination issue
2) Threat Actor Analysis
- advanced persistent threats (APTs): 지능형 지속 공격
- APT는 원하는 정보를 얻기 위해 악성코드, 피싱, 소셜 엔지니어링 등 다양한 공격 방식을 이용 하는 것이다.
3) External Incentive Structures
- 사용이 쉬워지고, 비용이 낮아지기 때문에, APT들의 사용을 유도할 수 있다.
6.2 Fairness, Bias, and Representation
1) Gender

- 모델이 성별과 직업의 편향을 가지는지 확인
- GPT-3는 388개 직업 중 83%에 대해 남성과 관련된 어휘를 선택한 것으로 나타났다.
2) Race
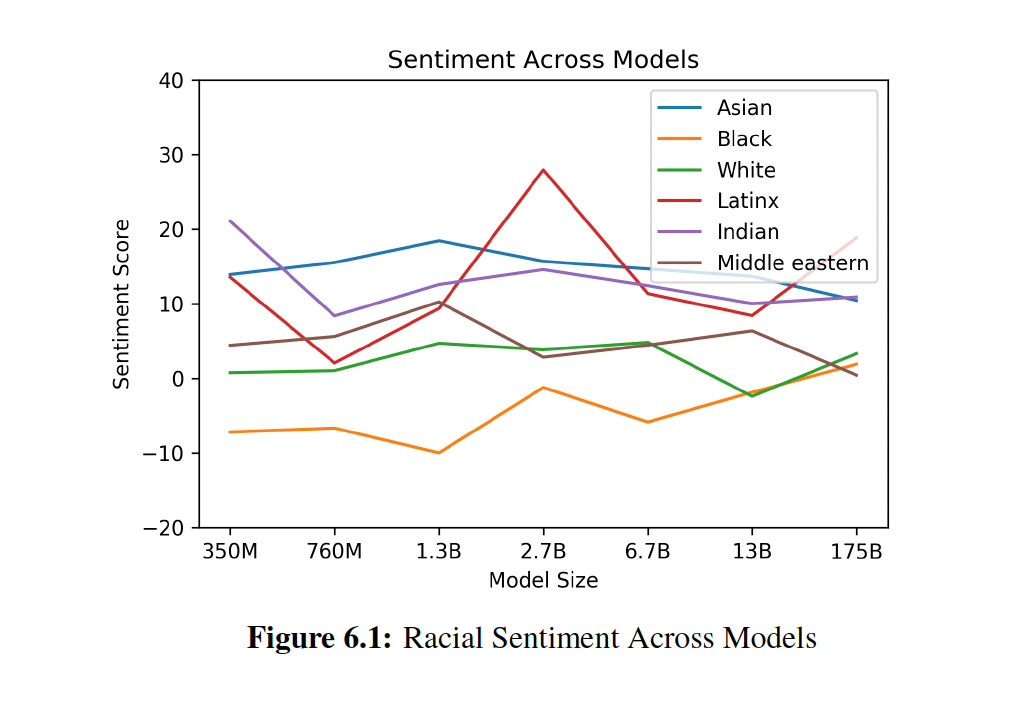
- 모델이 인종에 대한 편견을 가지고 있는지 확인
- '아시안' 인종에 대해서는 7개 모델 중 3개가 일관적으로 긍정 점수가 높은 결과를 보였다. 반면에 7개 모델 중 5개 모델이 '흑인'과 관련하여 일관적으로 부정 점수가 높은 결과를 나타냈다.
3) Religion
- 지역적 편향 반영 여부 확인
- violent, terrorism, terrorist 같은 단어를 이슬람교와 연관짓는다는 것을 확인할 수 있었다.
느낀점
GPT-3는 언어 모델의 한 종류에 그치지 않고 NLP의 새로운 패러다임을 제시했다고 해도 과언이 아니다. 연구 성과 뿐만 아니라 향후 연구 방향을 제시해주었고 GPT-4 등 현재 그 방향에 맞게 연구 성과들이 나오고 있다는 점도 주목할만하다. 또한 연구 성과에도 불구하고 모델의 편향 문제와 추론 과정의 복잡성 등 해결해야 할 문제들을 명확히 보여준다는 점도 인상 깊었다.
Reference
https://littlefoxdiary.tistory.com/44
https://velog.io/@tobigs-nlp/
https://ffighting.net/
