Abstract
- 헌법적 AI(Constitutional AI)
- 인간의 라벨링 없이 AI가 스스로 개선하며 유해하지 않은 AI 어시스턴트를 훈련하는 방법
- CAI(Constitutional AI) 과정
1) 지도 학습 단계: AI가 자체 출력을 비판하고 수정하여 모델을 미세 조정
2) 강화 학습 단계: AI가 출력의 품질을 평가하고, 이를 바탕으로 강화 학습을 수행(RLAIF: RL from AI Feedback)
- 결과적으로 유해하지 않으면서도 회피적이지 않은 AI 어시스턴트가 생성되고 이 AI는 유해한 요청에 대해 반대 의견을 설명할 수 있음
- 연쇄적 사고(chain-of-thought) 추론을 활용하여 AI 의사 결정의 성능과 투명성 개선
1. Introduction
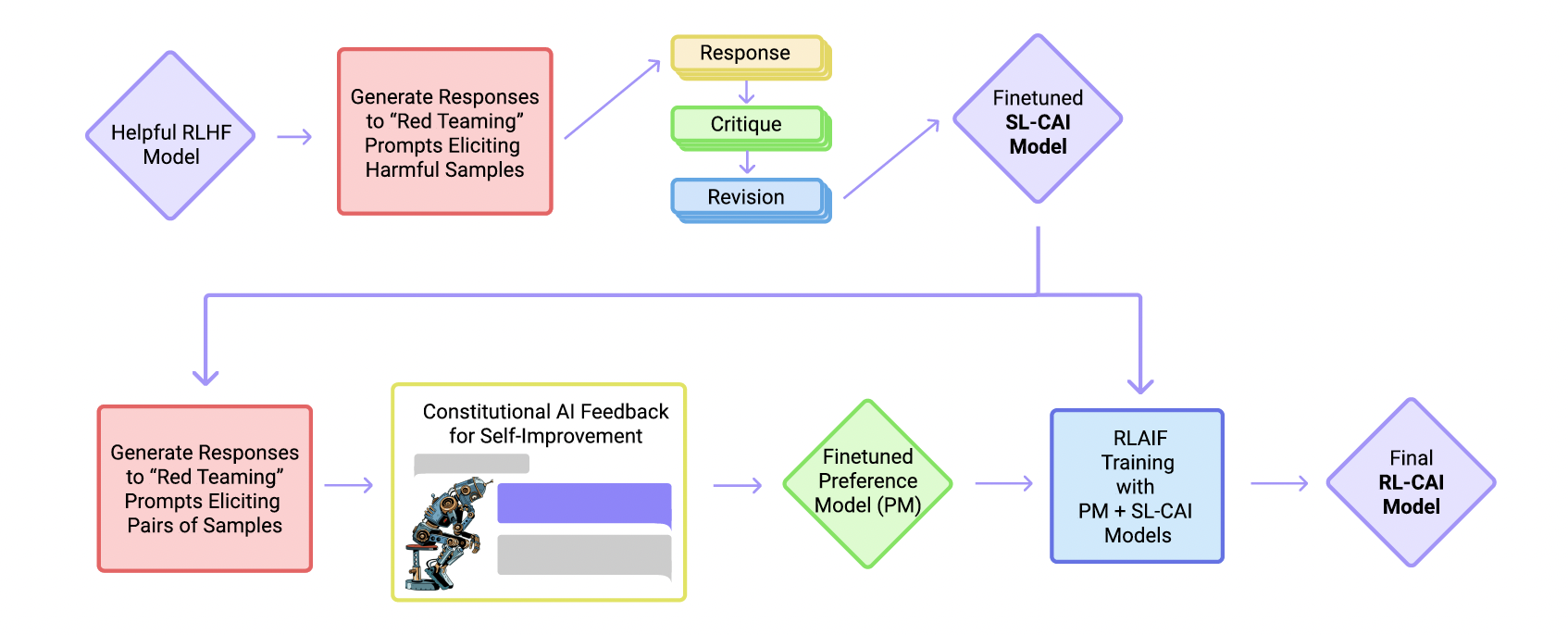
헌법적 AI(Constitutional AI, CAI)의 핵심 내용
-
목적: 인간의 직접적인 감독 없이도 도움이 되고, 정직하며, 해롭지 않은 AI 어시스턴트를 훈련하는 것
-
방법:
- 짧은 원칙이나 지침 목록(Constitution)을 사용
- 인간의 유해성 라벨 없이 AI가 자체적으로 개선
-
장점:
- 기존 RLHF(Reinforcement Learning from Human Feedback) 방식보다 RL-CAI가 크라우드 워커들에게 더 선호됨
- 회피적이지 않으면서도 유해하지 않은 응답 생성
- AI 행동 통제 원칙의 투명성 향상
- 목표 변경 시 새로운 인간 피드백 라벨 수집 불필요
-
동기:
- AI를 이용한 AI 감독 연구
- 유해하지 않으면서도 도움이 되는 AI 개발
- AI 의사결정의 투명성 증대
- 인간 피드백 라벨 수집 과정을 생략함으로써 AI 훈련 및 개선 과정의 효율성 향상
1-1. Motivations
Scaling Supervision
-
정의: 인간이 AI를 보다 효율적으로 감독할 수 있도록 AI를 활용하는 기술
-
장점:
- AI 감독의 효율성 향상
- 인간-AI 협력을 통한 감독 품질 개선
- 고성능 AI 시스템에 대한 적절한 감독 가능성
-
접근 방식:
- 약 10개의 간단한 자연어 원칙만을 사용해 AI 모델 무해하게 미세 조정
- 연쇄적 사고(chain-of-thought) 추론을 통한 의사결정 투명성 확보
-
주의점:
- 결정의 자동화와 불투명성 증가 위험성이 수반될 수 있기에 CAI 방식은 연쇄적 사고(chain-of-thought) 추론을 활용하여 의사 결정을 보다 명확하게 만듦
-
목표: 궁극적으로 인간 감독을 가능한 한 효과적으로 만드는 것
A Harmless but Non-Evasive (Still Helpful) Assistant
-
무해한 AI가 종종 쓸모없거나 회피적인 경향 존재
-
유용성과 무해성 사이의 긴장 존재
ex) 불쾌한 질문을 접한 후에는 나머지 대화에서 회피적인 답변만 반복하는 경우 발생 -
유용하고 무해하면서도 회피적이지 않은 AI 어시스턴트 개발 필요
-
개선 방향:
- 비윤리적 요청 시 거절 이유 설명
- 대화 참여도 유지
- 불쾌한 언어나 감정 표현 자제
-
기대 효과:
- 유용성과 무해성 사이의 균형 개선
- 자동화된 'red teaming' 확장 (무해성 과도 훈련 시 유용성 상실 위험 방지)
Simplicity and Transparency
-
기존 RLHF 방법의 한계:
- 대량의 인간 피드백 라벨 필요
- 라벨의 비공개성 또는 과도한 정보량으로 인한 이해 어려움
-
개선 목표: AI 훈련 과정의 단순화와 투명성 향상
-
제안된 개선 방법:
- 자연어로 된 간단한 지침/원칙 목록 사용
- 연쇄적 사고 추론을 통한 AI 의사결정 과정 명확화
- 유해 요청 거절 이유를 설명하는 AI 훈련
-
기대 효과:
- AI 훈련 목표의 명확한 이해 가능
- AI 의사결정 과정의 투명성 증가
- 유해성 판단 기준의 명확화
1-2. The Constitutional AI Approach
인간의 직접적인 감독을 최소화하면서 안전하고 유용한 AI 어시스턴트를 훈련하는 새로운 방법인 '헌법적 AI(Constitutional AI, CAI)'를 제안한다. 이 접근법의 핵심은 AI의 행동을 통제하는 원칙들을 '헌법'으로 정의하고, 이를 기반으로 AI를 훈련시키는 것이다.
CAI의 훈련 과정은 크게 두 단계로 나뉜다.
-
지도 학습 단계: 비판(Critique) → 수정(Revision) → 지도 학습(Supervised Learning)
- 목적: AI의 응답 분포를 원하는 방향으로 조정
1) 유해한 질문에 대한 초기 응답 생성
2) Constitution 에 따라 자체 응답 비판
3) 비판을 바탕으로 응답 수정 (여러 차례 반복)
4) 최종 수정된 응답으로 언어 모델 미세 조정
- 목적: AI의 응답 분포를 원하는 방향으로 조정
-
강화 학습 단계: AI 비교 평가(AI Comparison Evaluations) → 선호 모델(Preference Model) → 강화 학습(Reinforcement Learning)
- 목적: AI의 성능을 세밀하게 개선
1) 유해한 질문에 대해 두 가지 응답 생성
2) 헌법 원칙에 따라 더 나은 응답 선택 (AI 비교 평가)
3) AI 선호 데이터셋 생성 및 인간 피드백과 혼합- AI 평가 데이터셋: 유해하지 않은 답변
- 인간 피드백: 유용한 답변
5) PM을 기반으로 강화 학습 수행
- 목적: AI의 성능을 세밀하게 개선
이 방법의 주요 특징은 다음과 같다:
1. 인간 감독 최소화: 소수의 원칙과 예시만으로 AI 훈련
2. 투명성 향상: 자연어로 된 간단한 원칙 사용
3. 유용성과 안전성 균형: 회피적이지 않으면서도 안전한 응답 생성
4. 효율성: 지도 학습 단계를 통해 강화 학습의 탐색 필요성 감소
1-3. Contributions
-
AI의 유해성 식별 능력 향상:
- 언어 모델의 성능이 향상될수록 유해성 식별 능력도 크게 개선됨
- 연쇄적 사고 추론(chain-of-thought reasoning) 적용 시 더욱 향상됨
- 인간 피드백 기반 모델과 비슷한 수준의 평가 결과 도출
-
점진적 유해성 감소 방법:
- AI가 생성한 비판과 수정을 반복 적용하여 유해성 점진적 감소
- 직접 수정보다 비판 생성이 무해성 개선에 더 효과적
- 이전 연구에서 발견된 AI의 회피성 문제 해결
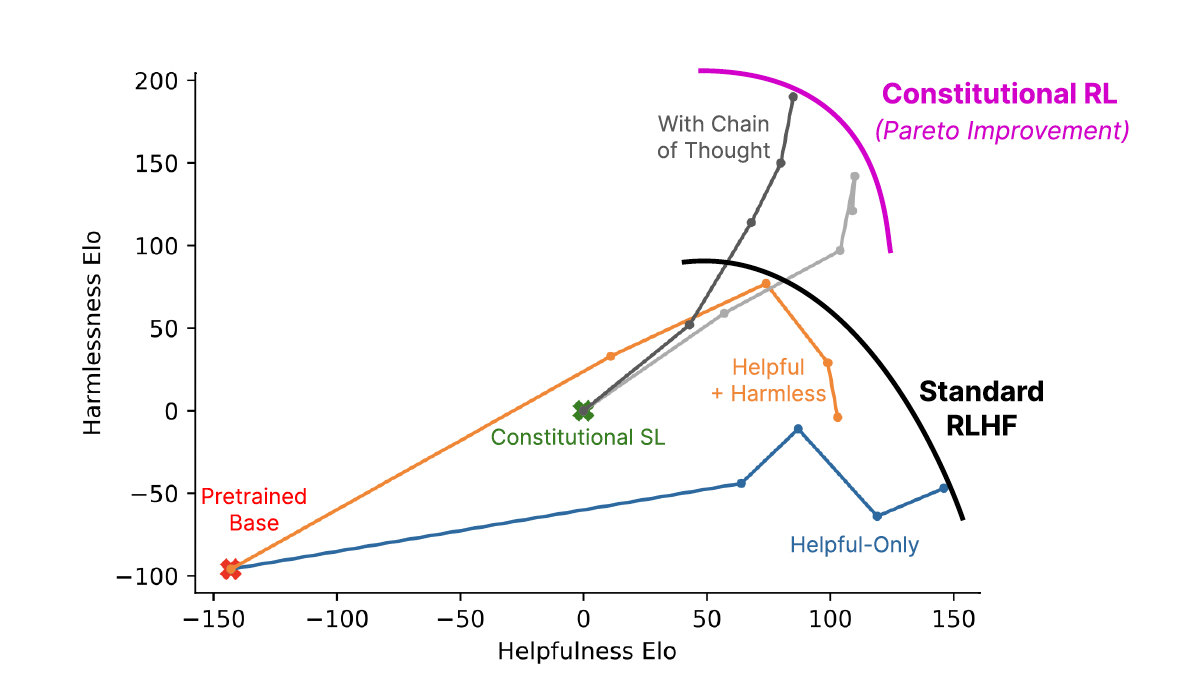
-
자체 감독 강화학습의 효과:
- AI가 생성한 선호 라벨을 사용한 강화학습이 모델 행동 개선
- 크라우드 워커 평가에서 우수한 성과 달성
- 유해성 평가에서 인간 피드백 사용과 동등하거나 더 나은 결과
-
투명성과 재현성 향상:
- 다양한 few-shot 프롬프트와 헌법적 원칙 공개
- 모델의 다양한 프롬프트 응답 결과를 포함한 GitHub 저장소 제공
1-4 Models and Data
-
초기 모델 훈련:
- 방법: 인간 피드백을 활용한 강화학습(RLHF)
- 데이터: 도움이 되는 인간 피드백(HF) 데이터만 사용
-
비교 모델:
- 새로운 선호 모델
- 도움과 무해성을 모두 갖춘 RLHF 정책 모델
- 이 모델들도 인간 피드백으로 훈련됨
-
데이터 수집 방법:
- 각 데이터 샘플은 프롬프트와 모델이 생성한 두 가지 응답 쌍으로 구성
- 크라우드 워커는 과제에 따라 더 도움이 되거나 무해한 응답에 라벨을 붙임
- 'helpfulness data'와 'harmlessness data' 별도 수집
- red team: 크라우드 워커가 모델의 유해한 응답을 유도하는 프롬프트 작성
- RLHF로 훈련된 두 가지 모델:
- 'helpfulness data'로만 훈련한 모델
- HH 모델: 도움과 무해성을 모두 갖춘 모델
2. Evaluating the Potential for AI Supervision of HHH

이 연구는 대형 언어 모델의 HHH(유용성, 정직성, 무해성) 감독 능력을 평가한다. 주요 실험 과정과 결과는 다음과 같다.
-
데이터셋 구성:
- 기존 221개의 이진 비교 데이터셋 사용
- 추가로 217개의 더 어려운 비교 데이터 작성 (무해성에 대한 미묘한 테스트 포함)
-
평가 방법:
a) 선호 모델 평가:- 인간 선호 라벨로 훈련된 선호 모델(PM)의 정확도 측정
b) 이진 선택 문제:
- 사전 학습된 언어 모델 또는 유용한 RLHF 정책으로 직접 답변 평가
-
연쇄적 사고 추론(CoT) 적용:
- 큰 모델에서 성능 크게 향상
- 5개의 CoT 샘플 생성 및 평균화로 추가 성능 향상
-
추가 평가:
- 유해성 중심의 이진 선택 평가 수행
- [Ganguli et al., 2022] 데이터셋 사용
-
주요 결과:
- 모델들이 90% 이상의 이진 정확도로 더 나은 응답 예측 가능
- 언어 모델이 유해한 행동 식별 및 유형 분류 가능
- 대형 언어 모델의 성능이 크라우드 워커의 성능에 근접
3. Constitutional AI: Critiques, Revisions, and Supervised Learning
3-1 Method

이 연구는 인간의 유해성 피드백 없이 유용하고 무해한 AI 모델을 구축하는 방법을 제시한다.
-
초기 설정:
- 도움을 주는 RLHF 모델 사용
- '레드 팀 작업'을 통해 얻은 유해한 프롬프트 활용
-
헌법적 원칙 적용:
- 16개의 유해성 관련 원칙 작성
- 각 수정 단계에서 원칙 무작위 샘플링
-
비판-수정 파이프라인:
- 모델이 자신의 응답을 비판하고 수정
- 여러 번의 수정을 통해 유해 콘텐츠 제거
- Few-shot 프롬프트로 관점 혼동 문제 해결
-
모델 미세 조정:
- 수정된 응답으로 사전 학습 모델 미세 조정
- 유용성 유지를 위해 RLHF 모델의 유용한 응답도 포함
-
결과 분석:
- 첫 번째 수정으로 대부분의 유해성 제거
- 수정된 응답이 회피적이지 않음 확인
- 'SL-CAI'로 명명된 모델 생성
3-2. Datasets and Training
3-3. Main Results
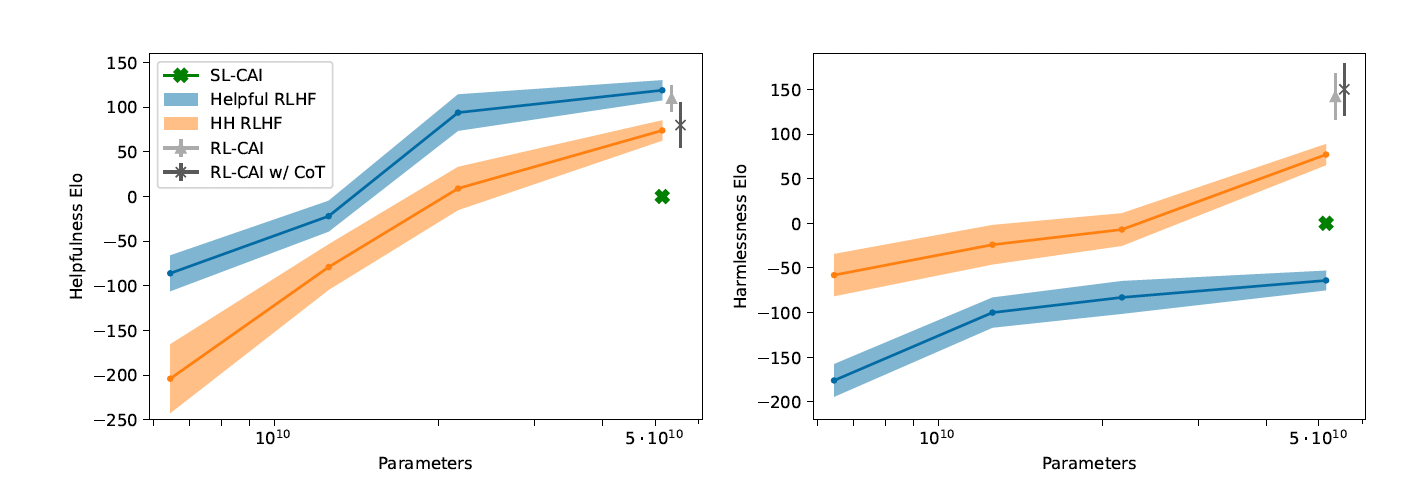
-
유용한 RLHF 모델: 가장 유용하지만 가장 유해함
-
HH RLHF 모델: 유용성은 낮지만 가장 무해함
-
SL-CAI 모델:
- RLHF 모델들보다 유용성은 낮음
- 유용한 RLHF보다 무해하고, HH RLHF보다는 유해함
-
SL-CAI vs 사전 학습 모델:
- SL-CAI가 더 유용하고 무해함
-
추가 비교:
- 52B 매개변수 SL-CAI 모델 (RL-CAI의 초기 스냅샷으로 표시)
- 52B 매개변수 사전 학습 모델 (RLHF의 초기 스냅샷으로 표시)
이 결과는 헌법적 AI 접근법이 인간의 직접적인 피드백 없이도 유용성과 무해성 사이의 균형을 어느 정도 달성할 수 있음을 보여준다. SL-CAI 모델은 완전한 RLHF 모델만큼의 성능은 아니지만, 사전 학습된 모델보다는 확실히 개선된 결과를 보여주었다.
4. Constitutional AI: Reinforcement Learning from AI Feedback
4-1. Method
AI 피드백을 활용한 강화 학습(RLAIF) 주요 내용은 다음과 같다
-
기본 접근법:
- 유용성: 인간 피드백 라벨 유지
- 무해성: 인간 피드백을 모델 피드백으로 대체
-
프로세스:
a) 어시스턴트 모델로 두 개의 응답 생성
b) 피드백 모델이 응답 평가 (무해성 기준)
c) 응답의 로그 확률 계산 및 정규화
d) 정규화된 확률을 목표값으로 하는 선호 모델 비교 예시 생성 -
피드백 모델:
- 주로 사전 학습된 언어 모델 사용
- 16개의 다양한 원칙 무작위 적용
- Few-shot 예시로 컨텍스트 제공
-
초기 모델:
- SL-CAI 모델을 초기 스냅샷으로 사용
-
강화 학습:
- RLHF와 동일한 파이프라인 사용
- 선호 모델: 인간 피드백(유용성)과 모델 피드백(무해성) 혼합하여 훈련
-
특징:
- 다양한 원칙 조합으로 선호 모델의 견고성 향상
- 초기 정책과 선호 모델 훈련 데이터의 분포 유사성 활용
RLAIF는 AI 시스템이 자체적으로 유해성을 평가하고 개선하는 능력을 활용하여, 더 효율적이고 확장 가능한 AI 훈련 방법을 제시한다.
Chain-of-Thought Prompting

-
CoT 프롬프트 구조:
- 인간과 어시스턴트 간 대화 제시
- 평가 원칙 제시
- 두 가지 응답 옵션 제공
- "단계별로 생각해 봅시다" 프롬프트로 연쇄적 사고 유도
Reference
https://scale.com/blog/chatgpt-vs-claude
https://arxiv.org/pdf/2204.05862
https://littlefoxdiary.tistory.com/112
