YOLOv3는 YOLO 시리즈의 세 번째 모델로, 속도와 정확도를 개선하여 실시간 객체 탐지에서 효율성을 극대화했다. 간단한 설계 변경과 훈련 기법을 통해 이전 모델 대비 발전을 이루었으며, COCO 데이터셋 기준으로 SSD와 RetinaNet 등과 경쟁할 만한 성능을 보였다.
Abstract
- YOLOv3는 속도와 정확성에서 균형을 맞춘 모델이다.
- AP50 기준 RetinaNet과 유사한 정확도를 가지며, 3.8배 더 빠르다.
Core Concepts
YOLOv3의 Bounding Box Prediction은 YOLO9000의 앵커 박스 설계를 확장해 효율성과 정확성을 모두 개선했으며, 객체성과 좌표 예측의 분리로 안정성과 유연성을 확보했다
1. Bounding Box Prediction
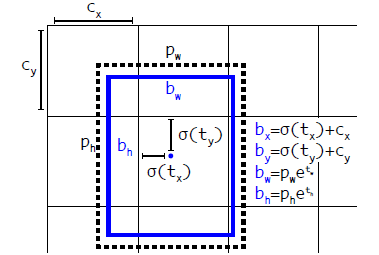
앵커 박스 기반 예측
- YOLO9000(YOLO V2)에서 도입된 차원 클러스터를 앵커 박스로 사용
- bounding box 좌표는 중심 좌표 , 너비 , 높이 로 구성
- 수식:
- : 셀의 오프셋
- : 앵커 박스의 너비와 높이
손실 함수
- 제곱 오차 손실(Sum of Squared Error Loss)을 사용
- 손실 계산:
- : 예측값
- : 실제값(ground truth)
객체성(Objectness) 점수 예측
- 로지스틱 회귀를 통해 각 경계 상자가 실제 객체와 얼마나 겹치는지 점수화
- 앵커 박스가 실제 객체와 가장 많이 겹칠 때 점수 1
- 겹치는 비율이 기준치(0.5) 이상이지만 최적이 아닌 경우 점수 무시
- 각 실제 객체에 하나의 앵커 박스만 할당
2. Class Prediction
- 각각의 bounding box는 multi-label classification 수행
- 하나의 class를 예측하는 softmax classifier를 사용하지 않고 각 class에 대해 o, x를 판별하는 logistic classifiers를 채택
- 다중 클래스 레이블이 중첩된 경우에도 유연하게 대처 가능
- 손실 함수: binary cross-entropy loss
3. Predictions Across Scales
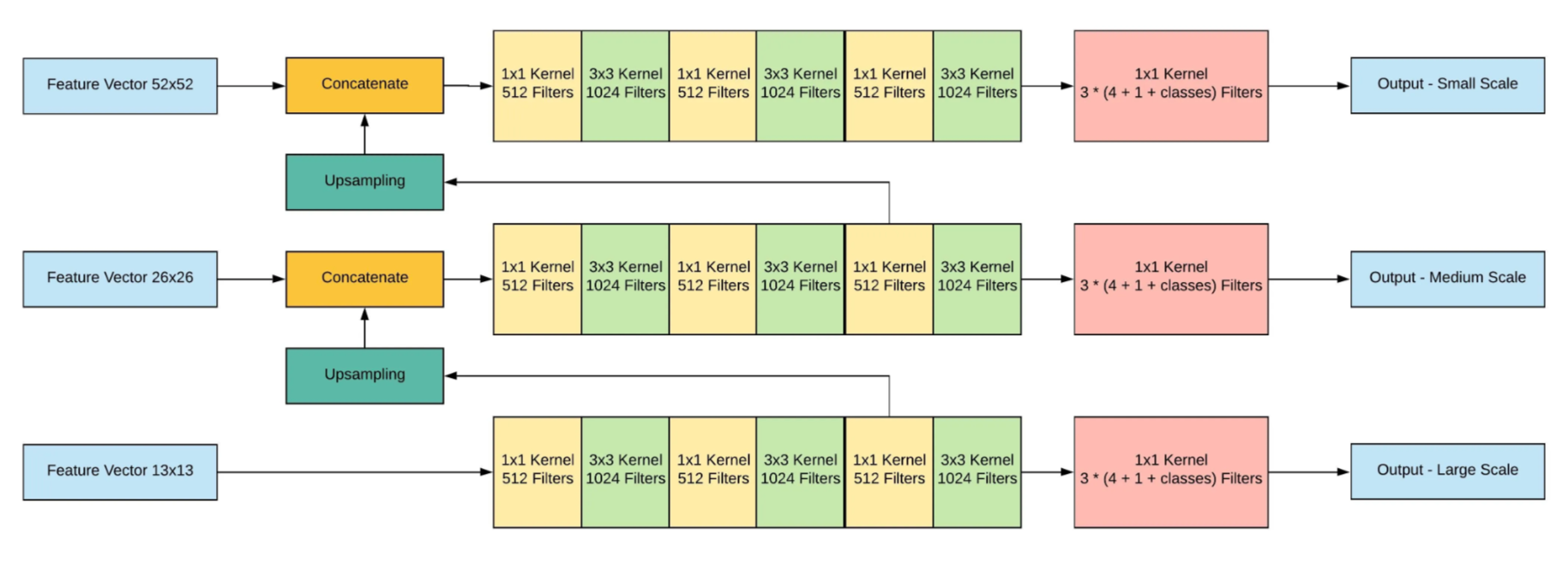
- 3개의 서로 다른 scale에서 결과 예측
- Feature Pyramid Networks(FPN)와 유사한 개념을 활용해 각 scale에서 특징을 추출
- base feature extractor에서 여러 합성곱 계층을 추가
- 마지막 계층은 bounding box, objectness,and class 예측을 포함한 3차원 텐서를 생성
4. Feature Extractor (Darknet-53)
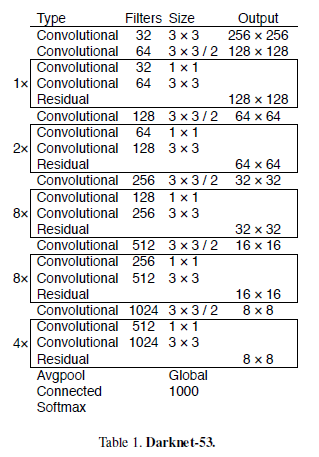
- YOLOv2의 Darknet-19와 ResNet의 residual network 방식을 결합
- Bottle neck 구조, Short-cut 도입
- 총 53개의 convolution layer로 구성
- 성능 비교:
- ResNet-101과 유사한 정확도, 속도는 1.5배 빠름
- ResNet-152보다 2배 더 빠르고 비슷한 성능
5. Training

- multi-scale training
- 데이터 증강 및 배치 정규화 사용
- Darknet 프레임워크 기반으로 학습
Conclusion
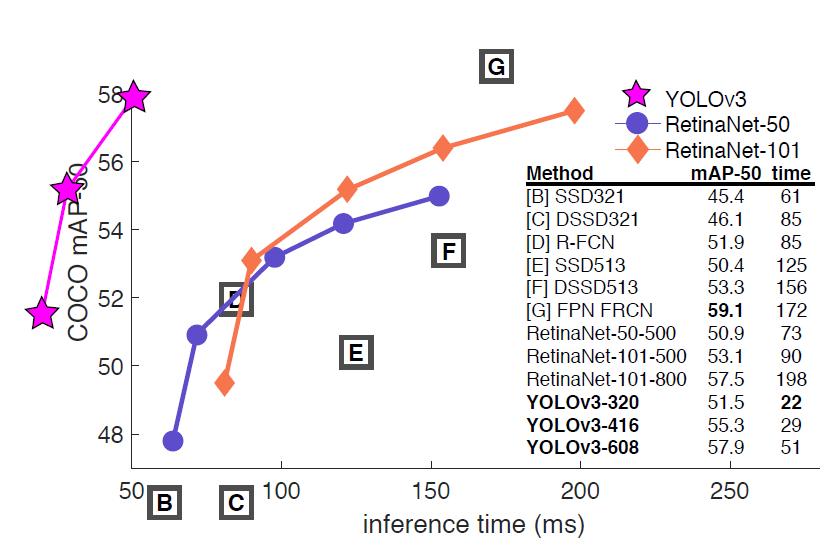
- YOLOv3는 실시간 탐지에서 빠르고 정확한 성능을 보여주는 객체 탐지 모델이다.
- COCO 기준 새로운 mAP에서는 최고 성능을 기록하지 못했지만, AP50 기준에서는 RetinaNet과 유사한 성능을 보인다.
- 객체 탐지 기술의 사회적 책임과 잠재적 위험에 대한 논의가 필요하다.
느낀점
본 논문은 성공적인 결과물 뿐만 아니라 Focal loss, linear x, y prediction 등 시도했으나 실패했던 히스토리까지 언급이 되어있다는 점이 인상 깊었다. YOLOv3는 객체 탐지 모델의 성능과 실용성 간 균형을 맞춘 좋은 사례였다는 점에서 의의가 있으며 단순한 구조로도 강력한 성능을 낼 수 있다는 점을 시사해주고 있다.
Reference
https://arxiv.org/abs/1804.02767
https://bestinau.com.au/yolov3-architecture-best-model-in-object-detection/
https://towardsdatascience.com/dive-really-deep-into-yolo-v3-a-beginners-guide-9e3d2666280e
https://herbwood.tistory.com/21
https://www.youtube.com/watch?v=jqykPH3jbic
