학습 source
머신러닝을 학습하면서 이론적 기초가 부족하다는 생각에 '혼자 공부하는 머신러닝+딥러닝' 교재를 도서관에서 빌려 독학을 시작했습니다!
머신러닝을 처음 공부하는 사람도 쉽게 이해할 수 있도록 친절한 용어로 설명이 되어있다는 점에서 나에게 딱 맞는 책이라는 생각이 들었어요.
책 내용은 회사 신입 데이터 사이언티스트가 회사에서 주어진 과제를 차근차근 수행해나가면서 성장해 나가는 스토리 형식이라 학습에 더욱 재미를 붙일 수 있었습니다 ㅎㅎ 하루에 한 챕터씩 소화하겠다는 목표로 시작해서 매일 조금씩 머신러닝을 알아가고 있는 중이에요! 지금부터 공부한 내용을 기록하고 공유하고자 블로그에 글을 남깁니다.
Chapter 01 k-최근접 이웃 알고리즘
1. 데이터 준비
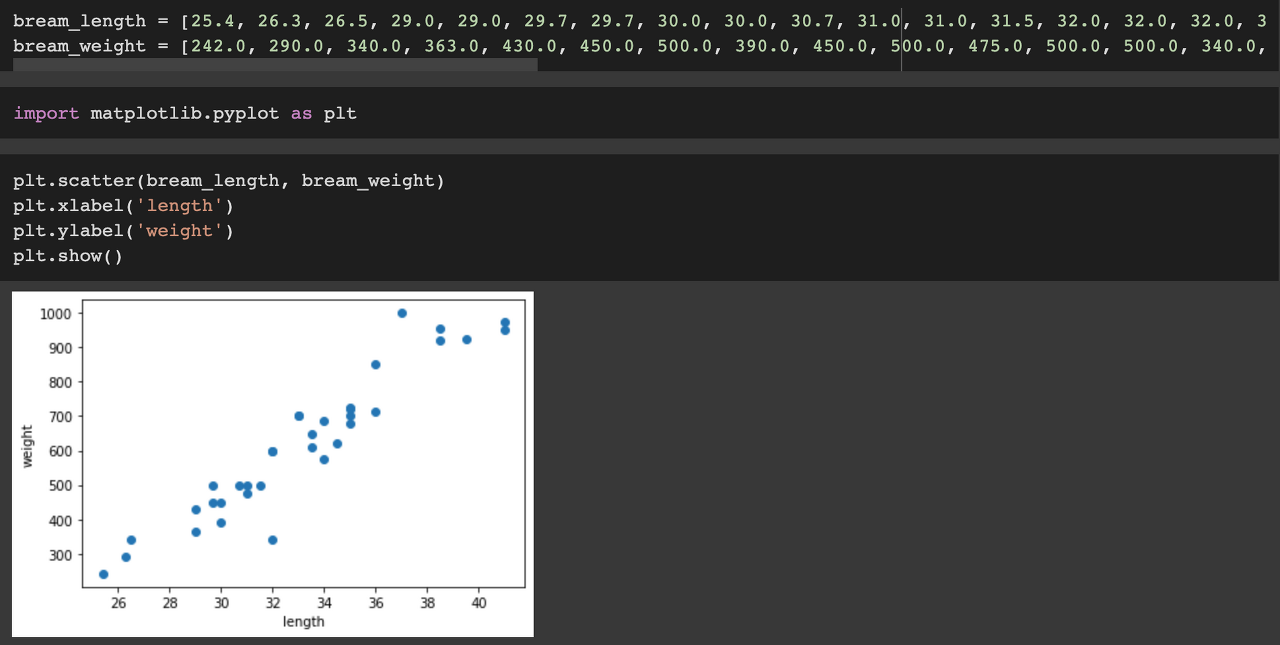
도미의 길이와 무게가 담긴 데이터를 matplotlib을 사용해서 scatterplot을 그려봤습니다. 길이가 길수록 무게가 무겁기 때문인지 그래프가 선형에 가까운 형태입니다.

빙어의 데이터까지 합쳐서 길이와 무게 데이터를 각각 만들고

특성(feature) 데이터 생성
length데이터에는 생선의 길이(도미 35마리, 빙어 14마리)가, weight에는 생선의 무게(마찬가지로 도미 35, 빙어 14)가 담겨 있습니다.
zip()이라는 함수는 iterable객체(여기서는 리스트 2개)를 받아서 원소를 각각 꺼내 하나로 묶어주는 작업을 합니다. 이를 통해 생선의 길이와 무게 데이터를 하나로 묶은 fish_data를 생성해주었습니다.
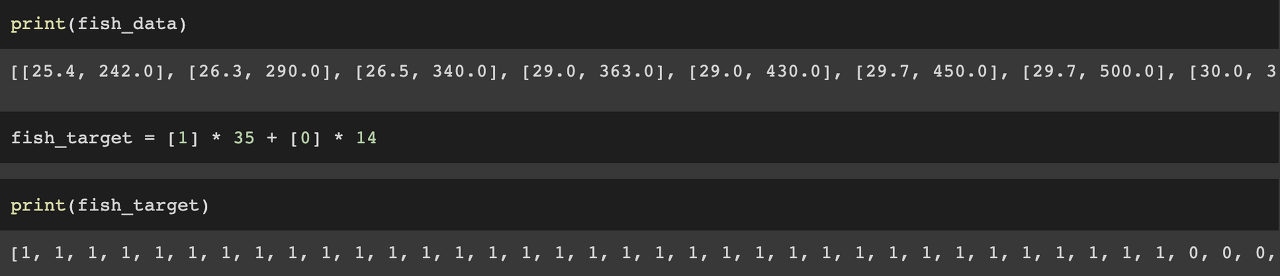
타깃 데이터 생성
fish_target 데이터에는 도미를 1, 빙어를 0으로 담아주기 위해 리스트 연산자를 사용했습니다.
2. k-최근접 이웃 알고리즘 _KNeighborClassifier( )
분류 모델을 만드는 사이킷런의 클래스 중 하나
주위의 k개의 이웃 샘플을 보고 해당 데이터가 속할 그룹을 판단하는 알고리즘
n_neighbors로 k를 지정할 수 있다.
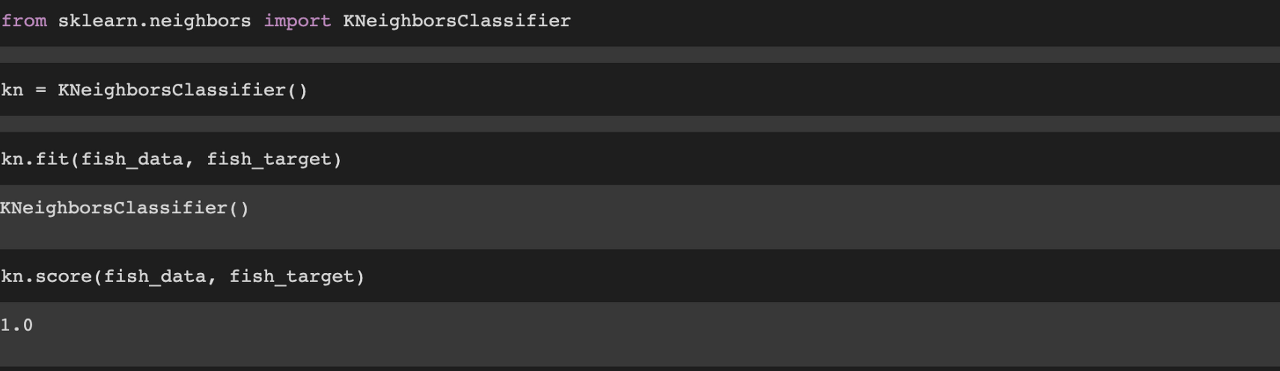
kn이라는 변수에 KNeighborClassifier 클래스를 담아주고 fit( ) 명령어를 통해 학습 시켜줍니다.
score( ) 명령어에 특성 데이터와 타깃 데이터를 넣어서 성능을 평가하면 1점(1점이 만점)이 나오는데, 이미 학습한 데이터로 평가하는 것이기 때문에 당연한 결과입니다.
이번에는 길이가 30이고 무게가 600인 특성을 지닌 생선이 도미인지 빙어인지 분류해보도록 하겠습니다.
그래프로 우선 확인해보면,
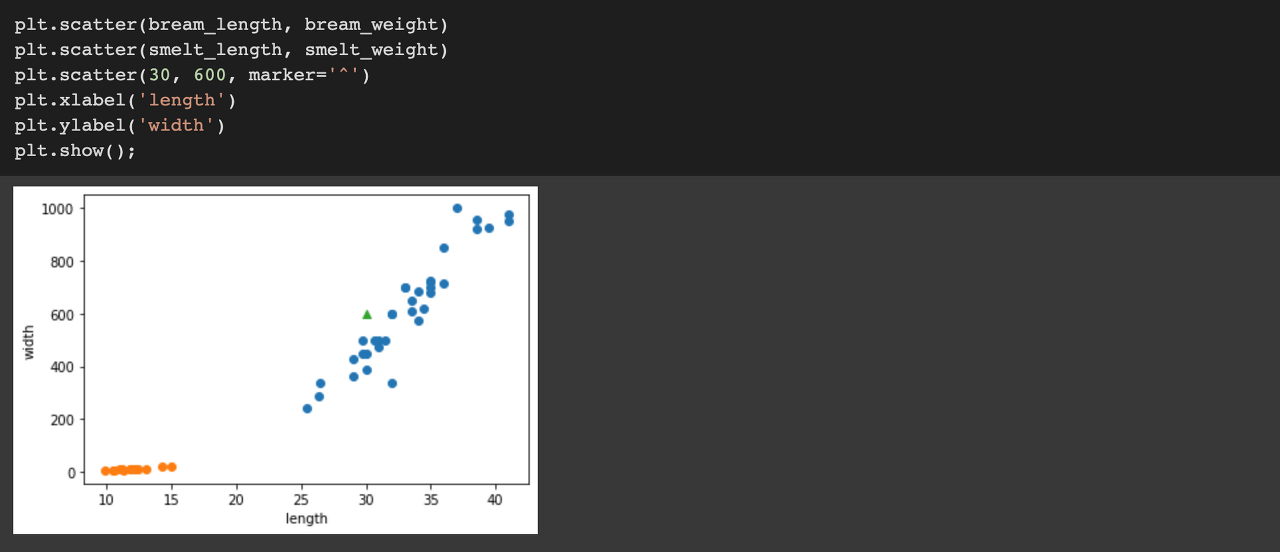
초록색 세모 모양이 도미 그룹군에 가까이 위치한 것을 볼 수가 있습니다.
예측을 해보도록 하겠습니다.

predict( ) 명령어에 특성 값을 넣어주면 분류 결과를 확인해볼 수 있습니다. 값이 1로 도미로 알맞게 분류한 것을 알 수 있네요!
여기까지 분류의 기본 알고리즘인 k-최근접 알고리즘에 대해서 알아보았습니다. 다음에는 머신러닝의 성능을 효과적으로 검증하기 위해서 훈련 데이터와 검증 데이터로 나누는 방법에 대해서 알아보겠습니다.
자료출처: 한빛미디어
