#선형 회귀 이론 및 실습 #1
#정규 방정식
#거친코딩
선형 회귀는
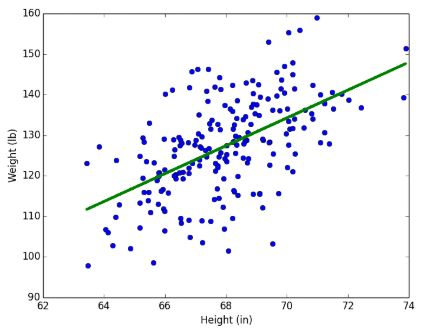
종속 변수와 한 개 이상의 독립 변수 사이의
선형 상관 관계를 모델링하는 회귀분석 기법이다.
선형 회귀는 선형 예측 함수를 사용해 회귀식을 모델링,
알려지지 않은 파라미터는 데이터로부터 추정한다.
특성이 하나인 선형 모델은
Y = W0 + W1*X
W0 => y축 절편, W1 => 특성의 가중치목적은 특성과 타깃 사이의 관계를 나타내는 선형 방정식의
가중치 W를 학습하는 것
선형 회귀 모델을 훈련 시킨다는 것은
- 모델이 훈련 데이터에 부합하게 파라미터를 설정하고
- 모델이 얼마나 잘 들어맞는지 측정하는 것
비용함수로는 MSE, MAE, RMSE 등 여러 종류가 존재하는 데
미분 편의성이 좋은 MSE를 주로 사용한다.
MSE는 예측 값과 실제 값 사이의 오차를 제곱하여 이를 평균낸 것
오차의 제곱을 하기 때문에 이상치에 예민하게 반응한다.
MSE = Mean Squared Error- Mse
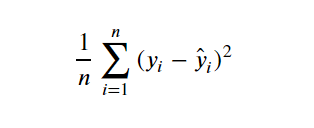
선형 회귀 모델의 최적화
#1 정규방정식
- 일단 랜덤으로 데이터를 흩뿌린다. => scatter 이용
import matplotlib.pyplot as plt
import numpy as np
x=2*np.random.rand(100, 1) #0과 1사이의 균일분포 추출, 100 * 1
y=4+3*x+np.random.randn(100, 1) #정규분포로 noise term 역할
plt.scatter(x,y)
plt.show()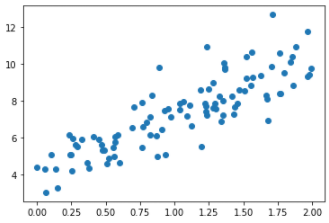
- 정규방정식을 이용하여 모델을 찾는다.
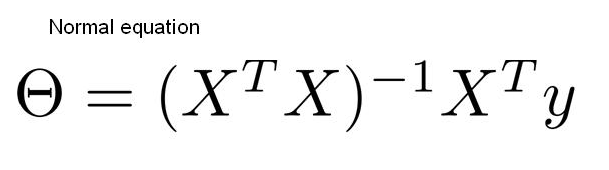
x_b = np.c_[np.ones((100,1)), x]
theta_best = np.linalg.inv(x_b.T.dot(x_b))
.dot(x_b.T).dot(y)
=> theta_best = array([[4.09339163],
[3.12004925]])
처음에 작성했던 식과 동일하지 않지만 비슷하게 구해진다.
x_new = np.array([[0],[2]])
x_new_b = np.c_[np.ones((2,1)),x_new]
prediction = x_new_b.dot(theta_best)
plt.plot(x_new, prediction, "r-") # 1번
plt.plot(x,y,'b.') # 2번
plt.axit([0,2,0,15])
plt.show()
prediction은 새로운 theta_best로 예측한 예측 값
1번은 새로운 예측 된 모델을 그리고
2번은 위에서 그렸던 랜덤 분포된 데이터를 그린다.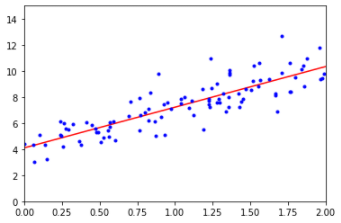
이 과정을 사이킷 런을 이용하여 간단하게 수행할 수 있다.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(x,y)
=> lin_reg.intercept_ = [4.09339163]
=> lin_reg.coef_ = [3.12004925]
Whiplash We Flash