분류 모델(Classification)
성능평가 방법
분류 모델에는 다양한 것들이 있다.
Perceptron, SVM, Decision Tree, Bayesian 등이 그 예시이다.
이런 모델들을 개발했을 때 해당 모델의 성능을 평가하는 척도를 제시한다.
기억 안날 때 보고 참고하려고 이곳에 작성한다...
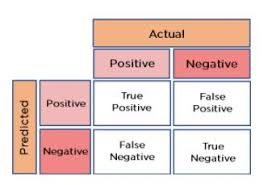
위의 이미지는 Confusion Matrix이다.
각 지점에 대한 설명을 보태면
True/False는 모델이 잘 분류했는 지를 의미하고 Positivie/Negative는 분류를 어떻게 했는 지를 의미한다.
- True Positive = True를 True로 옳게 분류한 경우
- False Positive = True라고 분류했지만 False인 경우
- False Negative = False라고 분류했지만 True인 경우
- True Negative = False라고 분류했고 옳게 분류한 경우
솔직히 볼 때 마다 헷갈리긴 해서 매번 다시 찾아보고 생각한다.
이제 성능평가 지표에 대해서 설명한다.
성능평가 지표
Precision(정밀도)
정밀도는 분류 모델이 True로 분류한 것들 중에서 실제로 True인 정도를 의미한다.
Precision = TP/(TP+FP) 로 표현할 수 있고 이 값은 높으면 높을 수록 좋은 값이다.
Accuracy(정확도)
정확도는 전체 데이터에서 모델이 올바르게 분류한 경우를 의미한다.
Accuracy = (TP+TN)/(TP+FN+FP+TN)로 표현할 수 있고 이 값은 높으면 높을 수록 좋은 값이다.
Recall(재현율)
재현율은 분류 모델이 실제 True 중에서 True라고 분류한 경우를 의미한다.
Recall = TP/(TP+FN) 로 표현할 수 있고 이 값도 역시 높으면 높을 수록 좋은 값이다.

Whiplash We Flash