Time Series Summary
reference
https://otexts.com/fppkr/tspatterns.html
https://playinpap.github.io/easypeasy-time-series-02/
항상성 같은거 여기서 따옴. 말이 쉽게 잘되어있음.
검정에 대한 부분이나 복잡한 공식들은 제외하고 요약.
평균, 중앙값
평균은 전체를 합산한다는 점. 중앙값은 분포되어있는 데이터 중 중앙에 있는 값을 나타낸다.
그러므로 합산을 통한 분석이 필요할 때는 평균이 좋은 경우가 많고, 아닐 때는 중앙값을 사용하는게 좋은 경우가 많지만 정답은 없다.
Time-step features
시간 인덱스에서 뽑을 수 있는 특성이다.
가장 기본적인 형태는 time dummy로, 시간의 처음부터 끝까지를 숫자로 인덱스화 하는 것이다.
df['Time'] = np.arange(len(df.index))Lag features
말 그대로 지연 특성이다.
이전의 값이 나중의 값에 영향을 미치는 점을 고려한 특성으로
kaggle learning에서는 1-step lag feature를 사용한다.
df['Lag_1'] = df['Hardcover'].shift(1)Trend
시계열에서 지속적이고, 긴 기간동안 반복되는 변화에 대한 특성이다.
-> 장기적으로 증가하나거 감소하는 특성. 추세가 증가에서 감소로 변하면, 추세의 방향이 변화했다고 표현.
시계열에서 Trend를 보기 위해서는 이동평균선 (Moving Average Plots) 를 확인해야 한다.
Seasonality
시계열의 규칙적이고, 기간적인 변화를 의미하는 특성으로 시간이나 달력과 같은 요소를 따른다.
-> 해마다 어떤 특정한 떄나 1주일마나 특정 요일에 나타나는 것 같은 계절성 요인이 영향을 주는것.
kaggle learning에서는 두가지를 배우는데
첫번째는 indicators로 일간 관찰이나 주간에 관한 것이다.
두번째는 푸리에 특성으로, 연간과 같은 많은 관찰에 관한 것이다.
Cycle
고정된 빈도가 아닌 형태로 증가나 감소하는 모습을 보일때 주기가 나타난다고 한다.
일정한 빈도로 나타나지 않는 요동은 주기적인 것 이고, 빈도가 변하지 않고 연중 어떤 시기와 연괸되어 있다면 계절성이 있다고 한다.
Stationarity
과거 관찰값을 토대로 미래를 예측하기 위해서는 수집된 관측값이 안정적으로 유지되고 있는 상태인지, 또는 계속해서 변동하는 상태인지를 알아야 한다. 이떄, 시계열의 안정적 수준이 바로 정상성이며, 정상이란 변하지 않고 일정한 상태를 의미한다. 여기서 일정한 상태란, 평균 a에서 위 아래로 b 구간 사이에서 일정하지만 불규칙적인 변동을 가지고 움직이고 있음. 을 뜻한다.
정상성을 가지고 있는 시계열은 특정한 규칙이 없기 때문에, 예측할 수 없다.
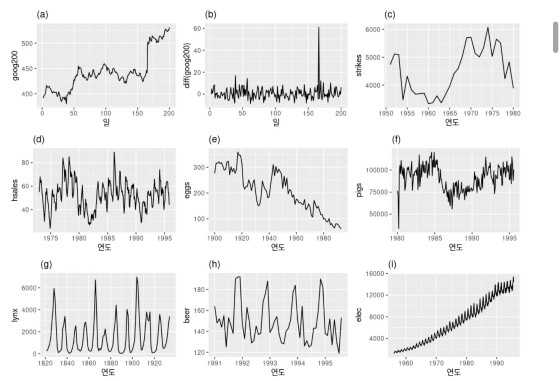
이 그림을 통해 이해해 보면
d, h, i는 분명하게 계절성이 보이기 때문에 정상성을 가진다고 할 수 없습니다.
a, c, e, f, i도 또한 추세가 있고, 수준이 변하기 때문에 정상성을 가진다고 할 수 없습니다.
i는 추가적으로 분산이 증가하기 때문에, 정상성을 가진다고 볼 수 없습니다.
그러므로 이 그림에서 b, g만 정상성을 가질 수 있는 후보로 남았습니다.
정상화된 시계열은 예측이 불가능하고, 이는 잔차(실제값과 예측값의 차이) 가 white noise를 나타낸다는 것으로 확장할 수 있습니다.
이에 관한 설명은 후에 서술되어 있습니다.
Plot
계절성 그래프
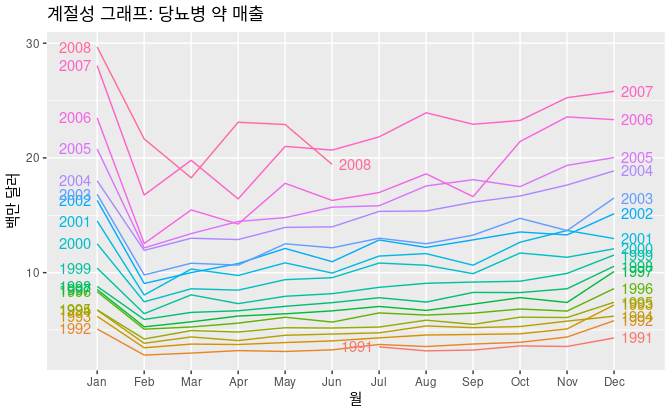
계졀성 그래프는 나타내려는 중요한 계절성 패턴을 더욱 분명하게 보여주고, 특별히 패턴 변화가 있는 연도를 찾아낼때 쓸모가 있다.
위의 그래프를 예시로 들면, 매년 1월에 매출이 크게 뛰는 것을 볼 수 있다. 이것은 정부가 연말에 사재기 하는 매출이 1~2주 후 까지 정부에 등록되지 않기 때문이다.
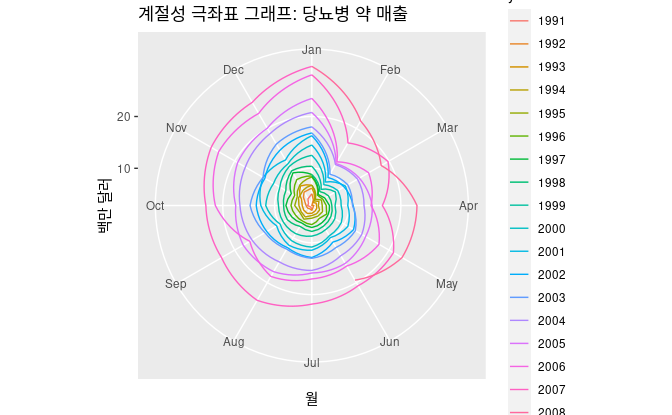
같은 그래프지만 극좌표로 나타낸다면, 더욱 가시성이 높아진다.
계절성 부시계열 그래프
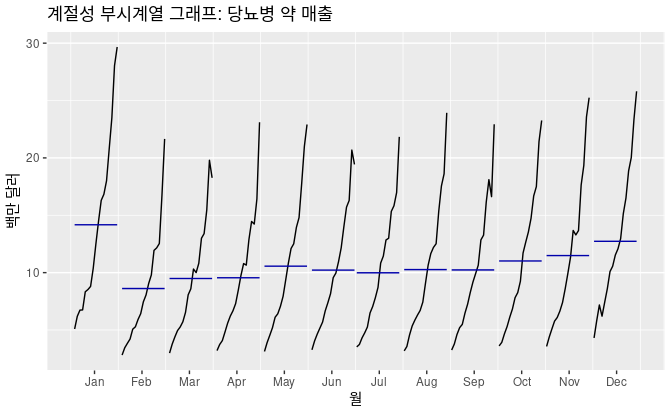
전체 데이터를 월별로 구분해서 나타난 그래프이다. 중요한 계절성 패턴을 분명하게 살펴볼 수 있고, 계절성이 시간에 따라 어떻게 변하는지도 볼 수 있다. 그리고 특정한 철에서 나타나는 변화를 확인할 때 특별히 쓸모가 있다.
시차 그래프
lag에 따른 계절성을 뽑아내기 위한 그래프라는 것 까지 이해했다.
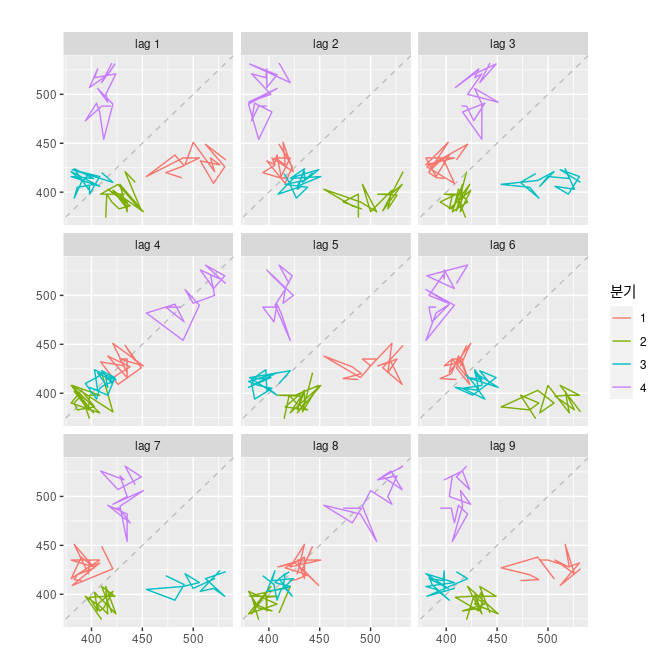
시차 4, 8에서 양의관계가 뚜렷한 것을 보니 데이터에 계절성이 강하게 있다고 이해할 수 있다.
~~ 추가로 공부하기.
자기상관
자기상관 (autocorrelation)은 시차값 사이의 선형관계를 측정하는 상관계수이다.
rk는 yt와 yt-k의 관계를 측정하는 변수로
수식을 통해 1 ~ -1사이로 표현될 수 있는 것을 알 수 있다.
1 2 3 4 5 6 7 8 9
-0.102 -0.657 -0.060 0.869 -0.089 -0.635 -0.054 0.832 -0.108
위 표는 k에 따른 자기상관계수를 나타낸 표로

이렇게 그려질 수 있다.
k가 4의 배수인 경우는 자기상관계수의 값이 높은데, 데이터의 계절성 패턴 때문이다. 고점은 4개의 분기마다 나타나는 경향이 있고, 저점도 4개의 분기마다 나타나는 경향이 있다.
파란 점선은 후에 나옴.
ACF
데이터에 추세가 존재한다면, 작은 크기의 시차에 대한 자기상관은 큰 양의 값을 갖는 경향이 있다. 추세가 있다면 시간적으로 가까운 관측치들이 관측값의 크기에 있어서도 비슷하기 때문이다. 그러므로 추세가 있는 시계열의 ACF는 양의 값을 가지는 경향이 있으며, 이 ACF값은 시차(lag)가 증가함에 따라 서서히 감소한다.
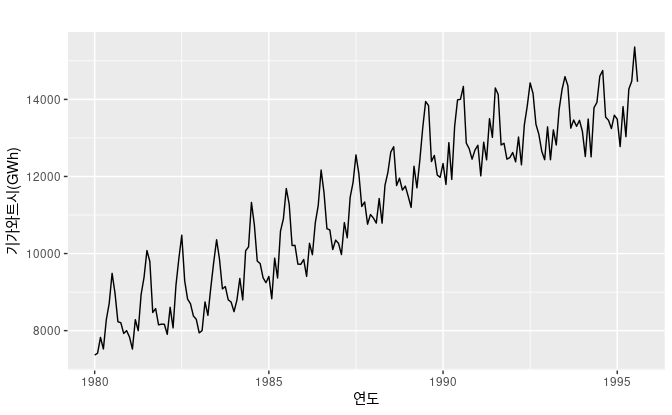
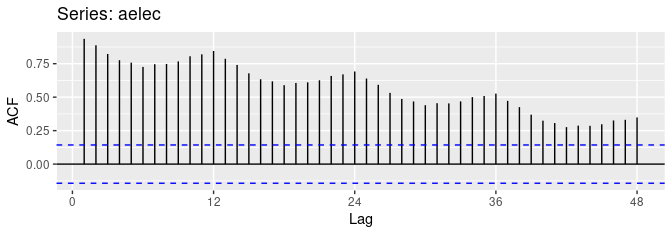
첫번째 그래프와 같이 추세와 계절성을 모두 가질경우, ACF는 양의 값을 갖고, 계절성 때문에 물결모양을 그린다.
백색잡음
자기상관이 없는 시계열을 백색잡음(white noise)라고 부른다.
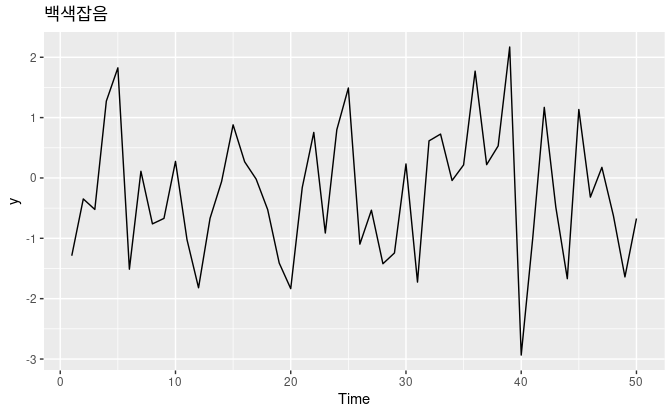
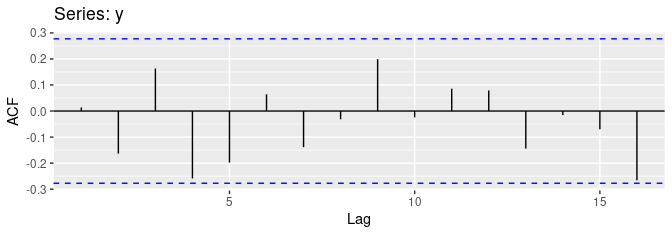
위의 그래프는 백색잡음이고, 그에따른 ACF를 나타내고 있다.
백색잡음을 판단할떄는 ACF에서의 막대의 95%가 에 들어갈 수 있다고 기대한다.
여기서 T는 시계열의 길이로, 이 예제에서는 T = 50이기 떄문에 +- 0.28에 경계가 있다.
변환과 조정
더 단순한 패턴이 더 좋은 정확도를 만들어 낸다. 그러므로 과거데이터에 대한 변환과 조정은 유용하다.
달력 조정
단순히 달력때문에 데이터의 변동이 나타날 수 있습니다.
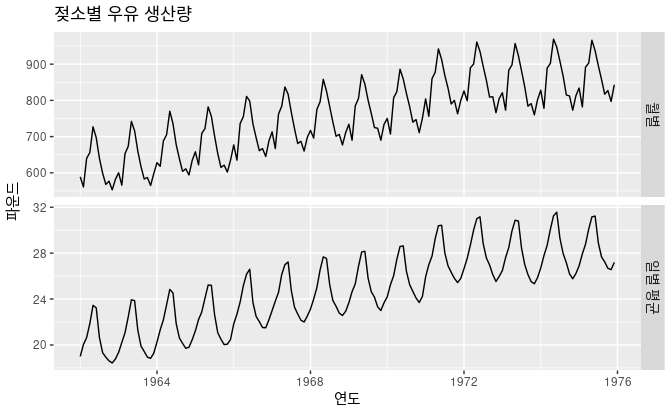
이 그래프를 예시로 들면, 단순한 월별 일수의 차이 때문에 데이터의 변동이 일어나고 있습니다.
이 데이터를 일별 평균으로 바꾸면, 효과적으로 일수의 차이를 제거할 수 있습니다.
인구조정, 인플레이션 조정 등의 수치조정
특정 지역에서 시간에 따른 병원 침상 개수에 대한 데이터가 있다고 가정하자.
그 데이터를 특정 인구수(100, 1000명)에 따른 침상 개수의 비율로 나타낸다면, 인구수에 따른 데이터의 변동을 효과적으로 제거할 수 있다. 이와 비슷하게 몇십년동안 새로운 집의 평균 가격이 증가한 데이터가 있을때, 모든값을 특정 연도의 환율 가치로 나타내도록 시계열을 조정할 수 있다.
이처럼 하나의 상수값을 특정 변수의 비율로 나타낸다면, 더 효율적으로 데이터를 판단할 수 있다.
수학적 변환
로그변환, 박스-칵스 변환등
로그변환의 유용성에 대해 추가적 공부.
잔차 진단
적합값
시계열에서의 각 관측값은 이전의 모든 관측치를 통해 예측될 수 있다. 이러한 것을 적합값(fitted values)라 부른다. 또한 관측값 을 가지고 하는 의 예측값이라는 의미에서 로 사용하기도 한다.
모자 기호는 추정치라는 것을 의미한다. 그러므로 예측치와 적합값(추정치)는 다르고, 나이브 또는 나이브 계절성 예측에서는 어떠한 매개변수도 없기 때문에 적합값이 예측치가 된다.
잔차
시계열모델에서의 잔차(residuals)는 모델을 맞춘 후에 남는 것을 의미한다. 전부는 아니지만 많은 시계열 모델에서 잔차는 관측값과 적합값의 차이로 나타난다.
잔차에는 상관관계가 없습니다. 잔차 사이에 상관관계가 있다면, 장차에 예측값을 계산할 때 사용해야 하는 정보가 남아있다는 것 입니다.
2. 잔차의 평균은 0입니다. 잔차의 평균이 0이 아니라면, 예측값이 편향될 것 입니다.
편향 문제를 고치려면 간단하게 잔차의 평균을 모든 예측치에 더해주어 해결할 수 있습니다.
상관문제는 난이도가 높으므로 추후에 설명.
정확도 평가
예측 오차
예측오차는 테스트 데이터에 적용하고, 여러단계 예측값을 포함하여 계산한다는 점에서 잔차와 다르다.
흔히 평가할때 쓰는것들이 예측오차.
눈금에 의존하는 오차
예측오차는 데이터와 같은 눈금 위에 있으므로, et만 고려하는 정확도 측정 값은 눈금에 의존하고 다른 단위를 포함하는 시계열을 비교하는데 사용할 수 없다.
이 두가지가 가장 널리 사용된다.
MAE를 최소화 하는 예측 기법은 예측값의 중앙값을 내고, RMSE를 최소화 하는 예측 기법은 예측치의 평균을 낸다.
백분율 오차
백분율 오차는 로 나타낼 수 있다. 단위와 관련이 없다는 장점이 있어서 데이터 모음 사이의 예측 성능을 비교할 때 자주 사용한다.
백분율 오차에 기초하는 측정값은 어떤 t에 대해 yt = 0이면 무한대가 되거나 정의되지 않는다는 점, yt에 가까울 수록 극한값을 갖는다는 단점이 있으며, 측정 단위가 의미있는 0을 갖는다고 가정한다는 것 입니다.
그렇기 때문에 온도에는 임의의 0점이 있기 때문에 온도의 정확도를 측정할 때 백분율 오차를 사용하는 것은 말이 안된다.
양수 오차보다 음수 오차에 더 큰 가중치를 준다는 단점도 있다. 이러한 단점은 MAPE보다 SMAPE를 사용할때 더 부각된다.
눈금 조정된 오차
예측오차에 분모 부분에 분자, 분모가 모두 단위값을 가진 식을 넣어 눈금을 조정한 오차 방식.
추후 살펴보기.
예측 구간
어렵다
시계열 회귀 모델
단순 선형회귀는 배경지식에 있기 때문에 생략.
최소 제곱 추정
최소 제곱 원리(least square principle)은 제곱 오차의 합을 최소화 하여 계수를 효과적으로 선택할 수 있는 방법입니다.
기존에 알고있는 loss에 해당하는 부분이며, loss를 줄이는 방향이 모델을 학습시키거나, 훈련한다고 한다.
추정된 계수는 와 같이 표현된다.
적합값
이렇게 추정된 계수를 사용해서 y의 예측값을 얻을 수 있다.
와 같이 표현되며, 이 예측값을 적합값(fitted value) 라고 부른다.
적합도
이렇게 추정해낸 적합값이 데이터에 얼마나 잘 맞는지 요약하는 일반적인 방법은 결정 계수 또는 를 사ㅏ용하는 것 이다.
예측값이 실제와 가깝다면, 는 1에 가까워지고, 관련이 없다면 0에 가까워 진다. 그러므로 0~1의 값을 가지게 된다.
회귀 모델 평가
관측된 y와, 적합값 y_hat의 차이값은 잔차로 정의합니다.
잔차는 관련된 관측값의 예측할 수 없는 성분이며, 몇가지 유용한 성질이 있다.
잔차의 평균은 0이고, 잔차와 예측변수에 대한 관측값 사이의 상관관계도 0이다.
https://otexts.com/fppkr/regression-evaluation.html
평가방법 여러가지가 있는데 아직은 힘들다
시계열 분해
-> 어려워서 많이 넘김.
시계열 성분
시계열의 성분에는 상기에 서술한 추세, 계절성, 주기가 있고, 주로 추세와 주기를 묶고(추세-주기 성분), 계절성을 하나로 둔 다음(계절성 성분) 이와 상관없는 변수가 있다고 가정합니다(나머지 성분). 시계열 분해는 두가지로 표현할 수 있는데
첫번째는 덧셈분해 입니다.
두번째는 곱셈분해 입니다.
계절성 요동의 크기나 추세-주기 주위의 변동이 시계열의 수준에 의해 변하지 않으면, 덧셈 분해가 가장 적절합니다. -> 시계열의 수준을 이해해야 되는데, 정상성이 있다면 시계열의 수준이 안정적인 것이고, 아니면 아닌 것으로 이해하면 되는건가..
계절성 패턴에서 변동이나 추세-주기 주위의 변동이 시계열의 수준에 비례하는 것으로 나타날때는, 곱셈분해가 더 적절합니다.
계절성에 의한 변동이 주된 관심사가 아니라면, , 와 같이 계절성으로 조절된 시계열은 유용할 수 있습니다. ex) 학교를 졸업한 사람들이 일자리를 찾는 것 때문에 나타나는 실업률 증가 -> 계절성 변동.
경기 침체 때문에 실업자가 많아서 생기는 증가 -> 비-계절성
시계열의 전환점을 살펴보거나, 어떤 방향으로의 변화를 해석하는 것이 목적이라면 추세-주기 성분을 사용하는 것이 낫다.
이동평균
추세-주기를 측정하기 위해 이동평균 방법을 사용한다. (고전 시계열 분해)
이동 평균 평활
m의 이동 평균은
과 같이 나타낼 수 있다.
이므로, k기간 안의 시게열 값을 평균하여 시간 t의 추세-주기를 측정한다.
분해 기법
고전적 분해 생략.
X11, SEATS, STL
ARIMA
ARIMA는 데이터에 나타나는 자기상관을 표현하는데 목적이 있다.
Staionarity -> 추가설명
정상성을 나타내는 시계열은 시계열의 특징이 해당 시계열이 관측된 시간에 무관하다.
-> 추세나 계절성이 있는 시계열은 정상성을 나타내는 시계열이 아니다.왜냐하면 추세와 계절성은 서로 다른 시간에 시계열의 값에 영향을 줄 것이기 때문이다.
반면, 백색잡음 시계열은 정상성을 나타낸다 -> 언제 관찰하는지에 상관이 없고, 시간에 따라 어떤 시점에서 보더라도 똑같이 보일 것이기 때문.
정상성을 가지고 있는 시계열은 특정한 규칙이 없기 때문에, 예측할 수 없다.
이 그림을 통해 이해해 보면
d, h, i는 분명하게 계절성이 보이기 때문에 정상성을 가진다고 할 수 없습니다.
a, c, e, f, i도 또한 추세가 있고, 수준이 변하기 때문에 정상성을 가진다고 할 수 없습니다.
i는 추가적으로 분산이 증가하기 때문에, 정상성을 가진다고 볼 수 없습니다.
그러므로 이 그림에서 b, g만 정상성을 가질 수 있는 후보로 남았습니다.
정상화된 시계열은 예측이 불가능하고, 이는 잔차(실제값과 예측값의 차이) 가 white noise를 나타낸다는 것으로 확장할 수 있습니다.
주기가 있지만 추세나 계절성은 없는 시계열은 정상성을 나타낸다. -> 주기가 고정된 길이를 갖고 있지 않기때문에, 시계열을 관측하기 전에 주기의 고점이나 저점이 어디인지 모르므로.
일반적으로, 정상성을 나타내는 시계열은 장기적으로 볼 때 예측할 수 있는 패턴을 나타내지 않을 것이다. -> 시간 그래프는 시계열이 일정한 분산을 갖고 대략적으로 평평하게 될 것이다.
정상성을 나타내지 않는 시계열을 찾아낼 때 ACF 그래프도 유용하다.
정상성을 나타내지 않는 데이터에서는 ACF가 느리게 감소하지만, 정상성을 나타내는 시계열에서는 비교적 빠르게 0으로 떨어진다.
그리고 정상성을 나타내지 않는 데이터에서 r1는 종종 큰 양수을 가진다.
differencing
정상성을 나타내지 않는 시계열을 정상성을 나타내도록 만드는 한 가지 방법.
연이은 관측값들의 차이를 계산하는 것 이다.
차분은 시계열의 수준에서 나타나는 변화를 제거하여 시계열의 평균 변화를 일정하게 만드는데 도움이 될 수 있다. -> 추세나 계절성이 제거, 또는 감소된다.
