
Kafka 란 무엇일까 ?

위의 그림을 보면 카프카는 자기 자신을 분산 이벤트 스트리밍 플랫폼 ( 스트리밍을 처리하기 위한 플랫폼) 으로 소개 하고 있다.
fortune company 100개 기업 기준으로 80% 이상이 kafka를 사용하고 있고..
제조, 은행 , 통신 등 다양한 곳에서 kafka를 사용한다고 한다.
kafka 의 구성요소
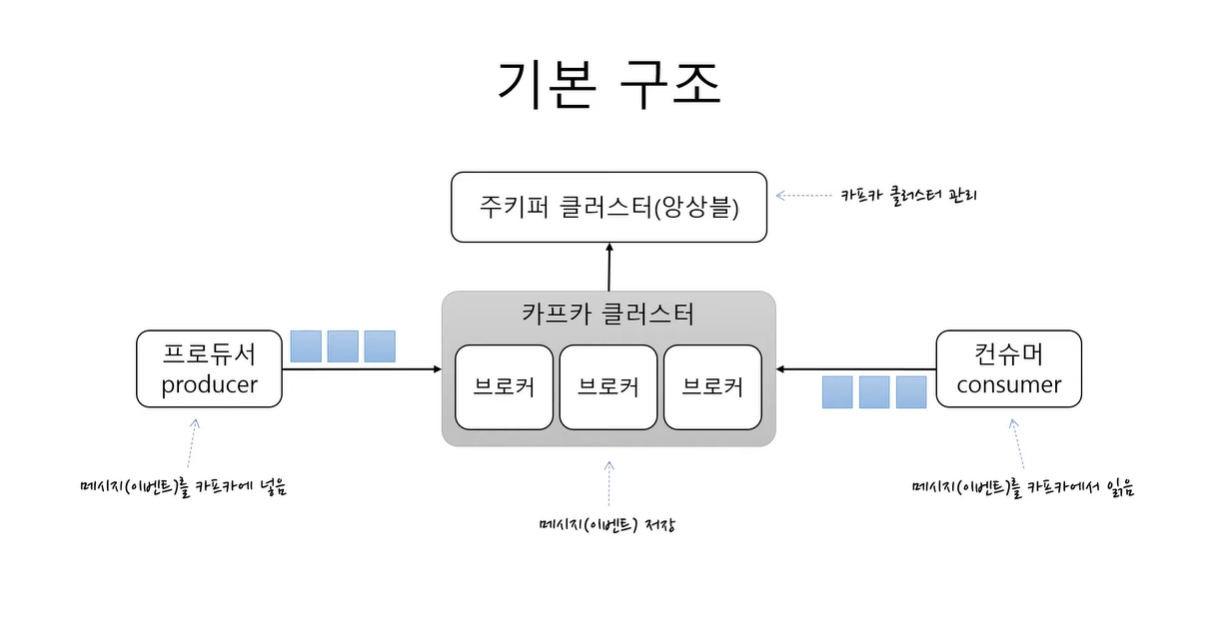
kafka 는 크게 4개의 구성요소로 이루어져 있다고 본다.
Kafka cluster
-
메세지를 저장하는 저장소
-
여러개의 브로커로 구성. (브로커는 각각의 서버라고 보면 됨)
-
메세지를 나눠서 저장하고 이중화 처리도 한다.
-
장애가 나면 대체도 한다. (고가용성)
-
데이터를 이동하는데 필요한 핵심 역할을 맡음.
ZooKeeper
-
Kafka cluster 를 관리함.
-
ZooKeeper 속에 Kafka cluster 와 관련된 정보가 기록되고 관리됨.
Producer
-
Kafka cluster 에 메세지를 보내고 넣음.
-
메세지를 저장할 때 어떤 토픽에 저장해줘 라고 요청을 함
Consumer
-
Kafka cluster 에서 메세지를 읽어와서 필요한 처리를 함.
-
어떤 토픽에서 메세지를 읽어올래 라고 처리함.
Topic & Partition
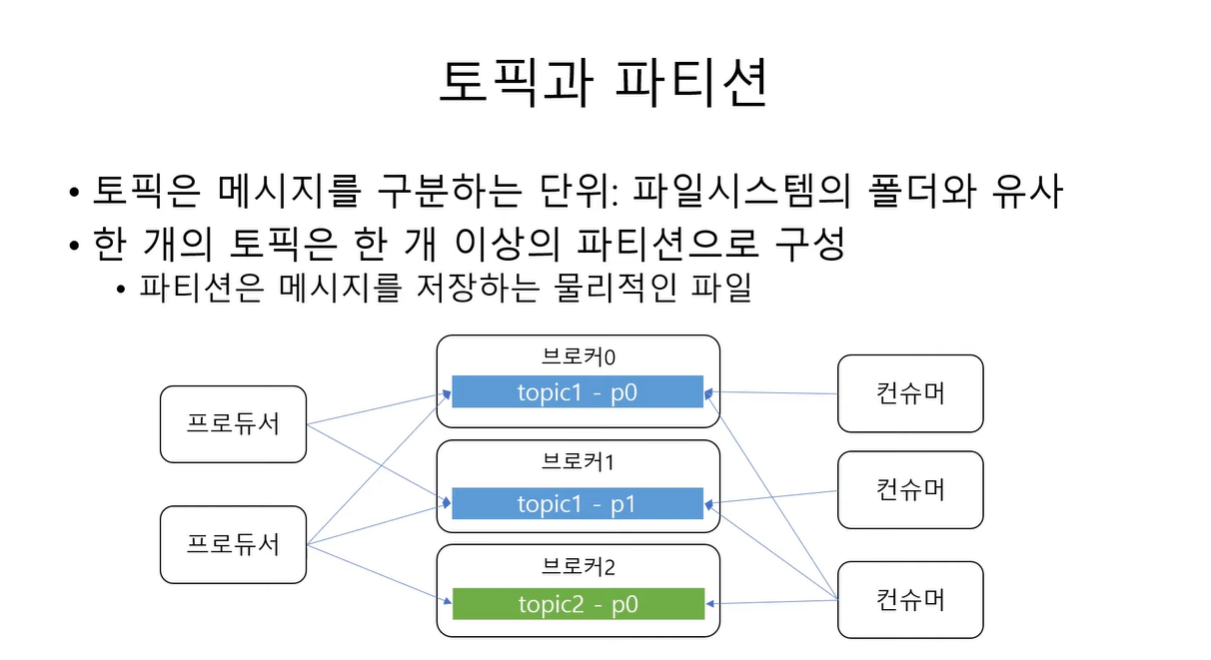
Topic
-
메세지를 저장하는 단위가 토픽이라고 한다.
-
메세지를 구분하는 용도로 사용을 함.
-
파일시스템의 폴더나 메일함과 유사한 개념
-
한개의 토픽은 한개 이상의 파티션으로 구성 된다.
-
토픽을 기준으로 producer와 consumer 가 메세지를 주고 받음.
Partition
- 메세지를 저장하는 물리적인 파일을 의미함.
Partition 과 Offset, 메시지 순서
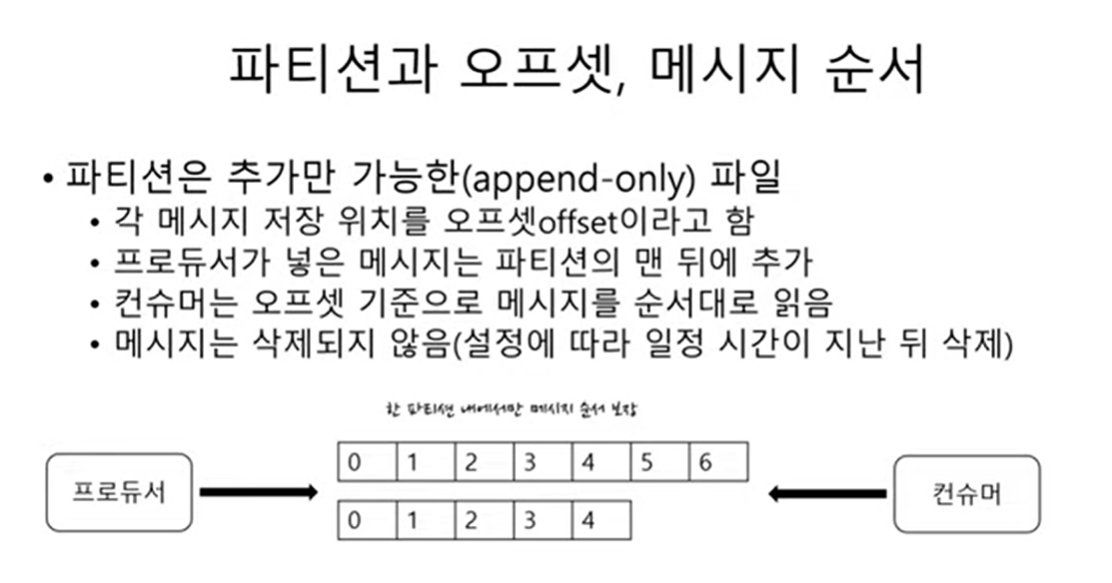
-
Partition 은
append-only파일이고 각각의 메시지가 저장 되는 위치를offset이라고 한다. -
Producer 가 카프카에 메시지를 저장하면 저장된 메시지들은 차례대로 offset-0, offset-1, offset-2 같은식으로 offset 값을 가지게 된다.
-
또한,
append-only file이기 때문에 Producer 가 넣은 메시지는 Partition의 맨뒤에 추가가 된다. (중간에 낄 수 없음) -
Consumer 는 Offset 기준으로 메시지를 순서대로 읽는다. (섞어서 읽지 못함)
-
Partition에 저장된 메시지는 삭제되지 않는다.(파일이기 때문)
-
아래와 같이 저장이 됨.
여러 파티션과 프로듀서
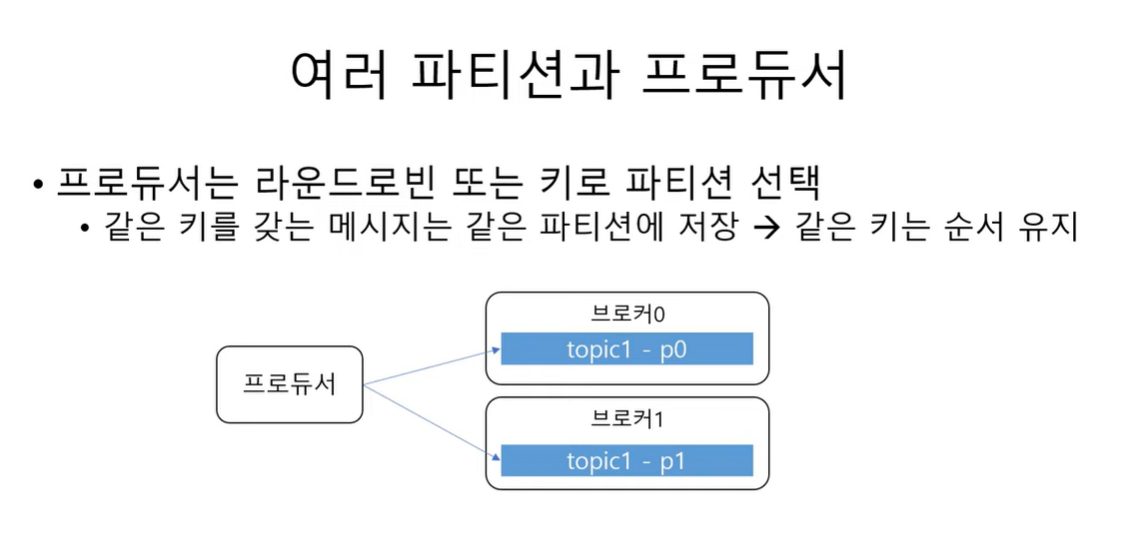
토픽이 여러 파티션으로 구성될 수 있다고 했다. 그렇다면 producer는 어떤 파티션에 메시지를 저장할까 ?
-
RR(Round-Robin) 방식으로 돌아가면서 저장한다.
-
key를 이용해서 파티션을 선택한다.
-
producer 가 카프카에 메시지를 전송할 때 토픽의 이름뿐만 아니라 key도 저장할 수 있음.
-
key 가 있는 경우 key 의 hash 값을 이용해서 저장 할 토픽을 선택하게 된다.
-
같은 key 를 갖는 메시지는 같은 파티션에 저장된다.
-
이는 같은 key 에 대해서는 메시지의 순서가 유지됨을 의미함.
RR 이란?
시분할 시스템을 위해 설계된 선점형 스케줄링의 하나로서, 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum/Slice)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘.
같은말로, 컴퓨터 운영에서, 컴퓨터 자원을 사용할 수 있는 기회를 프로그램 프로세스들에게 공정하게 부여하기 위한 한 방법으로서, 각 프로세스에 일정시간을 할당하고, 할당된 시간이 지나면 그 프로세스는 잠시 보류한 뒤 다른 프로세스에게 기회를 주고, 또 그 다음 프로세스에게 하는 식으로, 돌아가며 기회를 부여하는 운영방식이라 풀어 말할 수 있겠습니다.
보통 시간 단위는 10 ms ~ 100 ms 정도로, 시간 단위동안 수행한 프로세스는 준비 큐의 끝으로 밀려나게 되고, 문맥 전환의 오버헤드가 큰 반면에 응답시간이 짧아지는 장점이 있어 실시간 시스템에 유리합니다.
여러 파티션과 컨슈머
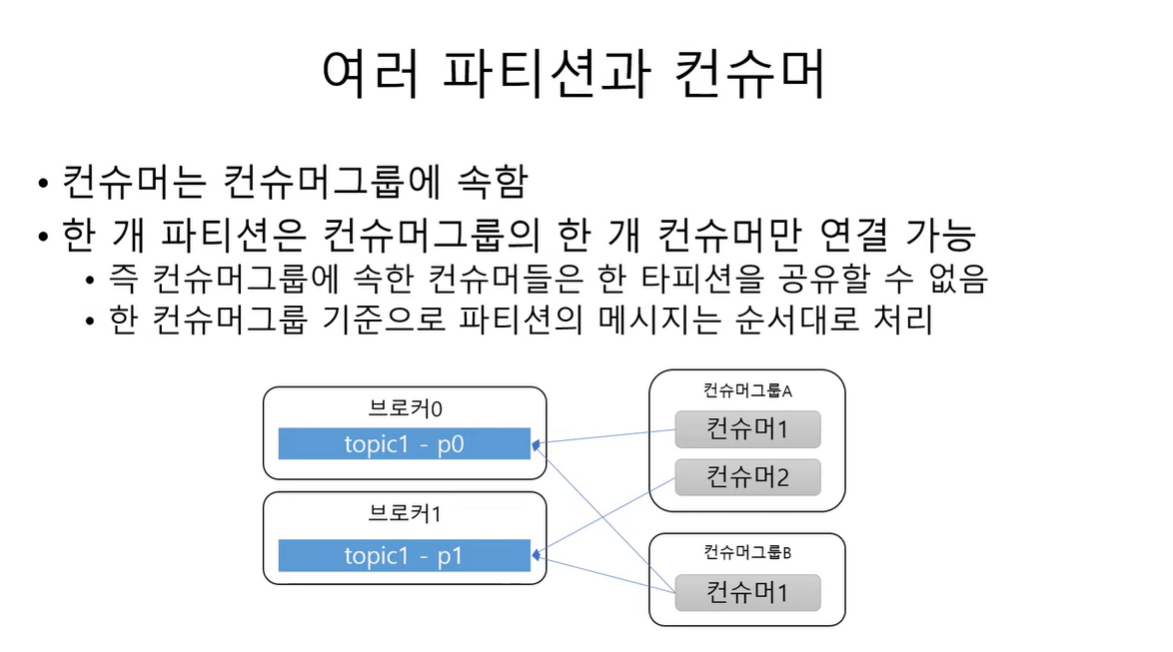
Consumer 는 Consumer Group 이라는 곳에 속하게 된다.
-
Consumer 가 카프카 브로커에 연결할 때 나는 어떤 그룹에 속한다 라고 지정을 하게 되어 있음.
-
한개의 파티션은 해당 그룹의 한개 Consumer 에만 연결이 가능하다.
-
그룹에 속해 있는 Consumer 들은 특정한 파티션을 공유할 수 없음.
-
위의 그림에서 그룹 A에 있는 컨슈머 1,2는 파티션 0 과 1에만 각각 연결할 수 있고, 컨슈머 1과 컨슈머 2는 파티션 0 이나 1을 함께 공유할 수는 없음.
-
따라서 한개의 Consumer 만 한개의 파티션을 연결 할 수 있기 때문에 Consumer Group 기준으로 파티션의 메시지가 순서대로 처리되는 것을 보장할 수 있게 된다.
-
한개의 파티션이 한개의 Consumer 만 연결 할 수 있다는 제한은 Consumer Group 내에서만 적용 되기 때문에 한개의 파티션을 서로 다른 그룹의 컨슈머는 공유할 수 있음.
카프카의 성능
Kafka 는 Patition File 대해서 OS 가 제공하는 PageCache 를 사용한다.
- 파일 IO 가 실제로는 메모리에서 처리되기 때문에 IO속도가 빨라짐.
Zero Copy
- 디스크에서 데이터를 읽어서 네트워크로 보내는 속도가 빨라짐.
브로커가 컨슈머에 대해서 하는일이 별로 없음
- 보통의 메시지 시스템은 메시지를 필터하거나 재전송하는 일련의 작업을 진행하는데 카프카 브로커는 진행하지 않기 때문에 더욱 빠름 (producer와 consumer 가 직접 함.)
묶어서 보내고, 받음 (batch)
-
프로듀서는 일정 크기만큼 메시지를 묶어서 한번에 보낼 수 있고, 컨슈머도 일정 크기만큼 묶어서 받아 올 수 있음.
-
낱개로 건건 마다 보내는 것보다 처리량 증가
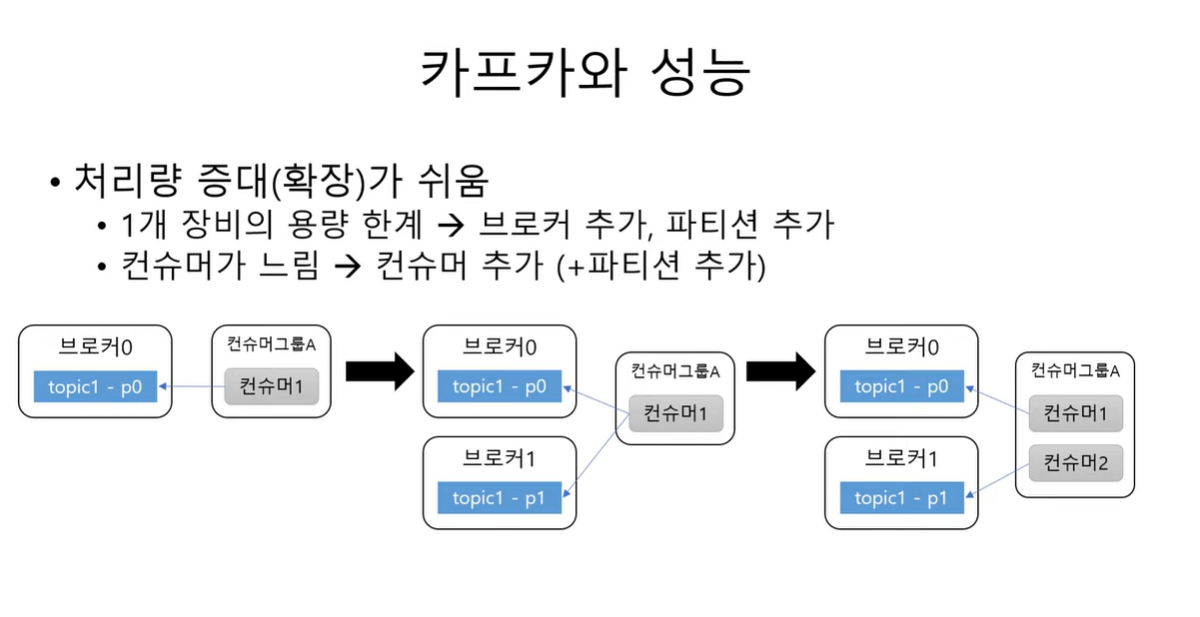
처리량을 확장하기 쉬움.
-
1개의 장비에서 용량이 모자르면 브로커 와 파티션을 추가하면 됨.
-
컨슈머가 느리면 컨슈머 추가 & 파티션을 추가하면 됨.
-
수평확장이 용이함.
Kafka의 장애처리 - 레플리카
레플리카
-
파티션의 복제본이다. 복제 수 만큼 파티션의 복제본이 각 브로커에 생기게 된다.
-
토픽을 생성할 때 복제수를 2로 지정하면, 동일한 데이터를 가지고 있는 파티션이 서로다른 브로커에 2개가 생기게 됨.
-
하나가 리더가 되고 나머지를 팔로워가 된다. 프로듀서와 컨슈머는 리더를 통해서만 메시지를 처리하게 되고, 팔로워는 리더로부터 복제하게 됨.
-
리더가 속한 브로커 장애 시 다른 팔로워가 리더가 됨.
영상참초
