
✐ 통계분석
✔︎ 탐색적 분석
- 데이터에 대한 요약과 일부르 보여준 뒤, 데이터 분석 방법과 인사이트를 제시하는 문제
✍︎ 작성해야 하는 내용
- 제시된 데이터에 대해 어떻게 이해하고 있는지 기술해야 한다.
- 적절한 분석방법론을 나열해야 한다.
- 예상되는 가상 분석 결과를 제시해야 한다.
- 3에서 제시한 가상 분석 결과를 통해 어떤 인사이트를 얻게 될지 예상하여 기술해야 한다.
- 추가로 분석 과정에서 예상되는 주의 사항 등을 추가하면 더 좋은 점수를 얻을 수 있다.
✔︎ 회귀분석
- 주로 얘가 많이 나온다.
✍︎ 작성해야 하는 내용
- 분석 결과 중 유의한 설명변수를 파악하여 작성해야 한다.
- 회귀 모형의 유의성 검토에 대한 내용이 필요하다.
- p-value
- 결정 계수를 해석해야 한다.
- R-squared, Adjusted R-squared(다중회귀분석은 이걸 더 봐야 한다.)
- 모형 수식을 작성해야 한다.
- 1번에서 파악한 통계적으로 유의한 설명변수를 이용하여 모형의 수식을 작성
- 이 모형을 통해 알 수 있는 사실까지 적어주면 더 좋은 점수를 얻을 수 있다.
- 귀무가설 : 설명변수의 계수가 모두 0이다.
- 대립가설 : 적어도 하나의 설명변수의 계수는 0이 아니다.
- F-통계량, p-value값을 확인하고, 귀무가설의 기각역인 0.05와 비교했을 때 어떤지, 따라서 어떤 가설을 채택하는지 & 추정된 회귀모형은 통계적으로 유의한지
- t값과 Pr(>|t|) (p값)을 이용하여 각 설명변수들의 계수에 대한 통계적 가설검정 실시
- t-통계량과 p-value(Pr(>|t|)값을 확인하고, 귀무가설의 기각역인 0.05와 비교했을 때 어떤지, 따라서 어떤 가설을 채택하는지 & 해당 설명변수는 통계적으로 유의한지
- 결정계수를 확인할 때, Multiple R-squared와 Adjusted R-squared를 모두 적어주고, 이것은 전체 데이터를 설계된 (다변량) 회귀모형이 OO%, OO%를 설명하고 있다고 해석할 수 있다는 말을 적어야 한다.
- 최종적으로 추정된 회귀식을 적는다.
- (종속변수)=
- 위의 회귀식을 통해 알 수 있는 것들을 적는다.
심화과정 : 벌점화 방식(AIC) 변수선택법을 활용한 다변량 회귀분석
- 변수선택법을 결정하고 초기 모형을 세팅한다.
- 선택된 최적 모형의 AIC를 계산한다.
- 선택된 모형에서 변수를 추가/삭제할 경우 각 모형에서 AIC를 계산한다.
- 각 모형에서 최소의 AIC 모형을 선택하여 최적 모형으로 선정한다.
- 2~4단계를 반복하고, AIC가 더 이상 줄어들지 않을 때 최종모형을 최적 모형으로 선정한다.
- 다변량 모형에 대한 F-test를 통해 가설검정을 실시한다.
- 각 변수의 계수에 대한 t-test를 통해 가설검정을 실시한다.
- 결정계수를 통해 모형에 대한 설명력을 확인한다.
✔︎ 주성분 분석
- 주성분 분석의 누적 기여율과 시각화 자료인 Scree plot, biplot에 대한해석이 필요하다.
✍︎ 작성해야 하는 내용
- 주성분 분석에 대한 Summary가 나온 경우
- Summary에 대한 설명과 의미를 제시한다.
- 이를 통해 해석 가능한 인사이트를 제시한다.
- 가상의 결과를 가지고 어떤 주성분이 어떤 변수와 관련이 있는지
- Scree plot이 나온 경우
- Scree plot이 어떤 의미를 포함하고 있는지, 왜 사용하는지
- 2차원 그래프에서 x축에는 주성분의 개수, y축에는 분산이나 고윳값을 두어 주성분 분석에서 요인의 수를 결정하기 위해 사용한다.
- 해석은 어떻게 하는지
- y축의 값이 수평을 유지하기 전 단계로 주성분의 개수를 선택한다.
- Scree plot이 어떤 의미를 포함하고 있는지, 왜 사용하는지
- biplot이 나온 경우
- biplot이 어떤 의미를 포함하고 있는지, 왜 사용하는지
- 원 변수와 주성분(Comp1, 2) 간의 관계를 그래프로 표현한 것으로 그래프를 통해 각 주성분의 의미를 해석하고 각 개체들의 특성을 파악할 수 있다.
- 화살표는 원 변수와 Comp의 상관계수를 의미하며, 화살표가 Comp와 평행할 수록 상관계수가 크므로 해당 Comp에 큰 영향을 끼친다.
- 화살표가 같은 방향으로 인접해 있을 수록 같은 주성분으로 생성될 수도 있음을 알 수 있다.
- 해석은 어떻게 하는지
- 변수 방향, 상관관계가 동떨어진 것들은 이상치로 분류한다.
- 하나의 변수에만 영향을 많이 받는다면 그것은 이상치
- 모든 변수에 영향을 거의 받지 않는다면 그것은 이상치
- 이상치를 이용하여 인사이트를 도출할 수도 있다.
- biplot이 어떤 의미를 포함하고 있는지, 왜 사용하는지
✔︎ 로지스틱 회귀분석
- 해석 방법은 일반 선형 회귀분석과 비슷하다.
- 유의미한 설명변수 파악, 회귀 모형의 유의함, 결정 계수 해석, 모형 수식 작성, 오즈비를 이용한 해석 등이 필요하다.
- 로지스틱 회귀식
✍︎ 작성해야 하는 내용
- 변수선택법을 결정하고 초기 모형을 세팅한다.
- 선택된 최적 모형의 AIC를 계산한다.
- 선택된 모형에서 변수를 추가/삭제할 경우 각 모형에서 AIC를 계산한다.
- 각 모형에서 최소의 AIC 모형을 선택하여 최적 모형으로 선정한다.
- 2~4단계를 반복하고, AIC가 더 이상 줄어들지 않을 때 최종모형을 최적 모형으로 선정한다.
- 각 변수의 계수에 대한 가설검정을 실시한다.
- 이때, 귀무가설은 각 설명변수별로 그 값이 0이라는 것이고, 대립가설은 각 설명변수별로 그 값이 0이 아니라는 것이다. 따라서 가설검정은 설명변수의 개수만큼 반복한다.
- 모형 수식을 작성한다.
- 모형 수식을 통해 알 수 있는 사실을 적어주는 것이 좋다.
- 만약 어떤 설명변수가 boolean이라면, 0 또는 1의 값만 가지므로 결과 해석을 유의해서 해야 한다는 결론을 내릴 수 있다.
✔︎ 의사결정나무
- 모델링 결과, 교차타당성 오차에 대한 해석이 필요하다.
✍︎ 작성해야 하는 내용
- 결과에서 조건에 따른 분류에 대해 파악하고, 설명한다.
- 시각화 결과에 대핳여 해석하고, 인사이트를 도출한다.
✔︎ 앙상블
- 배깅, 부스팅, 랜덤포레스트가 있지만 일단 나중에..
✍︎ 작성해야 하는 내용
✔︎ 나이브 베이지안
- 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기의 일종
- 텍스트 분류에 사용되어 문서를 여러 범주 중 하나로 판단하는 문제에 나온다.
- 하나의 속성 값을 기준으로 다른 속성들이 독립이라 전제했을 때, 해당 속성값이 클래스 분류에 미치는 영향을 측정한다.
✍︎ 작성해야 하는 내용
- 나이브 베이지안 수식
- 위의 수식을 통해 다음을 도출할 수 있다.
- 쉽게 말해, 이다.
- 를 모르는 상태에서 를 구할 수 있다.
✔︎ 군집분석
- 덴드로그램 해석
- 덴드로그램은 각 단계에서 관측치의 군집화를 통해 형성된 그룹과 이들의 유사성 수준을 표시하는 트리 다이어그램이다.
- 유사성 수준은 수직 축을 따라 측정되거나 사용자가 거리 수준을 표시할 수 있는데, 다른 관측치는 수평축을 따라 나열된다.
- 비계층적 군집분석(K-means)
- 모든 개체가 군집으로 할당될 때까지 군집과정을 반복한다.
- (between_SS / total_SS)의 값이 1에 가까울수록 잘 분류되었고 좋은 모델임을 나타낸다.
✐ 기타 알아두면 좋은 것들
✔︎ 혼동행렬(오분류표)
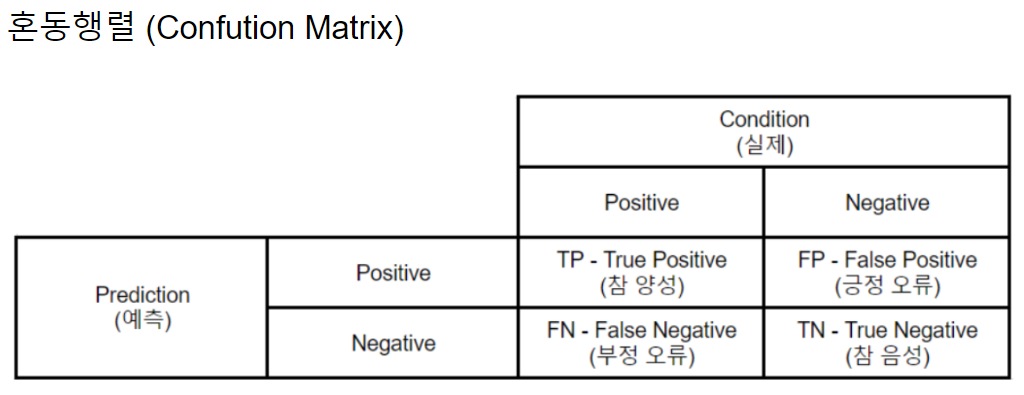
-
정분류율(Accuracy)
-
오분류율(Error Rate)
-
특이도(Specificity) = TNR(True Negative Rate)
-
민감도(Sensitivity) = TPR(True Positive Rate) = 재현율(Recall)
-
정확도(Precision)
-
F1 Score
✔︎ 최적회귀분석 방법
- AIC를 최소화하는 방향으로
✔︎ 주성분 분석
- Cumulative Proposition이 70~90%가 되면 선택 종료
✔︎ 불순도 측정
지니지수
- 지니지수의 값이 클수록 이질적이며 순수도가 낮다고 볼 수 있다.
엔트로피 지수
- 엔트로피 지수의 값이 클수록 순수도가 낮다고 볼 수 있다.
- 엔트로피 지수가 가장 작은 예측 변수와 이때의 최적분리규칙에 의해 자식마디를 형성한다.(의사결정나무)

Data + Math