1. Pattern Discovery in Data
데이터에서 규칙성을 찾는 것은 고전 역학부터 양자 역학에 이르기까지 과학 발전의 근간이 되어온 중요한 문제이다.
1.1 Pattern Recognition
- automatically discover regualarities in data
- and use these regualarities to make decision
- e.g., classifying the data into different categories
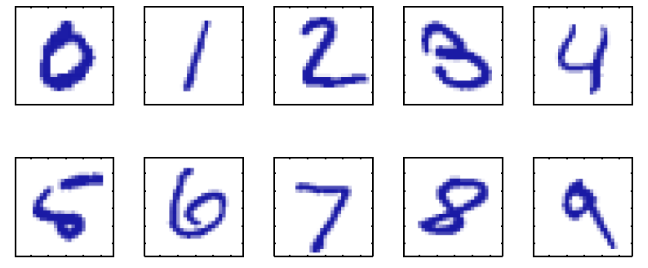
- handwritten digit recognition
1.2 Machine Learning
- a large set of input vectors , or a training set is used
- to tune the parameters of an adaptive model
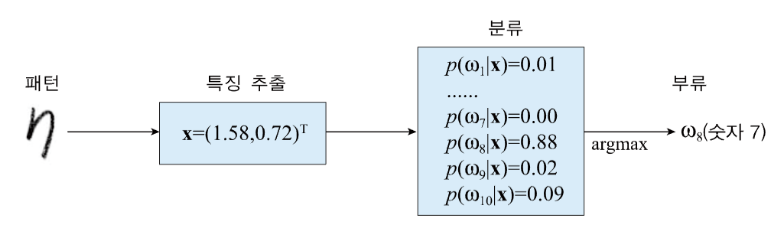
- the category of an input vector is expressed using a target vector
- the result of algorithm: where the output is encoded as target vectors
입력 는 숫자 이미지의 각 픽셀 값들이고, 타겟 벡터 는 모델이 도달해야 하는 목표, 해당 이미지의 실제 정답을 의미한다.
1.3 Why Probability is Important in Data Mining
Goal
- discover meaningful patterns from large datasets
Challenge
- real-word data is urcentain and noisy due to measurement errors or incomplete information
Solution
- Probability theory provides a mathematical framework to model and reason about uncertainty
Applications
- key tasks rely on probabilistic reasoning
- clssification, clustering
- recommendation systems
- anomaly detection
- predictive modeling
Benefit
- allows us to quantify uncertainty and make informed decisions
- e.g.,
- spam detection
- purchase likelihood
확률로 불확실성을 정량화하고 위험을 종합적으로 따져 논리적인 결론을 도출한다.
2. Basic Concept of Probability
2.1 Fundamentals
Experiment
- a process that produces outcomes that cannot be predicted with certainty
- e.g., tossing a coin, rolling a die
Sample Space
- the set of all possible outcomes of an experiment
- e.g., die roll
Event
- a subset of the sample space representing outcomes of interest
- e.g., even number
2.2 Conditional Probability
- the probability of event occuring given that event has already occurred
- the formula is provided that
2.3 Random Variables
- a function that assigns a numerical value to the outcome of a random experiment
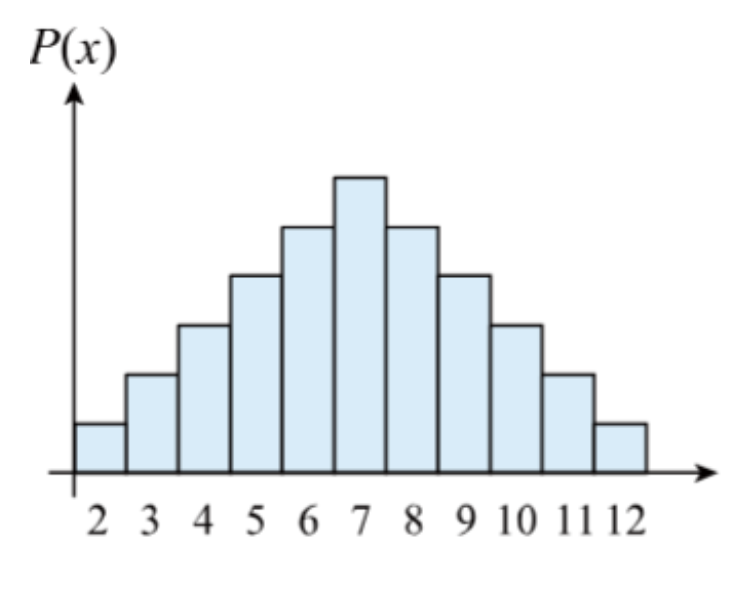
1. Discrete Random Variable
- takes a finite or countably infinite set of values
- described by a probability mass function(PMF)
2. Continous Random Variable
- takes any value within an interval
- described by a probability density function(PDF)
Importance
- they translate real-word uncertainty into mathematics forms to compute expectation and variance for decision-making
2.4 Independence
- two events and are independent
- the occurrence of one does not affect the probability of the other
- equivalently
In Data Mining
- Naive Bayes assumes features are conditionally indepedent given the label to simplify calculations
- e.g., email classification features
사실 현실에서는 "free"와 "win" 같은 단어가 스팸 메일에 함께 자주 등장하므로 이 가정은 비현실적이다. 하지만 계산을 단순화해도 뛰어난 성능을 보이기 때문에 널리 사용한다.
2.5 Bayes' Theorem
Prior Probability
- initial belief about an event before observing any evidence
초기의 믿음, 가진 정보를 의미한다.
Likelihood
- the probability of observing evidence given that hypothesis is true
- how well the hypothesis explains the observed data
Posterior Probability
- the probability of an event after observing evidence
- it updates the prior probability using new information
새로운 정보를 이용해서 사전 확률을 업데이트하는 과정이다.
Bayes' Theorem
- : marginal probability(nomalization constant) calculated as
한계 확률 또는 정규화 상수라고 불리며 관찰된 증거가 나타날 전체 확률을 의미한다. 위 식에서 분자만 계산하면 합이 1이 되지 않을 수 있기에 로 나누어 결과값들을 0과 1 사이로 맞춘다.
정규화 상수
E.g.,
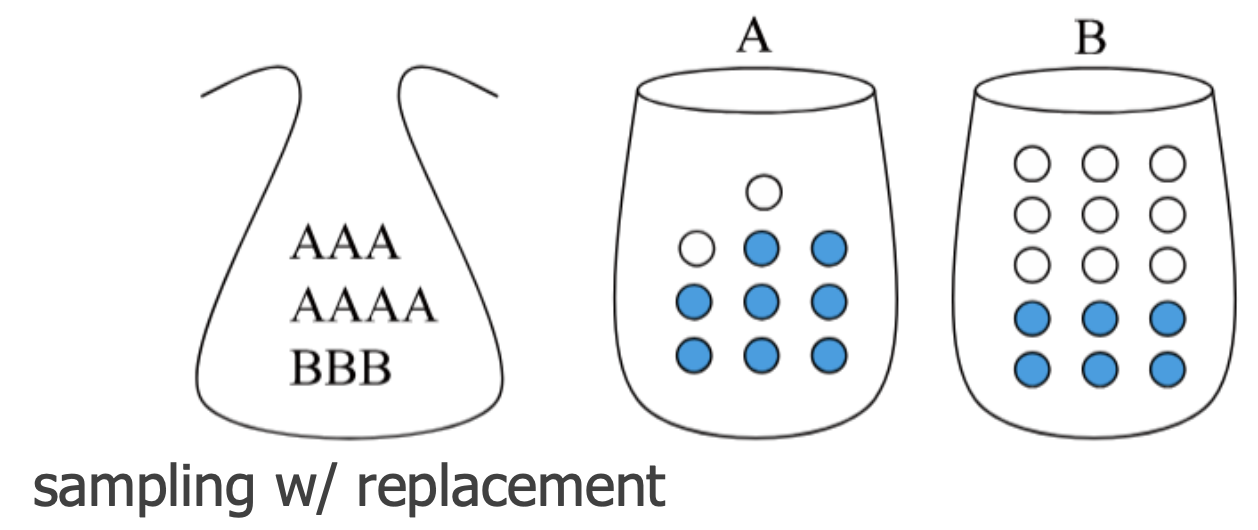
- joint Probability: P(A,white)
- marginal Probability: P(white)
- posterior Probability: P(A∣white)
- updating the probability of choosing Bag A after seeing a white ball
3. Bayesian Decision Theory
Definition
- a fundamental statistical approach to learning from data
- quantify the trade-offs between different decisions using probabilities and associated costs
확률과 각 결정에 따르는 비용을 이용해 서로 다른 의사결정 간의 trade-off를 정량화하는 데 기반한다.
Assumptions
- problems are posed in probabilistic terms, and all relevant probability values are known
E.g.,
- sorting fish based on features
- sea bass vs. salmon
전형적인 베이지안 결정 이론 예제로 관찰된 특징(무게, 길이, 색상)에 대한 조건부 확률을 이용해 어느 클래스에 속할지 결정한다.
관찰된 데이터(특징 )가 주어졌을 때, 각 클래스()의 likelihood를 측정한다.
4. Bayesian Classifier
4.1 Posterior Classifier
- = Bayes Classifier
- assign observation to the class with the highest posterior probability
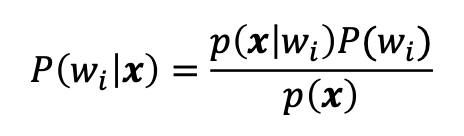
: posterior probability
:: likelihood
: prior probability
: evidence
Binary Classification
- , then classify belongs to
- , then classify belongs to
4.2 MAP Classifier
- computing the posterior probability directly is difficult
- since the evidence is constant for all classes, it can be ignored during comparison
- choose the class with the largest (likelihood prior)
Binary Classification
- , then classify belongs to
- , then classify belongs to
Bayes classifier에서 어차피 비교만 할 거면 p(x)를 계산할 필요가 없어, p(x)를 생략하고 likelihood x prior만 비교한다.
4.3 ML Classifier
- if we have the same prior, we can omit and Maximum Likelihood Classifier
- choose the class with the larget likelihood:
: PDF(연속형 확률 변수)
: PMF(이산형 확률 변수)
: 연속적인 를 관측했을 때, 이 물고기가 어떤 이산적 클래스에 속할 확률

| Classifier | Decision Rule | Meaning |
|---|---|---|
| Posterior Classifier | 최고 사후 확률 클래스 선택 [1, 3] | |
| MAP Classifier | 우도(Likelihood) × 사전 확률(Prior) [1-3] | |
| ML Classifier | 우도(Likelihood)만 고려 [2, 3] |
4.4 Error Probability
- even with the most optimal classifier, errors are unavoidable whenever class districutions overlap
Definition
- the probability that a classifier assigns a sample to the wrong decision region
Decision Regions
- these denote the areas in the feature space assigned to specific classes
- e.g., if a sample fails in , it is classified as
오류 확률은 샘플이 실제 속한 클래스가 아닌 잘못된 결정 영역에 할당된 확률이다.
General Formula
- assuming two districutions have the same prior, the error calculated as
- the integrals measure the misclassified probability mass, which is represented by the shared area in the distribution graph
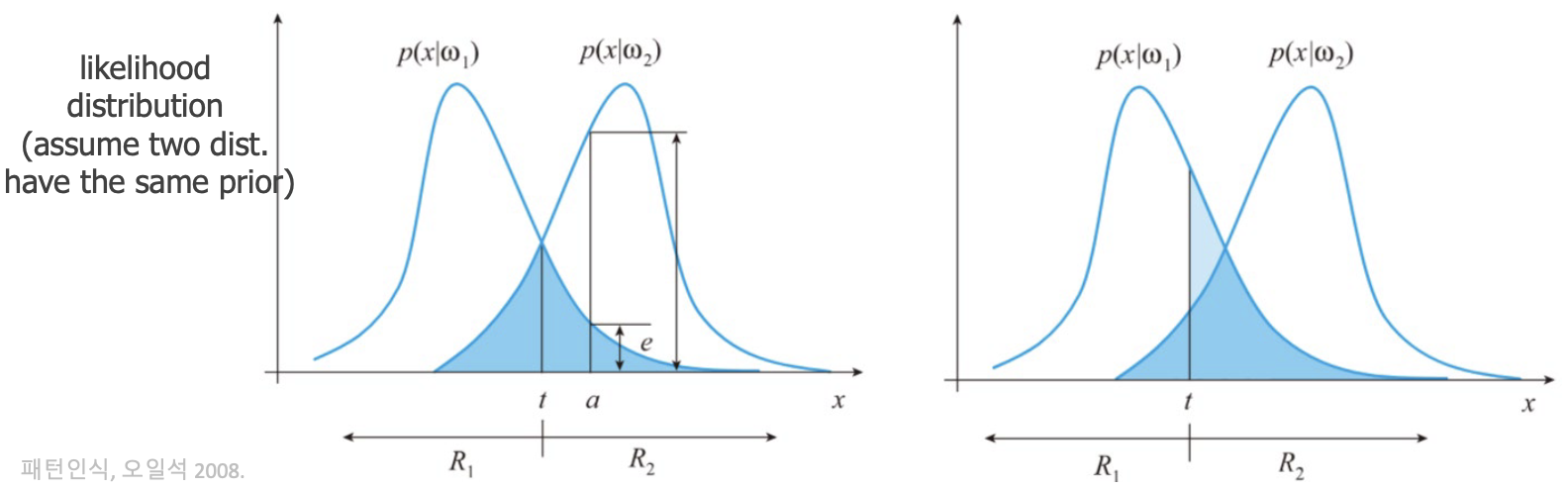
- the level of overlap between the likelihood distributions and is critical
- the more they overlap, the higher the error rate will be
5. Minimum Risk Bayesian Classifier
5.1 Beyond Error Rate: Expected Risk
The problem with Error Rate
- minimizing the error rate implicitly assumes that every mistake costs the same
The Reality
- in practice, different errors have different consequences
- e.g., false alarms vs. missed detections
The Goal
- incorporate these different "loss" values into the decision-making process to minimize the Expected Risk rather than just the number of errors
5.2 Loss Matrix
Definition
- a matrix that quantifies the penalty for every possible decision
Notation
- the loss incurred when the true class is , but the classifier decides it is
- : correct decision (0 or very low cost)
- : incorrect decision (penalty > 0)
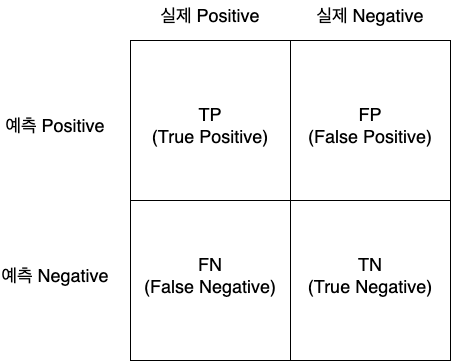
5.3 Conditional Risk for a Sample
- when we observe a sample , we must choose between deciding or
- : the total risk we take by calling is a
- it considers both the chance that is actually (correct) and the chance it is (wrong)
- : the risk of calling is a
특정 결정을 했을 때 기대되는 손실을 conditional risk라고 부른다.
Decision Rule
- we decide if its risk is lower than )
두 클래스 중 하나를 결정해야 할 때, 조건부 위험이 더 작은 쪽을 선택한다.
5.4 Likelihood Ratio
- by rearranging the inequality , we get the final decision rule based on the Likelihood Ratio
Likelihood Ratio
Thereshold
- the right-hand side is a constant value (independent of )
- the classifier simply compares the ratio of the two likelihood against this threshold
우변은 미리 설정한 손실 비용과 사전 확률, 즉 상수이다. 에 대한 두 클래스의 우도비를 구한 뒤, 이미 계산해 둔 고정된 임계값보다 큰지 작은지만 확인하여 클래스를 결정한다.
5.5 Boundary Shifting
MAP as a Special Case
- if all misclassification costs are equal and , this rule simplifies back to the MAP classifier
Shifting
- if the cost of misclassifying increases ( gets larger), the thereshold becomes smaller
- this shifts the decision boundary to make it "easier" to classify something as to avoid the high cost of missing it
틀렸을 때 더 위험한 클래스가 있다면 thereshold를 낮춰서 더 적극적으로 찾아내도록 분류기를 조정한다.
6. Naive Bayes Spam Filter
classify emails as spam or non-spam using Bayes's theorem!
Naive Assumption
- features are assumed to occur independently given the class label to simplify calculation
단어들이 서로 독립이라고 가정하기 때문에 naive하다.
Parameter
- prior : the proportion of spam emails in the total training set
- likelihood : the probability that word apeears in a spam email
Classification Rule
- calculate the posterior probability:
- the email is classified as spam if this value is higher than the probability for non-spam class
Practicality
- although the independence assumption is often unrealistic, the method performs well in practice
