1. Uncertainty and Information Theory
1.1 Uncertainty in Data Mining
- Many data mining tasks involve making predictions under uncertainty, such as in classification where the goal is to predict a class label from an input feature vector
- This relationship is expressed as the posterior probability , which is the probability that an instance belongs to class given the observed features
- Real-world datasets contain uncertainty due to noisy data, missing attributes, overlapping feature distributions, and measurement errors
- overlapping feature distributions
- 서로 다른 클래스의 특징값 분포가 겹침
- A 클래스와 B 클래스가 어떤 feature에서 비슷한 값들을 많이 가져서 경계가 뚜렷하지 않은 상태
- overlapping feature distributions
- Information theory provides a mathematical framework for quantifying this uncertainty using concepts like entropy, conditional entropy, and mututal information
- entropy:
- conditional entropy:
- mutual information:
정보이론으로 불확실성을 수량화하는 수학적 프레임워크를 만들 수 있다.
1.2 Introduction to Information Theory
- Introduced by Claude Shannon in 1948 to study how information can be efficiently transmitted through channels
- Key objectives: Quantifying information in a message, measuring uncertainty in random variables, and understanding the relationship between probability distributions and information
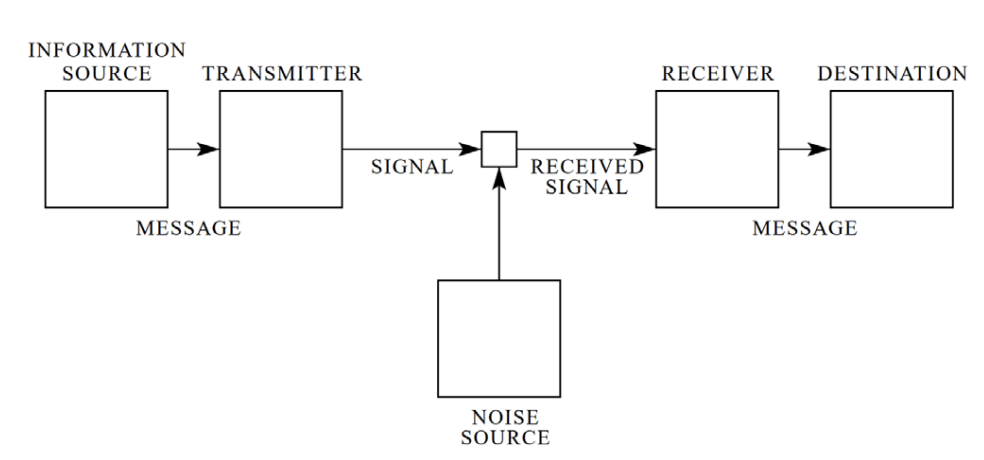
확률 분포와 불확실성의 관계를 측정, 데이터 마이닝에서 확률 분포 간 관계를 정량화한다.
2. Self-Information and Entropy
2.1 Self-Information: Information of an Event
Definition:
- It measures the information content of a single event
- If an event is unlikely (low probability), it provides more information
Properties
- Non-negative: , 확률 이므로 로그값 항상 0 이상
- Monotonic: 가 작을수록 가 커짐
- 희귀 사건이 많을수록 더 많은 정보를 가짐
- Additive for independent events: (, 독립일 때)
2.2 Entropy: Uncertainty of a Distribution
Definition:
- It is expected value of self-information or the average information produced by a random variable
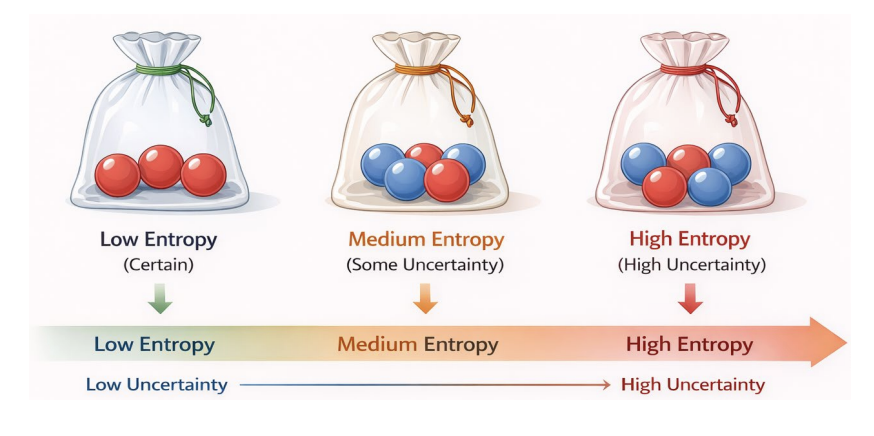
- Low entropy high certainty, while High entropy high uncertainty
Properties
- Non-negativity:
- 모든 확률 값은 0과 1 사이이므로 엔트로피 값은 음수가 될 수 없음
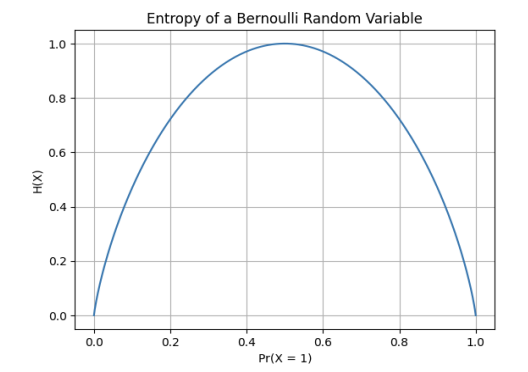
- Maximum entropy(max): 모든 결과가 동등하게 가능할 때 (은 가능한 결과 개수)
- 모든 결과가 균등하게 발생할 때 불확실성은 최대
- Deteministic case(min): 한 결과만 확정(확률 1)일 때
- 완전한 확실성으로 인해 결과가 완전히 예측 가능, 불확실성이 없는 상태
3. Conditional Entropy and Mutual Information
3.1 Conditional Entropy
Definition
- Conditional entropy measures the remaining uncertainty of a random variable after observing another variable
- measures how much uncertainty in remains after knowing
Mathematical Definition
- Alternative form: (Conditional entropy is the expected uncertainty over )
- : x가 딱 하나로 고정, 확률 안 곱함
- : x가 여러 값, 각각의 확률 를 가중치로 곱해서 평균냄
Interpretation
- If strongly predicts conditional entropy is small
- If provides little information about conditional entropy is large
X를 알면 알수록 Y에 대한 불확실성이 줄어들고 줄어든 정도를 수치화한 것이 조건부 엔트로피이다.
E.g.,
- Computing the conditional entropy of exam results given study status
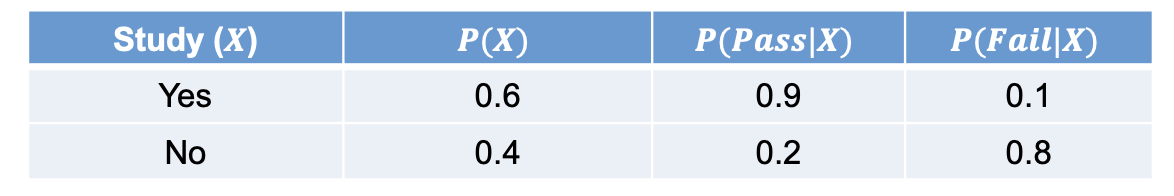
Study 여부에 따른 Pass/Fail 확률 데이터를 통해 특정 조건()이 주어졌을 때 의 불확실성이 어떻게 변하는지 계산하는 기초로 활용한다.
3.2 Chain Rule of Entropy
Definition
- Entropy satisfies an important decomposition rule called the chain rule of entropy
Mathematial Formula
- Similarly,
전체 불확실성을 어떤 변수를 먼저 기준으로 잡느냐에 따라 두 가지로 쪼갤 수 있다.
Interpretation
- The joint entropy represents the total uncertainty of two variables together
- The total uncertainty can b e decomposed into two parts:
- The uncertainty of one variable
- The remaining uncertainty of + remaining uncertainty of after observing
- Total uncertainty = uncertainty of + remaining uncertainty of after observing
3.3 Mutual Information
Definition
- Mutual information measures how much information two random variables share, or how much knowing one variable reduces the uncertainty about the other
Mathematical Definition
- Another formulation:
- : X를 모를 때 Y의 불확실성
- : X를 알고 난 후 Y의 남은 불확실성
- : X를 앎으로써 줄어든 불확실성
- If and are independent, then
Properties
- Non-negativity
- Dependency
- Larger mutual information indicates a stronger dependency between variables
Interpretation
- Independence
- If and are independent,
- Knowing one variable dose not reduce the uncertainty about the other; they do not share any information
- Perfect Prediction
- If knowing allows us to perfectly predict , then
- Once is known, all uncertainty about disappears
- MI measures how strongly two variables are related by quantifying the reduction in uncertainty
MI란 X를 알기 전과 X를 알고 난 후의 불확실성 차이, 그 차이가 크면 클수록 두 변수는 강하게 연관되어 있고 차이가 0이면 아무 관련이 없다.
4. Featrue Selection and Decision Trees
4.1 Mutual Information and Feature Selection
- In data mining, a useful feature provides information about the target variable (label)
Core Idea
- Feature selection can be formulated as maximizing the mutual information
Significance
- High MI with the label significantly reduces the uncertainty of the target
- MI close to zero the feature provides little or no useful information for prediction
Goal
- Features with larger MI are considered more information and improve learning performance
4.2 Information Gain
Decision Tree에서 어떤 기준으로 데이터를 나눌지 결정할 때 사용한다.
- IG represents how much uncertainty about the class label is reduced by knowing the feature
- 나누기 전 데이터 (parent)
- 불확실성:
- 기준으로 나눈 후 (children)
- 불확실성:
- = 나누기 전 불확실성 - 나눈 후 불확실성
4.3 Information-Theoretic Interpretation of Decision Trees
Goal
- The ultimate goal of decision tree learning is to reduce uncertainty about the class label
Process
- At each node, the algorithm evaluates candidate features and selects the one with the highest information gain
Information-Theoretic View
- Selecting the best feature is equivalent to maximizing the mutual information between feature and class label
- Decision tree learning is an iterative process of reducing uncertainty in the dataset
Higher means more uncertainty; observing results in a lower , leading to a reduction in uncertainty
