1. Why data mining?
1.1 Challenge
we are drowning in data, but starving for knowledge
- the key problem is not collecting data,
- but extracting meaningful knowledge
1.2 Solution: data mining
- automated analysis of large-scale data
- pattern discovery and knowledge extraction
- supporting data-driven decision making
2. Evolution of sciences
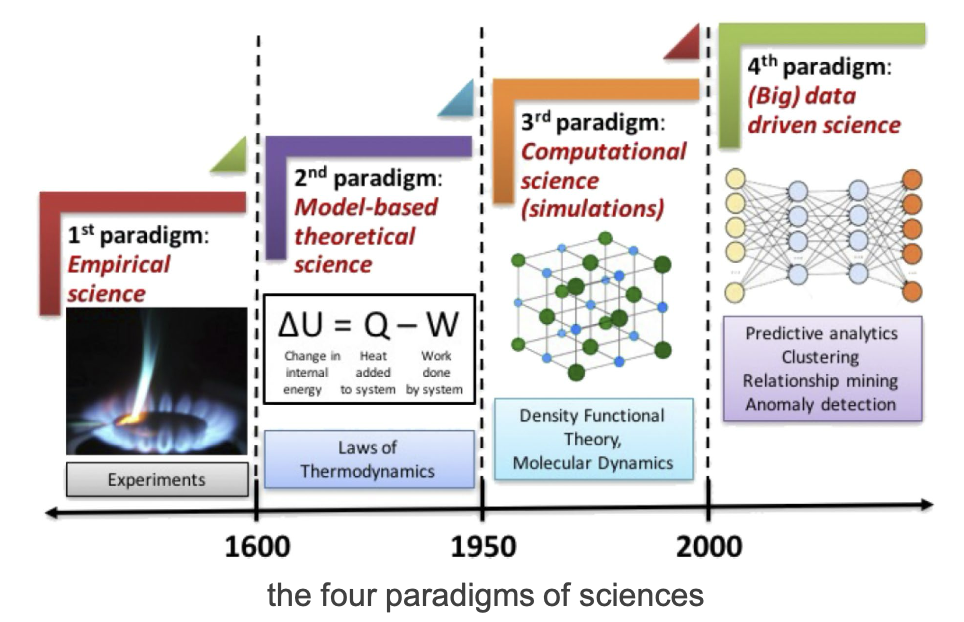
1. Empirical science (~1600)
- knowledge from observation and experiments
- manual data collection
- trial-and-error discovery
2. Theoretical science (1600 ~ 1950s)
- development of mathematical models
- theories explain empirical observations
3. Computational science (1950s ~ 1990s)
- computer-based simulation
- large-scale numerical experiments
Early data management (1960s)
- data collection & database collection
- IMS, network DBMS
- focus on basic storage & retrieval
Relational revolution (1970s)
- introduction of the relational data model
- development of RDBMS
- SQL and data independence
Advanced database systems (1980s)
- mature RDBMS technology
- application-oriented DBMS
- spartial, scientific/engineering databases
4. Data science (1990 ~ now)
- explosion of large-scale data
- advances in storage and internet
The rise of data mining (1990s)
- data warehousing
- data mining techniques
- multimedia, web, etc.,
Large-scale & web-centric era (2000s)
- stream data management & mining
- web technologies
- global information systems
- expansion of data mining applications
5. The new challenge
- data mining
- extracting knowledge from massive, heterogeneous, and fast-changing data
3. What is data mining?
3.1 Data mining
- the process of discovering useful patterns and knowledge from large amounts of data
- the term data mining is somewhat misleading
- it is closer to "knowledge mining from data"
- the idea is similar to mining gold:
- extracting valuable knowledge from large volumes of raw data
3.2 Related terms
- knowledge discovery from data (KDD)
- knowledge extraction
- data / pattern analysis
- data archaeology
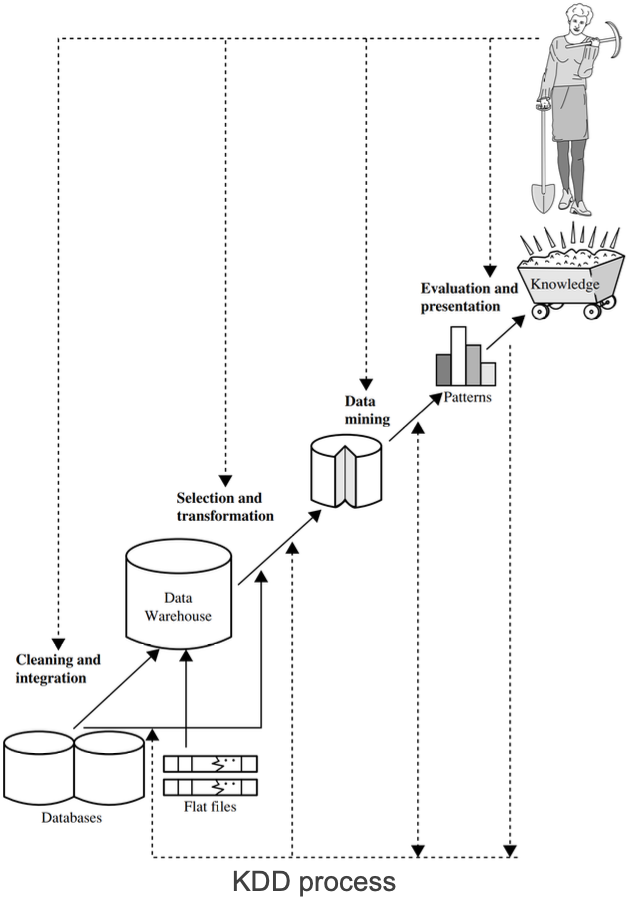
3.3 KDD Process
1. Data cleaning
- remove noise and inconsistencies
2. Data integration
- combine data from multiple sources
3. Data selection
- select relevant data for analysis
4. Data trnasformation
- convert data into suitable format
5. Data mining
- apply algorithms to discover patterns
- 엄밀히는 KDD 전체 프로세스 안에서 데이터마이닝은 알고리즘을 적용해 패턴을 찾는 한 단계이다.
6. Pattern evaluation
- identify interesting and meaningful patterns
7. Knowledge presentation
- visualize results
1-4단계는 데이터 전처리(Preprocessing)로 묶어서 부른다.
data mining aims to discover interesting patterns and knowledge from large-scale data
4. What kinds of data can be mined?
- data mining can be applied to any meaningful data for a target application
4.1 Basic types
- database data
- relational databases, managed by DBMS, queried using SQL

- data warehouse data
- integrated data from multiple sources
- organized for decision support
- represent multidimensional data as cubes
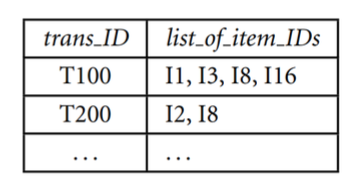
- transactional data
- records of transactions (e.g., purchases)
- each transaction contains a set of items
- used for market basket analysis
4.2 Complex types
- time-series / series data
- stock prices, biological sequences
- data streams
- sensor data, network traffic
- spatial data
- geographic information, maps
- text data
- documents, product reviews
- multimedia data
- images, audio, video
- graph
- social networks, web graphs
- web data
- web pages, hyperlinks, user behavior sequence data
5. What kinds of patterns can be mined?
5.1 The main functionalities include:
Characterization & discrimination
- summarizes the characteristics of a target class and compares it with other classes
Associations & correlations
- discovers patterns and relationships that frequently occur together in data
- 자주 같이 등장하는 패턴, 상관관계 발견으로 장바구니 분석 등에 활용된다.
Classification & regression
- builds models to predict class labels or numerical values from data
Clustering
- groups similar data objects into clusters without perdefined class labels
Outlier detection
- identifies data objects that significantly deviate from normal patterns
앞 목차가 어떤 데이터를 이었다면, 여기에서는 어떤 목적으로 분석하느냐를 의미한다.
6. Types of data mining tasks
6.1 Descriptive mining
- describes general properties of data
- finds patterns that summarize the data
- e.g., clustering, association rules, characterization
6.2 Predictive mining
- uses current data to predict unknown values
- e.g., classification and regression
7. Which technologies are used?
data mining has incorporated many technologies from other domain
Statistics
- studies the collection, analysis, interpretation, and presentation of data (mathematical foundation)
- statistical models describe data using random variables and probability distributions
- these models can represent the behavior of objects within a target class
- in data mining
- summarize and describe data
- build predictive models
- handle noise and missing values
- validate discovered patterns using hypothesis testing
- statistical techniques help determine
- whether discoverd patterns are statistically significant or simply occur by chance
- applying statistical methods to large datasets can be challenging
전통 통계 알고리즘은 계산 비용이 커서 대규모, 실시간 데이터에는 효율적인 알고리즘이 필요하다.
Machine Learning
- studies how computers can learn from data and improve their performance automatically
- main learning approaches include:
- supervised learning: classification
- unsupervised learning: clustering
- semi-supervised learning: 소량의 라벨 + 많은 비라벨로 성능 개선
- active learning: 사람이 선택된 예제만 라벨링해 효율적으로 모델 개선
- machine learning research often focuses on improving model accuracy
- whereas data mining also emphasizes efficiency and scalability when handling very learge datasets
Database & data warehouse
- focus on the storage, management, and retrieval of large volumes of structured data
- key database technologies include:
- data models
- query languages such as SQL
- query processing and optimization
- indexing and data access methods
- data mining frequently relies on database technologies to effciently process large datasets
- a data warehouse integrates data from multiple sources and organizes them into a unfied repository
- data warehouses often use multidimensional data structures such as data cubes, which support OLAP operations and multidimensional data mining
Information retrieval
- searching and retrieving information from large collections of documents
- the data involved are usually unstructured
- text documents
- web pagaes
- multimedia data
- IR systems often use probabilistic models to measure the similarity between documents
데이터마이닝과 결합하면 대규모 문서/웹 컬렉션에서 토픽을 찾고 문서, 웹 콘텐츠 간 관계를 이해할 수 있다.
