1. Regression
1.1 Definition
- a statical method to study relationship between and y
- : covariate / predictor variable / independent variable / feature
- : response / dependent variable
- training data , , ... ,
- noise is added to target
- instead of
Goal
- find a model that approximate
1.2 Etymology
- re(back) + gression(going)
- going back from data to formula
- regression towards the mean
- tail and short men tend to have sons with heights closer to mean
Simple Linear Regression
1.3 Linear Regression
- popular linear model for predicting a quantitative response
- applies to real-valued target functions
- long history in statistics, social and behavioral sciences
- regression means is real-valued
- inherited from statistics
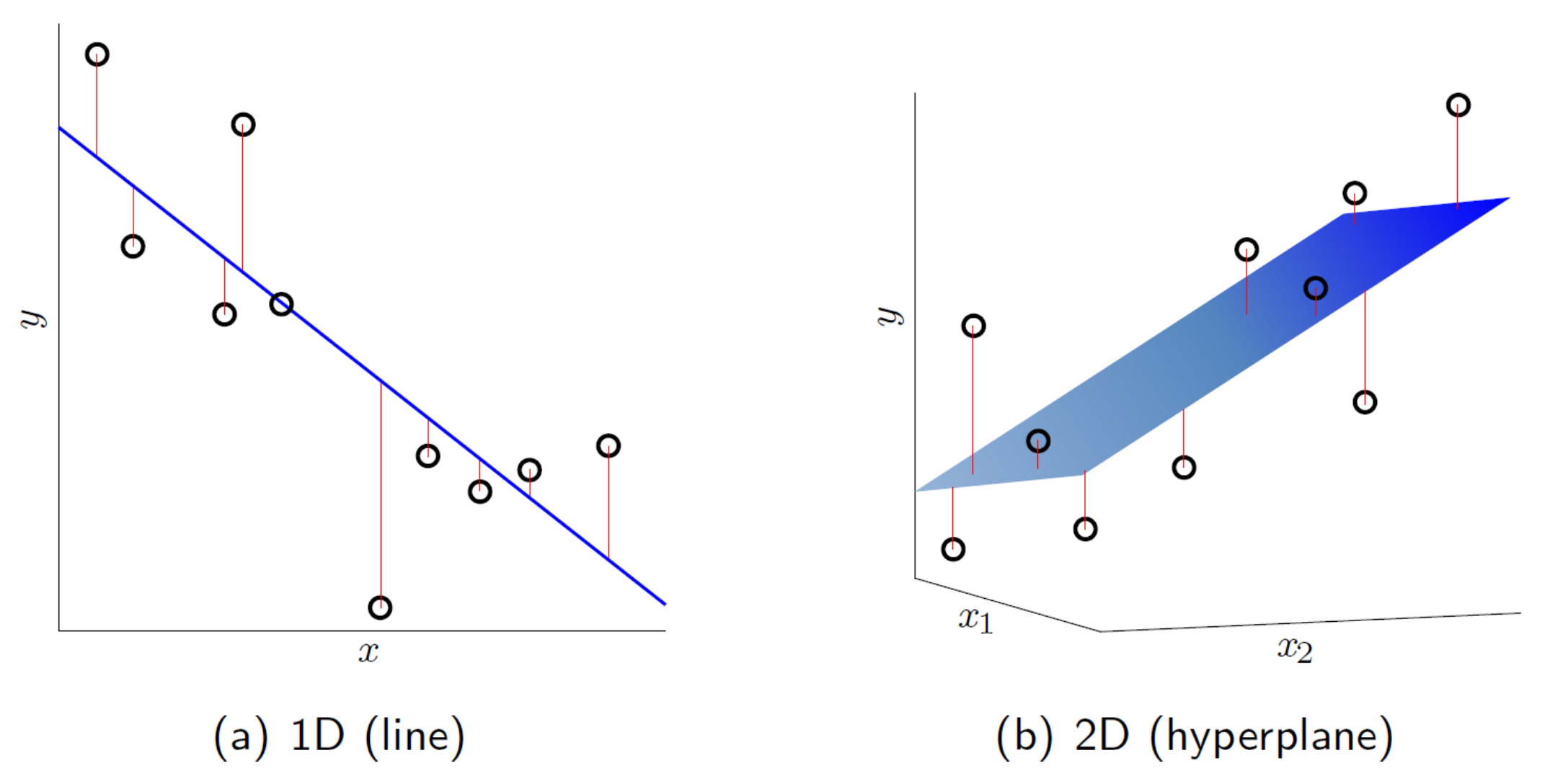
Simple vs. Multiple
- : simple linear regression
- one predictor
- : multiple linear regression
- multiple predictor
Least Squares
- ordinary least squares
- minimizes the sum of squared residuals
- leads to a closed-form expression
- generalized least squares, iteratively reweighted least squares
Maximum Likelihood
- Ridge / Lasso regression
- least absolute deviation regression
Other Techniques
- Bayesian linear regression, principal component regression
1.4 Linear Regression in 1D and 2D
- in OLS, sum of squared error is minimized
- solution hypothesis (in blue) of linear regression algorithm in 1D and 2D
2. Credit Approval Revisited
2.1 Components of the Learning Problem
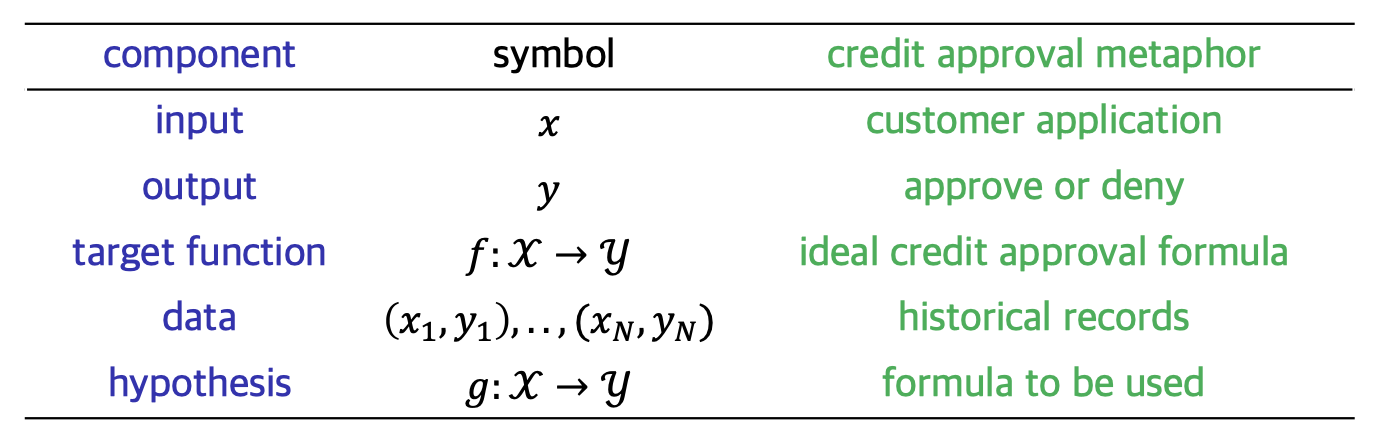
학습 문제의 핵심 요소를 추상화하기 위해 신용 승인 사례를 사용한다. 주요 구성 요소는 다음과 같다.
- : unknown target function
- : input space
- : output space
- : the number of input-output examples
- i.e., training examples
- : data set where
2.2 Regression Perspective
신용 승인 문제를 이진 분류가 아닌 회귀 관점에서 접근하면 다음과 같은 특징을 갖는다.
Quantitative Prediction
- consider credit approval as a regression problem
- instead of making a binary decision
- e.g., set a credit limit for each customer
Real-valued Target
- the bank uses historical records to build a data set
- : customer information
- : credit limit
- set by human experts; real number
- $123,000 for Alicee and $57,000 for Bob
Automation
- the bank wants to automate this task (as it did with credit approval)
- use learning to find a hypothesis
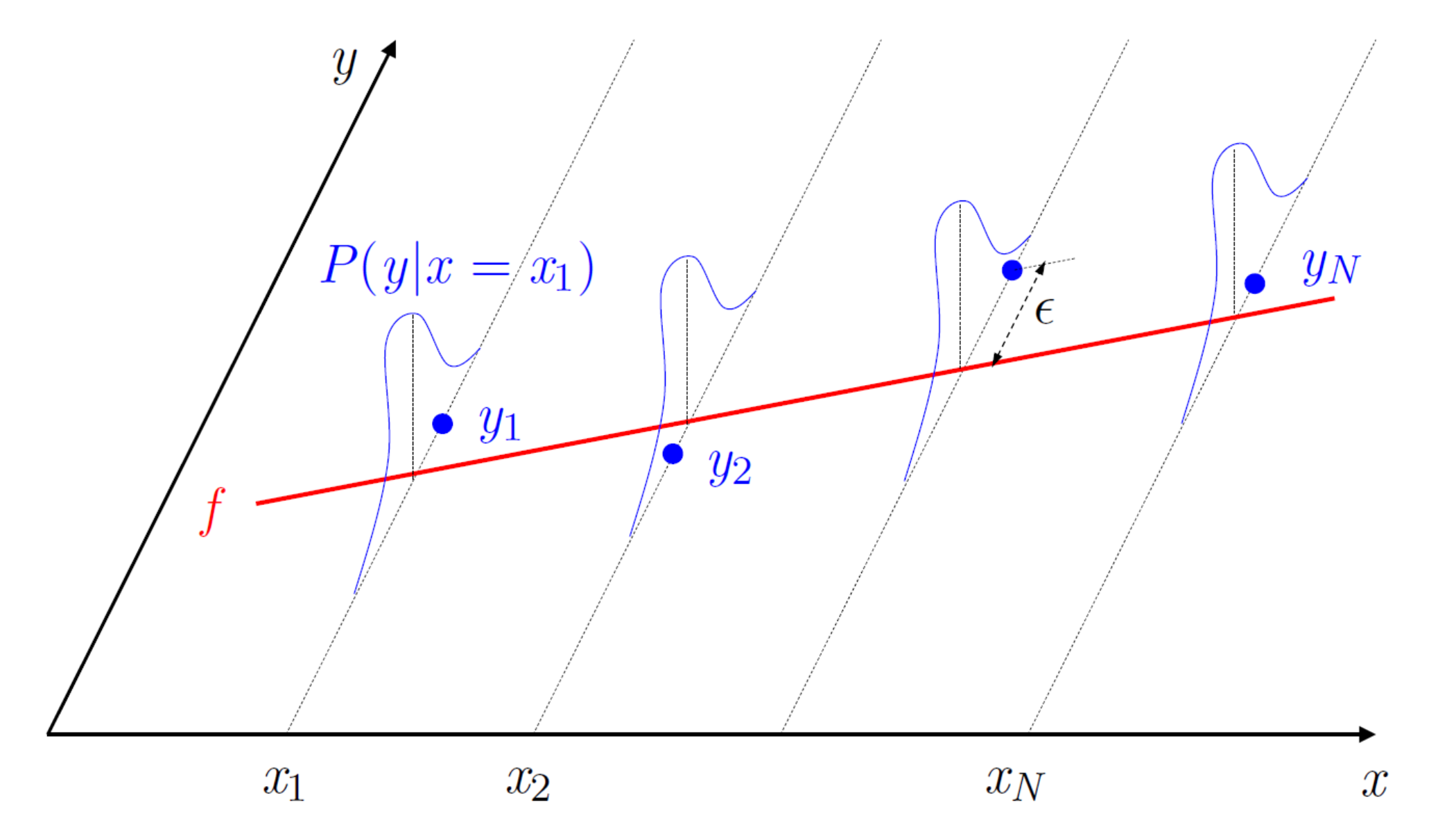
2.3 Target Distribution
현실적인 데이터 생성 과정에서는 완벽한 함수 를 가정하기 어렵기 때문에 확률론적 관점을 도입한다.
Inconsistency of Experts
- each expert may not be perfectly consistent
- out target will not be a deterministic function
Probabilistic Target
- regression label comes from some distribution generating each
- instead of a deterministic function
Learning Goal
- we have a unknown distribution generating each
- find a hypothesis that replicates how human experts determine credit limits
- minimize the error between and wrt that distribution
학습 문제의 본질은 분류에서 회귀로 바뀌어도 변하지 않는다. 데이터를 통해 미지의 타겟을 근사하는 가설을 찾는다는 기계 학습의 기본 틀은 유지된다.
3. Linear Regression Algorithm
3.1 Error Measurement
- based on minimizing squared error between and
- expected value is taken wrt joint probability distribution
Goal
- find a hypothesis that achieves a small
Issue
- cannot be computed
- since is unknown similar to what we did in classification
3.2 In-sample Error
- resort to in-sample error instead:
Sum of Squared Residuals
OLS는 잔차 제곱합을 최소화하는 기법이다. 은 를 모르기 때문에 계산이 불가능하지만 은 우리가 가진 데이터로 계산 가능하므로 의 대리 지표로 사용한다.
Signal Representation
- in linear regression, takes the form of
- a linear combination of the components of :
- : signal
항상 1의 값을 갖는 bias coordinate()가 포함되어 있어 인덱스가 0부터 시작한다.
