Physical vs Virtual Memory
Limitation of physical memory
1. Protection and Isolation
- ruin other process or access kernel memory
- overwrite
2. Pointers in programs
- Compiled programs include fixed pointer addresses
- Program may not be placed at the correct location
- E.g. two copies of the same program
Address Spaces for Multiple Processes
- multi process이면 항상 같은 곳에 load된다는 보장이 없다.
1. Fixed address compilation
Multiple Copies of Each Program
- Complie each program multiple times
- Load the appropriate complied program when the user starts the program
- Bad idea
- Multiple copies of the same program
2. Load-time fixup
Calculate addresses at load-time
- Program contains a list of location that must be modified at startup
- All relatibe to some starting address
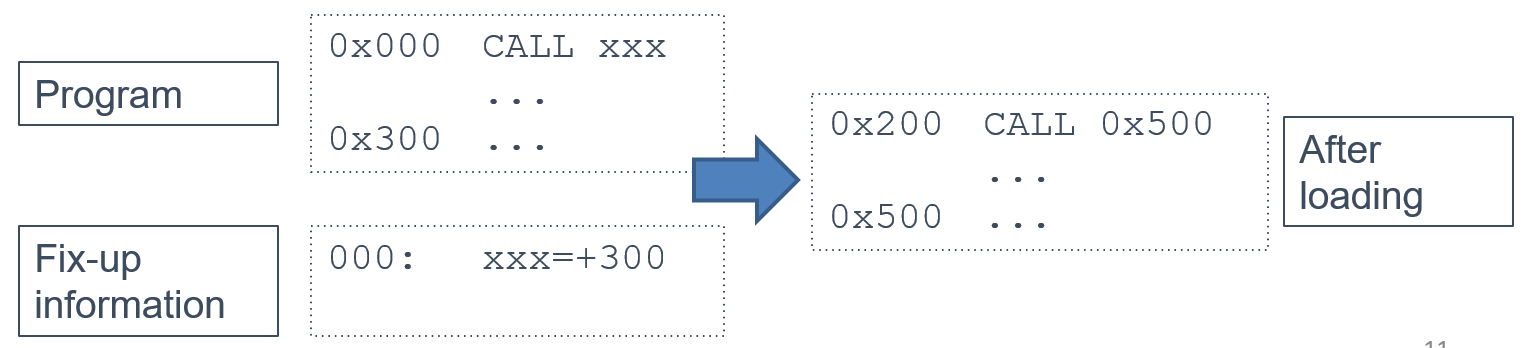
- All relatibe to some starting address
3. Position independent code
Compile programs in a way that is independent of their starting address
- Slightly less efficient than absolute addresses
- Commonly used today for security reasons
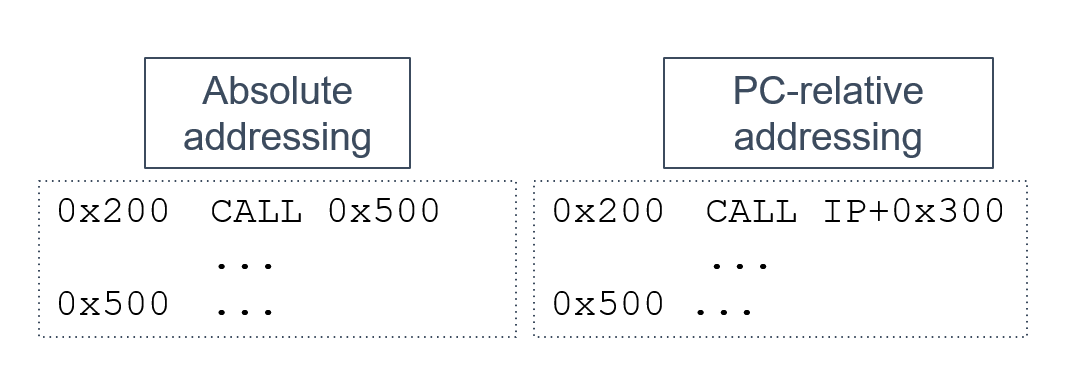
4. Hardware support (virtual memory)
- Hardware address translation
- The OS uses the MMU to map these locations to physical memory
- virtual(logical) memory: process가 보는 address space
MMU and Virtual Memory
- Memory Management Unit translates between virtual addresses and physical addresses
- Process uses virtual address
- MMU translates virtual addresses to physical addresses
- Physical addresses are the true locations of code and data in RAM
- kernel, os만 physical addr에 접근 가능
Virtual memory Implementation
Base and Bounds Registers
Maps a contiguous virtual address region to a contiguous physical address region
BASE: 적재될 위치, BOUND: 크기
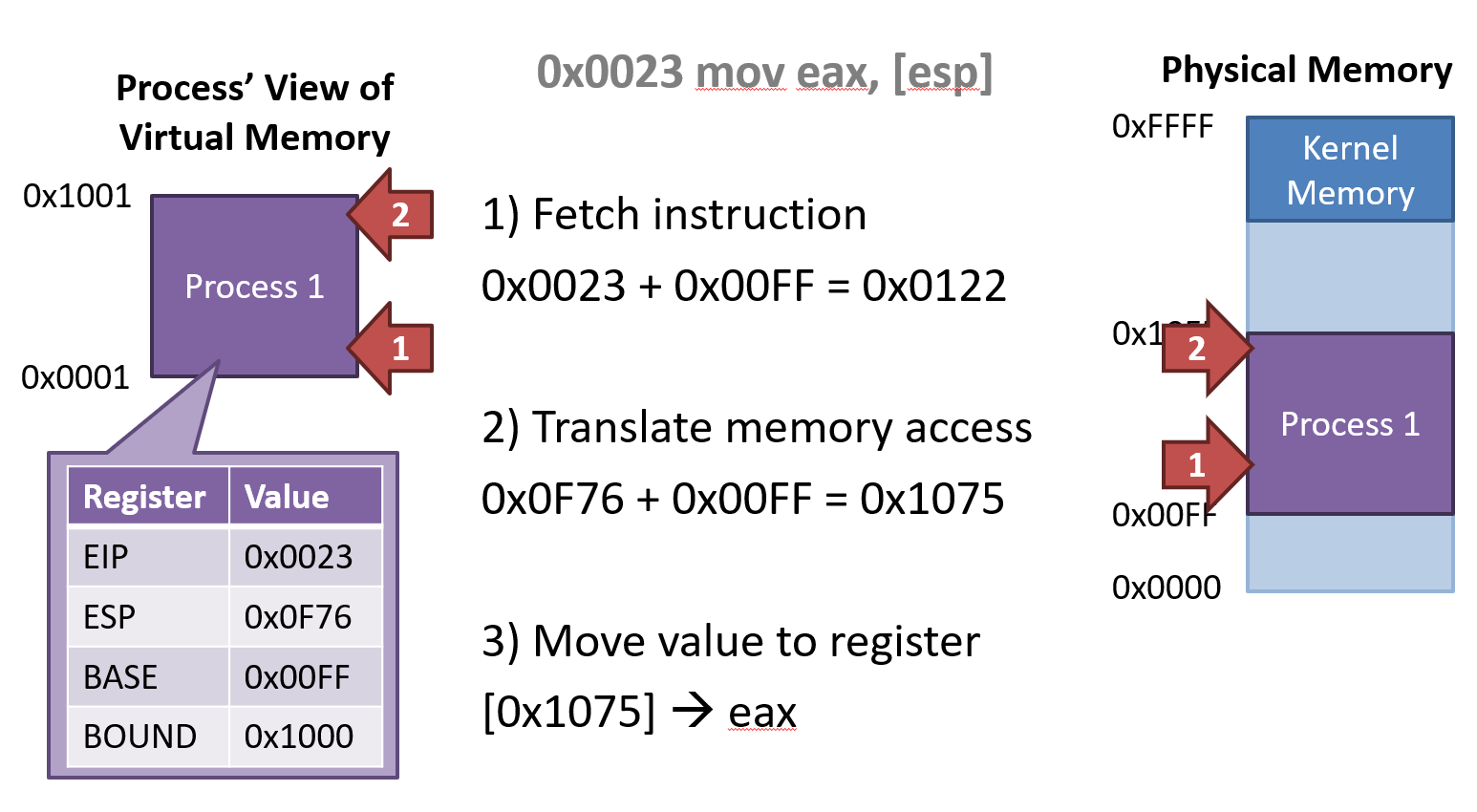
- Add BASE value to virtual address
Protection and Isolation
- If translated address is bigger than BASE + BOUND, then Raise Protection Exception
Implementation Details
- BASE and BOUND are protected registers
- Only code in Ring 0 can modify BASE and BOUND
- Prevents processes from modifying their BASE and BOUND
- Each CPU has one BASE and BOUND
- BASE and BOUND must be saved and restored during context switching
Advantages
- Simple implementation
- Processes can be loaded at arbitrary fixed addresses
- Protection and Isolation
- Flexible placement data in memory
Limitations
- Processes can overwrite their own code
- No sharing memory
- Process memory cannot grow dynamically
- May lead to internal freamentation
Internal Fragmentation
Wasted space => 할당된 영역 내 사용하지 않는 게 존재
-
Empty space leads to internal fragmentation
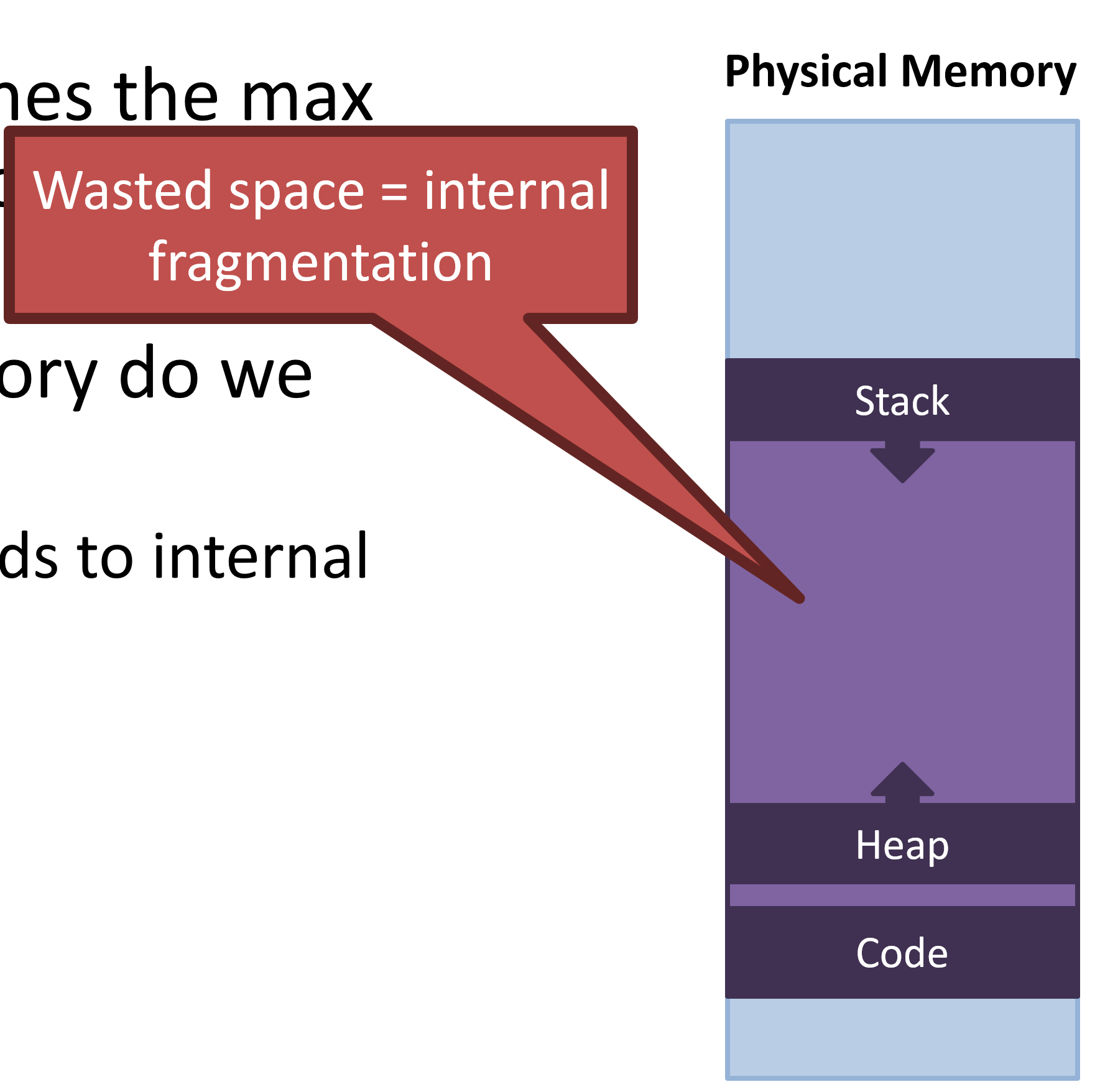
-
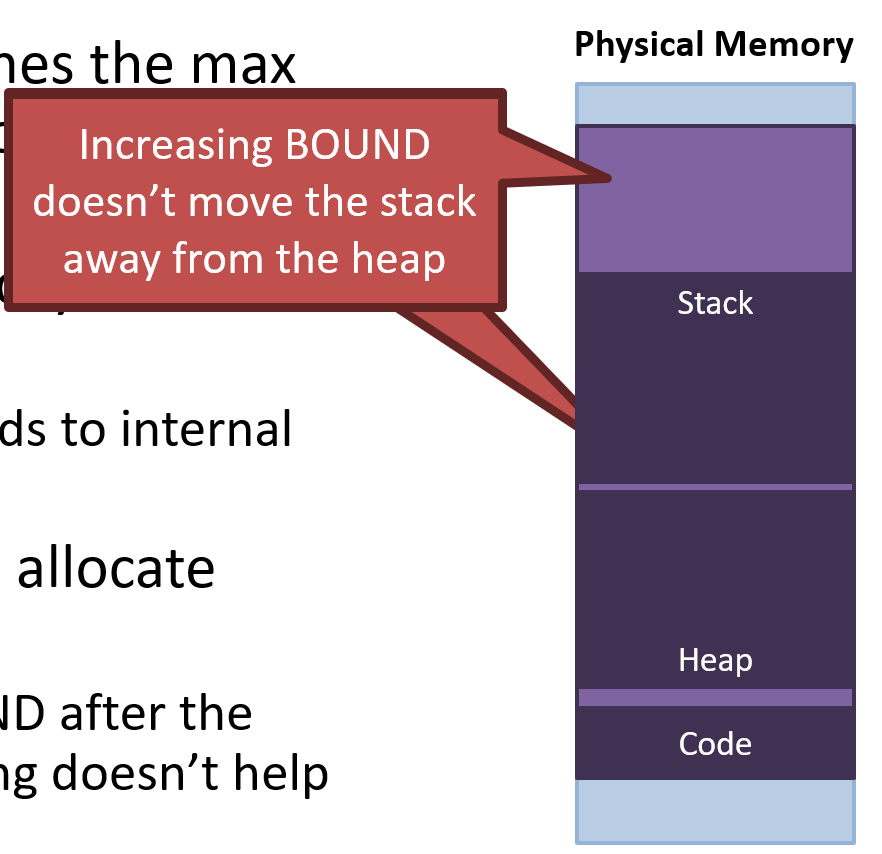
What if we don’t allocate enough?
- Increasing BOUND after the process is running doesn’t help
- It doesn't move the stack from the heap
Segmentation
Having a single BASE and a single BOUND means code, stack, and heap are all in one memory region -> 하나의 덩어리
- Leads to internal fragmentation
- Prevents dynamically growing the stack and heap
Generalize base and bounds approach
- Give each process several pairs of base/bounds
- Each pair = Segment
- 3 segments is common: code, heap(+data), and stack
Segments and Offsets
- Split virtual addresses into a segment index and an offset
- E.g. 14-bit addresses
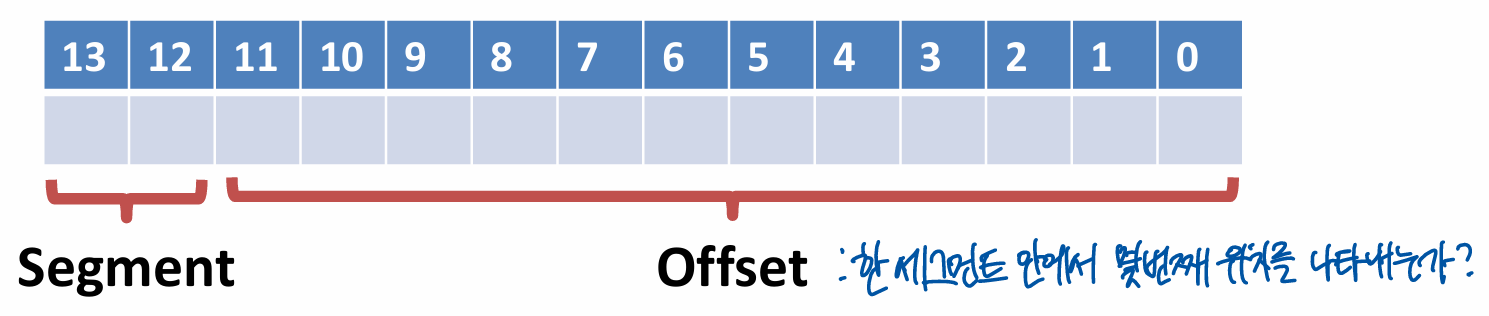
- Segment size is = 4KB
- 4 possible segments per process
- 00, 01, 10 ,11
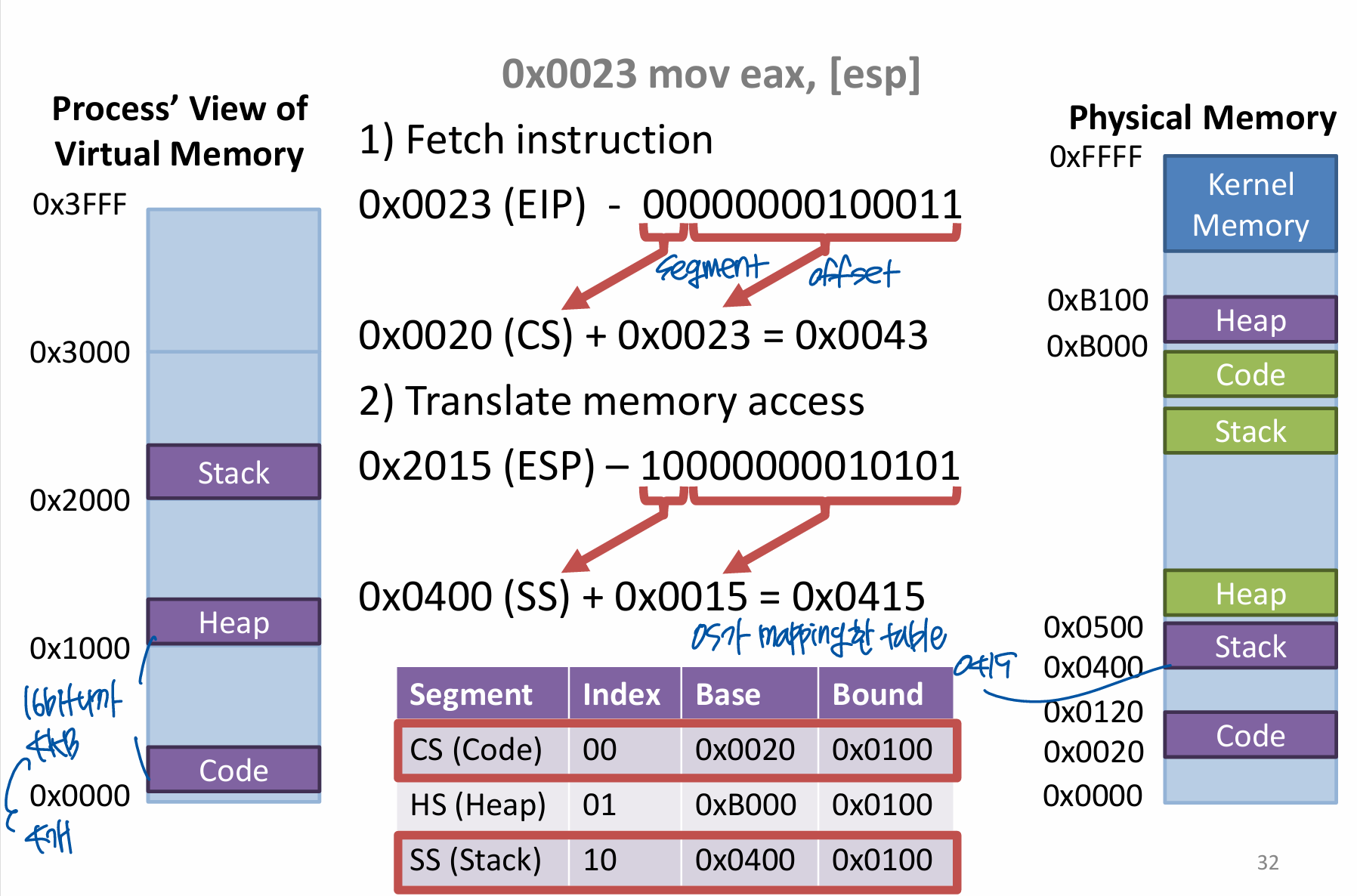
Separation of Responsibility
- OS manages segments and indexes
- Creates segments for new processes
- Builds a table mapping segments indexes to base address and bounds
- Swaps out the tables and segment registers during context switches
- Free segments when process is terminated
- CPU translates virtual address to physical address
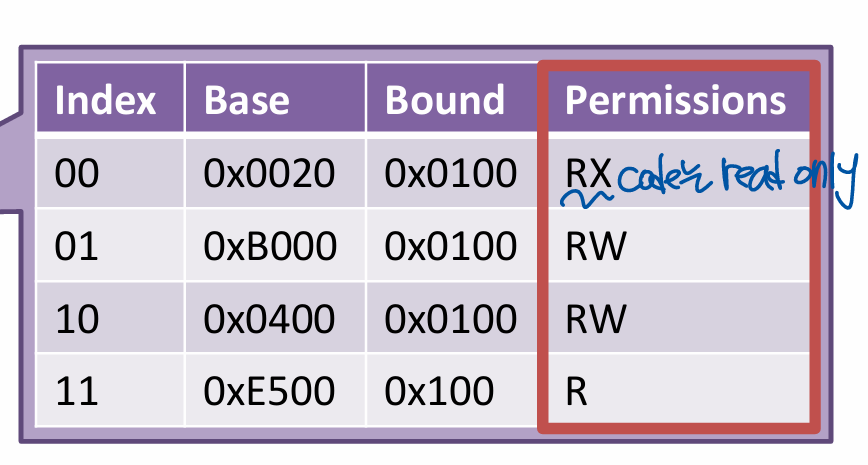
Segment Permissions
- Read, write, and executable (r, w, x)
- more security
x86 Segments
- segment: offset notation
- In 16-bit(real) x86 assembly, segment:offset notation is common
- mov[ds:eax], 42
- move 42 to the data segment, offset by the value in eax
- 현대는 segmentation을 지원하지만 paging 사용 -> (backward computing) 전체를 하나의 segment로 취급
Segmentation Fault
- Try to read/write memory outside a segment
- return ad를 덮어쓸 수 있기 때문에 return시(pop) 죽음
- buffer overflow attack
char buf[5];
strcpy(buf, "Hello World");
return 0; // seg fault when returnShared Memory
- If the code and shared data are the same, can share by setting base and bound same
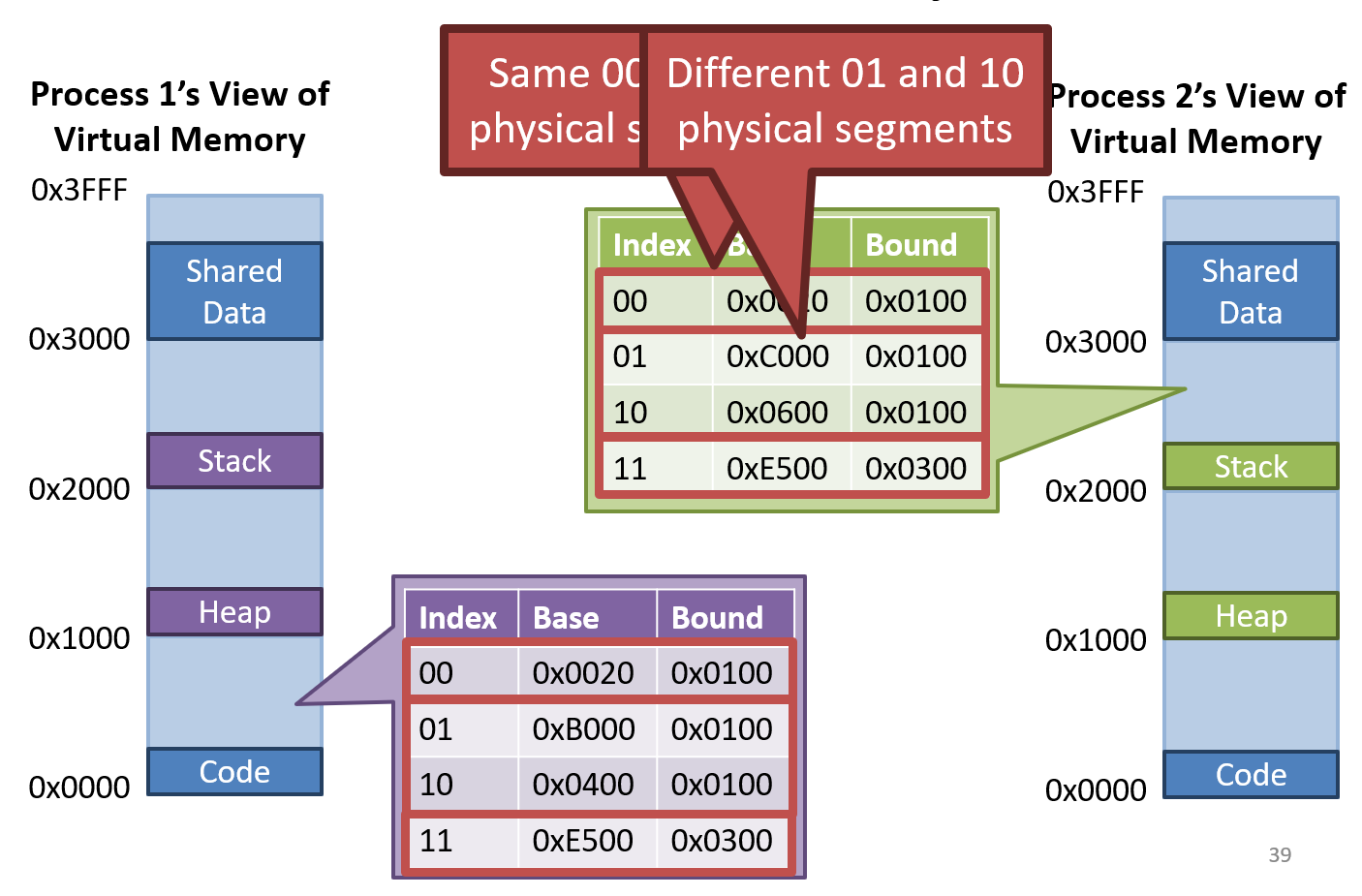
Advantages of Segmentation
- All the advantages of base and bound
- Better support for sparse address spaces
- Code, heap, and stack are in separate segments
- Segment sizes are variable => prevents internal fragmentation
- Supports shared memory
- Per segment permissions
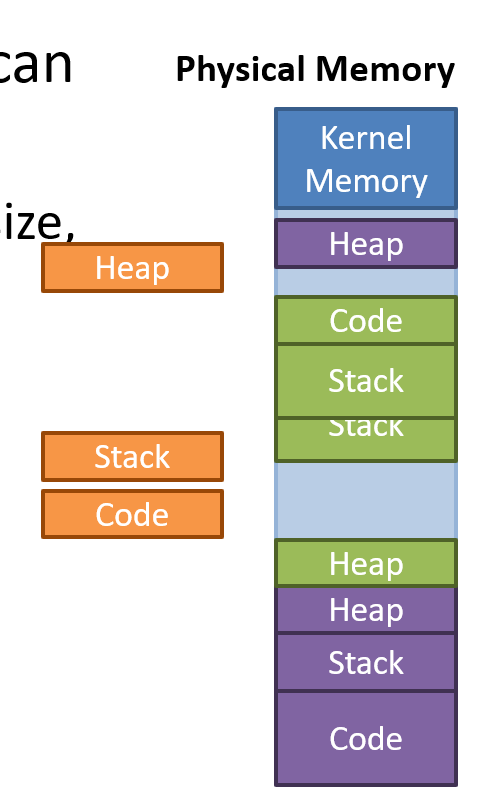
External Fragmentation
Problem: Variable size segments can lead to external fragmentation
가용 메모리는 남아있으나, 잘게 쪼개져 들어가지 못함
- Even there is enough free memory to start a new process, memory is fragmented
- Compaction can fix the problem -> expensive
Paging
segments are course-grained -> Segments lead to external fragmentation
Generalize segmented memory model
- Physical memory is divided up into physical pages(frames) of fixed sizes
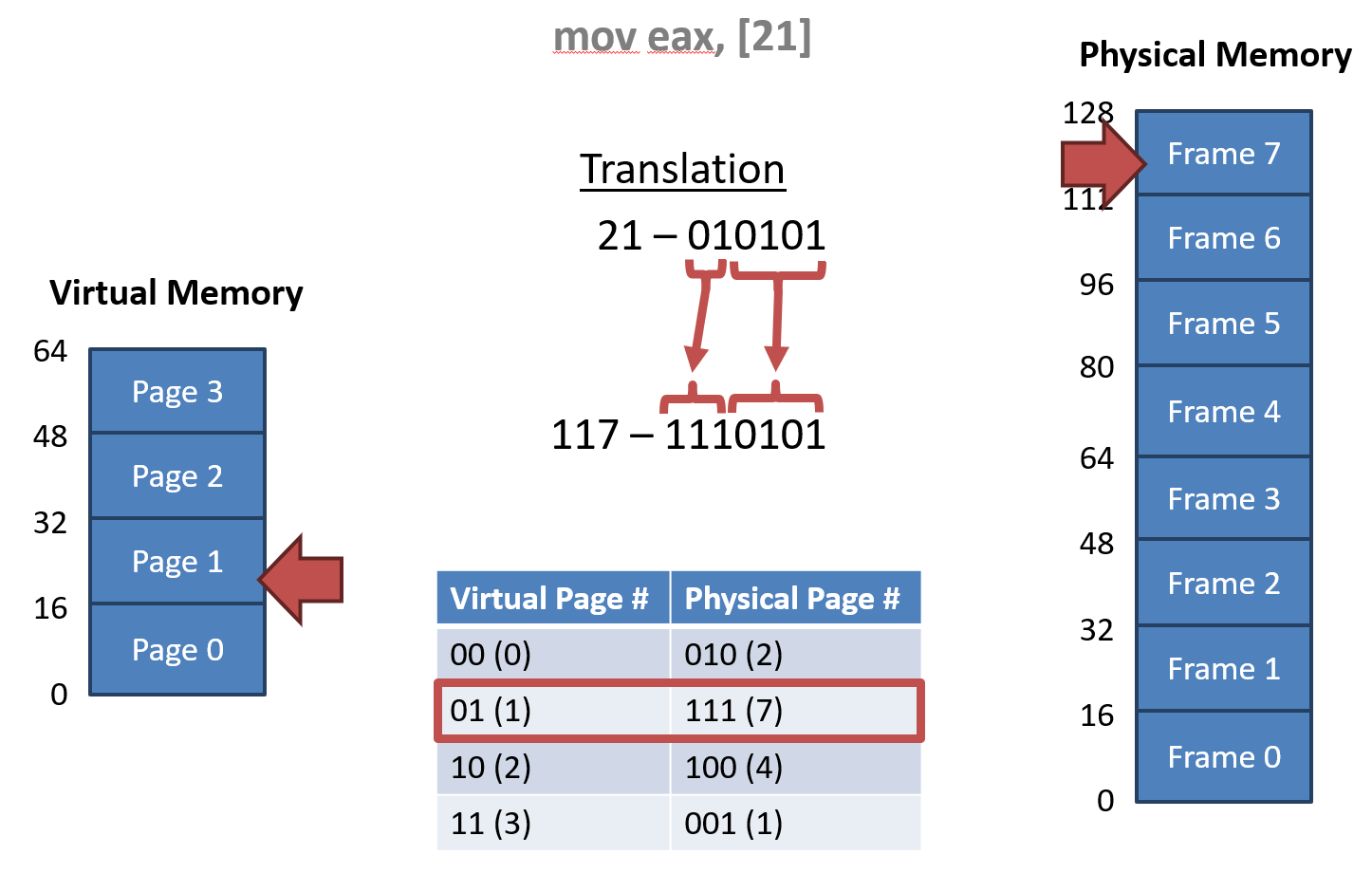
E.g. 1
- 64-byte virtual address space
- 16 byte per page
- 21번지에 있는 것을 읽어서 eax에 넣는다.
- 6 bit 중 2bit가 page
- virtual page number만 치환하고 다시 10진수 변환
E.g. 2
- 32-bit address space & page size = 4KB
- How many pages?
- How many bits to select the physical page?
- 20 bits
- Page table entry is 4 bytes large
- Each process needs 4MB of page table
- 100 processes = 400MB of page tables
32bit에서는 PTE 일반적으로 4bytes, page size 4KB
1M * 4bytes
Problems
Page table Implementation
- OS creates the page table for each process
- Page tables are stored in kernel memory
- OS stores a pointer to the page table in register in the CPU (CR3 register in x86)
- On context switch, OS swaps the pointer
- CPU translates virtual address into physical address
x86 Page Table Entry

- PTE are 4 bytes
- W - writable bit - writable or read-only?
- U/S - user/supervisor bit - can user processes access?
- Bits related to swapping
- P - present bit - is in physical memory?
- A - accessed bit - has read recently?
- D - dirty bit - has written recently?
Copy-on-Write
자식 프로세스를 위한 새로운 페이지 테이블을 생성하여 부모의 모든 페이지를 매핑 -> read-only로 공유
fork()is too slow- Rather than copy all of parents, create a new page table for the child that maps to all of the parents
- Mark all pages as read-only
- If parent or child writes a page, exception will be triggered
- OS catches the exception, makes a copy of the target page, then restarts the write operation
- All unmodified data is shared
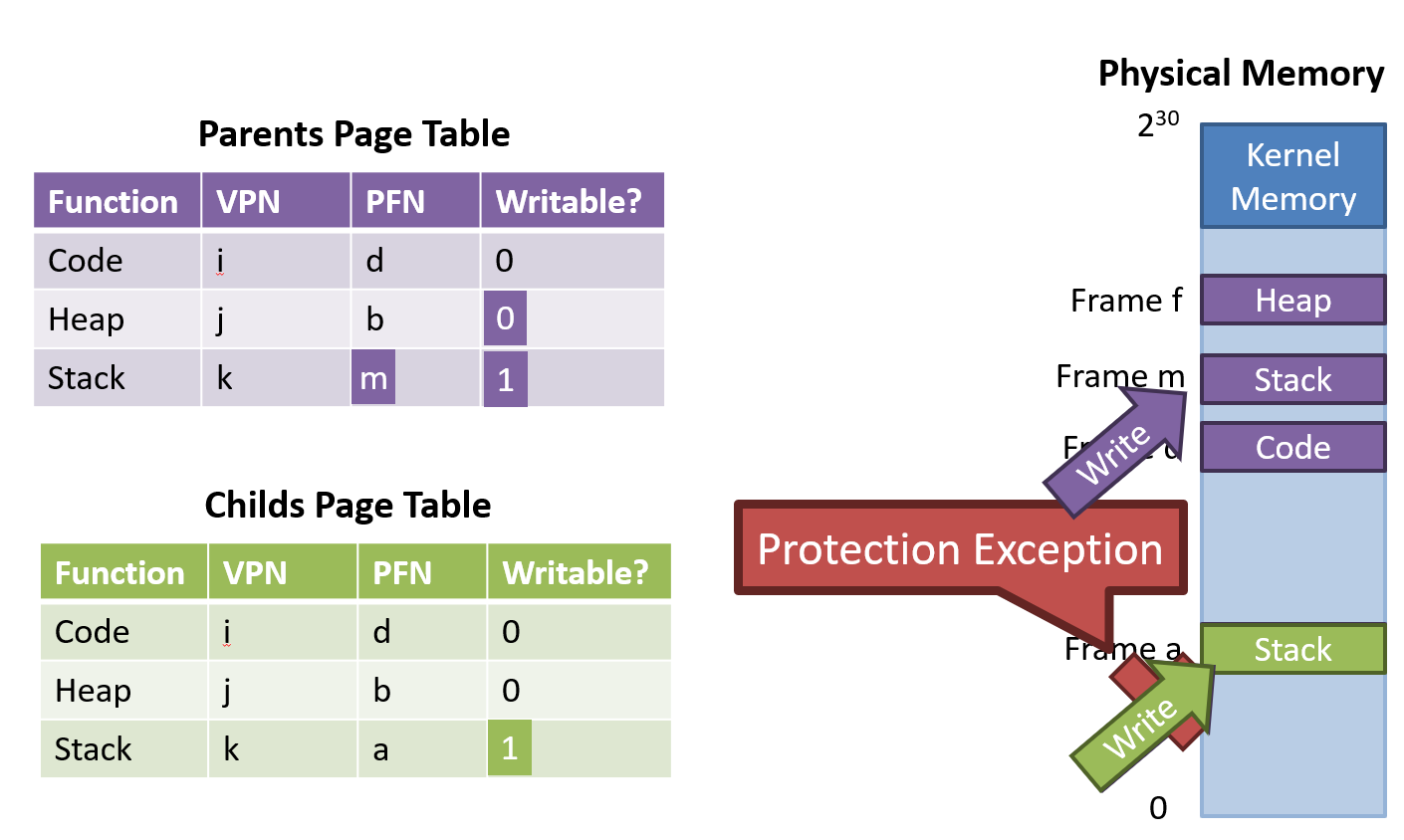
- Mark all pages read-only
- Child try to write on stack -> Exception occurs and OS makes a copy of the target page,
- Parent page table is modified into other region that copied original stack
Advantages of Page tables
- All the advantages of segmentation
- Even better support for sparse address spaces
- Each page is relatively small
- Fine-grained page allocations to each process
- Limits internal fragmentation
- All pages are the same size
- Each to keep track of free memory
- Prevents external fragmentation
- Per page permissions
- Prevents overwriting code, or executing data
Problems
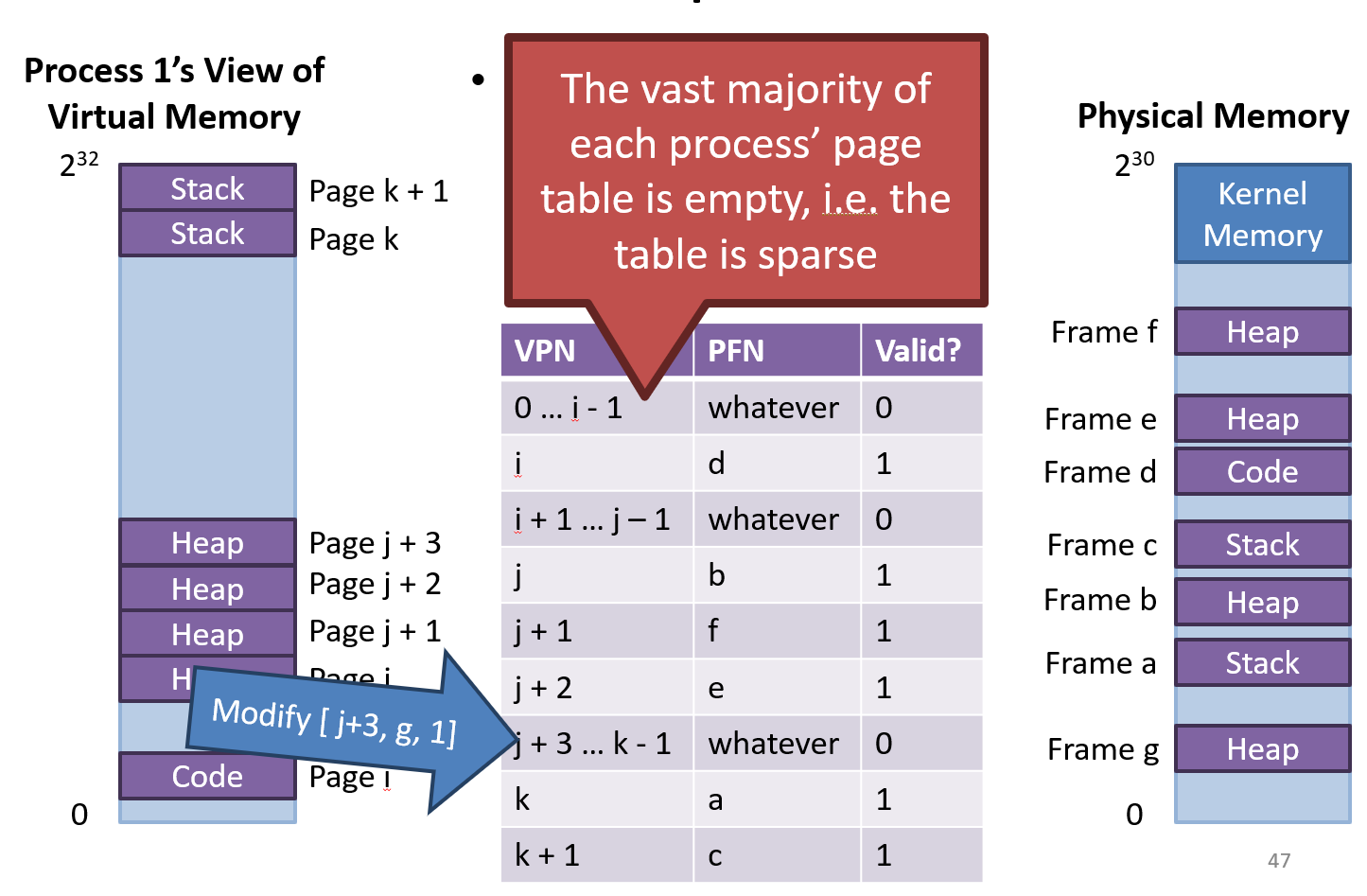
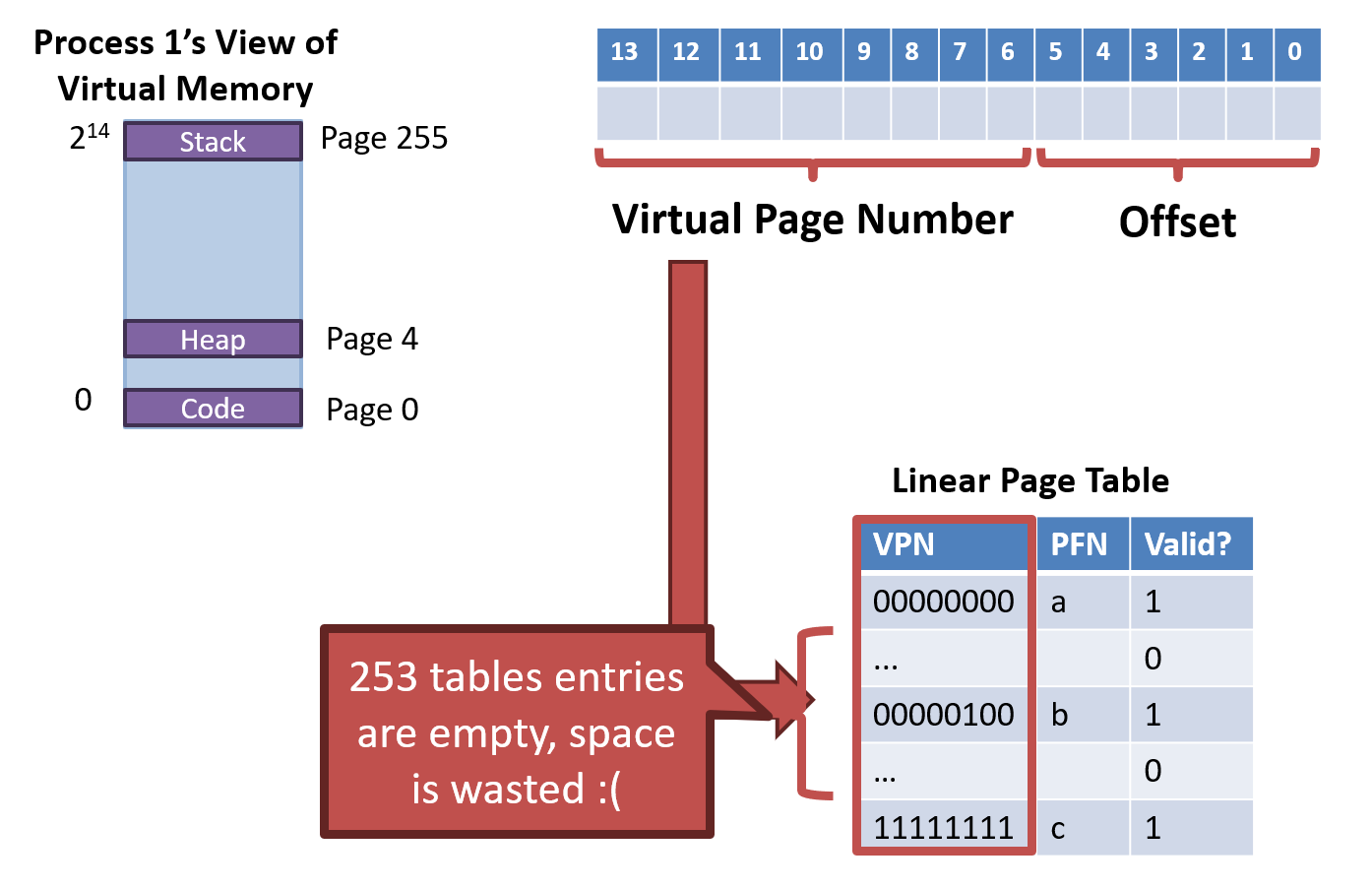
- Page tables are huge
- Vast majority of the PTE are empty or invalid
- Page tables are slow

- How many memory accesses occur during each iteration of the loop?
- 4 instructions are read from memory
- 1 memory access writes in memory
- 5 page table lookup
- Each memory access must be translated
- And the page tables are in memory
TLB (Translation Lookaside Buffer)
Problem : Page Table is slow
- Each virtual memory access must be translated
- Each translation requires a table lookup in memory
- Memory overhead is doubled
Caching
- Cache page table entries in the CPU's MMU
- TLB stores recently used PTEs
- CPU cache is very fast
- Translations that hit the TLB don't need to be looked up in memory
CPU > MMU > TLB
TLB Entry

- Do not cache the entire page -> need the index (VPN)
- VPN & PFN : virtual and physical pages
- pair로 가짐, TLB는 전체를 가지는 게 아니므로 VPN까지 필요
- G : global page?
- ASID : address space ID
- D : dirty bit : written recently?
- V : valid bit : valid?
- C : cache coherency
TLB control flow
- TLB Miss
- Load the page table entry from the memory
- Add it to the TLB
- Retry instruction
바로 access하지 않고, TLB에 넣고 memory access
Comparison TLB and w/o TLB
- Suppose we have a 10KB array of integers
- 4KB pages
- Without TLB
- How many memory accesses are required?
- 10KB/4 = 2560 integers
배열 내 정수 계산(32bit = 4 byte로 나눔) - Each requires one page table lookup, one memory read 5120 reads
- 10KB/4 = 2560 integers
- How many memory accesses are required?
페이지 테이블을 한 번 조회, 실제 메모리에서 데이터를 한 번 읽음 = 2
- With TLB
- TLB starts off cold (empty)
- 2560 to read the integers
- 3 page table lookups (3 pages will be cached)
- 10KB/4KB -> 2.5이므로 3pages 필요
- 2563 reads
- 2557번만 성공
Locality
1. Spatial locality
- If you access address x, you will access x+1 soon
- Most of the time, x and x+1 are in the same page
2. Temporal locality
- Most of the time, x and x+1 are in the same page
- The page containing x will still be in the TLB
근처를 접근할 가능성, 같은 주소에 가까운 시간 내에 접근할 가능성
Problems
- TLB entries may not be valid after a context switch
- VPNs are the same, but PFN mappings have changed
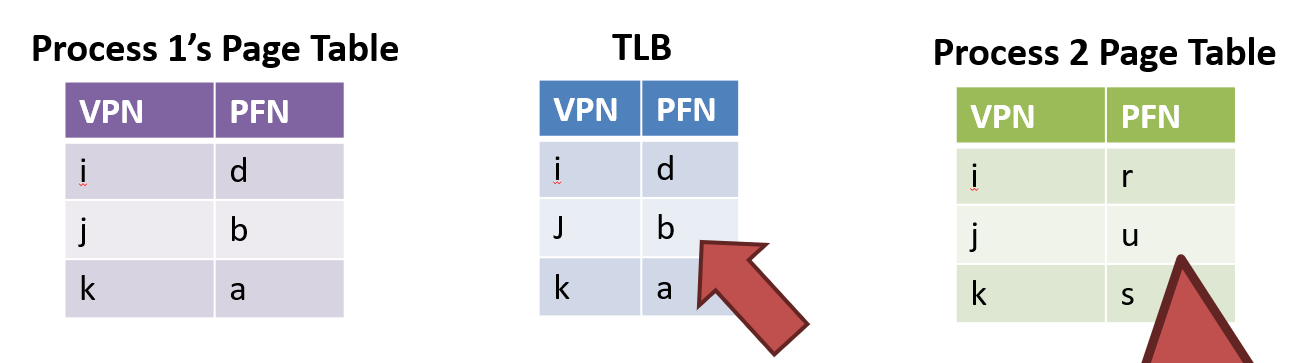
Solutions
- Clear the TLB after each context switch = TLB flush
- Each process will start with a cold cache
- Associate an ASID with each process
- ASID is just like a PID in the kernel
- CPU can compare the ASID of the active process to the ASID stored in each TLB entry
- If they don't match, TLB entry is invalid
ASID vs. PID
ASID는 process의 shared memory
Replacement Policies
- FIFO
- Random
- LRU: Least Recently Used
Hardware vs. Software Management
Hardware TLB
- Pros
- Easier to program = Less work for kernel developers, CPU does a lot of work
- CPU manages all TLB entries -> less overhead, TLB miss 처리 속도 빠름
- Easier to program = Less work for kernel developers, CPU does a lot of work
- Cons
- Complex management is difficult
- Limited ability to modify the TLB replacement policies
-> 유연성 부족
Easier to program
Software TLB
- Pros
- Greater flexibility = No predefined data structure for the page table
- Free to implement TLB replacement policies
- Cons
- More work for kernel developers
- CPU don't try to read the page table
- CPU don't Add/remove entries from the TLB
- More work for kernel developers
Greater flexibility
- TLB Miss
- CPU don't manage, occur Exception
- Then, OS handles the exception
- Insert the PTE into the TLB
- Tell the CPU to retry the previous instruction
Advanced Page Tables
Problem: Page Table Size
- 32-bit system with 4KB pages
- Each page table is 4MB
- Most entries are invalid => Wasted space
Solution 1: Bigger pages
- Increase the size of pages
- 32-bit system with 4MB pages
- 1024 * 4 bytes per page = 4KB page tables
- Problems
- Increased internal fragmentation
- Programs will have much less than 4MB
Solution 2: Alternate Data structures
- Hash table or Tree
- Why non-feasible?
- Can be done of the TLB is software managed
- If the TLB is hardware managed, OS must use the page table format specified by the CPU
hardware dependent하므로, 실제 구현 어려움
Solution 3: Inverted Page Tables
물리 프레임 → (어느 프로세스의 어느 가상 페이지가 이 프레임에 들어와 있는가?
Flip the table
- Map physical pages to virtual pages
- Pros
- Only one physical memory -> only need one inverted page table
- Cons
- Lookups are more expensive
- Table must be scanned to locate a given VPN
- What about shared memory?
- Implement VPN with a list -> More time with searching
- Lookups are more expensive
- TLB에서 찾고 없으면, table 순서대로 찾아야 함
- 여러 개가 속할 수 있어야 함 - 공유 메모리 등에서 여러 page mapping 가능
Solution 4: Multi-Level Page Tables
Split the linear page table into a tree of sub-tables
- Branches of the tree that are empty can be pruned
- Space / Time tradeoff
- Pruning reduces the size of the table (Save space)
- Tree must be traversed to translate virtual address (Increased access time)
E.g.
- 16KB address space
- 64 byte pages, 14-bit virtual address, 8-bit for the VPN, 6-bit for the offset
- How many entries?
- 256 entries, each is 4 bytes large
- 1KB linear page tables
- 1KB linear page table can be divided into 16 64-byte tables
- Each sub table holds 16 page table entries
- Each sub table holds 16 page table entries
32-bit x86 Two Level Page Table
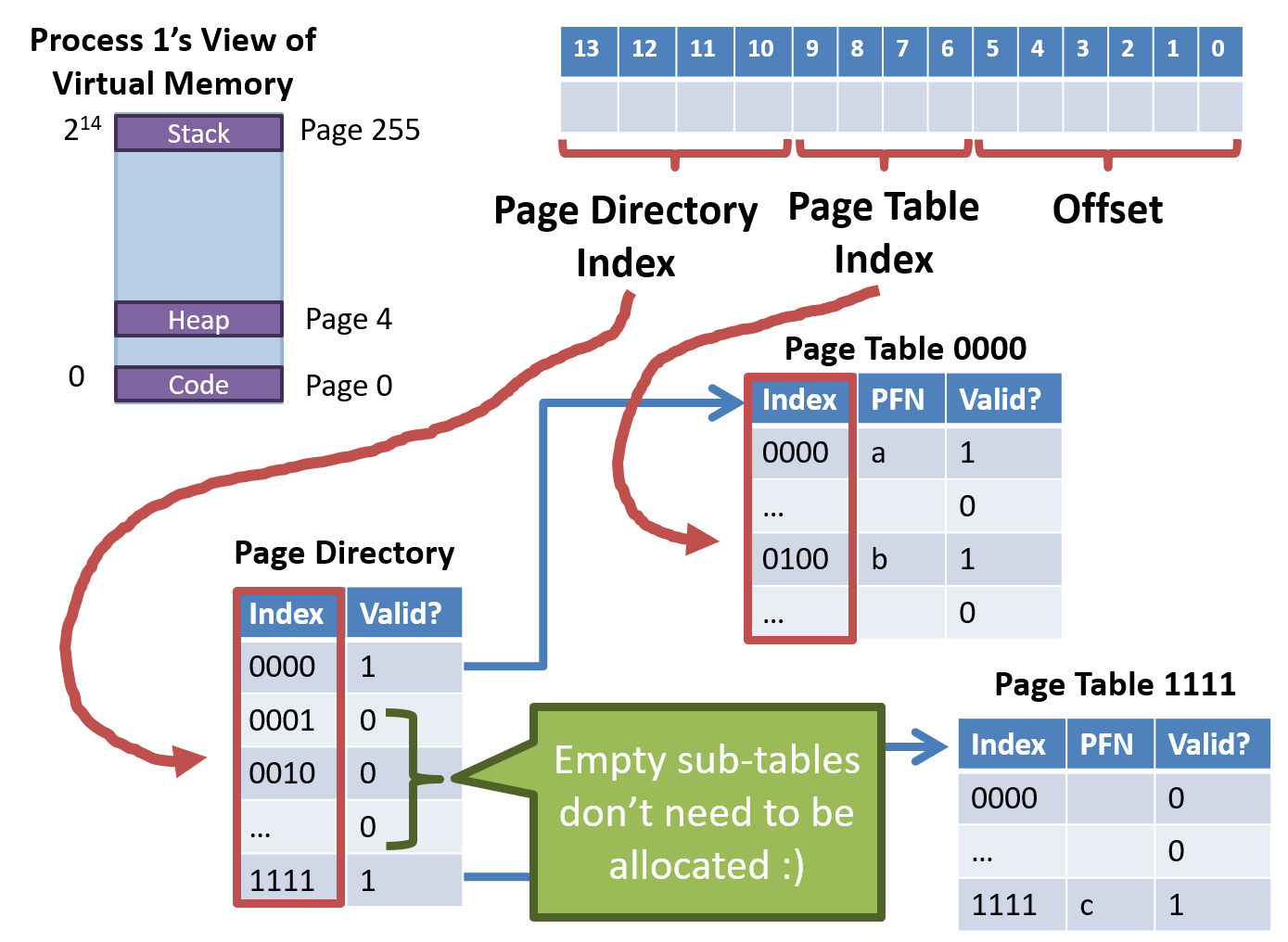
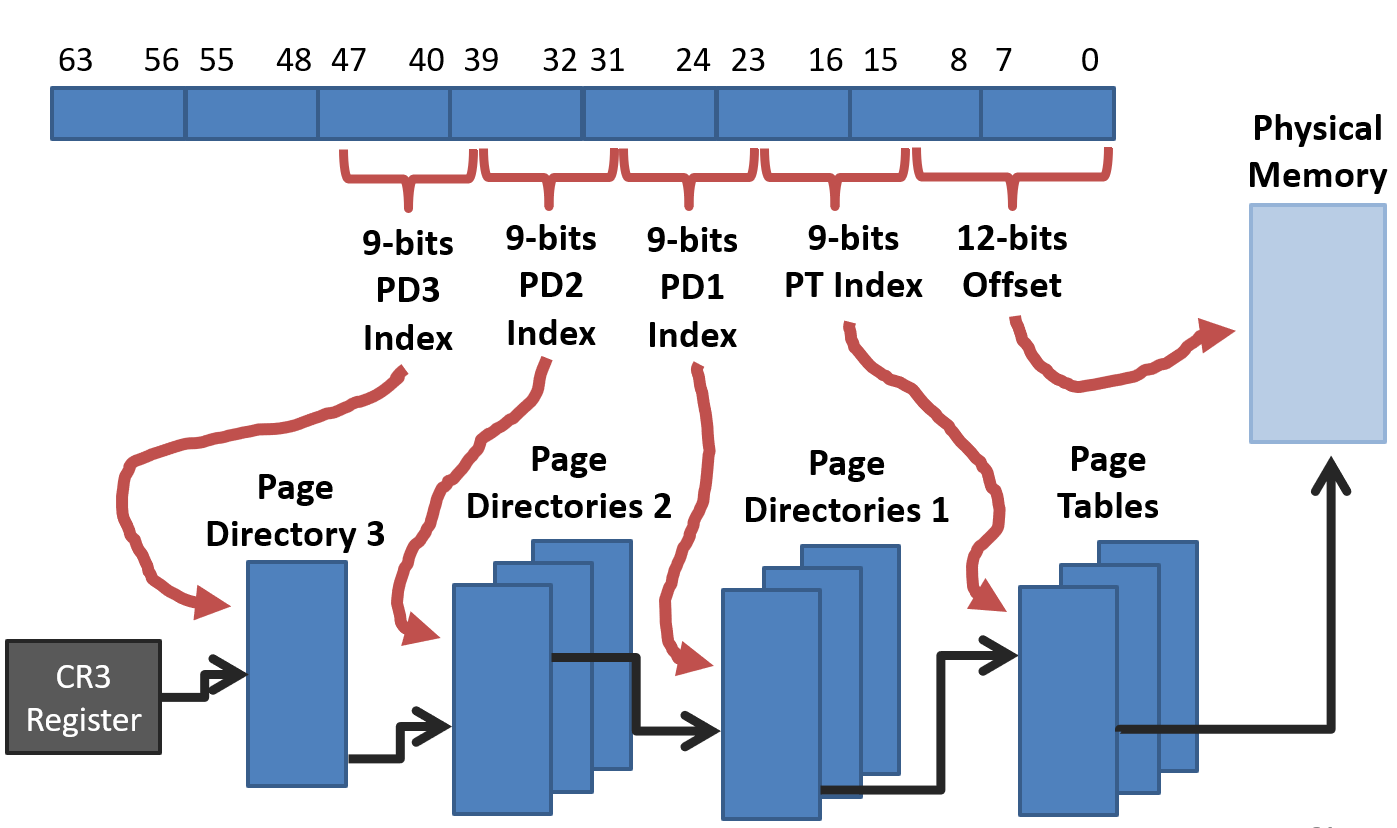
64-bit x86 Four Level Page Table
Hybrid approach
IA-32 architecture
- Both segmentation and segmentation with paging
- Each segment can be 4GB (전체를 segment로 잡음)
- Up to 16K segments per process
- Divided into two partitions
- First partition of up to 8K segments are LDT (Local Descriptor Table)
- Second partition of up to 8K segments shared among all processes GDT (Global Descriptor Table)
- CPU generates logical address (selector, offset)
- Segmentation unit generates linear address (virtual address) using selector
- MMU translates linear address into physical address
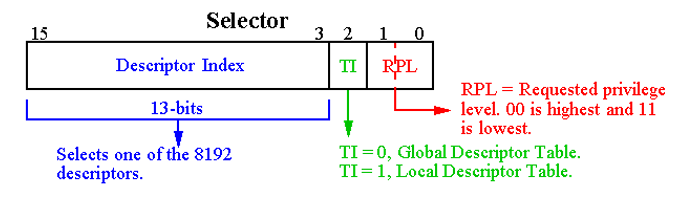
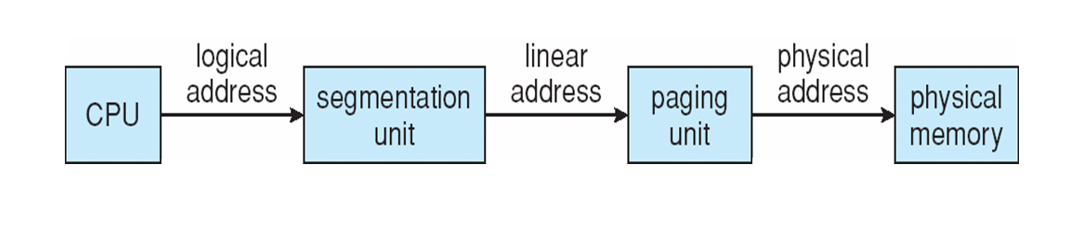
Descriptor Table
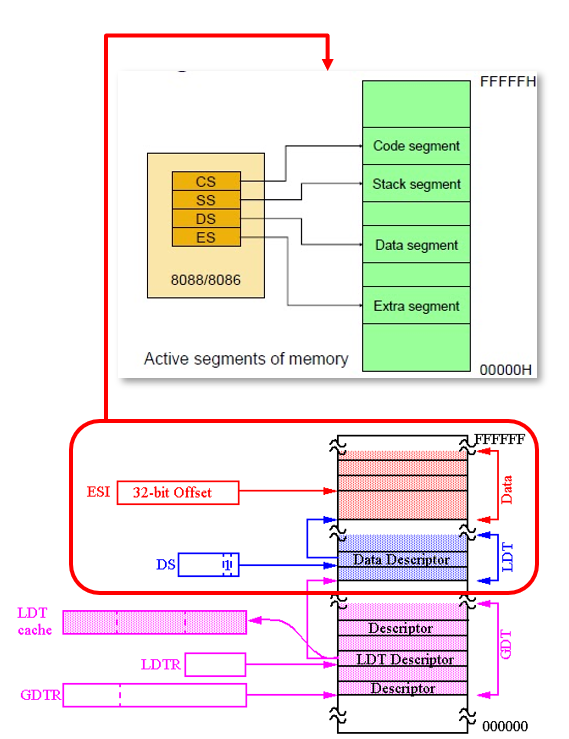
- GDTR points GDT
- Put LDT Descriptor value into LDTR, then LDTR points LDT
- Get the starting address of segment using selector
- Add offset and get linear address
Intel IA-32 Paging Architecture
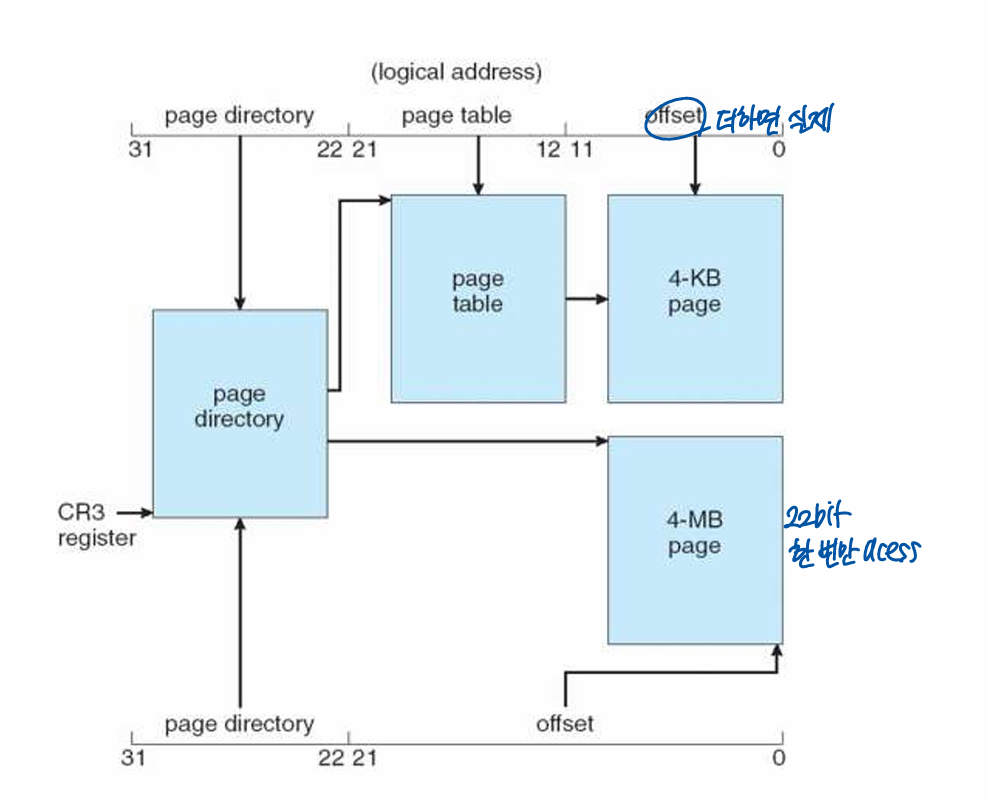
Don’t Forget the TLB
- Multi-level pages look complicated
- And they are, but only when you have to traverse them
- The TLB still stores VPN -> PFN mappings
- TLB hits avoid reading/traversing the tables at all

갓생호소인