강화학습이란?
- 주어진 환경에서 최적의 행동을 자동으로 찾는 것
- 환경과 상호작용하여 시도와 에러로부터 학습하는 것
- 앞으로의 기대 보상을 최대화하는 전략을 학습하는 것
- 불확실한 환경으로부터 최적의 policy를 찾기 위한 학습 방법
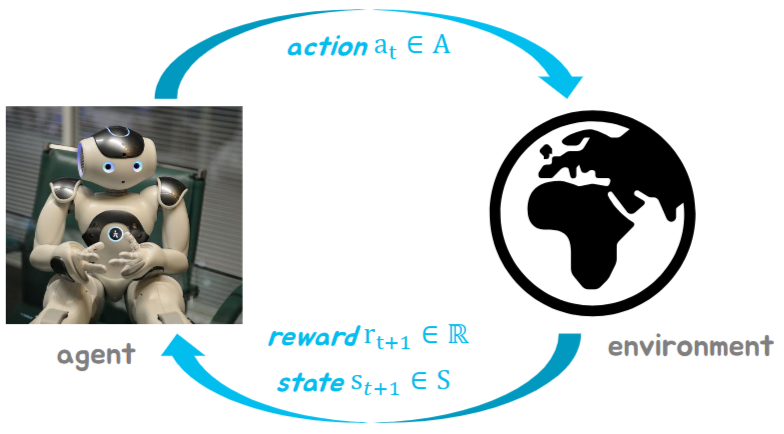
Formalizing Reinforcement Learning
- 에이전트는 현재의 상태 를 관측함
- 에이전트는 그로부터 를 시행함
- 환경은 행동으로부터 보상을 반환함
Rewards
- 보상 는 스칼라 피드백이다.
- 이는 에이전트가 스텝 에 얼마나 잘 하고 있는지를 나타낸다.
- 에이전트의 목표는 누적 보상을 최대화하는 것이다.
Sequential Decision Making
- 목표: 전체 미래 보상을 최대화하기 위한 행동을 선택하는 것
- 행동은 매우 장기적인 결과를 초래할 수 있음
- 보상또한 지연될 수 있음
- 더 많은 장기적인 보상을 위해 당장의 보상을 희생하는 편이 좋을 수도 있음
예를 들어:
- 적의 움직임을 방해함 (나중에 승리할 기회를 만들어줄 수 있음)
- 헬리콥터의 연료를 다시 채움 (몇 시간 뒤 충돌을 막을 수 있음)
- 금융 투자 (몇 주 또는 몇달이 걸릴 수도 있음)
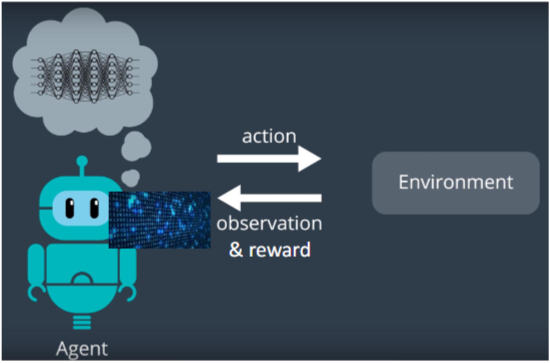
Agent and Environment
에이전트는 각 스텝 에서:
- 관측 를 받음
- 스칼라 보상 를 받음
- 행동 를 수행함
Environment state
- 환경상태 는 환경의 private 표현임
- 는 에이전트에게 보통 보이지는 않음
- 가 보이더라도 무관한 정보를 갖고있을 수 있음
Agent State
- 에이전트 상태 는 에이전트의 내부 표현임
- 에이전트가 다음 행동을 고르기 위한 정보를 제공함
- 강화학습 알고리즘에서 사용되는 정보임.
Markov Property
- Markov state는 history로부터 모든 유용한 정보를 갖고 있음
- 상태는 Markov이다
- 미래는 현재가 주어졌다면 과거로부터 독립적임
- 상태를 알고 있다면 과거의 상태는 버려도 됨
- 상태가 미래를 위한 충분한 통계량임
Fully Observable Environments
- Full observability: Agent가 직접 환경의 상태를 관측할 수 있음.
- Environment state = Agent state = Markov State
- Markov Decision Process(MDP)임. (다음 장에서 설명)
Partially Observable Environments
- Partial observability: 에이전트는 간접적으로 환경을 관측함
- 카메라가 달린 로봇이 찍은 비전은 로봇의 절대적인 위치를 말해주지는 못함
- 트레이딩 에이전트는 현재 가격 밖에 관측할 수 없음
- 포커 플레이어 에이전트는 public cards만 볼 수 있음
- 이제 에이전트 상태는 환경상태와 다름
- 이를 Partially Observable Markov Decision Process (POMDP)라고 부름
- 에이전트는 본인만의 상태 표현을 만들어야 함
State History
- History는 관측, 행동, 보상들의 나열임
- 시간 까지 모든 관측 가능한 변수들임
- 시간 까지 모든 관측 가능한 변수들임
- State는 다음에 어떻게 행동할지 결정하는데 쓰이는 정보임. 즉, History에 대한 함수임
Major Components of an RL Agent
RL 에이전트는 보통 이 컴포넌트들을 하나 이상 포함한다.
- Policy: 에이전트의 행동 함수
- Value Function: 각 상태가 얼마나 좋은지
- Model: 환경에 대한 에이전트의 표현
Policy
- Policy는 에이전트의 행동임
- 상태를 행동으로 매핑함
- Deterministic policy:
- Stochastic policy:
Value function
- Value fuinction은 미래의 누적 보상에 대한 예측값임
- 각 상태의 좋고 나쁨을 평가하는데 사용될 수 있음
- 그리고 비교를 통해 어떻게 행동할지 결정할 수 있음
(Environment) Model
- Model은 행동이 다음에 어떻게 변화할 것인지를 예측함
- 는 다음 상태를 예측함
- 은 다음 보상을 예측함
Example Maze: Policy
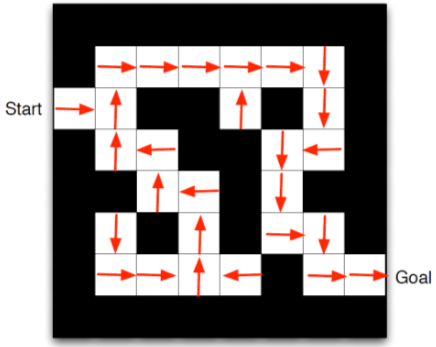
이 화살표들이 각 상태 에 대한 정책 를 나타냄
Example Maze: Value Function

각 숫자들이 에 대한 value function 를 나타냄
RL agent의 분류 (1)
- Value Based : No policy, Value Function
- Policy Based: Policy, No value function
- Actor Critic: Policy, Value function
RL agent의 분류 (2)
- Model-free: No model, policy and/or value function
- Model-based: Model, policy and/or value function
Planning과 Reinforcement Learning
Sequential decision making에는 두개의 기초적인 문제가 있음
- Planning
- 환경의 전환역학을 알 때 최적의 정책을 계산함
- look-ahead search 또는 dynamic programming을 사용하여 행동을 결정함
- 환경과의 직접적인 상호작용 없이 최적의 경로를 찾음
- Reinforcement Learning
- 환경을 알지 못한 채 시행착오를 통해 최적의 정책을 학습함
- 보상을 최대화하기 위해 exploration 및 exploitation 전략을 사용함
- 환경과 직접 상호작용하여 최적의 행동을 학습함
Exploration과 Exploitation
- 강화학습은 trial-and-error 학습과 비슷함
- 에이전트는 좋은 정책을 발견해야하고 이는 환경으로부터의 경험에서 나옴
- Exploration은 환경으로 부터 더 많은 정보를 찾는 것임
- Exploitation은 알려진 정보를 통해 보상을 최대화하는 것임
- 보통 Exploitation만큼 Exploration도 중요함
Prediction and Control
- prediction: 주어진 정책을 통해 미래를 평가하는 것
- control: 현재 정책을 개선시켜 최적의 정책을 찾는 것
요약
- 강화학습 vs 지도/비지도 학습
- State, Action, Reward
- Policy, Value, Model
- Planning vs Learning
- Exploration vs Exploitation
- Policy prediction & control

집요함과 에너지로 다른 사람에게 영감을 줄 것.