하둡 2.0
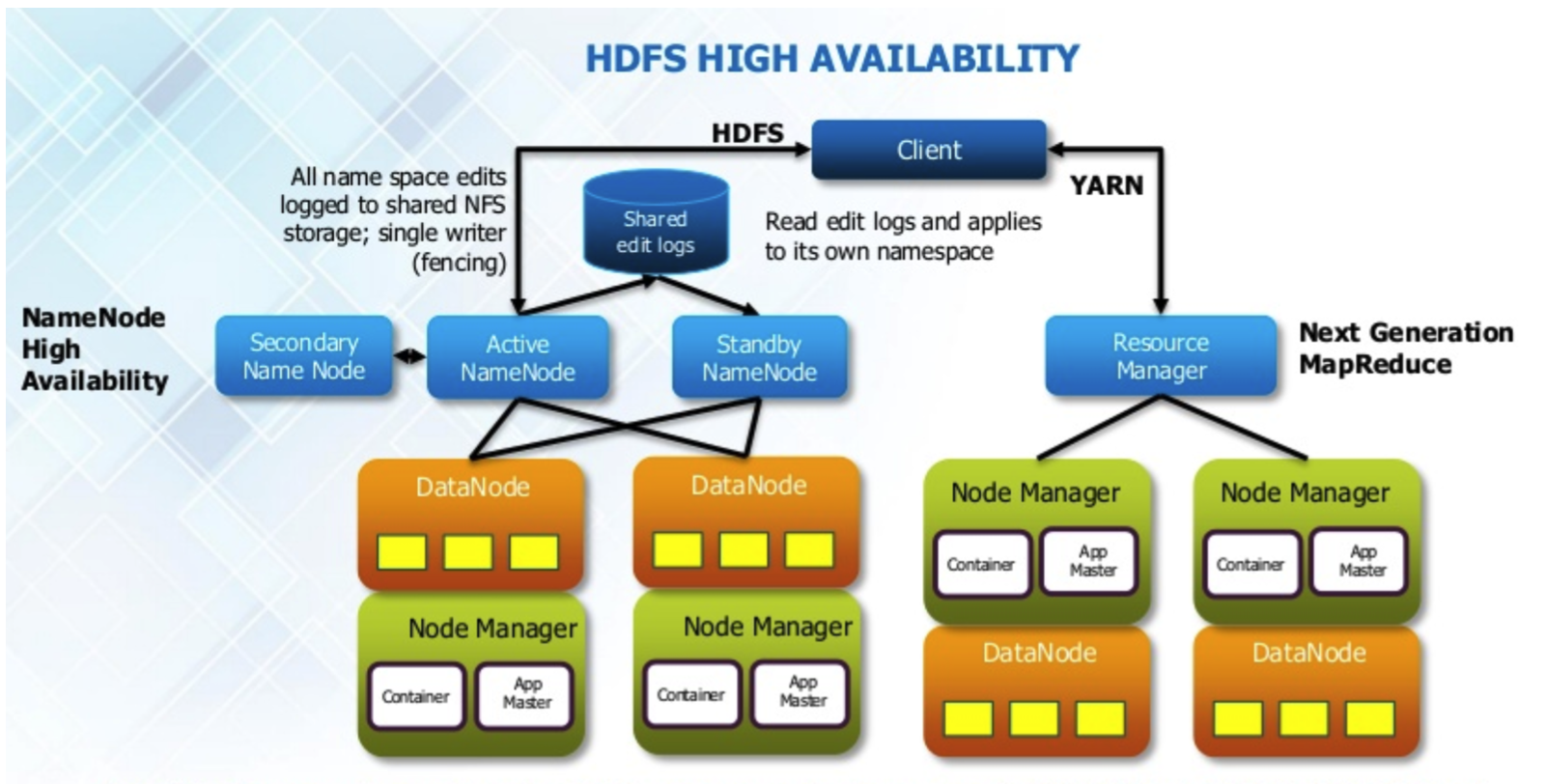
마스터 서버 장애를 해결하기 위한 부분이 가장 큰 변화 포인트
그림에서 SNN(Secondary Name Node)와 Active NN는 기존처럼 존재하는데 추가적으로 Stanby Name Node가 추가된 모습을 볼 수 있다
Stanby Name Node
데이타노드가 블록report를 하거나, 네임노드와 통신하는 것을 항상 Active와 Stanby 양쪽으로 통신을하게 된다. 그리고 StanbyNN는 평소에는 정보만 갖고있고 동작하지 않다가 ActiveNN가 다운되었을때 ActiveNN로 올라서게(전환) 된다
하둡2.0에서는 ANN에서 SNN로 전환되는 과정에서 약간의 다운타임이 발생할 수 있다.
(보통 하둡 네임노드의 메타정보의 크기에 비례해서 걸린다, 몇억개의 파일이 있으면 하둡네임노드의 크기가 100기가 가량 잡힌다 그러면 5~10분 소요)
Shared edit logs(중요)
네임노드가 단일구성일 때, 네임노드 메모리에 들어가있는 fsimage파일(하둡 메타정보에 대한 스냅샷)과 edits log가 로컬 메모리 어딘가에 저장이 되어있다
만약, 네임노드가 두개로 구성되면 edits log를 어디에다가 관리를 해야할까?
(Active와 Stanby가 공유를 해야하는데)
-> 네임노드 고가용성 & zooKepper(분산 코디네이터) 등장
Hadoop NameNode 이중화
NameNode의 두가지 측면에서의 안전성이 중요하다
- Durability(내구성)
- NameNode에서 관리하는 정보는 파일 시스템 전체 정보라고 할 수 있는 inode이다. inode에는 파일 시스템의 디렉토리 구조와 파일의 각 블럭에 대한 정보가 저장되어 있는데, 이 inode 정보가 잘못되거나 유실되면 클러스터가 수천대로 구성되어 있어도 저장된 파일은 아무런 쓸모가 없어지게 된다
- Availability(유효성)
- 수천대로 구성된 클러스터라 하더라도 NameNode 한대에 문제가 생기면 클러스터 전체가 동작하지 않게 된다
inode
아이노드는 정규 파일, 디렉터리 등 파일 시스템에 관한 정보를 가지고 있다, 유닉스계통 파일 시스템에서 사용하는 자료구조
NameNode 관리정보의 Durability
NameNode에는 크게 두가지 정보가 저장된다
- fsimage 정보 : 현재의 파일 구조 자체에 대한 정보
- edits log : 특정 시점에 구성된 fsimage snapshot 이후로 발생된 변경사항에 대한 edit log
이 두가지 정보 중에서 fsimage는 현재 시점에서의 최신 정보는 NameNode의 메모리에 로딩되어 있으며, 특정 시점의 snapshot은 NameNode에 mount되는 디스크에 파일 형태로 저장되어 있다. Edits log도 fsimage snapshot과 같이 NameNode의 디스크에 파일 형태로 저장된다
- 디스크에 중요한 정보를 저장해야하는 것이므로 fsimage와 edits log는 한개 이상의 디렉토리에 저장함으로서 안정성을 확보한다
NameNode의 이중화 구성 (Availability)
기본적인 서버의 이중화 구성
두대의 서버로 구성을 하고(Active, Stanby) 하나의 서버가 실제 기능을 수행하는 Active 서버 역활을 수행하고, 나머지 서버는 기능을 수행하지는 않지만 Active 서버 장애시 자동으로 Active 서버 역활을 수행하는 Stanby 서버 기능을 수행한다
이중화 구조의 문제점
-
Active 서버 장애 시점에 Stanby 서버에 Active 서버와 동일한 fsimage, edits log가 존재해야한다. 일반적인 구성에서 이 파일은 Active 서버에만 존재하므로 서버 장애 시 어떻게 Stanby로 가져올지에 대한 문제
-
Active 서버 장애 발생 시 Stanby 서버는 장애를 어떻게 찾아내고 두개의 서버가 동시에 Active 서버 상태가 발생하는 것을 어떻게 방지할 것인지에 대한 문제
- 이를 SplitBrain 상태라 한다. Standby Server가 Active Server가 되면서 기존의 Active Server가 계속해서 살아 있는 상태
이를 해결하기 위한 스토리지 구성 및 failover 처리 방법
-
스토리지 구성
- NFS(network file system)를 이용하는 방법
- Journal Node를 이용하는 방법
-
Failover 처리 : ZooKeeper를 이용한 자동 장애 인지 방법
네임노드 고가용성(High Availabilty)
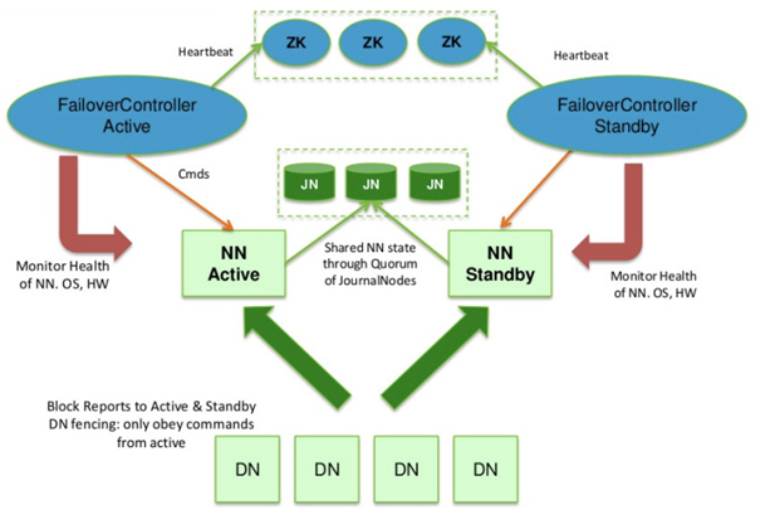
-
HDFS 고가용성은 이중화된 두대의 서버인 Active 네임노드와 Stanby 네임노드를 이용하여 지원한다
-
액티브 네임노드와 스탠바이 네임노드는 데이터 노드로부터 블록 리포트와 하트비트를 모두 받아서 동일한 메타데이터를 유지하고, 공유 스토리지를 이용하여 에디트(edit) 파일을 공유한다
-
액티브 NN는 네임노드의 역활을 수행하고, 스탠바이 NN는 액티브 NN와 동일한 메타 데이터 정보를 유지하다가, 액티브 NN에 문제가 발생하면 스탠바이 NN가 액티브 NN로 동작하게 된다
-
액티브 NN에 문제가 발생하는 것을 자동으로 확인하는 것이 어려우므로 보통 주키퍼를 이용하여 장애 발생시 자동으로 변경될 수 있도록 구성한다
주키퍼 (분산 코디네이터)
- 액티브 네임노드와 스탠바이 네임노드간에 문제발생시 역활을 바꿔주는 역활을 한다
- 분산 환경에서 서버들간의 상호 조정이 필요한 다양한 서비스 제공
- 하나의 서버에서 처리한 결과를 다른 서버들과도 동기화 -> 데이터 안정성을 보장한다
- 운영(active) 서버에서 문제가 발생하여 서비스 제공할 수 없는 경우
-> 다른 대기(stanby)중인 서버를 운영 서버로 바꿔 서비스 중지없이 제공되게 해준다 : 고가용성- 분산 동기화 제공 -> 하나의 서버에만 서비스가 집중되지 않도록 서비스를 알맞게 분산하여 동시에 처리하게 해준다
- 중앙 집중식 서비스로 알맞은 분산처리 및 분산 환경을 구성하는 서버 설정을 통합적으로 관리
저널 노드(JournalNode)
HDFS에서 새로 생긴 기능이 아닌 기존에 존재하던 방식으로 fsimage와 같은 스냅샷이 있고 edits log가 계속 발생하다가 edits log와 merge를 통해 백업이나 장애에 대응하는 처리 방식저널링은 보통 스냅샷을 갖고있고 지속적인 edits log를 가지는 방식을 말한다
edits log 공유 방식
- NFS(network file system) 방식
공유 스토리지를 이용하는 방법으로 공유 스토리지에 에디트 로그를 공유하고 펜싱을 이용하여 하나의 네임노드에만 에디트 로그를 기록한다
(펜싱 : active 서버에 문제가 발생하여서 stanby 서버를 active서버로 전환하는 과정을 일컫는다)
splitBrain 위험이 존재하고 네트워크상의 문제가 발생했을때 문제가 된다
-
두개의 Active NN가 발생하는 상황을 막기 위해
dfs.ha.fencing.methods 설정을 통해 Active NN을 Kill 시키거나 shrared Storage를 unmount해준다 -
만약 네트워크 장애의 경우, 기존 Active NN가 ZooKeeper와 Stanby NN로만 통신이 되지 않고, 공유 스토리지와 통신이 되는 상황이라면?
- 이런 경우 Stanby NN에서 fencing 처리는 네트워크 단절로 인해 수행할수 없으며 (서버장애 발생), 기존 Active NN는 여전히 Live한 상태가된다. Split Brain 발생 가능성이 존재한다
2. Journal Node를 이용한 이중화 구성 방식
저널노드는 edits 정보 (파일 시스템의 journaling(일지) 정보)를 저장하고 공유하는 기능을 수행하는 서버이다
저널노드에 저장되는 데이터는 아주 중요한 데이터이므로 하나의 서버로 구성되지 않고 3대의 서버로 구성된다. 이렇게 분산구성을 할 경우 저널노드 자체도 SplitBrain 상황이 발생할 수 있는데 이 문제는 저널노드 자체에서 해결하고 있다. 저널노드가 아닌곳에서 이런 SplitBrain 상황을 회피하기 위한 용도로 ZooKeeper를 사용한다
저널노드 자체적으로 SplitBrain 상황 등에 대처하는 방식 또한 ZooKeeper에서 사용하는 방식과 유사한 방식을 사용한다
저널노드 상에서의 failover 처리
-
Active 네임노드는 edit log처리용 epoch number를 할당 받는다. 이 번호는 유니크하게 증가하는 번호로 새로 할당 받은 번호는 이번번호보다 항상 크다
-
Active 네임노드는 파일 시스템 변경 시 Journal Node로 변경 사항을 전송한다. 전송 시 epoch number를 같이 전송한다
-
저널노드는 자신이 갖고있는 epoch number보다 큰 번호가 오면 자신의 번호를 새로운 번호로 갱신하고 해당 요청을 처리한다
-
저널노드는 자신이 갖고있는 번호보다 작은 epoch number를 받으면 해당 요청은 처리하지 않는다
- 이런 요청은 주로 SplitBrain 상황에서 발생한다
- 기존 NameNode가 정상적으로 Stanby로 변하지 않았고, NameNode가 정상적으로 fencing되지 않는 상태이다
-
Stanby NameNode는 주기적(1분)으로 저널노드로 부터 이전에 받은 edit log의 txid(트랙잭션 id, 운송장 번호 개념) 이후의 정보를 받아 메모리의 파일 시스템 구조에 반영한다
-
Active 네임노드 장애 발생 시 Stanby 네임노드는 마지막으로 받은 txid 이후의 모든 정보를 받아 메모리 구성에 반영 후 Active 네임노드로 변환한다
-
새로 Active 네임노드가 되면 1번 항목부터 다시 시작
이와 같은 방식으로 failover를 처리하기 때문에 갑작스런 장애가 발생해도 Stanby NN가 Active NN로 전환되고 edits log에서도 in-consistency(모순)이 발생하지 않게 된다
HDFS Federation
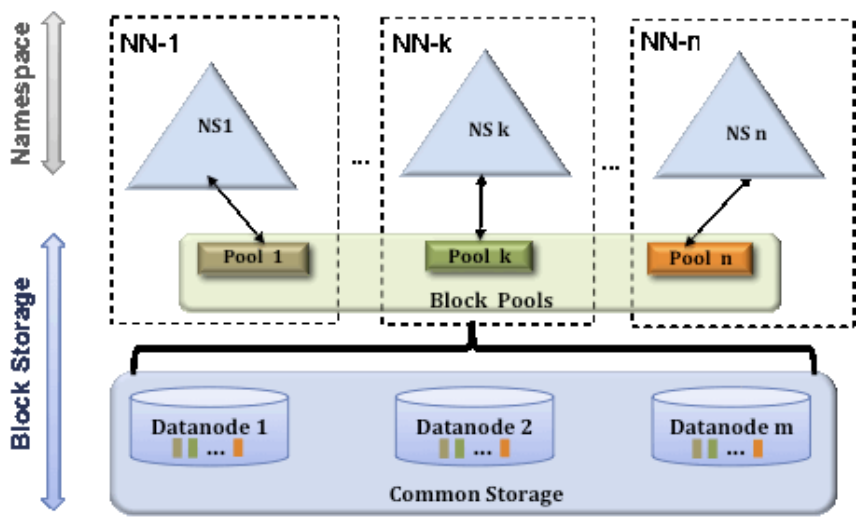
-
하나의 네임노드에서 관리하는 파일, 블록 개수가 많아지면 물리적 한계가 있다. 만약 네임노드의 디스크가 512Gb인데 클러스터의 파일 및 블록의 메타정보가 700Gb라면 문제가 발생
-
이를 해결하기 위해 HDFS Federation을 하둡 2.0 이상에서 지원, 복수의 네임노드를 갖게된다
-
HDFS 페더레이션을 사용하면 파일, 디렉토리 정보를 가지는 네임스페이스와 블록의 정보를 가지는 블록 풀을 각 네임노드가 독립적으로 관리한다
-
네임스페이스와 블록 풀을 네임스페이스 볼륨이라 하고 네임스페이스 볼륨은 독립적으로 관리되므로 하나의 네임노드에 문제가 생겨도 다른 네임노드에 영향을 주지 않는다
아파치 주키퍼란?
- 설정관리 (Configuration Management)
- 분산 클러스터 관리 (Distributed Cluster Management)
- 명명 서비스 (Naming Service, e.g., DNS)
- 분산 동기화 (Distributed Synchroization)
- 분산 시스템에서 리더 선출 (Leader election in a distributed system)
- 중앙 집중형 신뢰성 있는 데이터 저장소 (Centralized and highly reliable data registry)
아파치 주키퍼 구성
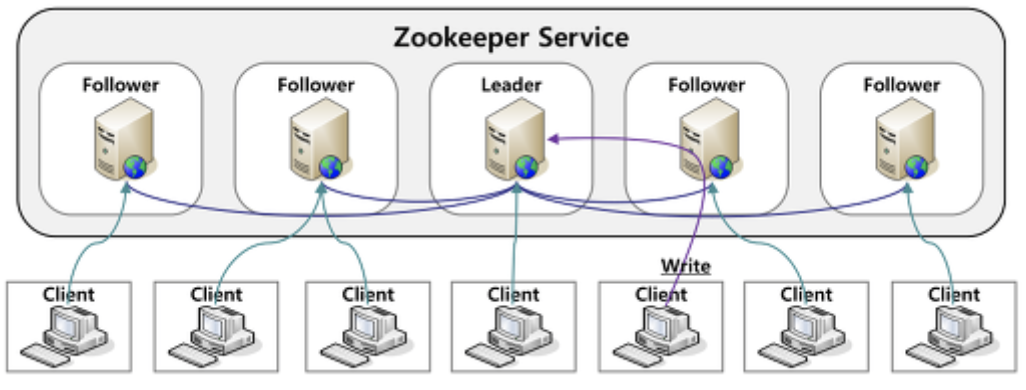
- 주키퍼는 n개의 서버로 단일 클러스터를 구성하며 이를 서버 앙상블이라고 한다
- 주키퍼 서비스는 복수의 서버에 복제되며, 모든 서버는 데이터 카피본을 저장한다
- Leader는 구동 시 주키퍼 내부 알고리즘에 의해 자동 선정된다
- Followers 서버들은 클라이언트로부터 받은 모든 업데이트 이벤트를 Leader에게 전달한다
- 클라이언트는 모든 주키퍼 서버에서 읽을 수 있으며, Leader를 통해 쓸 수 있고 과반수 서버의 승인(합의)가 필요하다
아파치 주키퍼 데이터 모델
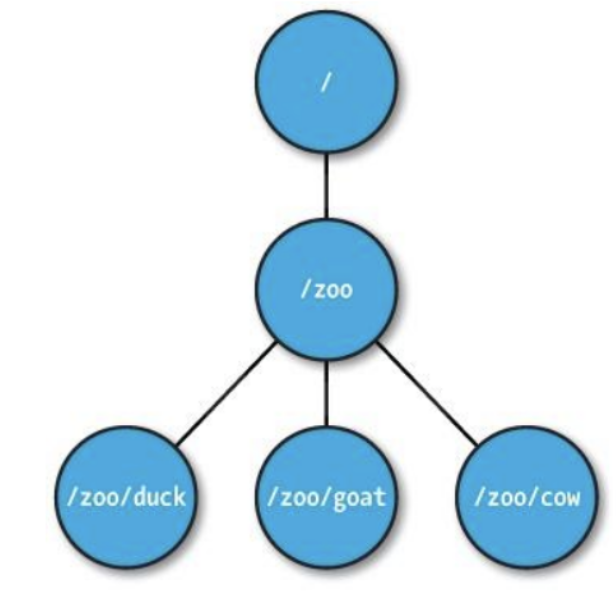
기본적으로 트리 형태를 갖는다
- 절대 경로로 '/'로 구분
- 변경이 발생하면 버전번호가 증가
- 데이터는 항상 전체를 읽고 쓴다
- znode는 1mb이하의 데이터를 가질 수 있으며, 자식 노드를 가질 수 있다
영속 종류
1. Persistents Nodes (영구 노드) : 명시적으로 삭제되기 전가지 존재한다
2. Ephemeral Nodes (임시 노드) : 세션이 유지되는 동안 활성 (세션이 종료되면 삭제된다), 자식노드를 가질 수 없다
3. Sequence Nodes (순차 노드) : 경로의 끝에 일정하게 증가하는 카운터가 추가된다. 영구 및 임시 노드 모두에 적용 가능
주피커 명령어
create, delete, exists, getChildren, getData, setData 등이 존재하며 언어별로 바인딩을 제공한다
주키퍼 WATCH
- Znode가 변경시 Noti를 클라이언트로 trigger 해줘서, 주키퍼의 znode 변화를 통지 받는다.
오퍼레이션 실행시 watch 등록 - zk.getChildren("mysvc/nodes", watcher)
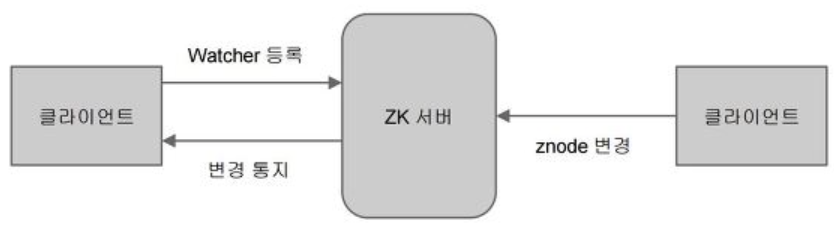
이벤트 종류
- 노드의 자식이 변경된 경우(NodeChildrenChanged)
- 노드가 생성된 경우 (NodeCreated)
- 노드의 데이터가 변경된 경우 (NodeDataChanged)
- 노드가 삭제된 경우(NodeDeleted)
아파치 주키퍼 사용 예
1) 클러스터 관리
- 그룹 멤버십 목록을 가질 부모 znode를 생성(예: /members)
- 부모 znode에 자신을 위한 자식 znode를 ephemeral로 생성 (예: /members/m-hostip)
- 자식 znode 데이터는 다른 구성원이 자신과 통신하는데 필요한 정보 저장(예: IP/Port)
- 또는 주기적으로 상태를 변경(load, memory, CPU etc.)
- 탈퇴하고자 할 경우 자신에 해당하는 znode를 삭제
- 멤버십 목록, 주기적 갱신(각 클라이언트) - 주기적으로 getChildren 실행해서 목록 갱신
- 멤버십 목록, Watch 이용(각 클라이언트) - 부모 znode에 getChildren 로 WATCH 등록하고 getChildren 결과로 목록 갱신
- NodeChildrenChanged 이벤트 수신 시, 위 과정 재실행
2) 리더 선출
- 마스터 후보 등록: 부모 znode에 자신을 위한 자식 znode를 시퀀스 & ephemeral 로 생성 (예: /masters/m-0000000010)
- 마스터 선출
. 부모 znode에 getChild로 WATCH 등록
. NodeChildrenChanged 이벤트 수신시, 현재 마스터가 없는지 확인
. 마스터에 해당 자식 znode가 없으면 부모 znode에 자식 znode를 구한뒤 시퀀스 번호가 가장 작은 znode를 마스터로 선택
.부모 znode에 getChild로 WATCH 등록
3) 분산 배타적 잠금
- N개의 클라이언트가 잠금(lock)을 소유하려고 시도한다고 가정
- 클라이언트들을 임시, 순차znode를 /cluster/locknode에 생성
- 클라이언트들은 잠금 znode 하위의 자식 리스트를 요청한다
- 가장 낮은 ID를 가진 클라이언트가 잠금을 소유한다
- 그 외의 클라이언트들은 감시(WATCH)를 수행한다
- 통지가 발생할 떄마다 잠금을 확인한다
- 잠금을 해제하고 싶은 클라이언트는 노드를 삭제하고 다음 클라이언트가 잠금을 획득하게 된다
4) 기타 용도
이벤트 통지: WATCH 사용
pub/sub : SEQUENCE사용
분산카운터: SEQUENCE 또는 znode의 version 사용
